译者 | 李睿
审校 | 孙淑娟
灾难恢复(DR)是企业级数据库的核心功能。数据库供应商一直在寻找改进灾难恢复的方法,而在过去的10年里,数据库灾难恢复也出现了重大的创新。
本文简要介绍数据库灾难恢复的发展历史,重点介绍了基于云计算的分布式数据库中的灾难恢复(DR)和高可用性(HA)的创新。
高可用性(HA)和灾难恢复(DR)的目标是保持系统在操作级别上正常运行。它们都试图消除系统中的单点故障,并使故障切换或恢复过程实现自动化。
高可用性(HA)通常由系统每年运行的时间百分比来衡量。灾难恢复的重点是在灾难发生之后使系统恢复服务,使数据的损失最小化。这是由两个指标来衡量的:恢复所需的时间或恢复时间目标(RTO),以及数据量的丢失或恢复点目标(RPO)。而恢复点目标(RPO)和恢复时间目标(RTO)应该尽可能降低。
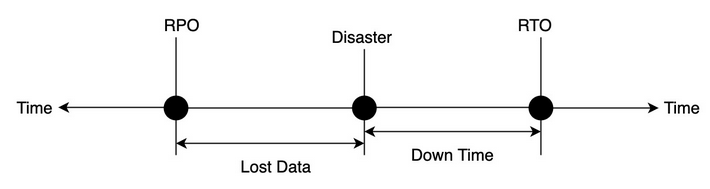
高可用性和灾难恢复的测量
每个灾难都是独一无二的,因此容错目标(FTT)描述了系统能够承受的最大灾难范围。通常使用的容错目标(FTT)是区域级别,它表示灾难已经影响到州或城市等地理区域。
数据库的灾难恢复技术经历了备份和恢复、主备和多活三个阶段。
在灾难恢复的早期阶段,数据库利用数据块和事务日志为完整数据和增量数据创建备份。如果发生灾难,则从备份和应用程序事务日志恢复数据库。
近年来,公共云数据库服务将存储复制与传统数据库备份技术相结合,提供基于快照的跨区域自动恢复备份。这种方法定期从源区域的数据库生成快照,并将快照文件复制到目标区域。如果源区域崩溃,则从目标区域恢复数据库,服务将会继续。这种解决方案的恢复点目标(RPO)和恢复时间目标(RTO)可能长达几个小时,因此它最适合没有严格可用性需求的应用程序。
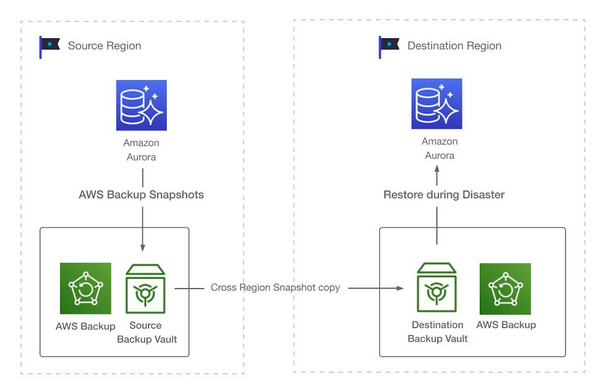
备份和恢复的灾难恢复
数据库集群标志着开发的第二个阶段。在集群中,主节点读取和写入数据。一个或多个备份节点接收事务日志并应用它们,提供具有一定延迟的读取功能。
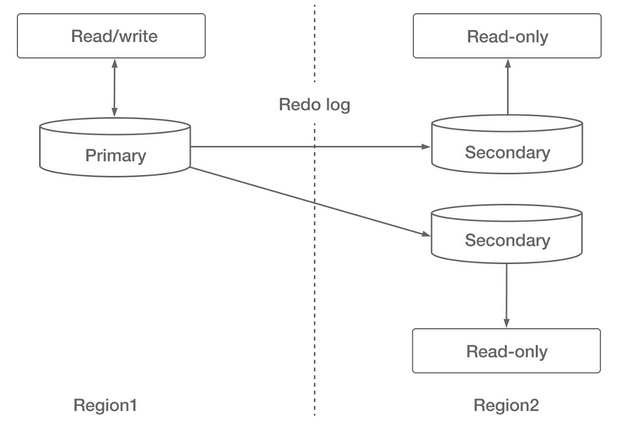
主备的灾难恢复
尽管这个解决方案涉及到集群的概念,但它仍然基于一个整体数据库。可扩展性仅限于读操作,不能扩展写操作。当然与前一代解决方案相比,其恢复时间目标(RTO)减少到几分钟,恢复点目标(RPO)减少到几秒。
Amazon Aurora使用跨区域读副本的逻辑复制,是建立在该技术上的早期云数据库服务之一。
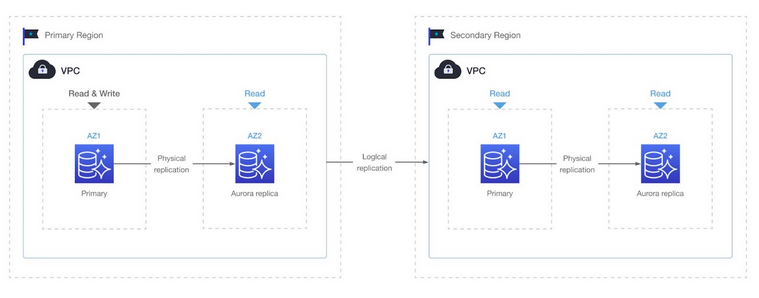
具有跨区域读副本的Aurora逻辑复制
近年来,Aurora在这一设计的基础上提供了全球数据库服务。该服务通过存储复制技术,将数据从源区域异步复制到目的区域。如果源区域出现故障,服务可以立即切换到备份集群。恢复时间目标(RTO)可以减少到几分钟,恢复点目标(RPO)不到一秒。
在多活灾难恢复中,一个数据库为同一份数据副本提供至少三个读和写服务节点,并且数据库可以根据工作负载向外或向内扩展。这种功能背后的需求来自广泛的互联网规模应用程序,这些应用程序需要更高的性能、更低的延迟、更高的可用性、弹性扩展性和数据库的弹性。
传统的分片数据库基于一个或多个列共享数据,形成了多活。分片解决方案通过事务日志复制实现灾难恢复。例如,谷歌公司曾经维护过一个非常大的MySQL分片系统。这个解决方案提供了某种程度的可扩展性,但不能随着碎片的增加而提高灾难恢复能力。其性能将显著下降,维护成本将大幅上升。因此,分片是多活的过渡解决方案。
近年来,基于Raft或Paxos共识协议的无共享数据库发展迅速。他们解决了以上提到的可扩展性和可用性挑战。多活的主要参与者包括TiDB和CockroachDB。他们的数据库及其灾难恢复技术使大多数遗留数据库和关系数据库服务(RDS)过时。
以下了解应用于分布式数据库的多活灾难恢复。例如,TiDB是一个开源的、高可用性的分布式数据库。它将每个表或分区划分为较小的TiDB区域,并将这些TiDB区域中的数据的多个副本存储在不同的TiKV节点上。这就是所谓的数据冗余。TiDB采用Raft共识协议,因此当数据发生更改时,只有在事务日志同步到大多数数据副本时才返回事务提交。这极大地提高了数据库恢复点目标(RPO)。事实上,在大多数情况下恢复点目标(RPO)是0。这确保了数据的一致性。此外,TiDB的架构将其存储引擎和计算引擎分离开来。这允许用户根据工作负载的变化扩展TiDB节点和TiKV存储节点。
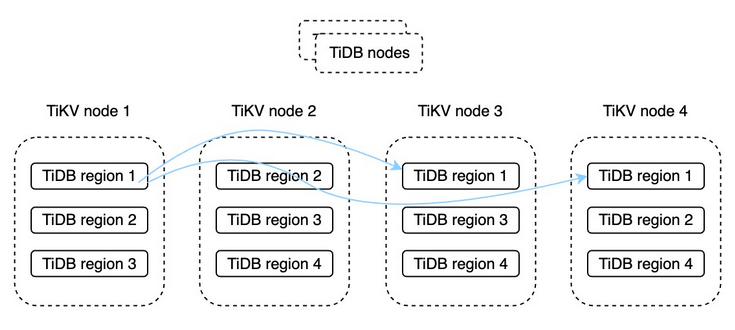
TiDB的存储架构
下图显示了TiDB如何交付典型的多区域灾难恢复解决方案。
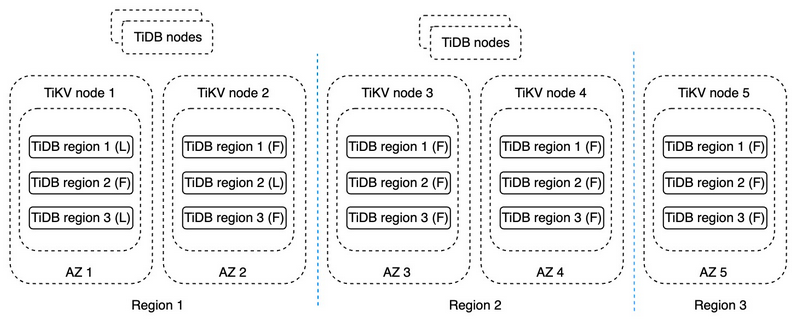
TiDB的多区域容灾解决方案
以下是TiDB容灾架构的关键术语:
在上图中,每个区域包含数据的两个副本。它们位于不同的可用性区域(AZ)中,整个集群跨越三个区域。区域1通常处理读写请求。区域2用于在区域1发生灾难后的故障转移,它还可以处理一些对延迟不敏感的读负载。区域3是保证即使在区域1完成时仍能达成共识的副本。这种典型的配置称为“2-2-1”架构。这种架构不仅确保了灾难恢复,而且为业务提供了多活能力。在这一架构中:
许多分布式数据库供应商经常向他们的用户推荐这种架构作为灾难恢复解决方案。例如,CockroachDB推荐他们的3-3-3配置来实现区域级灾难恢复;Spanner为多区域部署提供2-2-1配置。但是,当区域1和2同时不可用时,这一解决方案不能保证高可用性。一旦区域1完全关闭,如果区域2上的任何一个存储节点出现问题,则可能会导致系统性能下降,甚至数据丢失。如果需要多区域级别的容错目标(FTT),或者需要严格的系统响应时间,则仍然需要将这一解决方案与事务日志复制技术相结合。
TiCDC是TiDB的增量数据复制工具。它获取TiKV节点上的数据变化,并与下游系统同步。TiCDC具有与事务日志复制系统类似的架构,但它具有更强的可扩展性,并且在灾难恢复场景中与TiDB协同工作良好。
以下配置包含两个TiDB集群。区域1和区域2共同组成集群1,这是一个由5个副本组成的集群。区域1包含两个副本,用于提供读写操作,区域2包含两个副本,用于在区域1发生灾难时进行快速故障转移。区域3包含一个用于在Raft组中达到quorum的副本。区域3中的集群2作为灾难恢复集群。它包含三个副本,以便在区域1和区域2发生灾难时提供快速故障转移。TiCDC处理两个集群之间数据更改的同步。这种增强的架构可以称为2-2-1:1。
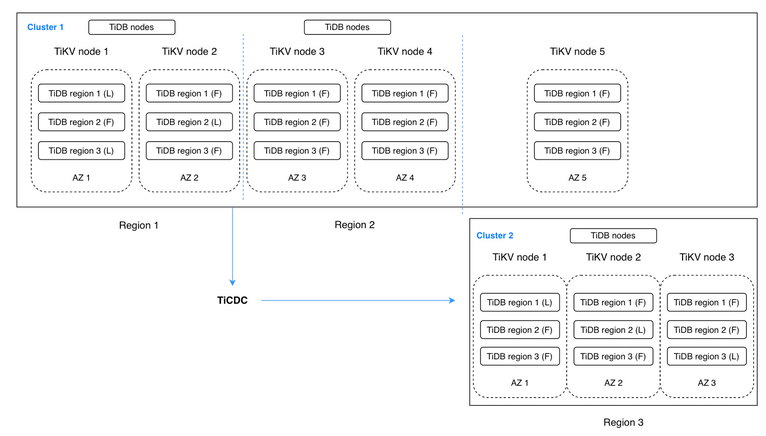
使用TiCDC的TiDB多区域灾难恢复
这种看似复杂的配置实际上具有更高的可用性。它可以实现多区域级别的最大容错目标,恢复点目标(RPO)以秒为单位,恢复时间目标(RTO)以分钟为单位。对于单个区域,如果完全不可用,恢复时间目标(RTO)为0。
在下表中,对本文中提到的容灾解决方案进行了比较:
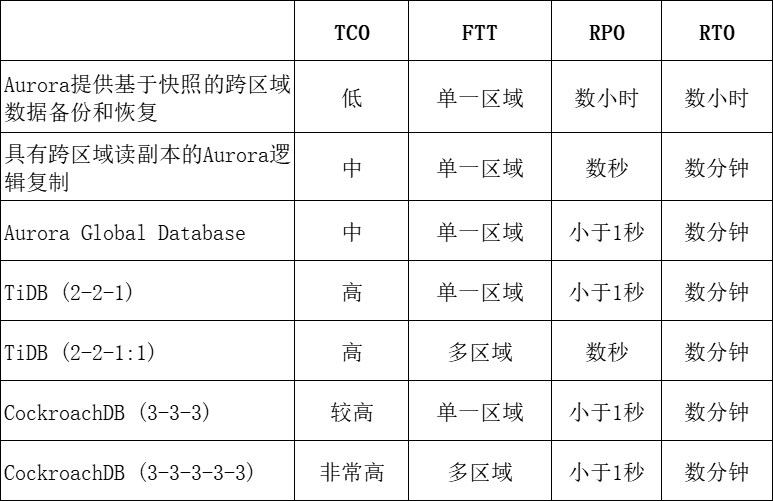
经过30多年的发展和几个不同的发展阶段,灾难恢复技术如今已经进入了多活阶段。
而使用无共享架构,TiDB等分布式数据库结合了多副本技术和日志复制工具,将数据库容灾带入多区域时代。
原文链接:https://dzone.com/articles/how-the-disaster-recovery-solutions-for-cloud-data
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
给定这段代码defcreate@upgrades=User.update_all(["role=?","upgraded"],:id=>params[:upgrade])redirect_toadmin_upgrades_path,:notice=>"Successfullyupgradeduser."end我如何在该操作中实际验证它们是否已保存或未重定向到适当的页面和消息? 最佳答案 在Rails3中,update_all不返回任何有意义的信息,除了已更新的记录数(这可能取决于您的DBMS是否返回该信息)。http://ar.ru
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
在选择我想要运行操作的频率时,唯一的选项是“每天”、“每小时”和“每10分钟”。谢谢!我想为我的Rails3.1应用程序运行调度程序。 最佳答案 这不是一个优雅的解决方案,但您可以安排它每天运行,并在实际开始工作之前检查日期是否为当月的第一天。 关于ruby-如何每月在Heroku运行一次Scheduler插件?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/8692687/
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为