目录
最近在文献调研,发现PCA基本都有用到,回忆起了机器学习和数学建模,总之还是要好好学学捏。

定义:主成分分析(Principal Component Analysis, PCA)是一种统计方法。通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量,转换后的这组变量叫主成分。
换一种说法:PCA去除噪声和不重要的特征,将多个指标转换为少数几个主成分,这些主成分是原始变量的线性组合,且彼此之间互不相关,其能反映出原始数据的大部分信息,而且可以提升数据处理的速度。
为什么会出现PCA呢?因为每个变量都在不同程度上反映了所研究问题的某些信息,并且指标之间彼此有一定的相关性,因而所得的统计数据反映的信息在一定程度上有重叠。在用统计方法研究多变量问题时,变量太多会增加计算量和分析问题的复杂性。
核心思想:降维,这个过程中可能会损失精度,但是能获取更高更关键的因素。
例子1:评选三好学生,每个学生都有很多特征,比如学习成绩、社会实践、思想道德、体育成绩等。在评比中,有一些特征属于“ 无用特征 ”,比如身高、体重、头发长短等,这些特征在评比中是不会考虑的;而有一些特征属于“ 冗余特征 ”,比如各科成绩、总成绩、GPA,实际上这些有一个即可。
例子2:见下图。原本黑色坐标系中需要记录每个点的横纵坐标(xi, yi),也就是 2 个纬度的数据。
但如果转换坐标系,如绿色坐标系所示,让每个点都位于同一条轴上,这样每个点坐标为(xi’, 0),此时仅用x’坐标表示即可,即 1 个维度。

在这个过程中,原先需要保存的 2 维数据变成了 1 维数据,叫做数据降维 / 数据提炼。而PCA的任务形象理解也就是坐标系的转换。
PCA其实目的就是寻找这个转换后的坐标系,使数据能尽可能分布在一个或几个坐标轴上,同时尽可能保留原先数据分布的主要信息,使原先高维度的信息,在转换后能用低维度的信息来保存。而新坐标系的坐标轴,称为主成分(Principal components, PC),这也就是PCA的名称来源。
首先假设有 n 个样本,p 个特征,
x
i
j
x_{ij}
xij 表示第i个样本的第 j 个特征,这些样本构成的 n × p 特征矩阵 X 为:
X
=
[
x
11
x
12
⋯
x
1
p
x
21
x
22
⋯
x
2
p
⋮
⋮
⋱
⋮
x
n
1
x
n
2
⋯
x
n
p
]
=
[
x
1
,
x
2
,
⋯
,
x
p
]
X=\begin{bmatrix} x_{11} & x_{12} & \cdots & x_{1p} \\ x_{21} & x_{22} & \cdots & x_{2p} \\ \vdots & \vdots & \ddots & \vdots \\ x_{n1} & x_{n2} & \cdots & x_{np} \\ \end{bmatrix} = [x_1,x_2,\cdots,x_p]
X=⎣
⎡x11x21⋮xn1x12x22⋮xn2⋯⋯⋱⋯x1px2p⋮xnp⎦
⎤=[x1,x2,⋯,xp]
我们的目的是找到一个转换矩阵,将 p 个特征转化为 m 个特征(m < p),从而实现特征降维。即找到一组新的特征 / 变量
z
1
z_1
z1,
z
2
z_2
z2, …,
z
m
z_m
zm(m ≤ p),满足以下式子:
{
z
1
=
l
11
x
1
+
l
12
x
2
+
⋯
+
l
1
p
x
p
z
2
=
l
21
x
1
+
l
22
x
2
+
⋯
+
l
2
p
x
p
⋮
z
m
=
l
m
1
x
1
+
l
m
2
x
2
+
⋯
+
l
m
p
x
p
\begin{cases} \begin{aligned} z_1&=l_{11}x_1+l_{12}x_2+\dots+l_{1p}x_p \\ z_2&=l_{21}x_1+l_{22}x_2+\dots+l_{2p}x_p \\ \vdots \\ z_m&=l_{m1}x_1+l_{m2}x_2+\dots+l_{mp}x_p \end{aligned} \end{cases}
⎩
⎨
⎧z1z2⋮zm=l11x1+l12x2+⋯+l1pxp=l21x1+l22x2+⋯+l2pxp=lm1x1+lm2x2+⋯+lmpxp
有的博客写的是去中心化而不是标准化,在计算过程中也仅体现出步骤的不同,实际两种方法都可以用的,大家也可以看看这篇博客看看这几种“化”的区别:数据归一化、标准化和去中心化。本篇只研究标准化,第四部分的参考链接中介绍了标准化和去中心化的步骤,写得很详细,欢迎大家学习~
标准化过程如下:
计算每个特征(共p个特征)的均值
x
j
‾
\overline{x_j}
xj 和标准差
S
j
S_j
Sj,公式如下:
x
j
‾
=
1
n
∑
i
=
1
n
x
i
j
\overline{x_j}=\frac{1}{n}\sum_{i=1}^nx_{ij}
xj=n1i=1∑nxij
S
j
=
∑
i
=
1
n
(
x
i
j
−
x
j
‾
)
2
n
−
1
S_j=\sqrt{\frac{\sum_{i=1}^n(x_{ij}-\overline{x_j})^2}{n-1}}
Sj=n−1∑i=1n(xij−xj)2
将每个样本的每个特征进行标准化处理,得到标准化特征矩阵
X
s
t
a
n
d
X_{stand}
Xstand:
X
i
j
=
x
i
j
−
x
j
‾
S
j
X_{ij}=\frac{x_{ij}-\overline{x_j}}{S_j}
Xij=Sjxij−xj
X
s
t
a
n
d
=
[
X
11
X
12
⋯
X
1
p
X
21
X
22
⋯
X
2
p
⋮
⋮
⋱
⋮
X
n
1
X
n
2
⋯
X
n
p
]
=
[
X
1
,
X
2
,
⋯
,
X
p
]
X_{stand}=\begin{bmatrix} X_{11} & X_{12} & \cdots & X_{1p} \\ X_{21} & X_{22} & \cdots & X_{2p} \\ \vdots & \vdots & \ddots & \vdots \\ X_{n1} & X_{n2} & \cdots & X_{np} \\ \end{bmatrix} = [X_1,X_2,\cdots,X_p]
Xstand=⎣
⎡X11X21⋮Xn1X12X22⋮Xn2⋯⋯⋱⋯X1pX2p⋮Xnp⎦
⎤=[X1,X2,⋯,Xp]
协方差矩阵是汇总了所有可能配对的变量间相关性的一个表。
协方差矩阵 R 为:
R
=
[
r
11
r
12
⋯
r
1
p
r
21
r
22
⋯
r
2
p
⋮
⋮
⋱
⋮
r
p
1
r
p
2
⋯
r
p
p
]
R=\begin{bmatrix} r_{11} & r_{12} & \cdots & r_{1p} \\ r_{21} & r_{22} & \cdots & r_{2p} \\ \vdots & \vdots & \ddots & \vdots \\ r_{p1} & r_{p2} & \cdots & r_{pp} \\ \end{bmatrix}
R=⎣
⎡r11r21⋮rp1r12r22⋮rp2⋯⋯⋱⋯r1pr2p⋮rpp⎦
⎤
r i j = 1 n − 1 ∑ k = 1 n ( X k i − X i ‾ ) ( X k j − X j ‾ ) = 1 n − 1 ∑ k = 1 n X k i X k j \begin{aligned} r_{ij}&=\frac{1}{n-1}\sum_{k=1}^n(X_{ki}-\overline{X_i})(X_{kj}-\overline{X_j})\\ &=\frac{1}{n-1}\sum_{k=1}^nX_{ki}X_{kj} \end{aligned} rij=n−11k=1∑n(Xki−Xi)(Xkj−Xj)=n−11k=1∑nXkiXkj
计算矩阵R的特征值,并按照大小顺序排列,计算对应的特征向量,并进行标准化,使其长度为1。R是半正定矩阵,且 t r ( R ) = ∑ k = 1 p λ k = p tr(R) = \sum_{k=1}^p\lambda_k = p tr(R)=∑k=1pλk=p。
特征值: λ 1 ≥ λ 2 ≥ ⋯ ≥ λ p ≥ 0 \lambda_1\ge\lambda_2\ge \dots \ge \lambda_p\ge0 λ1≥λ2≥⋯≥λp≥0
特征向量: L 1 = [ l 11 , l 12 , … , l 1 p ] T … L p = [ l p 1 , l p 2 , … , l p p ] T L_1=[l_{11},l_{12},\dots ,l_{1p}]^T \dots L_p=[l_{p1},l_{p2},\dots ,l_{pp}]^T L1=[l11,l12,…,l1p]T…Lp=[lp1,lp2,…,lpp]T
若存在明显的多重共线性,则重新根据研究问题选取初始分析变量。
由于这里是【计算过程】而不是【研究过程】,此处不推翻3.0部分的假设,着重探讨PCA的计算流程即可,故3.3和3.4部分可跳过,真正的研究过程再考虑特征矩阵如何取。
一组数据是否适用于主成分分析,必须做适合性检验。可以用球形检验和KMO统计量检验。
1. 球形检验(Bartlett)
球形检验的假设:
H0:相关系数矩阵为单位阵(即变量不相关)
H1:相关系数矩阵不是单位阵(即变量间有相关关系)
2. KMO(Kaiser-Meyer-Olkin)统计量
KMO统计量比较样本相关系数与样本偏相关系数,它用于检验样本是否适于作主成分分析。KMO的值在0-1之间,该值越大,则样本数据越适合作主成分分析和因子分析。一般要求该值大于0.5,方可作主成分分析或者相关分析。Kaiser在1974年给出了经验原则:
| KMO值的范围 | 适合性情况 |
|---|---|
| 0.9以上 | 适合性很好 |
| 0.8~0.9 | 适合性良好 |
| 0.7~0.8 | 适合性中等 |
| 0.6~0.7 | 适合性一般 |
| 0.5~0.6 | 适合性不好 |
| 0.5以下 | 不能接受的 |
第 i 个主成分的贡献率为:
λ
i
∑
k
=
1
p
λ
k
\frac{\lambda_i}{\sum_{k=1}^p\lambda_k}
∑k=1pλkλi
前 i 个主成分的累计贡献率为:
∑
j
=
1
i
λ
j
∑
k
=
1
p
λ
k
\frac{\sum_{j=1}^i\lambda_j}{\sum_{k=1}^p\lambda_k}
∑k=1pλk∑j=1iλj
一般取累计贡献率超过80%的特征值所对应的第一、第二、…、第m(m ≤ p)个主成分。Fi表示第i个主成分:
F
i
=
l
i
1
X
1
+
l
i
2
X
2
+
⋯
+
l
i
p
X
p
,
(
i
=
1
,
2
,
…
,
p
)
F_i=l_{i1}X_1+l_{i2}X_2+\dots+l_{ip}X_p,(i=1,2,\dots,p)
Fi=li1X1+li2X2+⋯+lipXp,(i=1,2,…,p)
对于某个主成分而言,指标前面的系数越大(即 l i j l_{ij} lij),代表该指标对于该主成分的影响越大。
参考了这个链接:主成分分析(PCA)及其可视化——python。其中提供了两种方法,分别对应3.1为标准化和去中心化的步骤,每一步都有注释和代码,很详细!
还有这个写的太好了qaq,英文的球球大家一定要看:Principal Component Analysis in 3 Simple Steps
1. 数据集
是从这部分的第一个链接里随便扣出来的部分数据,如果大家感兴趣可以玩玩。
链接:https://pan.baidu.com/s/108JPN6LGg7GJfxCiJaItZA
提取码:3w5u
2. 安装库
pip install pandas
pip install numpy
pip install seaborn
pip install matplotlib
pip install sklearn
pip install factor_analyzer
3. 读取数据集
import pandas as pd
import numpy as np
import seaborn as sns
# 读取数据集
df = pd.read_csv(r"D:\vscpro\PyThon\data.csv",
sep=',',
header=None).reset_index(drop=True)
df.columns = ['a', 'b', 'c']
df.dropna(how="all", inplace=True)
df.tail()
4. 适合性检验(Bartlett && KMO)
from factor_analyzer.factor_analyzer import calculate_bartlett_sphericity
from factor_analyzer.factor_analyzer import calculate_kmo
df_check = df
# Bartlett 球状检验
chi_square_value, p_value = calculate_bartlett_sphericity(df_check)
print("Bartlett=", chi_square_value, p_value)
# KMO检验(>0.5为好,越靠近1越好)
kmo_all, kmo_model = calculate_kmo(df_check)
print("KMO=", kmo_all)

5. 标准化
# 标准化
from sklearn import preprocessing
from sklearn.preprocessing import StandardScaler
X = df.iloc[:, 0:3].values
Y = df.iloc[:, 2].values
X_std = StandardScaler().fit_transform(X)
df = preprocessing.scale(df)
print(df)
6. 法一:计算系数相关矩阵并特征求解
金融领域常使用相关矩阵代替协方差矩阵。
# 系数相关性矩阵
covX = np.around(np.corrcoef(df.T), decimals = 3)
# 系数相关矩阵特征求解
featValue, featVec= np.linalg.eig(covX.T)
print(featValue, featVec)
7. 法二:计算协方差矩阵并特征求解
# 协方差矩阵
# ①写法:
# mean_vec = np.mean(X_std, axis=0)
# covX = (X_std - mean_vec).T.dot((X_std - mean_vec)) / (X_std.shape[0]-1)
# ②写法:
covX = np.cov(X_std.T)
# print(covX)
# 协方差矩阵特征求解
cov_mat = np.cov(X_std.T)
eig_vals, eig_vecs = np.linalg.eig(cov_mat)
# 基于相关矩阵的标准化数据的特征分解
cor_mat1 = np.corrcoef(X_std.T)
eig_vals, eig_vecs = np.linalg.eig(cor_mat1)
# 基于相关矩阵的原始数据的特征分解
cor_mat2 = np.corrcoef(X.T)
eig_vals, eig_vecs = np.linalg.eig(cor_mat2)
print(eig_vals, eig_vecs)
8. 计算贡献率
# 特征值排序输出
featValue = sorted(featValue)[::-1]
# 贡献度
gx = featValue / np.sum(featValue)
#累计贡献度
lg = np.cumsum(gx)
print(featValue, gx, lg)

9. 选取主成分
# 选取主成分,一般要超过80%或85%
k = [i for i in range(len(lg)) if lg[i] < 0.85]
k = list(k)
print(k)
10. 表示主成分
# 主成分对应的特征向量矩阵
selectVec = np.matrix(featVec.T[k]).T
selectVe = selectVec*(-1)
print(selectVec)
# 表示主成分
finalData = np.dot(X_std, selectVec)
print(finalData)

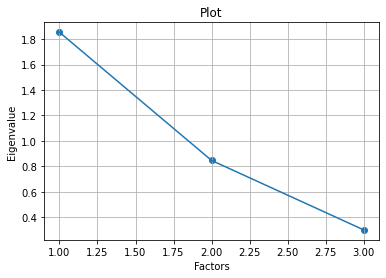
11. 绘制图像
import matplotlib.pyplot as plt
# 绘制散点图和折线图
plt.scatter(range(1, df.shape[1] + 1), featValue)
plt.plot(range(1, df.shape[1] + 1), featValue)
plt.title("Plot")
plt.xlabel("Factors")
plt.ylabel("Eigenvalue")
plt.grid()
plt.show()
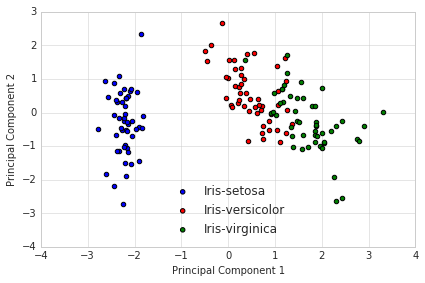
这个数据集是经典鸢尾花~
from sklearn.decomposition import PCA as sklearnPCA
sklearn_pca = sklearnPCA(n_components=2)
Y_sklearn = sklearn_pca.fit_transform(X_std)
# draw
with plt.style.context('seaborn-whitegrid'):
plt.figure(figsize=(6, 4))
for lab, col in zip(('Iris-setosa', 'Iris-versicolor', 'Iris-virginica'),
('blue', 'red', 'green')):
plt.scatter(Y_sklearn[y==lab, 0],
Y_sklearn[y==lab, 1],
label=lab,
c=col)
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.legend(loc='lower center')
plt.tight_layout()
plt.show()
这部分用来堆堆其他大佬们写的代码,方便后面学习和使用。
(1)PCA的Python实现
##Python实现PCA
import numpy as np
def pca(X,k):#k is the components you want
#mean of each feature
n_samples, n_features = X.shape
mean=np.array([np.mean(X[:,i]) for i in range(n_features)])
#normalization
norm_X=X-mean
#scatter matrix
scatter_matrix=np.dot(np.transpose(norm_X),norm_X)
#Calculate the eigenvectors and eigenvalues
eig_val, eig_vec = np.linalg.eig(scatter_matrix)
eig_pairs = [(np.abs(eig_val[i]), eig_vec[:,i]) for i in range(n_features)]
# sort eig_vec based on eig_val from highest to lowest
eig_pairs.sort(reverse=True)
# select the top k eig_vec
feature=np.array([ele[1] for ele in eig_pairs[:k]])
#get new data
data = np.dot(norm_X,np.transpose(feature))
return data
X = np.array([[-1, 1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
print(pca(X,1))
(2)sklearn的PCA
##用sklearn的PCA
from sklearn.decomposition import PCA
import numpy as np
X = np.array([[-1, 1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
pca = PCA(n_components=1)pca.fit(X)
print(pca.transform(X))
PCA的数学思想:
其余要点:
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
前言作为一名程序员,自己的本质工作就是做程序开发,那么程序开发的时候最直接的体现就是代码,检验一个程序员技术水平的一个核心环节就是开发时候的代码能力。众所周知,程序开发的水平提升是一个循序渐进的过程,每一位程序员都是从“菜鸟”变成“大神”的,所以程序员在程序开发过程中的代码能力也是根据平时开发中的业务实践来积累和提升的。提高代码能力核心要素程序员要想提高自身代码能力,尤其是新晋程序员的代码能力有很大的提升空间的时候,需要针对性的去提高自己的代码能力。提高代码能力其实有几个比较关键的点,只要把握住这些方面,就能很好的、快速的提高自己的一部分代码能力。1、多去阅读开源项目,如有机会可以亲自参与开源