最近系统性学习了一遍LIO-SAM,开始的时候一直搞不懂里程计坐标系,经过不断学习才有了一点自己的拙见。
引言:首先我们搞清楚SLAM算法主要是解决建图与定位问题,其更侧重定位,即让机器人知道自己在全局地图的哪个位置,只有这样才能继续后续的预测、感知、控制等模块。但是 SLAM算法做定位 这件事存在的意义就是为了解决当GPS这类非自主定位传感器信号不连续时的定位问题。SLAM算法主要是靠激光雷达/相机、IMU等传感器来做定位,但是不管是精度再高的激光雷达通过点云匹配得出位姿还是IMU预积分给出的位姿都会和map中的绝对位姿产生不断变化的误差,这个不断变化的误差便造就了不断变化的“里程计坐标系”。
继续往下看:
1.地图坐标系(map)
地图坐标系就是全局坐标系,其原点就是机器人刚开始出现在地图的那一点,属于固定坐标系,是不会动的。
2.里程计坐标系(odom)
这一部分是我想讲的重点,我会尽量讲详细,方便大家理解。
首先我们通过引言知道,里程计坐标系的产生是由于传感器的误差。举个例子:假设机器人在激光雷达第n帧走到了A点,A点在map上的坐标为(2,0),但是由于传感器的误差,导致传感器解算出来的坐标在(3,0),这个时候在odom下的坐标就是(3,0),因此可以说,odom相对于map在x方向上漂移了1m,如下图:
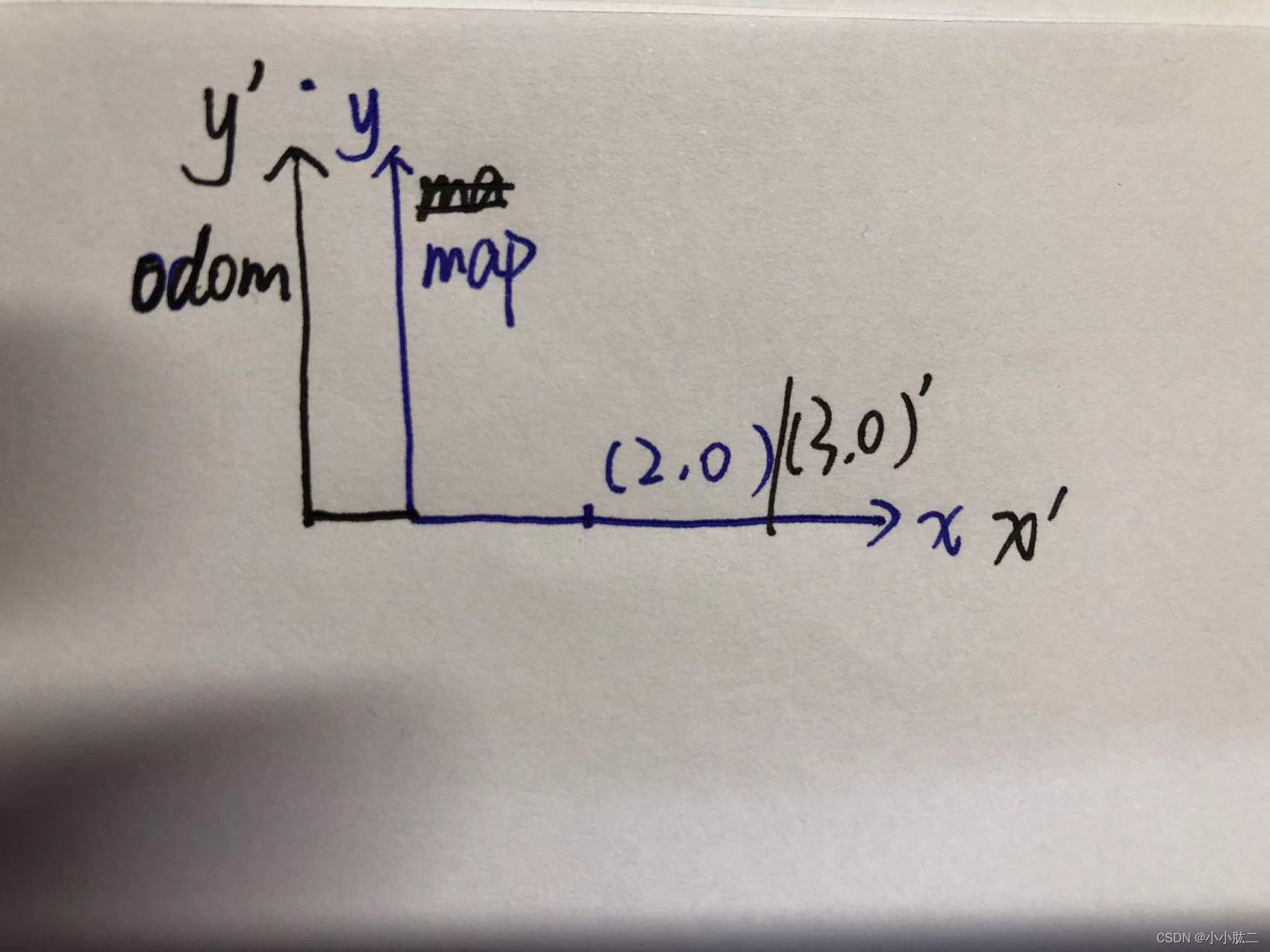
黑色代表odom,蓝色代表map。但是此时上图中的odom只存在于激光雷达第n帧的范畴内,假设到了激光雷达第n+1帧的时候,机器人走到了B点,B点在map上的坐标为(2,1),但是再次由于传感器的误差,导致传感器解算出来的坐标在(3,2),这个时候在odom下的坐标就是(3,2),因此可以说,odom相对于map在x方向上漂移了1m,y方向上漂移了1m,此时的odom与第n帧的odom就不同了,如下图
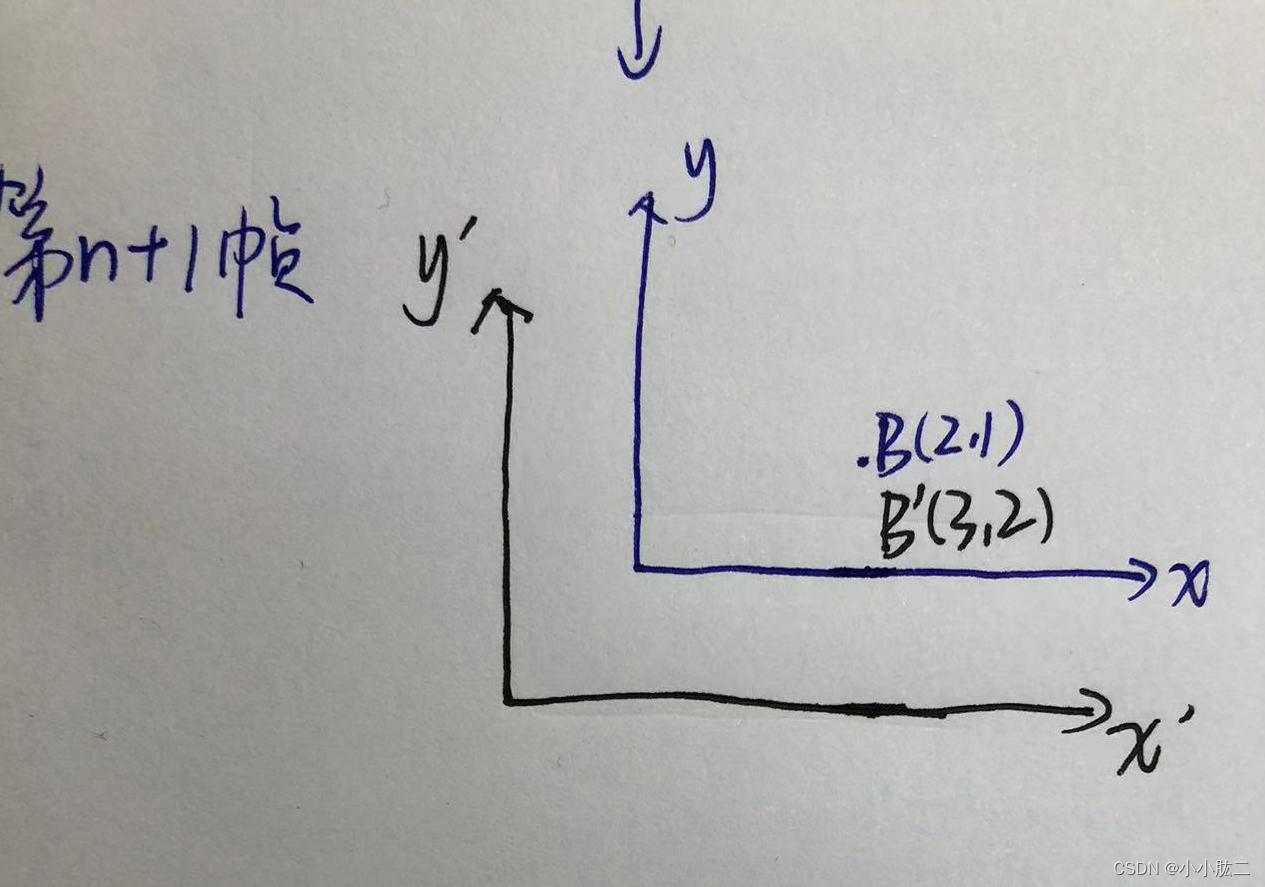
我们知道map坐标系是固定的,所以我们可以得到一个结论:odom是会随着每一帧激光雷达帧的输入而变化的。
我们回过头来看引言,SLAM算法做定位 这件事存在的意义就是为了解决当GPS这类传感器信号不连续时的定位问题,因此通过算法得出来的定位结果,本就不是绝对位姿,是一个通过解算估计出来的位姿,结合上面的图来说,我们通过SLAM算法得到的定位结果是B’而不是B(B是理想情况下的绝对位姿),但是我们最终需要得到的定位结果是在map坐标系下的位姿而不是odom下的。因此我们需要做一步操作,令每一帧的odom与map重合,即下图这样:

上图意思就是:机器人通过传感器解算得到的坐标在map中为(3,2),但是机器人实际在map中的绝对位置为(2,1)(这里不要理解错了,在地图中机器人是在(2,1)这个点的,B’这个点是传感器解算出来的,实际在地图中(3,2)这个点是没有机器人的,举个栗子,我(机器人)在家门口蒙着眼往家里面走,走了十步,我凭我自己在家里生活了这么多年的经验(传感器1)再加上我耳朵(传感器2)听到电视机的声音大小判断出来我这个时候在客厅并且距离电视机还有一米的距离(传感器结算出来的定位结果),但是我妈妈告诉我其实距离电视机还有两米的距离(绝对位置),这里的一米就相当于传感器解算的位置,妈妈告诉我的两米是绝对位置,因此我这个时候真正的位置是距离电视机两米的那个地方,而距离电视机只有一米的那个地方是没有人的,现在回到B点和B’点,机器人实际位置是在B点那个地方,B’这个点是没有机器人的。)算法解算位置与绝对位置在x与y方向有1的误差。(当然在实际的SLAM算法中的误差并没有这么大,只是为了方便大家理解,公司项目上就是用的LIOSAM这套代码,如果定位有1m的误差早把人撞si了哈哈哈)
OK现在回过头来看上面那个结论:我说odom是会随着每一帧而变化的,现在可能大家会问,odom与map重合以后不是固定了吗?我直接说答案,其实还是在变的,在坐标系重合之前,odom就是通过map中的绝对坐标与算法解算出来的坐标的误差创造出来的,只不过变化是相对的,现在坐标系虽说固定了,但是算法解算出来的坐标与实际坐标的误差是在不断变化的,因此可以理解为odom还是在不断变化的,只不过是看上去不变了。
总结:一句话概括,odom就是一个由于实际坐标与解算坐标两者的误差而产生的一个不断变化的坐标系。
3.基座坐标系(base_link)
这个就是机器人自身的坐标系,固定在机器人身上的某个位置,没啥好说的。
4.激光坐标系(laser_link)
这个就是激光雷达的坐标系,这个坐标系也很重要,对点云的操作(例如点云去畸变、提取特征点等等)就是在这个坐标系下完成的,也是固定在机器人身上的某个位置,与base_link的转换是固定的,甚至有些框架中base_link与laser_link是重合的,也没啥好说的。
到这里坐标系的部分就讲完了。我发这篇博客的目的,首先还是为了写一些有关SLAM坐标系的个人理解,如果能帮到大家也是我的荣幸;其次就是如果我哪里写错了,大家能纠正出来的话对我个人也有帮助,也欢迎大家积极留言评论。
码字不易,感谢大家!
本文主要介绍在使用Selenium进行自动化测试或者任务时,对于使用了iframe的页面,如何定位iframe中的元素文章目录场景描述解决方案具体代码场景描述当我们在使用Selenium进行自动化测试的时候,可能会遇到一些界面或者窗体是使用HTML的iframe标签进行承载的。对于iframe中的标签,如果直接查找是无法找到的,会抛出没有找到元素的异常。比如近在咫尺的例子就是,CSDN的登录窗体就是使用的iframe,大家可以尝试通过F12开发者模式查看到的tag_name,class_name,id或者xpath来定位中的页面元素,会抛出NoSuchElementException异常。解决
我爱Sanitize.这是一个了不起的实用程序。我遇到的唯一问题是,它需要永远准备一个开发环境,因为它使用Nokogiri,这对编译时间来说是一种痛苦。是否有任何程序可以在不使用Nokogiri的情况下执行Sanitize的操作(如果没有别的,只是温和地执行它的操作)?这将以指数方式提供帮助! 最佳答案 Rails有自己的SanitizeHelper。根据http://api.rubyonrails.org/classes/ActionView/Helpers/SanitizeHelper.html,它将Thissanitizehe
操作系统:CentOS6.2x86_64很抱歉缩进太古怪了。这是我的第一篇SO帖子,我是新来设置服务器的。不过,我正在学习,并将详细说明我尝试解决此问题所采取的步骤以及寻求帮助的地方。我是一位有抱负的年轻Web开发人员,并且我在其他人配置的服务器上工作,因此,这对我来说是全新的。我正在准备我最近购买的用于运行Rails应用程序的linode。我遵循了此处http://blog.blenderbox.com/2011/01/07/installing-rvm-ruby-rails-passenger-nginx-on-centos/提供的初始安装指南,并更改了步骤:sudobash反射(
对于体育新闻中文文本的关键字提取,常用的算法包括TF-IDF、TextRank和LDA等。它们的基本步骤如下:1.TF-IDF算法: -将文本进行分词和词性标注处理。-统计每个词在文本中的词频(TF)。-计算每个词在整个语料库中出现的文档频率(DF)和逆文档频率(IDF)。-计算每个词的TF-IDF值,并按照值的大小进行排序,选择排名前几的词作为关键字。2.TextRank算法:-将文本进行分词和词性标注处理。-将分词结果转化成图模型,每个词语为节点,根据词语之间的共现关系建立边。-对图模型进行迭代计算,计算每个节点的PageRank值,表示该节点的重要性。-选择排名前几的节点作为关键字。3.
我想知道NokogiriXPath或CSS解析是否可以更快地处理HTML文件。速度有何不同? 最佳答案 Nokogiri没有XPath或CSS解析。它将XML/HTML解析为单个DOM,然后您可以使用CSS或XPath语法进行查询。CSS选择器在要求libxml2执行查询之前在内部转换为XPath。因此(对于完全相同的选择器)XPath版本会快一点点,因为CSS不需要先转换成XPath。但是,您的问题没有通用答案;这取决于您选择的是什么,以及您的XPath是什么样的。很有可能,您不会编写与Nokogiri创建的相同的XPath。例如
大家好,我叫胡飞虎,花名虎仔,目前负责云效旗下产品Codeup代码托管的设计与开发。代码作为企业最核心的数据资产,除了被构建、部署之外还有更大的价值。为了帮助企业和团队挖掘更多源代码价值以赋能日常代码研发、运维等工作,云效代码团队在大数据和智能化方向进行了一系列的探索和实践(例如代码搜索与推荐),本文主要介绍我们如何通过直接打通源代码来提高研发与运维效率。随着微服务架构的流行,一个业务流程需要多个微服务共同完成。一旦出现问题,运维人员在面对数量多、调用链路复杂的情况下,很难快速锁定导致问题发生的罪魁祸首:代码。为了提高排查效率,目前常见的解决方案是:链路跟踪+日志分析工具相结合。即通过链路跟踪
我是编程新手,但在我的应用程序中我希望某些情况显示"is"或“否”而不是“真”或“假”。我不确定最好的方法,我读过this问题,但并没有真正理解如何实现它。有人能帮我吗,最好把它放在初始化程序、帮助程序或其他地方吗?我希望能够在我希望显示是/否的任何地方调用我的View中的内容,或者创建一个自定义数据类型,在我的迁移中我可以创建类似t.boolean_yesno的内容,然后为我做的每一列它只会将true存储为yes,将false存储为no。如果有人帮助我走上正轨,我将不胜感激,我没有使用初始化器或助手的经验。谢谢! 最佳答案 语言环
这里有两个测试:if[1,2,3,4].include?2&&nil.nil?puts:helloend#=>和if[1,2,3,4].include?(2)&&nil.nil?puts:helloend#=>hello上面告诉我&&比方法参数有更高的优先级,所以它逻辑上和2&&nil.nil?是真的,并将它作为参数传递给include?但是,有这个测试:if[1,2,3,4].include?2andnil.nil?puts:helloend#=>hello所以这告诉我方法参数和“and”具有相同的优先级(或者方法参数高于“and”)因为它传递了2以包含?在处理“和”之前。注意:我知
每当我实例化一个新的ActiveRecord模型(一个尚未持久化到数据库中的模型)并尝试访问构建模型上的一些各种关联时,Rails查询构建器有时会:将(1=0)谓词添加到查询的where子句。在select语句中添加“distinct”子句。我认为这只会在has_many:through关联连接两个或多个表时发生。我想知道为什么它添加了(1=0)谓词以及distinct子句。对于(1=0)谓词,新模型是否已保存到数据库应该无关紧要(对吧?)。我不知道为什么要添加distinct子句。我在下面有一个简单的例子。classAssignment#s.assignment_attachment
VIM中是否有可能为ruby代码重复“执行和更新‘#=>’标记”TextMate功能。我想要这样的东西:x=2classAdefa42endendx#=>A.new.a#=>输入一些命令...然后得到x=2classAdefa42endendx#=>2A.new.a#=>42这是来自CiaránWalsh’sBlog的对此功能的描述:Anothertooldefinitelyworthknowingisthe"ExecuteandUpdate'#=>'Markers"command(on⌃⇧⌘Ebydefault).Touseit,addsomecommentmarkers(the