文章目录
TRIZ理论是阿奇舒勒(G. S. Altshuller)在1946年创立的,它是发明问题的解决理论,为人们创造性地发现问题和解决问题提供了系统的理论和方法工具。TRIZ理论利用矛盾矩阵,揭示创造发明的内在规律和原理,着力于澄清和强调系统中存在的矛盾,目标是完全解决矛盾,获得最终的理想解。
TRIZ解决发明问题的基本思路是:定义和描述具体问题,根据所选定的TRIZ工具或工具组合,将具体问题标准化;将标准化的具体问题抽象化;寻找抽象化问题的解决方案;将抽象化的解决方案根据具体问题转换为具体解决方案,即具体的技术创新方案。
TRIZ理论现在已经在欧美和亚洲发达的国家和地区的企业得到广泛的应用,大大提高了创新的效率。据统计,应用TRIZ理论与方法,可以增加80%—100%的专利数量并提高专利质量;可以提高60%—70%的新产品开发效率;可以缩短产品上市时间50%。
TRIZ理论引入中国也只是近十几年的事,它已经逐渐得到国内诸多科研结构、公司和专家的重视。在以TRIZ理论为核心的创新方法与技术研究应用方面,走在前列的是我国的亿维讯集团公司,他们提供的一套完整的计算机辅助创新解决方案,正在国内诸多科研院所和大型企业研究机构发挥作用,为快速提升我们国家的创新技术水平提供技术上的支持。
亿维讯集团公司用行动和成果证明了“中国需要TRIZ理论”。本项目以TRIZ理论为基础,提供了一款包含社区功能的CAI(计算机辅助创新)工具,主要面向山东省创新方法大赛选手以及数十家企业的创新工程师,目的是让没有经历过TRIZ理论培训的创新人才也能感受到TRIZ理论创新的优越之处,为创新人才提供一个分享交流想法的平台,推动TRIZ理论在省内的普及。
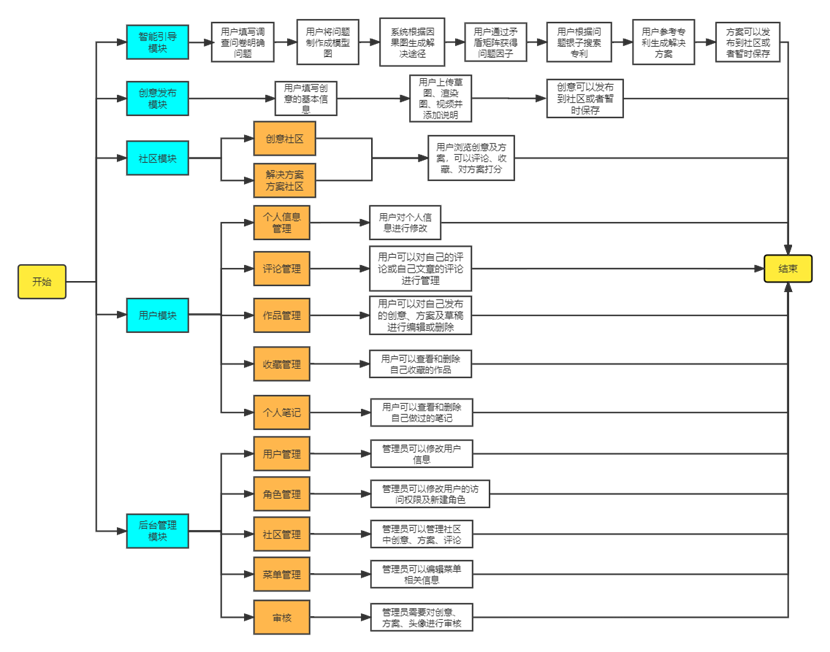
智能创新引导工具软件的系统基本操作流程如图所示:
| 条目 | 环境 |
|---|---|
| 开发的硬件环境 | (1)CPU:HexaCore Intel Core i7-9750H, 4100 MHz (41 x 100) (2)内存:32GB DDR4 (3)GPU:GTX1660Ti 6GB (4)256G SSD + 1TB HDD + 1TB SSD |
| 运行的硬件环境 | (1)CPU:HexaCore Intel Core i7-9750H, 4100 MHz (41 x 100) (2)内存:32GB DDR4 (3)GPU:GTX1660Ti 6GB (4)256G SSD + 1TB HDD + 1TB SSD |
| 开发该软件的操作系统 | Windows11 |
| 软件开发环境/开发工具 | (1)开发环境:JDK 13、Mysql 5.7.30、Redis 5.0.14、Maven 3.6.3、Node 14.15.1、Vue 2.0 (2)开发工具:IntelliJ IDEA、WebStorm |
| 该软件的运行平台/操作系统 | (1)浏览器:Google Chrome(2)操作系统:Windows11 |
| 软件运行支撑环境/支持软件 | 以Chromium(Webkit)为内核的浏览器 (如Google Chrome、MicroSoft Edge) |
| 编程语言 | Java、JavaScript |
在项目开发过程中,我们将项目分为8个阶段进行,并为每个阶段制定工作量以及里程碑。项目总体采用采用增量式开发(先开发主要功能模块,再开发次要功能模块,逐步完善,最终开发出符合需求的软件产品)的模式展开。

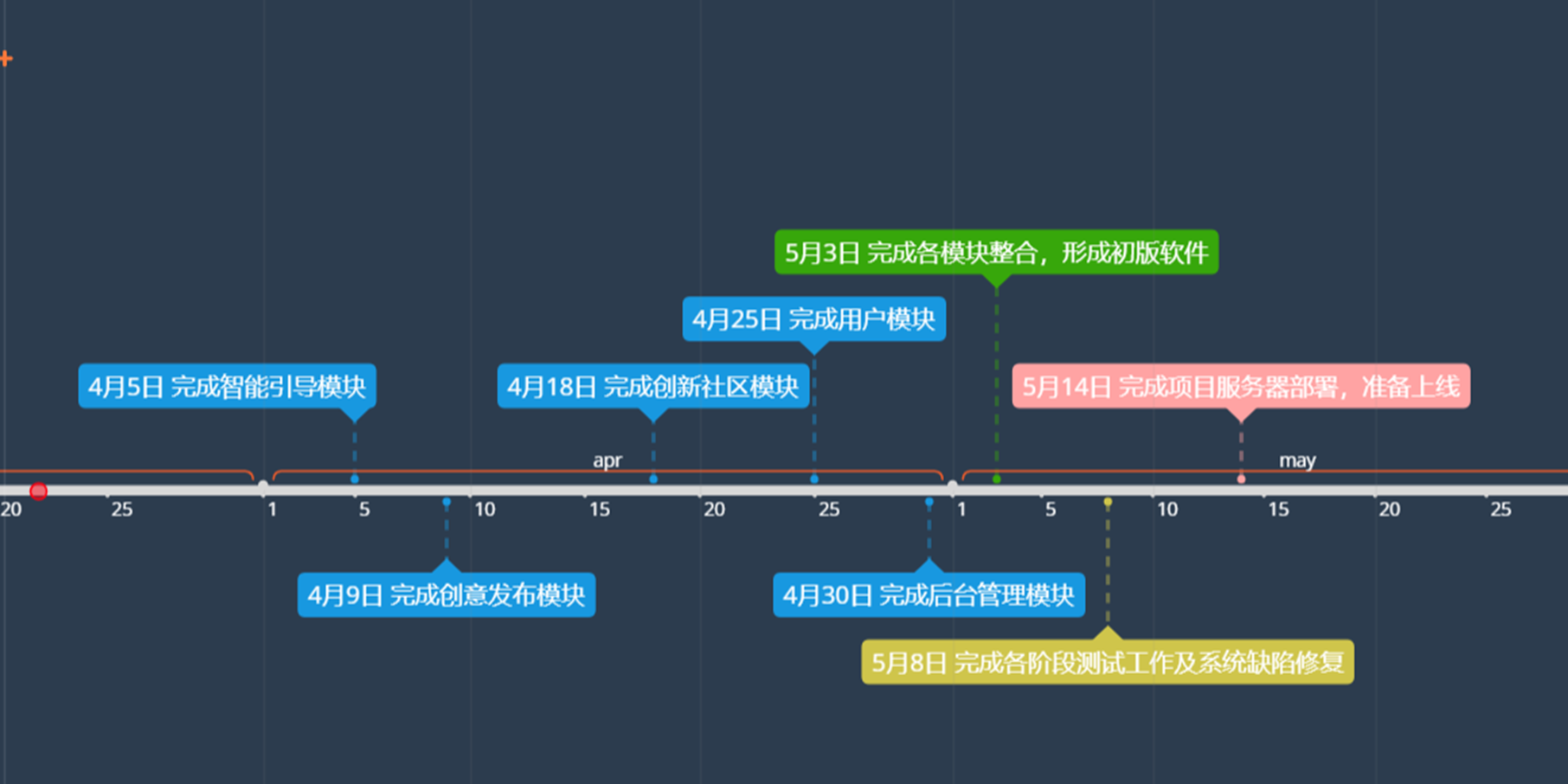
考虑到项目开发周期以及对项目规模的评估,项目的各个阶段采用Scrum敏捷开发框架(Scrum是迭代式增量软件开发过程,通常用于敏捷软件开发)进行开发。
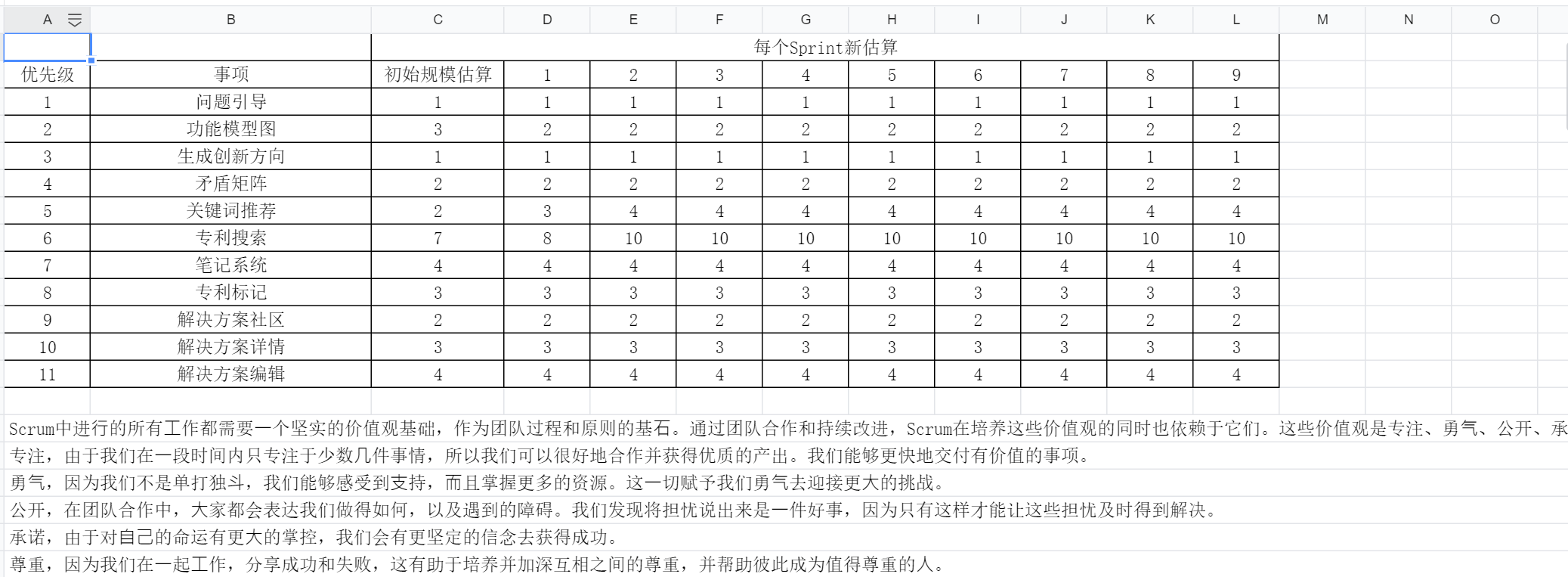
在项目开发过程中,开发团队维护两层计划:产品待办事项和Sprint待办事项。
首先产品待办事项是产品所有已知需求的优先级排序表,为了确保产品是有用的、有竞争力的,列表会不断地变化和调整。
Sprint待办事项是团队当前Sprint的任务清单。和产品待办事项不一样,它的寿命是有限的,仅在一个Sprint的时间里存活。它里面包含所有团队已承诺的以及相关联的任务。
以下是我们团队在智能引导模块开发过程中所维护的计划表:
产品待办事项:
本项目开发团队由A(负责人)、B、C、D四人组成。
每位成员工作汇总如下:
| 人员 | 工作 |
|---|---|
| A | 参与项目需求分析、设计并编写文档 前端开发:前端项目搭建 前端开发:问题引导(智能引导模块) 前端开发:搭建功能模型图绘制工具(智能引导模块) 前端开发:生成解决途径(智能引导模块) 前端开发:关键词推荐、智能专利检索及专利笔记摘录(智能引导模块) 前端开发:解决方案社区检索(方案社区模块) 前端开发:创意详情(创意社区模块) 前端开发:创意社区、解决方案社区关注、收藏功能(创意、方案社区) 前端开发:用户详情(个人模块) 前端开发:个人中心(个人模块) 前端开发:用户信息编辑、头像上传、密码修改(个人模块) 前端开发:解决方案仓库(个人模块) 前端开发:创意仓库(个人模块) 前端开发:创新引导仓库(个人模块) 前端开发:登录、注册及单点登录实现(个人模块) 前端开发:用户端消息功能(个人模块) 前端开发:创意发布模块 前端开发:基于RBAC模型实现页面访问控制 部署工作:搭建阿里云服务器环境(jdk、mysql、redis、nginx等)并完成前后端部署 项目优化:负责Gzip压缩、采用CDN方式引入组件等方式优化前端启动速度 参与项目测试工作,负责寻找软件缺陷、修复缺陷等工作 |
| B | 参与项目需求分析、设计并编写文档 制定Scrum敏捷开发计划 项目前端整体风格设计 前端开发:TRIZ矛盾矩阵 前端开发:解决方案编辑(智能引导模块) 前端开发:专利笔记系统(智能引导模块) 前端开发:创意社区检索(创意社区模块) 前端开发:解决方案详情(方案社区模块) 前端开发:创意社区、解决方案社区评论功能(创意、方案社区模块) 前端开发:网站主页设计及实现 前端开发:解决方案管理、创意管理、评论管理(管理系统模块) 前端开发:头像审核、解决方案审核、创意审核(管理系统模块) 项目优化:负责图片、字体等静态文件压缩以及相关懒加载技术实现 参与项目测试工作,负责寻找软件缺陷、修复缺陷等工作 |
| C | 参与项目需求分析、设计并编写文档 后端开发:专利搜索引擎开发 文本工作:TRIZ理论相关理论分析及总结发明原理相关关键词 后端开发:关键词推荐相关服务和接口 后端开发:关注功能实现 后端开发:用户管理、角色管理、菜单管理相关服务和接口 前端开发:用户管理、角色管理、菜单管理 部署工作:申请站点ICP域名备案 参与项目测试工作,负责寻找软件缺陷工作 |
| D | 参与项目需求分析、设计并编写文档 后端开发:后端SpringBoot项目搭建(实体层、Dao层、服务层、控制层等) 后端开发:用户实体相关服务、接口实现 后端开发:解决方案实体相关服务、接口实现 后端开发:评分系统相关服务、接口实现 后端开发:创意评论相关服务、接口实现 后端开发:解决方案评论相关服务、接口实现 后端开发:创意收藏相关服务、接口实现 后端开发:解决方案收藏相关服务、接口实现 后端开发:专利实体相关服务、接口实现 后端开发:智能引导实体相关服务、接口实现 后端开发:创意实体相关服务、接口实现 后端开发:文件系统相关服务、接口实现 后端开发:邮箱验证码相关技术实现 后端开发:数据库连接池相关技术实现 后端开发:基于JWT及token实现接口访问控制 后端开发:采用DFA算法实现敏感词处理 参与项目测试工作,负责寻找软件缺陷、修复缺陷等工作 |
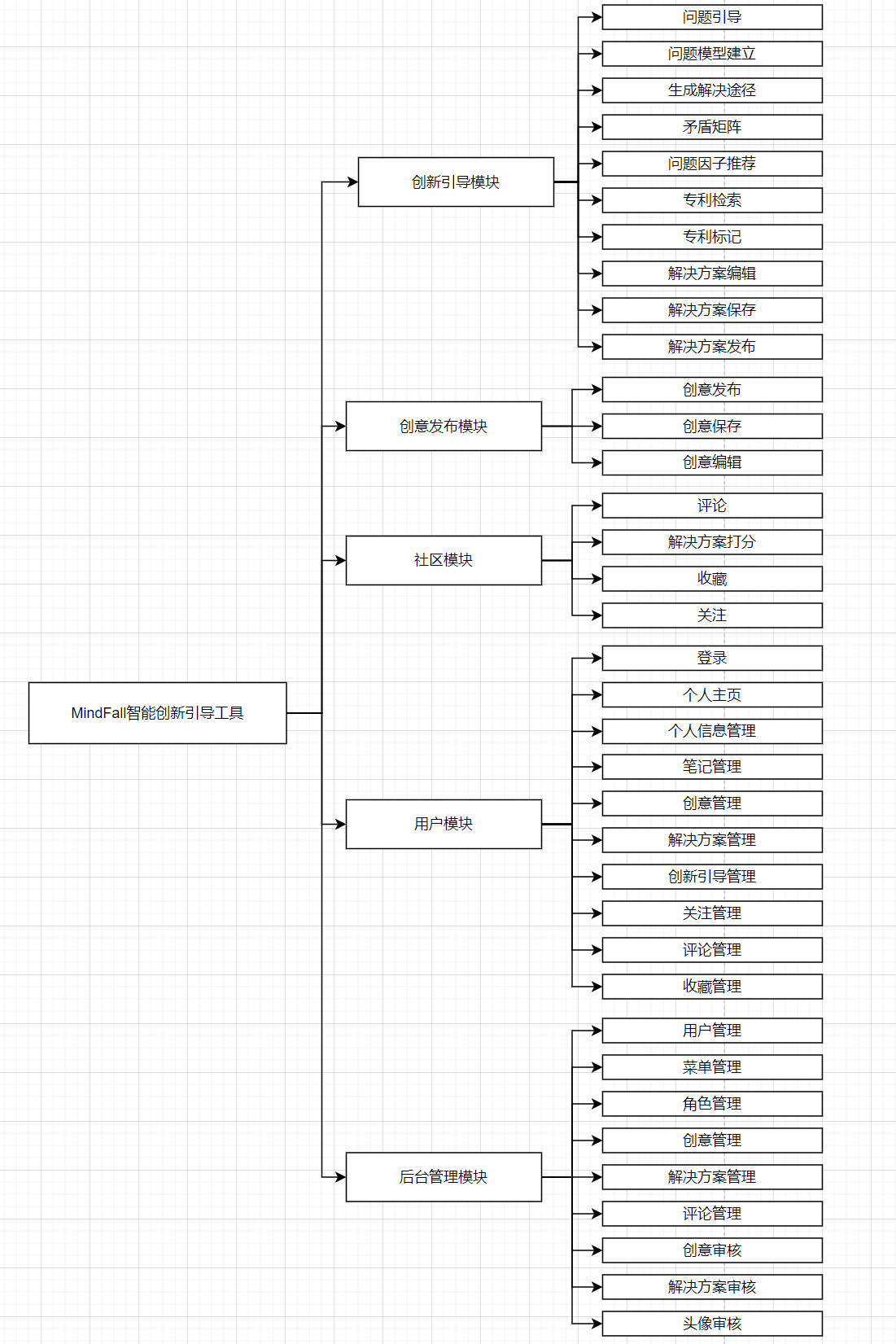
智能创新引导软件主要分为创新引导、创意发布、解决方案社区、创意社区、用户个人模块以及后台管理模块,具体模块结构及详细功能如下图:
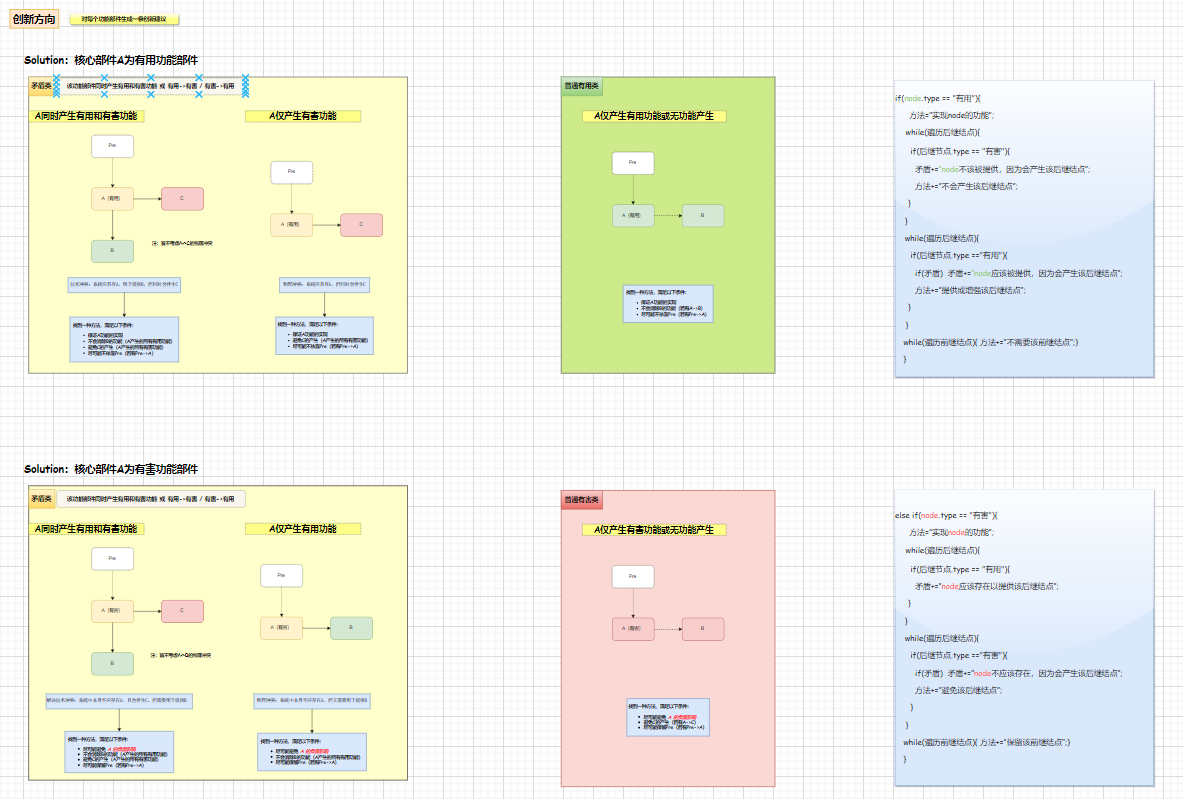
该功能主要借鉴了TRIZ理论研究中的III(Ideation International Inc)模式。根据有害和有用影响的区分,绘出问题中各部分因果关系网络图,利用软件工具对图中每一个节点能够自动列出问题的看法或者解决方法意见。每一个看法为使用者推荐了合适的传统TRIZ工具。
具体实现:
引入可视化图形布局工具,并在其基础上结合TRIZ理论实现了对于一项发明创造其关键功能、特性之间的关系图,实现对发明创造中具体问题的建模。具体功能包括新增功能/部件、编辑功能/部件、删除功能/部件、建立关联关系、删除关联关系以及其他布局显示功能。
建模完成后,可根据建模工具对每个功能/部件自动生成问题的解决途径,解决途径的生成方式参考自TRIZ理论中对于有用、有害、矛盾节点的处理思想,根据这些思想,我们整理出一套相应的解决途径生成算法。
建立索引:首先创建一个writer,并指定存放索引的目录为“/data/index”,使用分析器Analyzer进行分析,若已经有索引文件在索引目录下,将覆盖它们。然后新建一个document。
向document添加一个field,对它进行存储并索引,也可添加多个field,也是存储并索引。
然后我们将这个文档添加到索引中,如果有多个文档,可以重复上面的操作,创建document并添加。添加完所有document,我们对索引进行优化,优化主要是将多个segment合并到一个,有利于提高索引速度。随后将writer关闭。
全文检索:由于专利数据有多个属性,因此要使用多域查询,利用lucene的TermQuery进行全文检索,利用 “field:key”方式进行查询。创建一个在指定文件目录上的IndexSearcher。
然后创建一个使用StandardAnalyzer作为分析器的QueryParser,设置要搜索的域。接着用QueryParser来parse查询字串,生成一个Query。然后利用这个Query去查找结果,结果以Hits的形式返回。这个Hits对象包含一个列表,挨个把它的内容显示出来。
评分机制:此搜索引擎使用的是TF/IDF(term frequency–inverse document frequency)算法,直译为短语词频-反向文档频率算法,主要影响搜索评分的两个宏观维度为:分词出来的词频以及该词所出现的文档数(即反向文档频率)。

这个评分公式由6个部分组成:
CDN的全称是Content Delivery Network,即内容分发网络。CDN加速主要是加速静态资源,如网站上面上传的图片、媒体,以及引入的一些Js、css等文件。CDN将源站内容分发至全国所有的节点,缩短用户查看对象的延迟,提高用户访问网站的响应速度与网站的可用性,解决网络带宽小、用户访问量大、网点分布不均等问题。
使用CDN对项目静态资源进行引入,不仅可以提升网站打开速度,提升用户体验。另一方面可以在某种程度上减少黑客工具和服务器宽带压力。
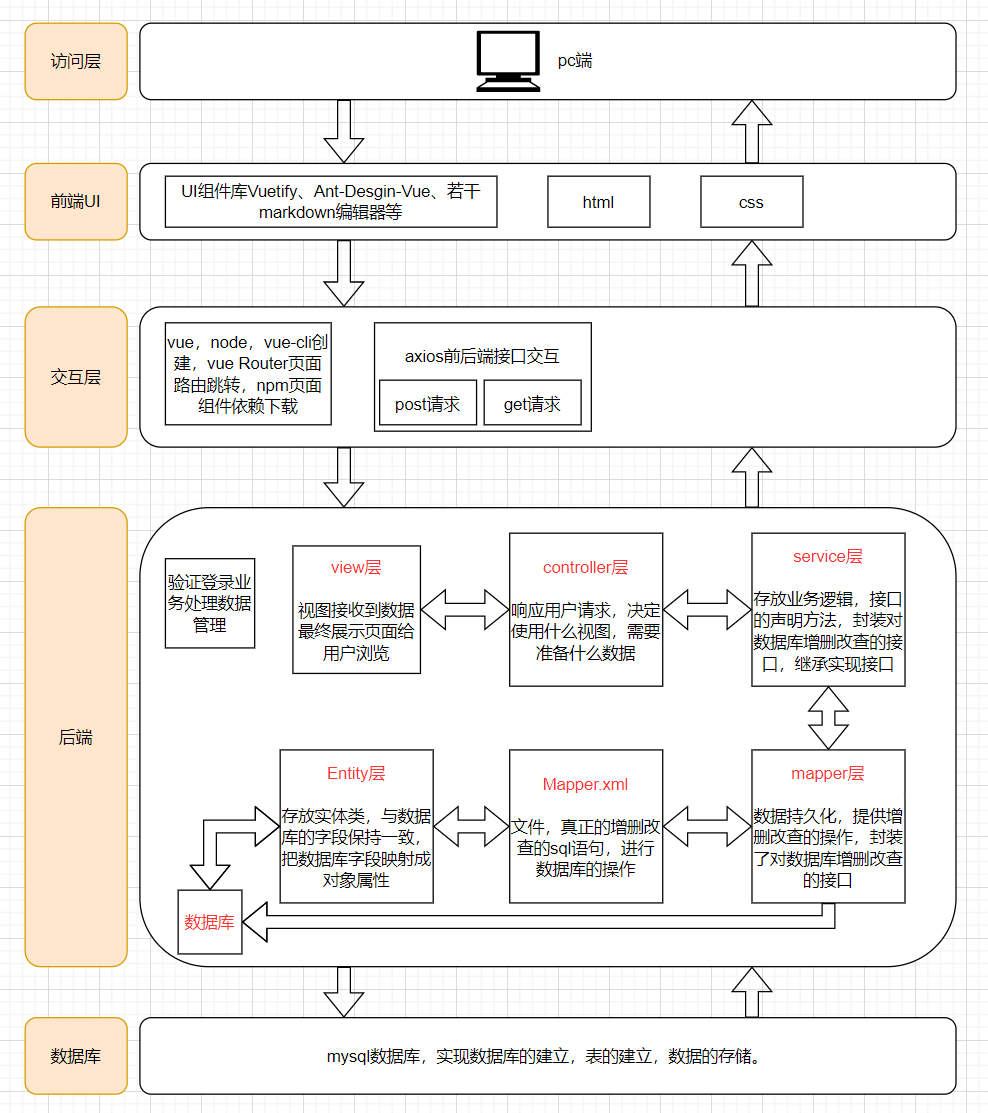
MyBatis-Plus是一个MyBatis的增强工具,支持普通 SQL查询,存储过程和高级映射的优秀持久层框架,拥有强大的CRUD操作,后端数据库操作主要通过使用Service层和Mapper层封装的crud方法,简化开发、提高效率。
Redis是高性能的非关系型数据库,基于Redis的高性能、高并发特点,将登录用户基本信息与待审核信息存放于Redis中,提高查询效率,减轻MySQL数据库的请求压力。
后端实现:导入Spring-data-redis依赖,将其封装的RedisTemplate类中的方法进行再封装为工具类RedisUtil,应用RedisUtil进行Redis数据库的操作。
JWT为带有签名信息的身份认证机制。实际应用中,在用户登录成功后会将用户的用户名信息存放在JWT的Payload中,将邮箱信息作为签名密钥生成JWT token。用户每次访问页面时,都会对其携带的JWT token进行验证。
创建敏感词过滤工具类SensitiveWordUtil,对用户编辑个人信息、发表评论时所含敏感词进行替换。
后端实现:首先创建敏感词文件,包含需要替换的敏感词,然后读取敏感词文件并创建敏感词集合,根据敏感词集合初始化敏感词容器,构建DFA算法模型,然后判断输入字符串中是否包含敏感字符,若包含敏感词,根据敏感词匹配规则获取字符串中的敏感词,最后对敏感词进行替换。
解决方案内容为MarkDown格式,前端展示内容摘要时需要纯文本格式,首先导入flexmark依赖,flexmark为MarkDown转化工具。创建Md2Text工具类,通过flexmark将MarkDowm格式转为HTML格式,再通过HTML解析器Jsoup将HTML格式转化为纯文本。
在初版开发完成后,我们选择将项目部署在阿里云服务器上,以下是资源实例的详细信息。
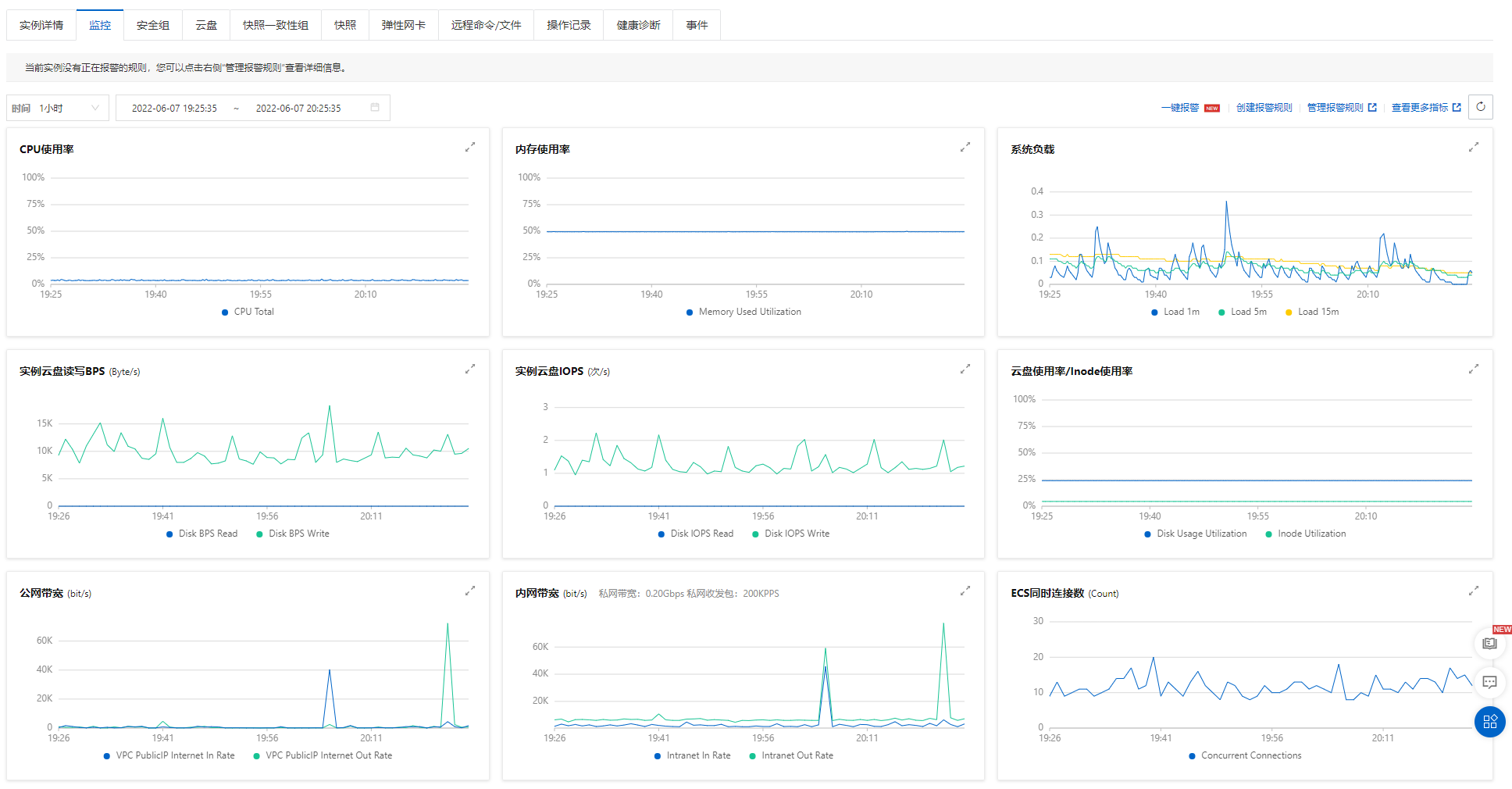
结合我们项目的前后端分离的系统架构,在部署时同样选择前后端分离的方式进行部署,即前后端使用各自的打包工具打包后上传服务器并执行。
首先在服务器上安装与项目兼容的JDK、MySQL以及Redis,并对环境变量进行相应配置。出于安全考虑,我们将MySQL和Redis的默认端口3306和6379进行了变更,同时设置了安全性较高的密码,在一定程度上防止了挖矿程序对固定端口的入侵。
完成以上配置后,将本地项目中的数据库、Redis等相关配置进行相应更改,同时重新指定文件上传功能的存放路径,以适配生产环境。然后在Maven工程选择package打包工具得到项目jar包并上传服务器。
最后在服务器上对该程序授予最高权限并选择后台运行项目。
前端项目的部署选择采用Nginx服务器进行代理。Nginx安装完成后,对配置文件进行编辑,设定部署端口为80,将Vue本地打包后的项目挂载到服务器根目录下,并设定后端代理端口。
站点通过ICP域名备案并申请得到SSL证书后,对Nginx服务器中SSL相关的内容进行配置。在nginx.conf中重新选择部署端口为443,并挂载SSL公钥及密钥。同时设定端口转发:
以上是项目部署的关键流程,具体部署过程在个人博客及相关部署文档已详细说明。
在模块整合完成后,项目进入测试阶段。团队分别就模块测试和项目总体测试两个阶段对项目展开测试。在测试过程中先采用黑盒测试的方法对站点各功能模块进行测试,查找软件缺陷;发现问题后,对具体源代码采用白盒测试的形式进行查找缺陷并修复问题。
以下是项目在测试过程中发现的部分较为重要的缺陷及修复记录。
| 缺陷 | 修复记录 |
|---|---|
| 所有输入框输入全空格可以通过 | 对部分输入框添加判断:如果输入内容全为空格,则不予通过 |
| 首次进入问卷页面和刷新问卷页面会触发表单输入规则验证 | 只在输入完成和提交表单时触发表单输入规则验证,其他情况清除验证信息 |
| 引导流程的顶部图片在部分型号的电脑上出现不居中的情况 | 修改布局,设置图片按照栅格布局居中 |
| 部件名称输入框前的不可修改输入框在部分情况下可以修改 | 更换输入框组件 |
| 功能模型图页面显示按钮组初始值不合理 | 调整了显示按钮组顺序,设置默认选中ALL按钮 |
| 建模工具说明的关闭按钮在左上角,不符合PC端的操作习惯 | 将建模工具说明的关闭按钮调整到右上角 |
| 绘制功能模型图页面在部分型号的电脑上出现左右卡片不等高的情况 | 修改高度单位,由px改为vh |
| 自动滚动功能在部分浏览器中会出现滚动位置不准确的情况 | 将自动滚动方式由按距离滚动改为按目标滚动 |
| 解决途径第一行的选择按钮可能出现换行的情况 | 修改布局,限制功能/部件的名称长度不超过8 |
| 解决途径卡片中的发明原理可能出现换行的情况 | 调整发明原理字号为13px |
| 解决途径卡片部分的引导不明确 | 更换解决途径标题部件,添加聚焦时显示的区域介绍 |
| 搜索框关键词更改后翻页触发更改后的关键词搜索 | 添加搜索关键词备份,只有在点击搜索按钮时更新关键词备份 |
| 专利详情的关闭按钮在左上角,不符合PC端的操作习惯,笔记摘录按钮不明显 | 将专利详情的关闭按钮调整到右上角,笔记摘录按钮置于其左侧 |
| 解决方案编辑页面的笔记列表浮在导航栏上层 | 修改笔记列表z-index |
| 解决方案编辑页面的富文本编辑器全屏后显示异常 | 去除工具栏的全屏按钮 |
| 发布解决方案缺少提示 | 添加发布成功对话框,3秒后跳转到解决方案 |
| 提交过大功能模型图出现请求头过大的问题 | 后端配置文件添加max-http-header-size: 2MB |
| 解决途径过长会出现被发明原理盖住的问题 | 设置解决途径过长时滚动查看 |
| 选择解决途径进入智能专利搜索,再返回重新选择解决途径,智能专利搜索页面的解决途径未发生变化,刷新后正常 | 取消当前页面使用keep-alive进行页面缓存后激活时加载解决途径的前后端交互 |
| 点击问题因子推荐后已选择的关键词变为未选择,但是关键词输入区域未清除 | 实时监听关键词选择组件,并实现实时动态变化已选关键词 |
| 输入邮箱获得验证码时间较长 | 更改验证码发送邮箱,采用465端口以及ssl通讯机制发送邮箱 |
| 如果收藏的解决方案或创意已被删除,则无法取消收藏 | 个人中心的收藏夹中添加取消收藏操作 |
| 个人笔记页面部分专利链接为空 | 研究专利链接组成结构,利用SQL操作补充空白专利链接 |
| 个人笔记页面富文本编辑器自动聚焦 | 取消创建编辑器时的自动聚焦选项 |
| 切换笔记时未保存的部分直接消失,对用户不友好 | 切换笔记时检查用户是否修改笔记,提示用户保存笔记 |
智能创新引导软件项目在未来的推广和用户接入方面,会借助智能化创新方法推广平台(与我们项目相关联的另一项目,主要对接省内企业和创新服务商)进行。因此,我们在登录、注册方面以及解决方案数据共享方面与创新推广平台进行了对接。
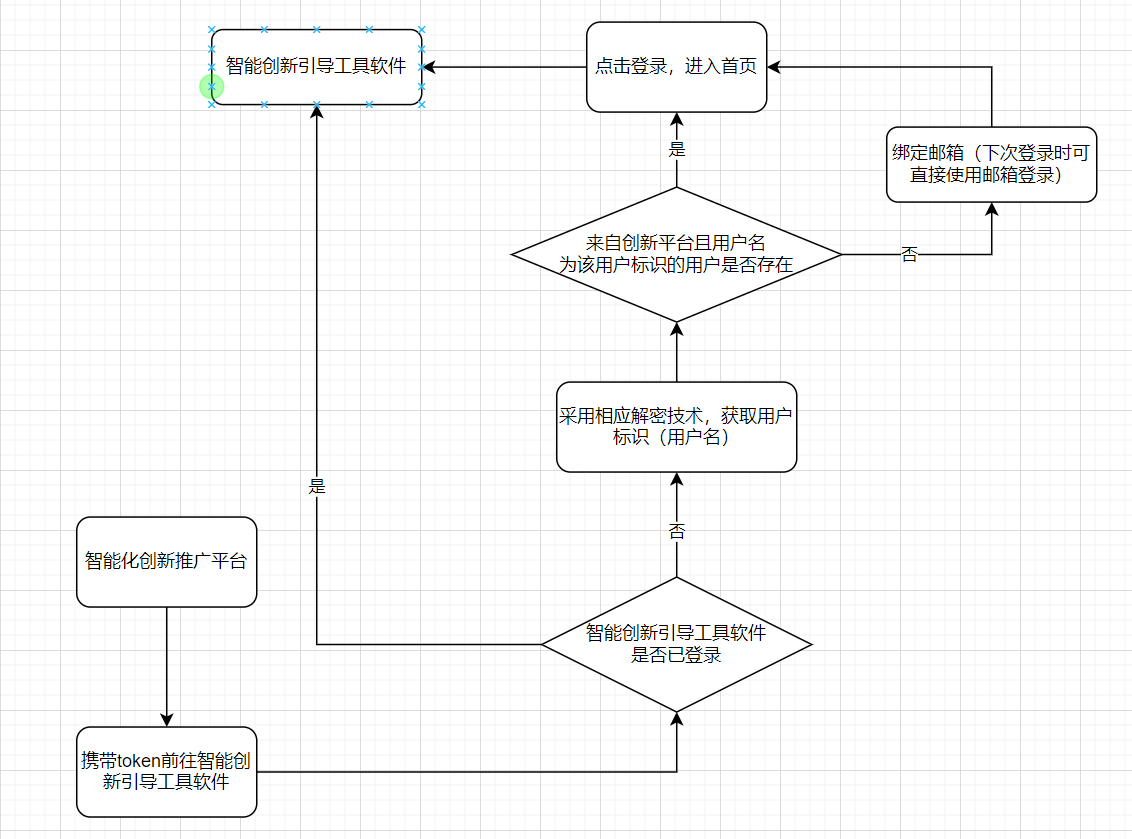
在登录功能上,我们加入了来自创新推广平台的第三方登录,采用将创新推广平台作为类似微信、支付宝等的第三方认证中心,跳转进行身份认证,认证成功后获取相应token并解析用户标识。
获取用户标识后,将该用户信息添加上来自第三方登录的专属标识,并与智能创新引导工具软件的用户数据进行比对,判断该用户是否已绑定邮箱。若该用户第一次使用该登录形式,则要求必须进行邮箱绑定,以避免该用户每次登录时都进行跳转验证。
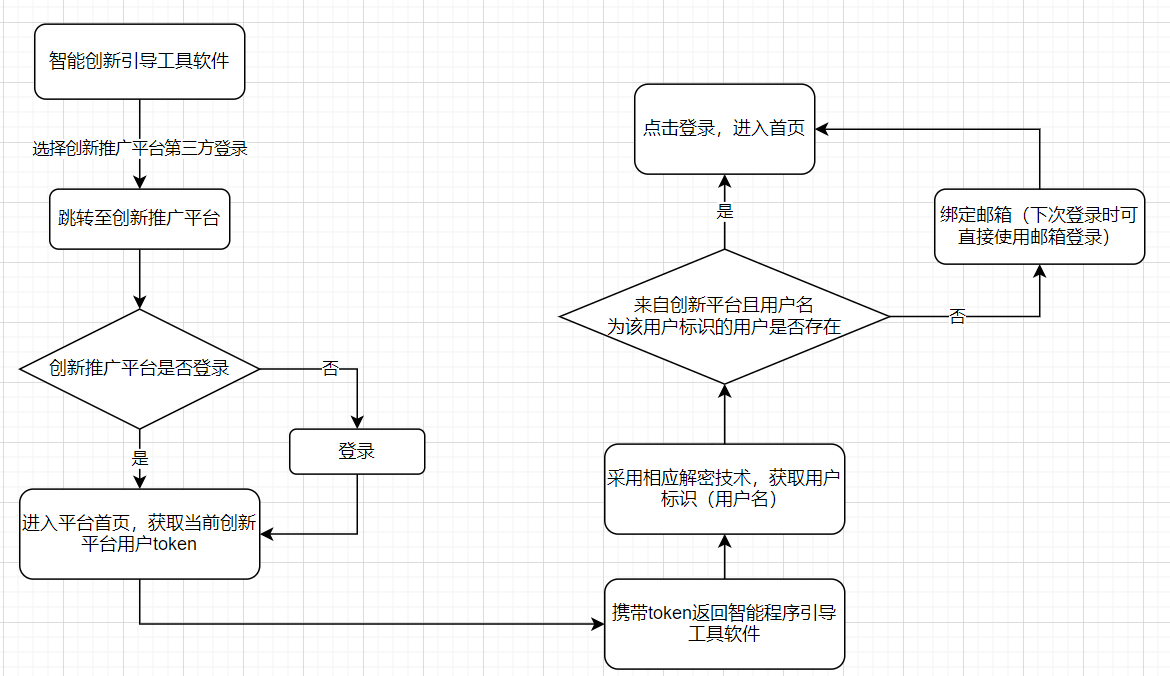
另一方面,在创新推广平台中也编写了前往智能创新引导工具软件的入口,跳转后的执行逻辑如下:
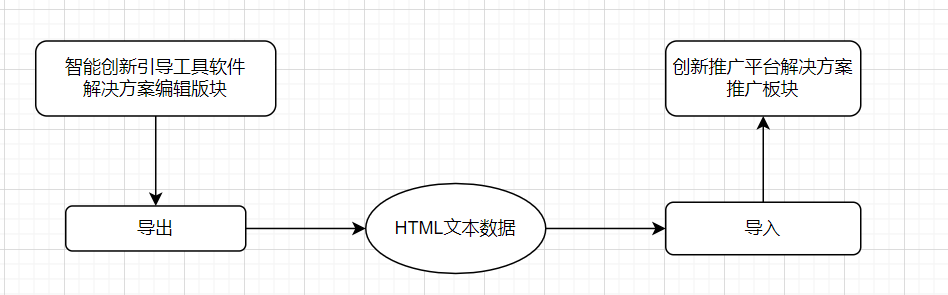
来自创新推广平台的创新工程师以及创新服务商将使主要用项目的智能创新引导模块进行辅助发明创造,在最终生成解决方案时,我们提供了数据的导出功能,将解决方案内容(Markdown语法,可能包含文字、图片、排版、超链接、表格等富文本)生成HTML文件,并使其在创新推广平台的方案推广中能够正确导入。
目前,智能化创新方法推广平台已经有济南数十家企业的用户数据,这些企业的 创新工程师将作为我们用户主体的一部分;同时,指导老师已联系省科协达成合作,将我们的网站推广到由省科协举办的山东省创新方法大赛,大赛的参赛选手也将作为我们用户主体的一部分(目前省科协方面正在进行对接测试阶段)。
| 编号 | 文档名称 | 最终修改日期 |
|---|---|---|
| 1 | 《项目实训申请表——智能创新引导工具软件》 | 2022/2/24 |
| 2 | 《参考自IWB4.0的方案解决引导方案》 | 2022/3/8 |
| 3 | 《工作汇报会议记录文档(一)》 | 2022/3/12 |
| 4 | 《工作汇报会议记录文档(二)》 | 2022/3/12 |
| 5 | 《智能创新引导工具软件——需求设计文档》 | 2022/3/21 |
| 6 | 《创新引导数据流程设计文档》 | 2022/3/26 |
| 7 | 《创新引导模块完成情况汇报》 | 2022/4/6 |
| 8 | 《创意模块完成情况汇报》 | 2022/4/9 |
| 9 | 《Redis缓存应用场景设计文档》 | 2022/4/10 |
| 10 | 《创意模块基本流程设计文档》 | 2022/4/12 |
| 11 | 《评论、社区功能整改记录文档》 | 2022/5/10 |
| 12 | 《MindFall智能创新引导工具软件V1.0-软件著作权登记申请表》 | 2022/5/16 |
| 13 | 《MindFall智能创新引导工具软件V1.0-操作手册》 | 2022/5/17 |
| 14 | 《MindFall智能创新引导工具软件V1.0-源代码》 | 2022/5/17 |
| 15 | 《测试记录文档》 | 2022/5/21 |
| 16 | 《Scrum敏捷开发文档》 | 2022/5/22 |
| 17 | 《智能创新引导工具软件-项目变更说明表》 | 2022/5/27 |
目前,项目已通过ICP域名备案并申请了为期一年的SSL安全证书。

网站网址为:https://www.mindfall.cn
同时,站点也已被部分搜索引擎收录,在搜索引擎中搜索“MindFall”或“智能创新引导工具”等相关关键词即可访问网站。

由于目前的用户量有限,而专利库的数据量庞大,在专利检索时仅以关键词作为检索依据,搜索结果过于庞大和分散,用户难以搜索到最符合心理预期或最有价值的结果,导致难以得出最佳的解决方案。另一方面,由于匹配结果数量过于庞大,效率方面有一定的提升空间。
建立知识库,在用户量到达一定值的时候,利用根据用户推荐算法和对专利库进行聚类分析等机器学习与数据挖掘知识建立知识库,使信息和知识有序化加快知识和信息的流动,有利于知识共享与交流以及实现组织的协作与沟通。
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我在我的Rails项目中使用Pow和powifygem。现在我尝试升级我的ruby版本(从1.9.3到2.0.0,我使用RVM)当我切换ruby版本、安装所有gem依赖项时,我通过运行railss并访问localhost:3000确保该应用程序正常运行以前,我通过使用pow访问http://my_app.dev来浏览我的应用程序。升级后,由于错误Bundler::RubyVersionMismatch:YourRubyversionis1.9.3,butyourGemfilespecified2.0.0,此url不起作用我尝试过的:重新创建pow应用程序重启pow服务器更新战俘
我已经像这样安装了一个新的Rails项目:$railsnewsite它执行并到达:bundleinstall但是当它似乎尝试安装依赖项时我得到了这个错误Gem::Ext::BuildError:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcheckingforlibkern/OSAtomic.h...yescreatingMakefilemake"DESTDIR="cleanmake"DESTDIR="
假设我有这个范围:("aaaaa".."zzzzz")如何在不事先/每次生成整个项目的情况下从范围中获取第N个项目? 最佳答案 一种快速简便的方法:("aaaaa".."zzzzz").first(42).last#==>"aaabp"如果出于某种原因你不得不一遍又一遍地这样做,或者如果你需要避免为前N个元素构建中间数组,你可以这样写:moduleEnumerabledefskip(n)returnto_enum:skip,nunlessblock_given?each_with_indexdo|item,index|yieldit
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
Ⅰ软件测试基础一、软件测试基础理论1、软件测试的必要性所有的产品或者服务上线都需要测试2、测试的发展过程3、什么是软件测试找bug,发现缺陷4、测试的定义使用人工或自动的手段来运行或者测试某个系统的过程。目的在于检测它是否满足规定的需求。弄清预期结果和实际结果的差别。5、测试的目的以最小的人力、物力和时间找出软件中潜在的错误和缺陷6、测试的原则28原则:20%的主要功能要重点测(eg:支付宝的支付功能,其他功能都是次要的)80%的错误存在于20%的代码中7、测试标准8、测试的基本要求功能测试性能测试安全性测试兼容性测试易用性测试外观界面测试可靠性测试二、质量模型衡量一个优秀软件的维度①功能性功
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手