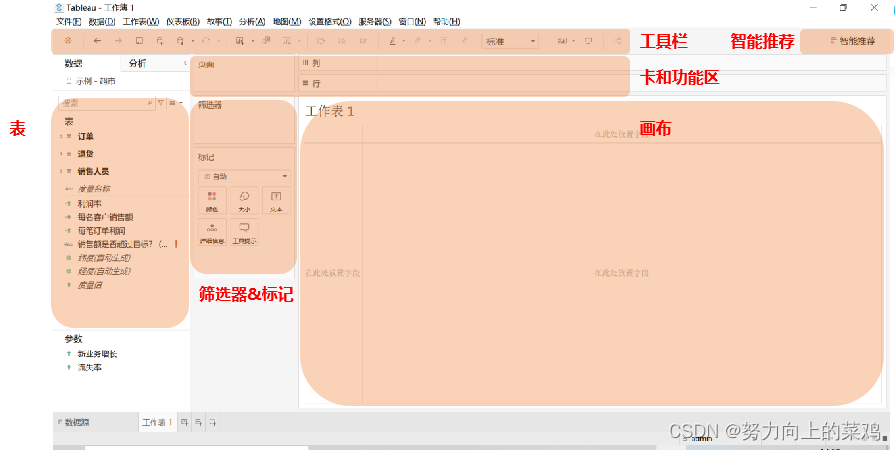
Tableau基础操作——界面简介及功能介绍
Tableau基础操作——界面简介及功能介绍
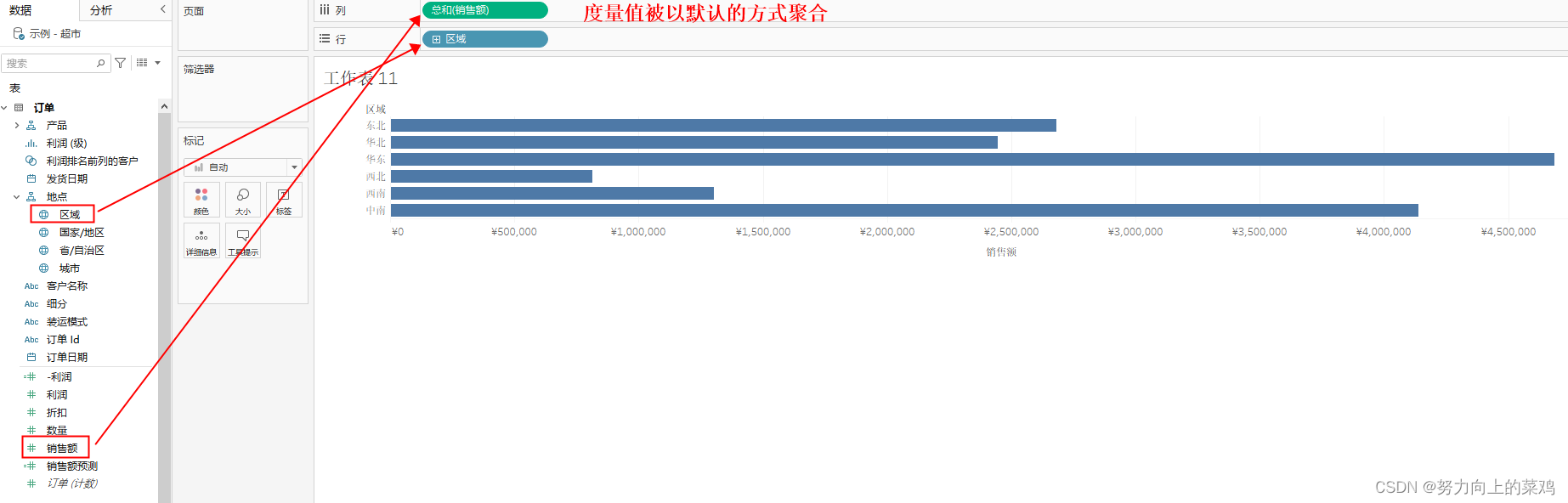
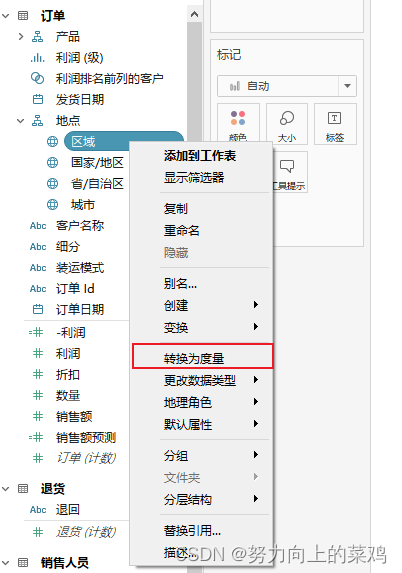
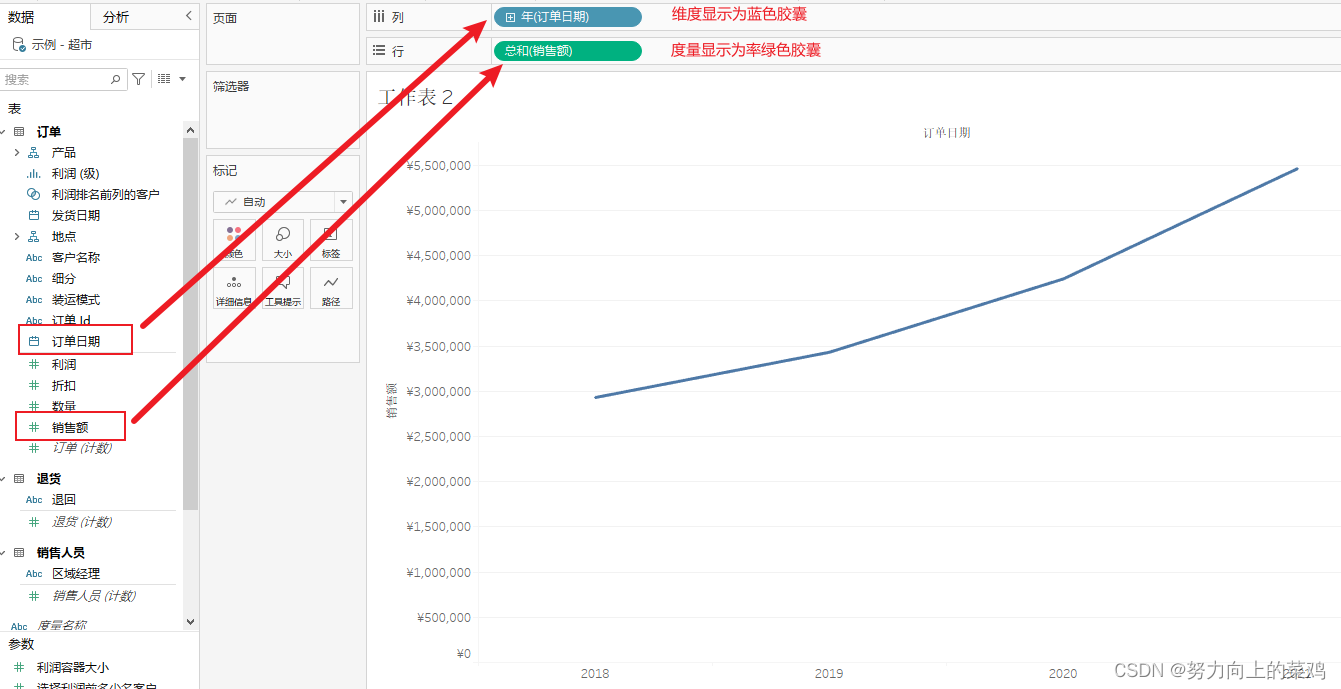
数据源中的字段都有一种数据类型,反应该字段的存储信息的种类,比如整数、日期和字符串

以上就是今天要讲的内容,本文仅仅简单介绍了Tableau的部分功能和界面指导内容,后续将会就Tableau的绘图及字段操作进行详细更新,欢迎点赞收藏,笔芯。
只是想确保我理解了事情。据我目前收集到的信息,Cucumber只是一个“包装器”,或者是一种通过将事物分类为功能和步骤来组织测试的好方法,其中实际的单元测试处于步骤阶段。它允许您根据事物的工作方式组织您的测试。对吗? 最佳答案 有点。它是一种组织测试的方式,但不仅如此。它的行为就像最初的Rails集成测试一样,但更易于使用。这里最大的好处是您的session在整个Scenario中保持透明。关于Cucumber的另一件事是您(应该)从使用您的代码的浏览器或客户端的角度进行测试。如果您愿意,您可以使用步骤来构建对象和设置状态,但通常您
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
Ⅰ软件测试基础一、软件测试基础理论1、软件测试的必要性所有的产品或者服务上线都需要测试2、测试的发展过程3、什么是软件测试找bug,发现缺陷4、测试的定义使用人工或自动的手段来运行或者测试某个系统的过程。目的在于检测它是否满足规定的需求。弄清预期结果和实际结果的差别。5、测试的目的以最小的人力、物力和时间找出软件中潜在的错误和缺陷6、测试的原则28原则:20%的主要功能要重点测(eg:支付宝的支付功能,其他功能都是次要的)80%的错误存在于20%的代码中7、测试标准8、测试的基本要求功能测试性能测试安全性测试兼容性测试易用性测试外观界面测试可靠性测试二、质量模型衡量一个优秀软件的维度①功能性功
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
Region是HBase数据管理的基本单位,region有一点像关系型数据的分区。region中存储这用户的真实数据,而为了管理这些数据,HBase使用了RegionSever来管理region。Region的结构hbaseregion的大小设置默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分。刚拆分时,两个子Region都位于当前的RegionServer,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的RegionServer。RegionSplit时机:当1个region中的某个Store下所有StoreFile
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption
我正在我的Rails项目中安装Grape以构建RESTfulAPI。现在一些端点的操作需要身份验证,而另一些则不需要身份验证。例如,我有users端点,看起来像这样:moduleBackendmoduleV1classUsers现在如您所见,除了password/forget之外的所有操作都需要用户登录/验证。创建一个新的端点也没有意义,比如passwords并且只是删除password/forget从逻辑上讲,这个端点应该与用户资源。问题是Grapebefore过滤器没有像except,only这样的选项,我可以在其中说对某些操作应用过滤器。您通常如何干净利落地处理这种情况?
在我做的一些网络开发中,我有多个操作开始,比如对外部API的GET请求,我希望它们同时开始,因为一个不依赖另一个的结果。我希望事情能够在后台运行。我找到了concurrent-rubylibrary这似乎运作良好。通过将其混合到您创建的类中,该类的方法具有在后台线程上运行的异步版本。这导致我编写如下代码,其中FirstAsyncWorker和SecondAsyncWorker是我编写的类,我在其中混合了Concurrent::Async模块,并编写了一个名为“work”的方法来发送HTTP请求:defindexop1_result=FirstAsyncWorker.new.async.
a=[3,4,7,8,3]b=[5,3,6,8,3]假设数组长度相同,是否有办法使用each或其他一些惯用方法从两个数组的每个元素中获取结果?不使用计数器?例如获取每个元素的乘积:[15,12,42,64,9](0..a.count-1).eachdo|i|太丑了...ruby1.9.3 最佳答案 使用Array.zip怎么样?:>>a=[3,4,7,8,3]=>[3,4,7,8,3]>>b=[5,3,6,8,3]=>[5,3,6,8,3]>>c=[]=>[]>>a.zip(b)do|i,j|c[[3,5],[4,3],[7,6],