弟弟最近要考试,临时抱佛脚在网上找了一堆学习资料复习,这不刚就来找我了,说PDF上有水印,影响阅读效果,到时候考不好就怪资料不行,气的我差点当场想把他揍一顿!

算了,弟弟长大了,看在打不过他的份上,就不打他了~

稍加思索,我想起了Python不是可以去水印?说搞就搞!
去除方法:
因为pfd文档无法直接去除水印,需要先将pfd文档转换成图片,在逐一对图片进行水印去除操作,最后在把图片插入到pdf文档中。
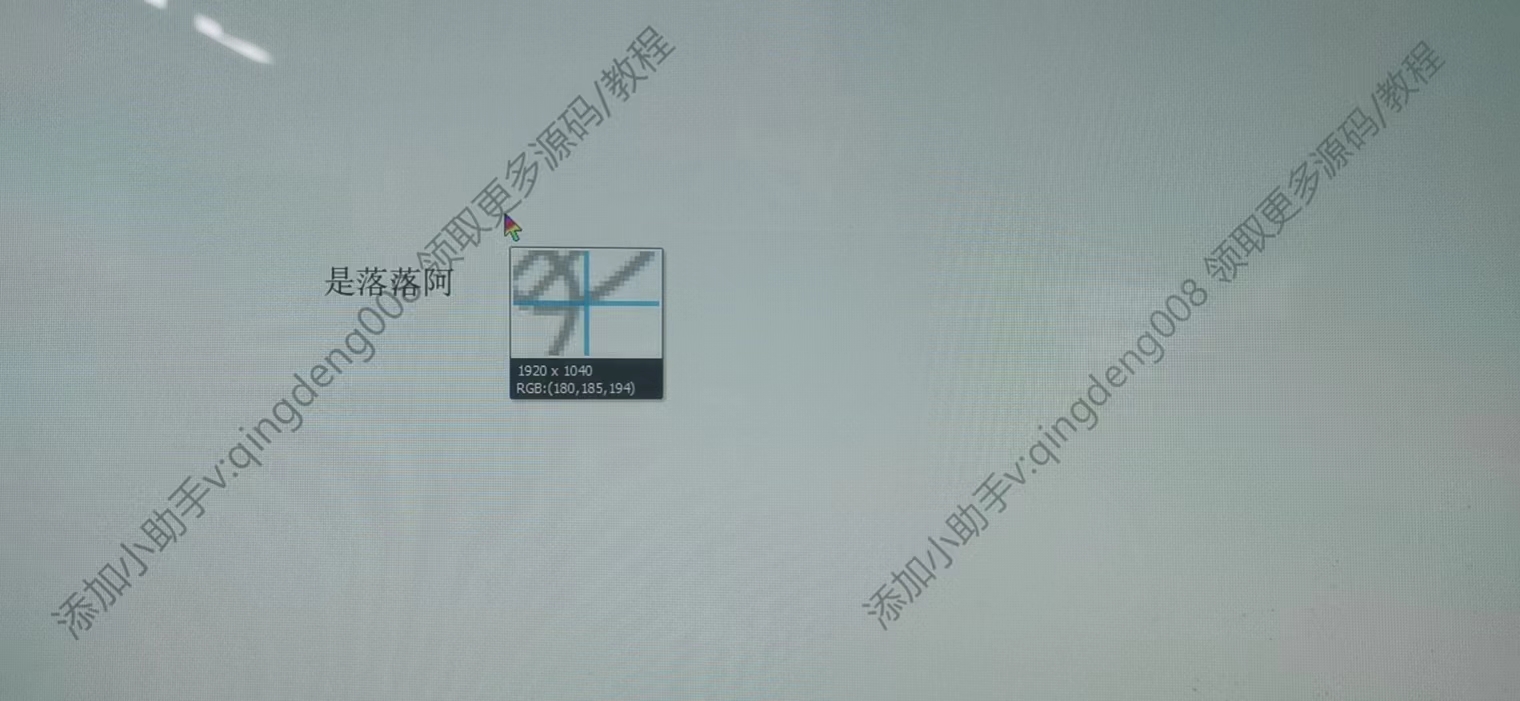
可以看到,RGB(179,179,179),因为这里要的是RGB色值总和,所以我们就认为,超过510,就认为是水印。
敲黑板
光学三原色是红绿蓝(RGB),也就是说它们是不可分解的三种基本颜色,其他颜色都可以通过这三种颜色混合而成,三种颜色等比例混合就是白色,没有光就是黑色。
在计算机中,可以用三个字节表示 RGB 颜色,1个字节能表示的最大数值是 255, 所以,(255, 0, 0)代表红色,(0, 255, 0)代表绿色,(0, 0, 255)代表蓝色。相应地,(255, 255, 255)代表白色,(0, 0, 0)代表黑色。从(0, 0, 0) ~ (255, 255, 255) 之间的任意组合都可以代表一个不同的颜色。
图片每个位置颜色由四元组表示,前三位分别是 RGB,第四位是 Alpha 通道。
代码示例:
from PIL import Image
from itertools import product
import fitz
# Python学习交流群:708525271
# 去除pdf的水印
def remove_pdfwatermark():
#打开源pfd文件
pdf_file = fitz.open("源码找落落阿.pdf")
#page_no 设置为0
page_no = 0
#page在pdf文件中遍历
for page in pdf_file:
#获取每一页对应的图片pix (pix对象类似于我们上面看到的img对象,可以读取、修改它的 RGB)
#page.get_pixmap() 这个操作是不可逆的,即能够实现从 PDF 到图片的转换,但修改图片 RGB 后无法应用到 PDF 上,只能输出为图片
pix = page.get_pixmap()
#遍历图片中的宽和高,如果像素的rgb值总和大于510,就认为是水印,转换成255,255,255-->即白色
for pos in product(range(pix.width), range(pix.height)):
if sum(pix.pixel(pos[0], pos[1])) >= 510:
pix.set_pixel(pos[0], pos[1], (255, 255, 255))
#保存去掉水印的截图
pix.pil_save(f"./{page_no}.png", dpi=(30000, 30000))
#打印结果
print(f'第 {page_no} 页去除完成')
page_no += 1
if __name__ == '__main__':
remove_pdfwatermark()
执行完成
查看生成图片:

查看图片内容

代码示例:
from PIL import Image
from itertools import product
import fitz
''' 图片转为pdf'''
#图片所在的文件夹
pic_dir = 'F:\123'
pdf = fitz.open()
#图片数字文件先转换成int类型进行排序
img_files = sorted(os.listdir(pic_dir), key=lambda x: int(str(x).split('.')[0]))
for img in img_files:
print(img)
imgdoc = fitz.open(pic_dir + '/' + img)
#将打开后的图片转成单页pdf
pdfbytes = imgdoc.convertToPDF()
imgpdf = fitz.open("pdf", pdfbytes)
#将单页pdf插入到新的pdf文档中
pdf.insertPDF(imgpdf)
pdf.save("源码找落落阿_完成.pdf")
pdf.close()
执行代码
查看生成的pdf文档
上面的内容都了解以后,我们就整合代码,直接运行就可以了。
from PIL import Image
from itertools import product
import fitz
# 去除pdf的水印
def remove_pdfwatermark():
# 打开源pfd文件
pdf_file = fitz.open("源码找落落阿.pdf")
# page_no 设置为0
page_no = 0
# page在pdf文件中遍历
for page in pdf_file:
# 获取每一页对应的图片pix (pix对象类似于我们上面看到的img对象,可以读取、修改它的 RGB)
# page.get_pixmap() 这个操作是不可逆的,即能够实现从 PDF 到图片的转换,但修改图片 RGB 后无法应用到 PDF 上,只能输出为图片
pix = page.get_pixmap()
# 遍历图片中的宽和高,如果像素的rgb值总和大于510,就认为是水印,转换成255,255,255-->即白色
for pos in product(range(pix.width), range(pix.height)):
if sum(pix.pixel(pos[0], pos[1])) >= 510:
pix.set_pixel(pos[0], pos[1], (255, 255, 255))
# 保存去掉水印的截图
pix.pil_save(f"./{page_no}.png", dpi=(30000, 30000))
# 打印结果
print(f'第 {page_no} 页去除完成')
page_no += 1
# 去除的pdf水印添加到pdf文件中
def pictopdf():
# 水印截图所在的文件夹
# pic_dir = input("请输入图片文件夹路径:")
pic_dir = 'F:\123'
pdf = fitz.open()
# 图片数字文件先转换成int类型进行排序
img_files = sorted(os.listdir(pic_dir), key=lambda x: int(str(x).split('.')[0]))
for img in img_files:
print(img)
imgdoc = fitz.open(pic_dir + '/' + img)
# 将打开后的图片转成单页pdf
pdfbytes = imgdoc.convertToPDF()
imgpdf = fitz.open("pdf", pdfbytes)
# 将单页pdf插入到新的pdf文档中
pdf.insertPDF(imgpdf)
pdf.save("源码找落落阿_完成.pdf")
pdf.close()
if __name__ == '__main__':
remove_pdfwatermark()
pictopdf()
# 兄弟们学习python,有时候不知道怎么学,从哪里开始学。掌握了基本的一些语法或者做了两个案例后,不知道下一步怎么走,不知道如何去学习更加高深的知识。
# 那么对于这些大兄弟们,我准备了大量的免费视频教程,PDF电子书籍,以及源代码!
# 直接在这个抠裙 708525271 自取即可~
需要理解的流程是:
写到这里,今天的分享就差不多快结束了,咱们下次再见!
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
有没有办法在这个简单的get方法中添加超时选项?我正在使用法拉第3.3。Faraday.get(url)四处寻找,我只能先发起连接后应用超时选项,然后应用超时选项。或者有什么简单的方法?这就是我现在正在做的:conn=Faraday.newresponse=conn.getdo|req|req.urlurlreq.options.timeout=2#2secondsend 最佳答案 试试这个:conn=Faraday.newdo|conn|conn.options.timeout=20endresponse=conn.get(url
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
我需要一个表,其中行实际上是2行表,一个嵌套表是..我怎样才能在Prawn中做到这一点?也许我需要延期..但哪一个? 最佳答案 现在支持子表:Prawn::Document.generate("subtable.pdf")do|pdf|subtable=pdf.make_table([["sub"],["table"]])pdf.table([[subtable,"original"]])end 关于ruby-on-rails-PrawnPDF:Ineedtogeneratenested
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
我意识到这可能是一个非常基本的问题,但我现在已经花了几天时间回过头来解决这个问题,但出于某种原因,Google就是没有帮助我。(我认为部分问题在于我是一个初学者,我不知道该问什么......)我也看过O'Reilly的RubyCookbook和RailsAPI,但我仍然停留在这个问题上.我找到了一些关于多态关系的信息,但它似乎不是我需要的(尽管如果我错了请告诉我)。我正在尝试调整MichaelHartl'stutorial创建一个包含用户、文章和评论的博客应用程序(不使用脚手架)。我希望评论既属于用户又属于文章。我的主要问题是:我不知道如何将当前文章的ID放入评论Controller。