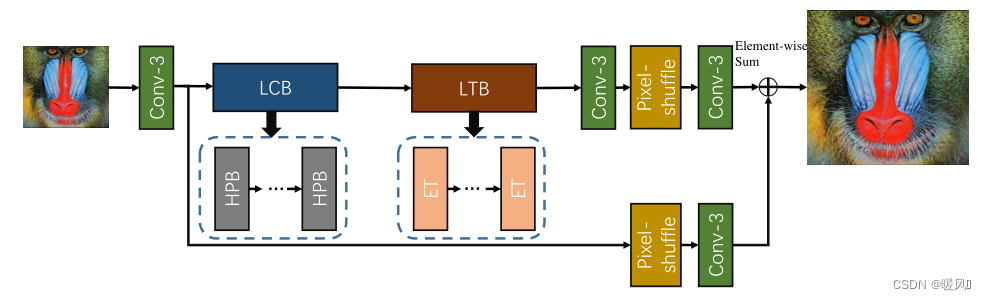
这篇文章网络结构ESRT( Efficient Super-Resolution Transformer)还是蛮复杂的,是一个CNN和Transformer结合的结构。文章提出了一个高效SRTransformer结构,是一个轻量级的Transformer。作者考虑到图像超分中一张图像内相似的细节部分可以作为参考补充,(类似于基于参考图像Ref的超分),于是引入了Transformer,可以在图像中建模一种长期依赖关系。而ViT这些方法计算量太大,太占内存,于是提出了这个轻量版的Transformer结构(ET)ET只使用了transformer中的encoder,并且作者还使用了feature spilt将QKV划分为小组分别计算注意力最后拼接。文章还在CNN部分提出了一个高频滤波器模块HFM,保留高频信息进行特征提取。
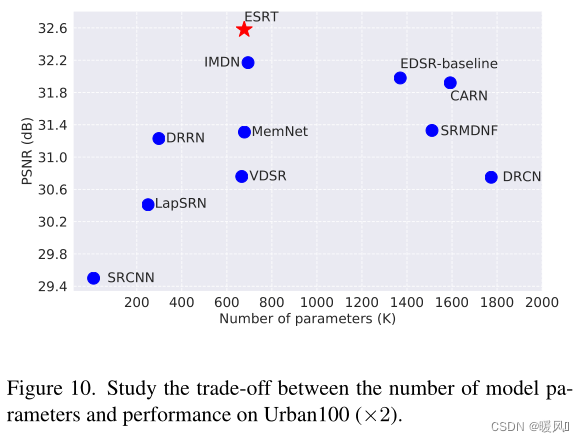
文章主要重点在速度(高效), 效果也是很好的,作者在实验部分提到把ET结构嫁接到RCAN中也能提高RCAN的效果,证明了ET的有效性。
原文链接:ESRT:Transformer for Single Image Super-Resolution
源码地址: https://github.com/luissen/ESRT.
ESRT:Transformer for Single Image Super-Resolution[CVPR 2022]
随着深度学习的发展,单幅图像超分辨率(SISR)技术取得了长足的进步。近来越来越多的研究人员开始探索Transformer在计算机视觉任务中的应用。然而,Vision Transformer巨大的计算成本和高GPU内存占用问题阻碍了其脚步。在本文中,提出了一种用于SISR的新型高效超分辨率Transformer(ESRT)。ESRT是一种混合模型,由轻型CNN主干网(LCB)和轻型Transformer主干网(LTB)组成。其中,LCB可以动态调整特征图的大小,以较低的计算成本提取深层特征。LTB由一系列高效Transformer(ET)组成,使用专门设计的高效多头注意(EMHA),它占用的GPU内存很小。大量实验表明,ESRT以较低的计算成本获得了有竞争力的结果。与原始Transformer占用16057M GPU内存相比,ESRT仅占用4191M GPU内存。
因为在同一张图像中相似的图像patch可以用作彼此的参考图像,以便使用参考patch来恢复特定patch的纹理细节。受此启发,作者将Transformer引入到SISR任务中,因为Transformer具有很强的特征表达能力,可以在图像中建模这种长期依赖关系。目标是探索在轻量级SISR任务中使用Transformer的可行性。近来有一些Transformer已经被提出用于计算机视觉任务。然而,这些方法往往占用大量GPU内存,这极大地限制了它们的灵活性和应用场景。
为了解决上述问题,提出了一种高效的超分辨率Transformer(ESRT),以增强SISR网络捕获长距离上下文依赖的能力,同时显著降低GPU的内存成本。
ESRT是一种混合架构,使用“CNN+Transformer”模式来处理小型SR数据集。ESRT可分为两部分:轻型CNN主干网(LCB)和轻型Transformer主干网(LTB)。
高频滤波模块(HFM)来捕捉图像的纹理细节。在HFM的内,又提出了一种高保留块(HPB),通过大小变化有效地提取潜在特征。在特征提取方面,提出了一种功能强大的自适应残差特征块(ARFB)作为基本特征提取单元,能够自适应调整残差路径和路径的权重。高效Transformer(ET),它使用专门设计的高效多头注意(EMHA)机制来降低GPU内存消耗。且只考虑局部区域中图像块之间的关系,因为SR图像中的像素通常与其相邻像素相关。尽管它是一个局部区域,但它比常规卷积要宽得多,可以提取更多有用的上下文信息。因此,ESRT可以有效地学习相似局部块之间的关系,使超分辨区域具有更多的参考。主要贡献如下:
高效超分辨率Transformer(ESRT)主要由四部分组成:浅层特征提取、轻型CNN主干(LCB)、轻型Transformer主干(LTB)和图像重建。
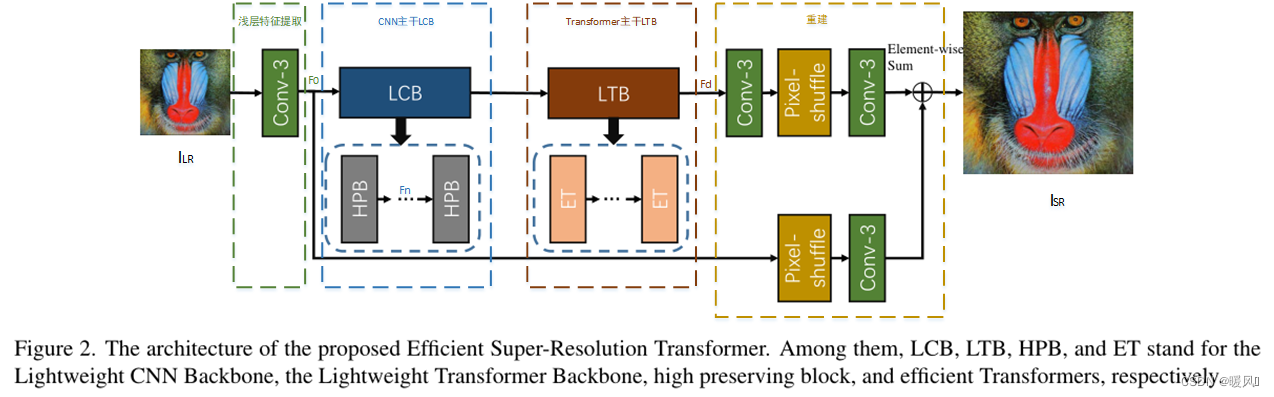
浅层特征提取:
一个3×3卷积层
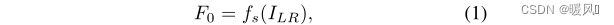
轻型CNN主干(LCB):
由多个高保留块High Preserving Blocks(HPBs)组成(实验中为3个),
ζ
n
ζ^n
ζn 是第n个HPB的映射,第n个HPB的输出为
F
n
F_n
Fn,公式:
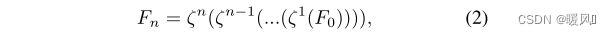
轻型Transformer主干(LTB):
每个HPB的输出拼接后送进LTB融合特征,LTB由多个Efficient Transformers (ETs)组成(实验中为1个),
ϕ
\phi
ϕ代表的是ET的功能,
F
d
F_d
Fd是LTB的输出,公式如下。
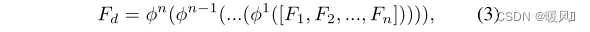
图像重建:
最后
F
d
F_d
Fd和
F
0
F_0
F0同时馈入重建模块,以获得重建图像
I
S
R
I_{SR}
ISR。
f
f
f和
f
p
f_p
fp分别代表卷积层和亚像素卷积层,获得
I
S
R
I_{SR}
ISR的公式如下:
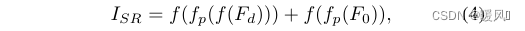
ESRT的整体结构比较常规,深层特征提取联合使用了CNN和Transformer。LCB内使用了比较复杂的结构,推理速度比较慢,而ET中仅使用了一个Transformer的encoder结构并不会带入太大的计算量。后面实验也证明了加入ET能给网络带来增益。
轻量级CNN主干网(LCB)的作用是提前提取潜在的图像特征,使模型具有超分辨率的初始能力。LCB主要由一系列高保留块(HPB)组成。
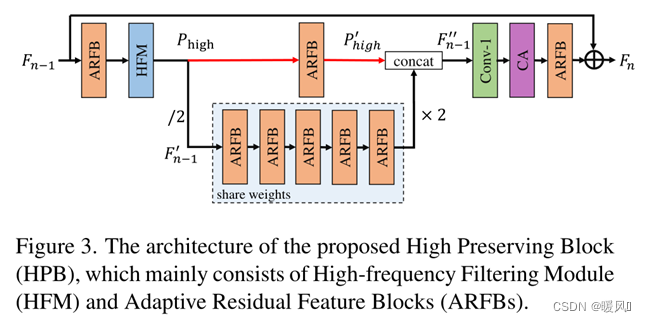
HPB:
以往的SR网络通常在处理过程中保持feature map的空间分辨率不变。在本文中为了降低计算成本,提出了一种新的高保留块(HPB)来降低处理特征的分辨率。然而,特征图尺寸的减小往往会导致图像细节的丢失,从而导致视觉上不自然的重建图像。为了解决这个问题,在HPB中,作者创造性地提出了高频滤波模块(HFM)和自适应残差特征块(ARFB)。
先介绍HPB的整体结:由HFM和ARFB组成。再详细剖析HFM和ARFB的结构。
整体结构: 前一个HPB的输出
F
n
−
1
F_{n-1}
Fn−1,作为当前HPB的输入。先经过一个ARFB用于提取
F
n
−
1
F_{n-1}
Fn−1作为HFM的输入功能。然后,使用HFM计算特征的高频信息(标记为
P
h
i
g
h
P_{high}
Phigh)。在获得
P
h
i
g
h
P_{high}
Phigh后,减小了特征映射的大小,以减少计算成本和特征冗余。下采样特征图表示为
f
n
−
1
′
f'_{n−1}
fn−1′、对于
f
n
−
1
′
f'_{n−1}
fn−1′使用多个共享权重的ARFB来探索SR图像的潜在信息(减少参数)。同时,使用单个ARFB处理
P
h
i
g
h
P_{high}
Phigh来对齐特征空间
f
n
−
1
′
f'_{n−1}
fn−1′。
f
n
−
1
′
f'_{n−1}
fn−1′在特征提取后通过双线性插值上采样到原始大小。拼接融合
f
n
−
1
′
f'_{n−1}
fn−1′和
P
h
i
g
h
′
P'_{high}
Phigh′,得到
f
n
−
1
′
′
f''_{n−1}
fn−1′′,用于保留初始细节。得到
f
n
−
1
′
′
f''_{n−1}
fn−1′′的公式为:
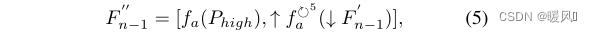
其中,↑和↓代表上下采样;
f
a
f_a
fa代表ARFB的功能。为了平衡模型尺寸和性能,采用五个共享参数的ARFB。
f
n
−
1
′
′
f''_{n−1}
fn−1′′由两个特征拼接,因此先使用1×1卷积层来减少t通道数。然后,使用通道注意力来加大具有高激活值的频道权重。最后,使用ARFB提取最终特征,并提出全局残差连接来添加原始特征
F
n
−
1
F_{n−1}
Fn−1至
F
n
F_n
Fn。该操作的目的是从输入中学习残差信息并稳定训练。
通道注意力模块引自Squeeze-and-excitation networks这篇文章,或者和RCAN中使用的CA模块是一样的。
这篇文章实际上也是套娃残差结构,但在残差结构上进行了很多改进,比如说加入了自适应的Res scaling、高频滤波器,下采样循环卷积等等。
HFM:High-frequency Filtering Module
由于傅里叶变换很难嵌入到CNN中,本文提出了一种可微HFM。HFM的目标是从LR空间估计出图像的高频信息。
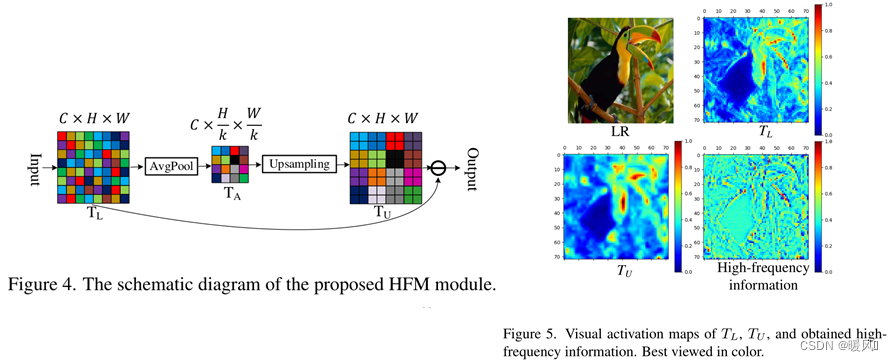
如图4所示,假设输入特征映射
T
L
T_L
TL的大小为
C
×
H
×
W
C×H×W
C×H×W,首先使用平均池化获得
T
A
T_A
TA:

其中k表示池化层的kernel大小,中间特征映射
T
A
T_A
TA的大小为
C
×
H
k
×
W
k
C×\frac{H}{k}×\frac{W}{k}
C×kH×kW。
T
A
T_A
TA中的每个值都可以被视为指定的
T
L
T_L
TL小区域的平均强度。之后,对TA进行上采样,以获得尺寸为
C
×
H
×
W
C×H×W
C×H×W的新张量
T
U
T_U
TU。
T
U
T_U
TU是平均平滑度信息的表达式。最后,从
T
L
T_L
TL中按元素减去
T
U
T_U
TU以获得高频信息。
T L T_L TL、 T U T_U TU和高频信息的视觉激活图如图5所示。可以观察到, T U T_U TU比 T L T_L TL更平滑,因为它是 T L T_L TL的平均信息。同时,高频信息在下采样(平均池化)之前保留了特征图的细节和边缘。因此,保存这些信息至关重要。
ARFB:Adaptive Residual Feature Block
受ResNet和VDSR启发,当模型的深度增加时,残差结构可以缓解梯度消失问题,并增加模型的表示能力。于是提出了一种自适应残差特征块(ARFB)作为基本特征提取块。
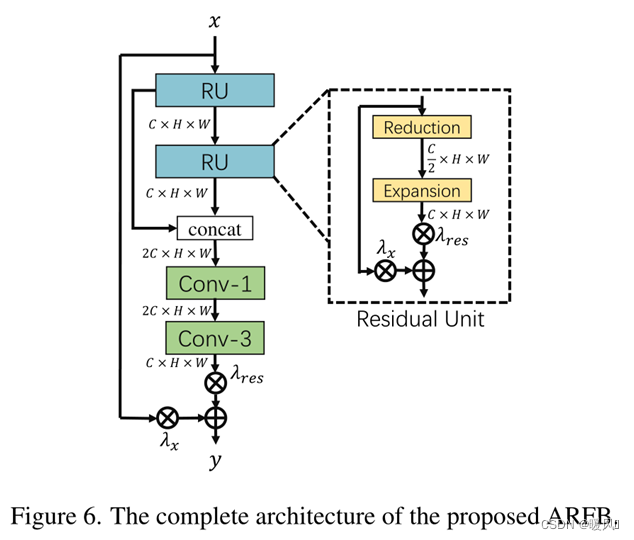
ARFB包含两个残差单元(RU)和两个卷积层。为了节省内存和参数数量,RU由两个模块组成:缩减模块和扩展模块。对于缩减,将特征映射的通道减少一半,并在扩展中恢复。同时,设计了一种带自适应权值的残差缩放算法(RSA),动态调整残差路径权重。与固定Res scaling相比,RSA可以改善梯度的流动,并自动调整残差特征映射的内容,以用于输入特征映射。假设
x
r
u
x_{ru}
xru是RU的输入,RU的过程可以表示为:
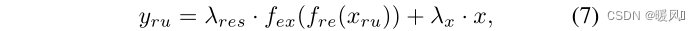
其中,
y
r
u
y_{ru}
yru是RU的输出,
f
r
e
f_{re}
fre和
f
e
x
f_{ex}
fex表示缩减和扩展操作,
λ
r
e
s
λ_{res}
λres和
λ
x
λ_x
λx分别是两条路径的自适应权重。使用1×1卷积层来改变通道数,以实现缩减和扩展功能。同时,将两个RU的输出拼接后输入1×1卷积层,以充分利用层次特征。最后,采用3×3卷积层来减少特征映射的通道,并从融合后的特征中提取有效信息。
LCB,CNN的部分就结束了,回顾一下:LCB由三个HPB构成。每个HPB由HFM和ARFB构成,结构中包含通道注意力和上下采用及五个共享参数的ARFB。全文贯穿了一个理念:减少参数。(ARFB共享参数、上下采样、缩减扩展层都是为了减少参数,体现轻量高效)
在SISR中,图像中的相似图像块可以用作彼此的参考图像,因此可以参考其他图像块来恢复当前图像块的纹理细节,这非常适合使用Transformer。然而,以前的vision Transformer变体通常需要大量的GPU内存,这阻碍了Transformer在vision领域的发展。在本文中,作者提出了一种轻型Transformer主干(LTB)。LTB由专门设计的高效Transformer(ETs)组成,可以以较低的计算成本捕获图像中相似局部区域的长期依赖性。
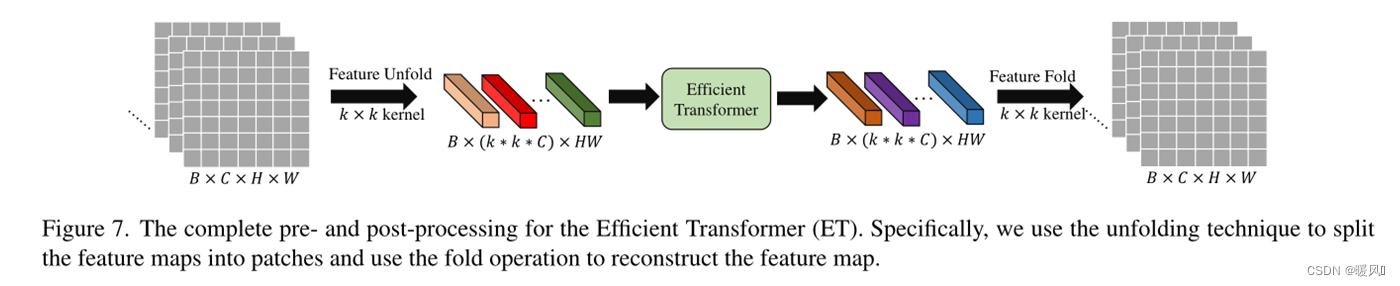
前后的准备工作: 将feature map展成一维序列、将序列转回feature map
标准Transformer将一维序列作为输入,学习序列的长距离依赖关系。而对于视觉任务,输入始终是二维图像。
在ViT中,一维序列是通过非重叠块划分生成的,这意味着每个块之间没有像素重叠。作者认为这种预处理方法不适用于SISR。
因此,提出了一种新的特征映射处理方法。如图7所示,使用展开技术将特征地图分割成小块(其实就是用重叠的块来划分patch),每个小块都被视为一个“单词”。具体而言,feature map ∈ R C × H × W ∈ R^{C×H×W} ∈RC×H×W(通过 k × k k×k k×k核)展开为一系列patch,即 F p i ∈ R k 2 × C , i = 1 , … , N F_{pi}∈ R^{k^2×C},i={1,…,N} Fpi∈Rk2×C,i=1,…,N,其中 N = H × W N=H×W N=H×W是patch数量。关键部分就在于N的数量是 H × W H×W H×W,意味着分割的时候每次 k × k k×k k×k的kernel移动步长为1,每个patch之间有很大的重叠。而ViT和Swin-T都是以不重叠的块来划分,得到N数量为 H k × W k \frac{H}{k}\times\frac{W}{k} kH×kW。
作者说由于“unfold”操作会自动反映每个patch的位置信息,因此每个patch的可学习位置嵌入都会被消除(???这是咋消除的)。然后,这些patch直接送进ET。ET的输出与输入具有相同的形状,使用“fold”操作来重建特征图。
EMHA:Efficient Multi-Head Attention
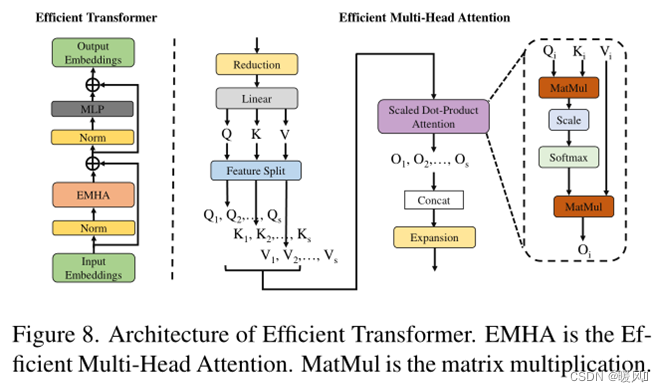
为了简单高效,与ViT一样,ET只使用标准Transformer的编码器结构。如图8左边所示,在ET的编码器中,有一个高效的多头注意(EMHA)和一个MLP。同时,在每个块之前使用层规范化,并且在每个块之后应用残差连接。ET部分与标准的encoder结构基本一致,唯二的区别在于,①作者把将QKV特征分割为s组,每组分别进行attention获得输出
O
i
O_i
Oi,然后将输出Concat为O。将大矩阵相乘拆分为多个小矩阵相乘,来减少参数操作;②注意力计算的时候不适用mask。
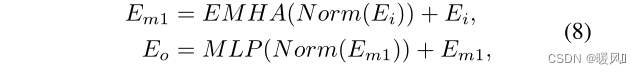
如图8右边所示,假设输入 E i E_i Ei的形状为B×C×N。
缩减层将通道数减少一半(
B
×
C
2
×
N
B×\frac{C}{2}×N
B×2C×N)。线性层将特征映射投影为三个元素:Q(查询)、K(键)和V(值)。特征分割(FS)模块将Q、K和V分割为具有同等分割因子s的s等分段,分别表示为
Q
1
,
.
.
.
,
Q
s
Q_1,...,Q_s
Q1,...,Qs、
K
1
,
.
.
.
,
K
s
K_1,...,K_s
K1,...,Ks和
V
1
,
.
.
.
,
V
s
V_1,...,V_s
V1,...,Vs。注意力操作(SDPA)输出
O
i
O_i
Oi,SDPA比于标准的注意力模块省略了mask操作。拼接起来,生成整个输出特征O。扩展层恢复通道数。假设标准Transformer中,Q和K计算形状为B×m×N×N的自注意力矩阵。然后该矩阵与V计算自注意力,第3和第4个维度为N×N。对于SISR,图像通常具有高分辨率,导致N非常大,自注意力矩阵的计算消耗了大量GPU内存和计算成本。
↓↓
为了解决这个问题,由于超分辨率图像中的预测像素通常只依赖于LR中的局部相邻区域,因此将Q、K和V分割为s等分段。最后一个自矩阵的第3和第4个维度变为为
N
s
×
N
s
\frac{N}{s}\times\frac{N}{s}
sN×sN,显著降低了计算量和GPU存储成本。
setting:
训练:使用DIV2K作为训练数据集。
测试:使用了五个基准数据集,包括Set5、Set14、BSD100、Urban100和Manga109。
指标:PSNR和SSIM用于评估重建SR图像的性能。
batch:16
patch:48×48
图像增强:随机水平翻转和90度旋转
初始学习速率设置为
2
×
1
0
−
4
2×10^{-4}
2×10−4每200个epochs减少一半。
optimizer:Adam ,momentum = 0.9。
损失函数:L1 loss
使用一个GTX1080Ti GPU训练需要约两天时间。
缩减层使用1×1卷积核,其他均使用3×3
卷积层通道数32,融合层通道数64
图像重建使用PixelShuffle
HFM中的k = 2
三个HPB,一个ET
分裂因子s = 4
ET的前后工作中k = 3
EMHA 8头注意力
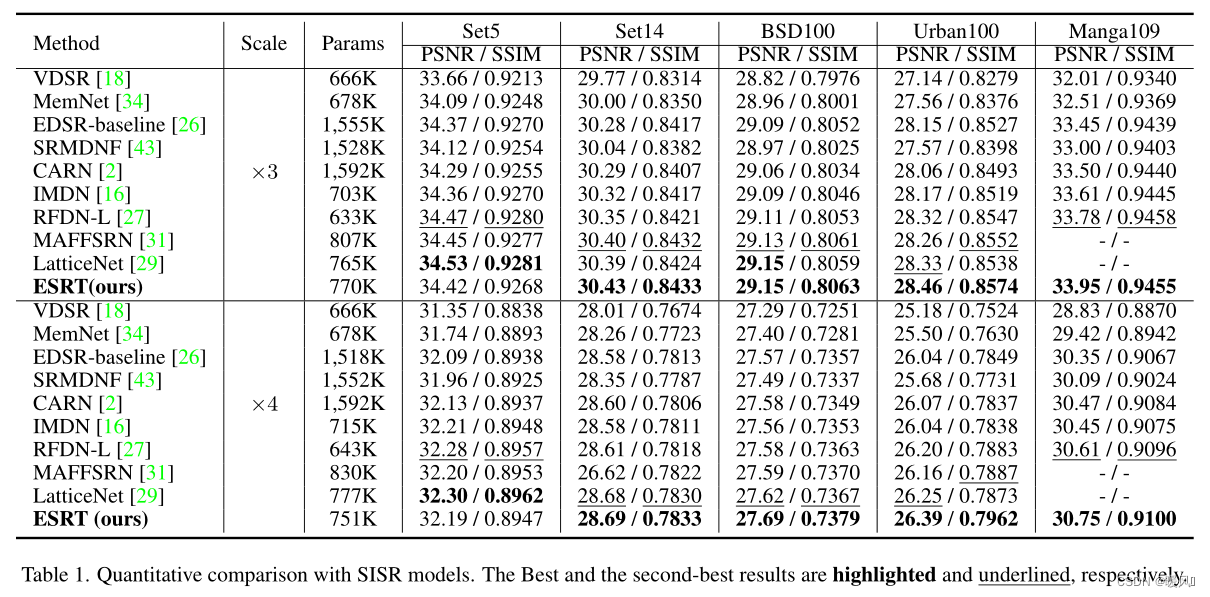
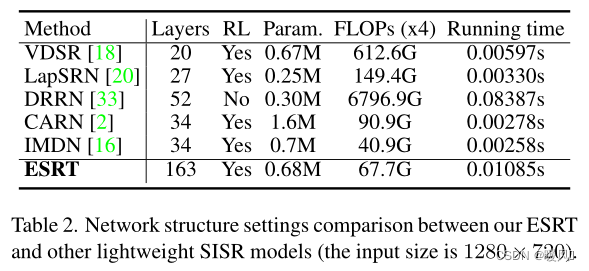
在表1中,
在表2中,
HPB:
表3中探讨了ESRT中HPB各组成部分的有效性。

ET:
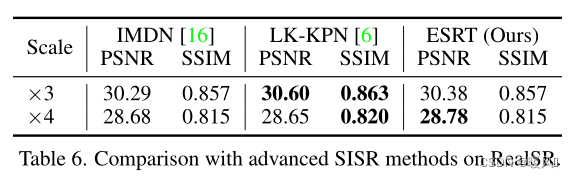
在表4中,分析了有无Transformer对模型的影响。
为了验证所提出的ET的有效性和普遍性,将ET引入RCAN。作者在实验中仅使用了一个小型版本的RCAN(残差组数量设置为5),并在重建部分之前添加ET。从表5可以看出,“RCAN/2+ET”模型的性能接近甚至优于原始RCAN,且参数更少。这进一步证明了ET的有效性和通用性,它可以方便地移植到任何现有的SISR模型中,进一步提高模型的性能。
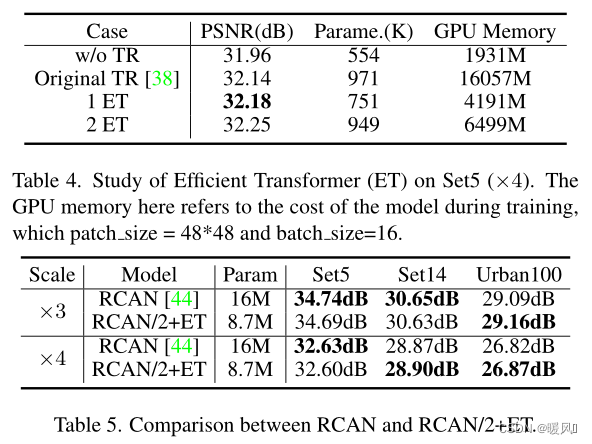
ESRT与真实图像数据集(RealSR)上的一些经典轻量级SR模型比较。根据表6,可以观察到ESRT达到了比IMDN更好的效果。此外,ESRT在×4上的性能优于LK-KPN,后者是专为实际SR任务设计的。该实验进一步验证了ESRT在真实图像上的有效性。
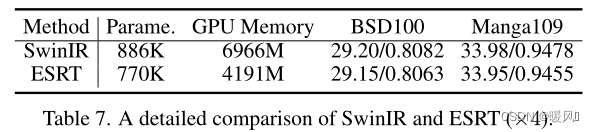
ESRT中的EMHA类似于SwinIR的Swin-Transformer层。然而,SwinIR使用滑动窗口来解决Transformer的高计算问题,而ESRT使用分裂因子来减少GPU内存消耗。根据表7,与SwinIR相比,ESRT以更少的参数和GPU内存实现了接近的性能。值得注意的是,SwinIR使用了一个额外的数据集(Flickr2K)进行训练,这是进一步提高模型性能的关键。为了与IMDN等方法进行公平比较,作者在这项工作中没有使用此外部数据集。
本文中,提出了一种用于SISR的新型高效超分辨率Transformer(ESRT)。
CNN和Transformer结合的混合结构。最后祝各位科研顺利,身体健康,万事胜意~
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
我们在Ubuntu14.04和Gitlab9.3.7上运行,运行良好。我们正在尝试更新到Gitlabv9.3.8的最新安全补丁,但它给我们这个错误:Gem::Ext::BuildError:ERROR:Failedtobuildgemnativeextension.currentdirectory:/home/git/gitlab/vendor/bundle/ruby/2.3.0/gems/re2-1.0.0/ext/re2/usr/local/bin/ruby-r./siteconf20170720-19622-15i0edf.rbextconf.rbcheckingformain(
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva
我一直在尝试用Ruby实现Luhn算法。我一直在执行以下步骤:该公式根据其包含的校验位验证数字,该校验位通常附加到部分帐号以生成完整帐号。此帐号必须通过以下测试:从最右边的校验位开始向左移动,每第二个数字的值加倍。将乘积的数字(例如,10=1+0=1、14=1+4=5)与原始数字的未加倍数字相加。如果总模10等于0(如果总和以零结尾),则根据Luhn公式该数字有效;否则无效。http://en.wikipedia.org/wiki/Luhn_algorithm这是我想出的:defvalidCreditCard(cardNumber)sum=0nums=cardNumber.to_s.s
下面是我写的一个计算斐波那契数列中的值的方法:deffib(n)ifn==0return0endifn==1return1endifn>=2returnfib(n-1)+(fib(n-2))endend它工作到n=14,但在那之后我收到一条消息说程序响应时间太长(我正在使用repl.it)。有人知道为什么会这样吗? 最佳答案 Naivefibonacci进行了大量的重复计算-在fib(14)fib(4)中计算了很多次。您可以将内存添加到您的算法中以使其更快:deffib(n,memo={})ifn==0||n==1returnnen
为了防止在迁移到生产站点期间出现数据库事务错误,我们遵循了https://github.com/LendingHome/zero_downtime_migrations中列出的建议。(具体由https://robots.thoughtbot.com/how-to-create-postgres-indexes-concurrently-in概述),但在特别大的表上创建索引期间,即使是索引创建的“并发”方法也会锁定表并导致该表上的任何ActiveRecord创建或更新导致各自的事务失败有PG::InFailedSqlTransaction异常。下面是我们运行Rails4.2(使用Acti
我正在开发一个类似微论坛的项目,其中一个特殊用户发布一条快速(接近推文大小)的主题消息,订阅者可以用他们自己的类似大小的消息来响应。直截了当,没有任何形式的“挖掘”或投票,只是每个主题消息的响应按时间顺序排列。但预计会有很高的流量。我们想根据它们引起的响应嗡嗡声来标记主题消息,使用0到10的等级。在谷歌上搜索了一段时间的趋势算法和开源社区应用示例,到目前为止已经收集到两个有趣的引用资料,但我还没有完全理解它们:Understandingalgorithmsformeasuringtrends,关于使用基线趋势算法比较维基百科页面浏览量的讨论,在SO上。TheBritneySpearsP
我收到错误:unsupportedcipheralgorithm(AES-256-GCM)(RuntimeError)但我似乎具备所有要求:ruby版本:$ruby--versionruby2.1.2p95OpenSSL会列出gcm:$opensslenc-help2>&1|grepgcm-aes-128-ecb-aes-128-gcm-aes-128-ofb-aes-192-ecb-aes-192-gcm-aes-192-ofb-aes-256-ecb-aes-256-gcm-aes-256-ofbRuby解释器:$irb2.1.2:001>require'openssl';puts
文章目录一.Dijkstra算法想解决的问题二.Dijkstra算法理论三.java代码实现一.Dijkstra算法想解决的问题解决的问题:求解单源最短路径,即各个节点到达源点的最短路径或权值考察其他所有节点到源点的最短路径和长度局限性:无法解决权值为负数的情况二.Dijkstra算法理论参数:S记录当前已经处理过的源点到最短节点U记录还未处理的节点dist[]记录各个节点到起始节点的最短权值path[]记录各个节点的上一级节点(用来联系该节点到起始节点的路径)Dijkstra算法步骤:(1)初始化:顶点集S:节点A到自已的最短路径长度为0。只包含源点,即S={A}顶点集U:包含除A外的其他顶
对于体育新闻中文文本的关键字提取,常用的算法包括TF-IDF、TextRank和LDA等。它们的基本步骤如下:1.TF-IDF算法: -将文本进行分词和词性标注处理。-统计每个词在文本中的词频(TF)。-计算每个词在整个语料库中出现的文档频率(DF)和逆文档频率(IDF)。-计算每个词的TF-IDF值,并按照值的大小进行排序,选择排名前几的词作为关键字。2.TextRank算法:-将文本进行分词和词性标注处理。-将分词结果转化成图模型,每个词语为节点,根据词语之间的共现关系建立边。-对图模型进行迭代计算,计算每个节点的PageRank值,表示该节点的重要性。-选择排名前几的节点作为关键字。3.