目录
基于哈希表的 Map 接口的实现。此实现提供所有可选的映射操作,并允许使用 null 值和 null 键。(除了非同步和允许使用 null 之外,HashMap 类与 Hashtable 大致相同。)此类不保证映射的顺序,特别是它不保证该顺序恒久不变。 此实现假定哈希函数将元素适当地分布在各桶之间,可为基本操作(get 和 put)提供稳定的性能。迭代 collection 视图所需的时间与 HashMap 实例的“容量”(桶的数量)及其大小(键-值映射关系数)成比例。所以,如果迭代性能很重要,则不要将初始容量设置得太高(或将加载因子设置得太低)。
HashMap是数组加链表组成的复合结构,HashMap的主干是数组,其中数组被分为一个个桶(bucket),每个桶存储有一个或多个键值对,每个键值对也称为 Entry ,通过哈希值决定了Entry对象在这个数组的下标;哈希值相同的Entry对象(键值对),则以链表形式存储。
是不是很不好理解?没事咱们画亿个图来解释。
当我们new了一个HashMap对象时,并且往HashMap中传入了三个键值对(Entry)时,其结构大致如下:
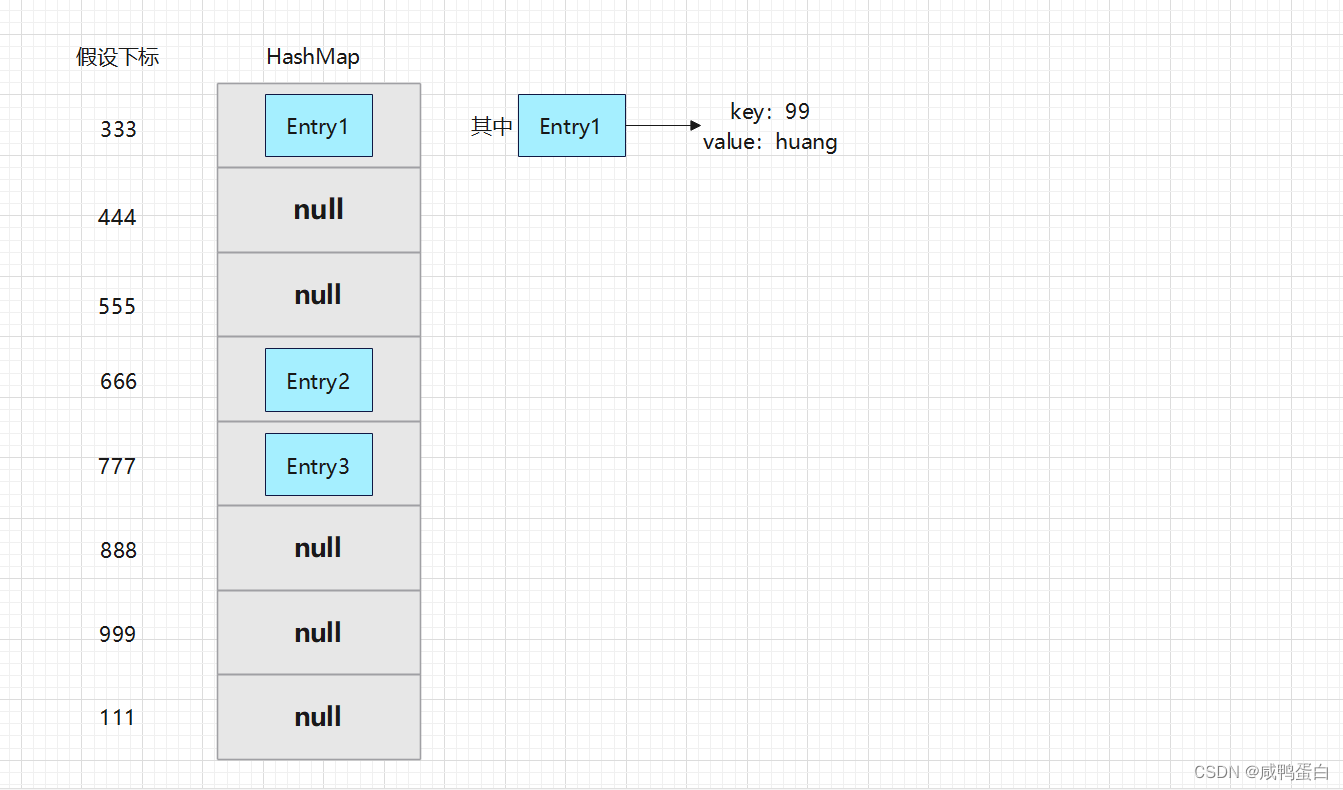
传入第一个键值对Entry1时,调用put方法:
map.put( 99 , "huang" );
key为99,此时会通过哈希函数hash()计算key的值,假如计算的结果为333(这里仅为假设,计算的结果并不是真的为333),那么就将键值对(Entry1)放入到对应下标中
Entry2 与 Entry3 也是如此。
需要注意的是:
1.HashMap中数组长度的原始大小为16,并不是上面展示的长度,且数组的初始值都为null。
2.注意并不是通过hashCode()计算key来获得hash值,而是通过另外的计算方式,这里不展开讲,具体可以自行搜索hash函数。
结合上面所说的,可以简单做一个小结:
当调用put方法的时候
比如调用 map.put(99, "huang") ,插入一个Key为99的元素。这时候我们需要利用一个哈希函数来确定Entry1的插入位置(index):
index = Hash(99)
假定最后计算出的index是333,那么就将这个Entry1存入到数组中下标为333的位置。
当然,数组的长度是有限的,而插入的Entry会越来越多,这个时候又该如何存储呢?
这个时候就需要用到链表了。
此时我们再调用put方法:
map.put( 520 , "liuliu")
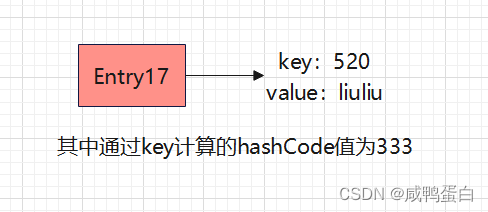
此时通过哈希函数计算得到的下标为333,而下标333处有一个Entry1,这时就出现了”hash冲突“。该如何插入呢?
HashMap数组的每一个元素不止是一个Entry对象,也是一个链表的头节点。每一个Entry对象通过Next指针指向它的下一个Entry节点。当新来的Entry映射到冲突的数组位置时,只需要插入到对应的链表即可,而插入是根据“头插法”进行插入:
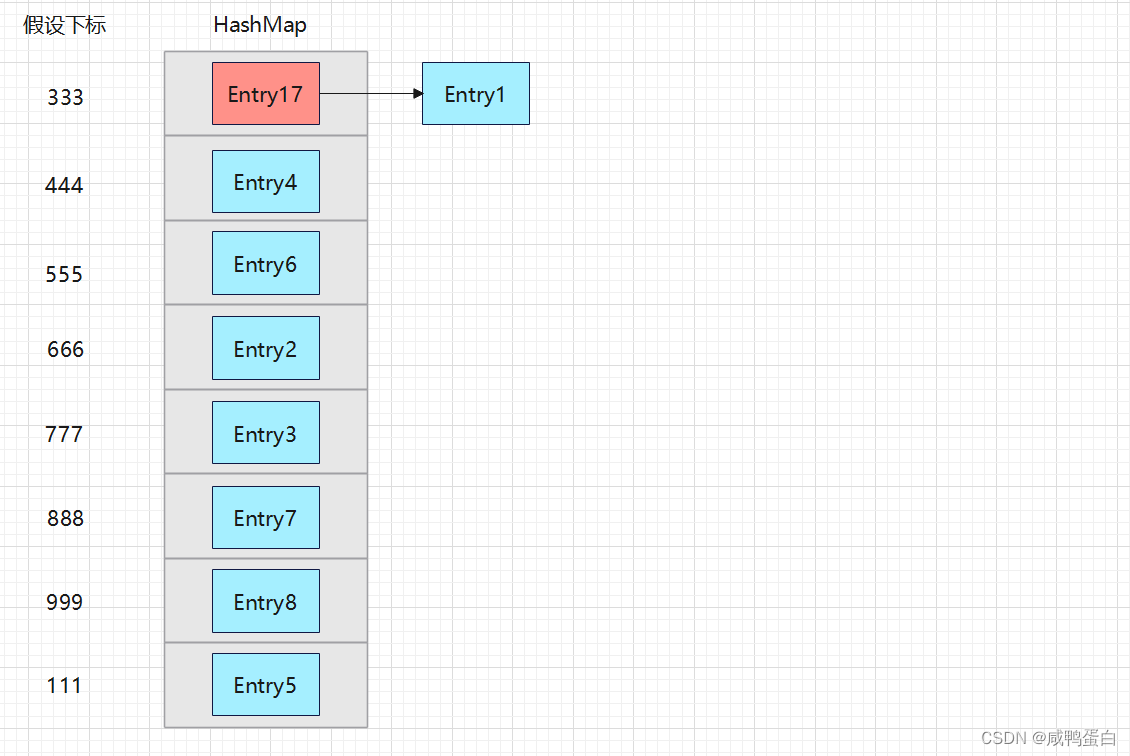
❤ 宝贝们看懂了嘛?❤
当然还有一种情况,当我想要修改我的Entry1中value的值,这时的过程是怎么样呢?
调用put方法:
map.put( 99 , "gege" );

key一样,调用哈希函数计算出的值当然也一样啦!
此时已经确定了存入的Entry18应该在下标为333的位置。此时会去查询链表,根据equals方法,查询当前的key:99 是否存在,如果存在,则用新的Entry覆盖旧的Entry。如果不存在则再次使用“头插法”将当前Entry插入到链表中。
所以这里的key=99 是存在的,因为Entry1的key为99,查询到了相同的key,则用Entry18覆盖Entry1:
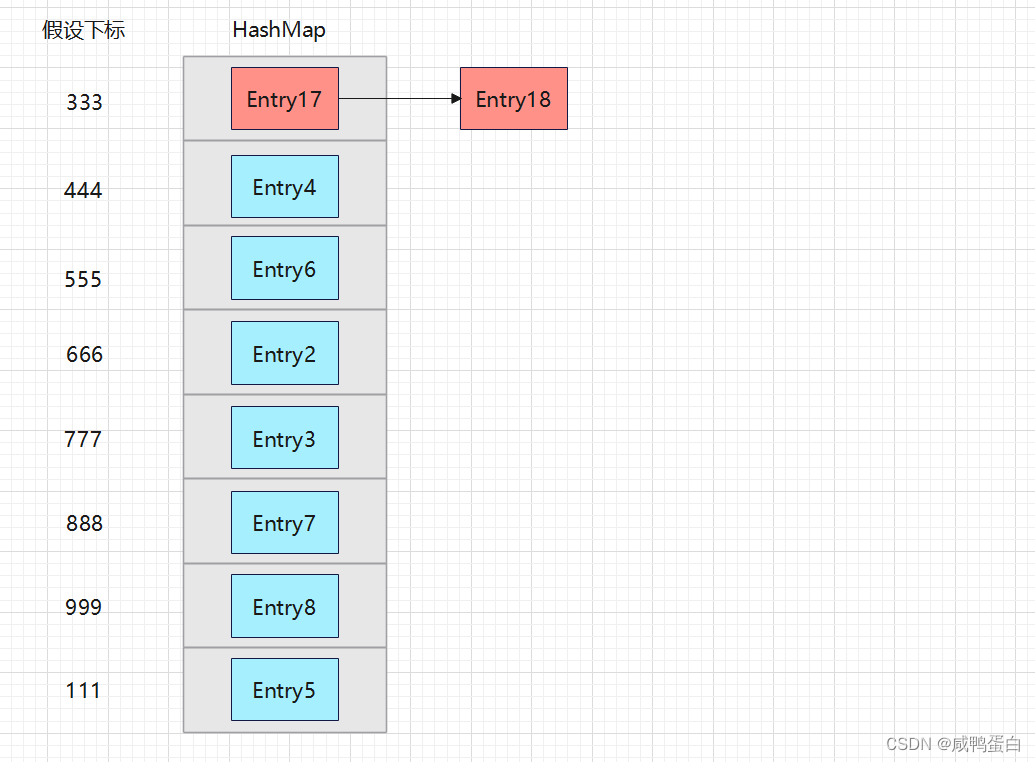
上面介绍的即为Put方法原理,同时在修改value值中也涉及了Get方法原理
这里也细致展开Get方法原理:
当我们调用Get方法:
map.get( 99 );
我们想要找到key为99的value,那么过程是怎么样的呢?

首先根据哈希函数计算出key的值,可以算出其结果为333,则此时根据下标333处的链表来查询key。
使用equals方法比对Entry17的key,返回结果为false,则继续查询,比对Entry18的key,返回结果为ture。表示已经匹配到了正确的key。
再获取对应的value:gege。
这就是Get方法的步骤了。
❤ 宝贝们看懂了嘛?❤
get方法总结:
1.通过hash函数计算key的值,得到一个数组下标
2.使用equals方法去比对下标处的头节点的key。
3.遍历链表,直至找到对应的key,返回value值。
是不是很容易理解了。
在jdk1.7中HashMap主要结构为:数组+链表。
在jdk1.8中HashMap主要结构为:数组+链表+红黑树。
为什么要加入红黑树呢?学过的人都应该知道,红黑树查询是非常快的。
设想一个情况,当我们插入的Entry非常多时,我们的链表会长的可怕,这个时候去遍历链表寻找对应的key,所花费的时间可想而知的恐怖。
加入红黑树可以优化查询的时间,使查询效率快上不少。
那么在jdk1.8的HashMap中,当链表的长度超过8时,链表会自动转化为红黑树,优化查询速度。
同时还有一个区别:发生“hash冲突”时,我们上面的做法是“头插法”,这是jdk1.7的做法,而在jdk1.8中,使用的是“尾插法”。
我在从html页面生成PDF时遇到问题。我正在使用PDFkit。在安装它的过程中,我注意到我需要wkhtmltopdf。所以我也安装了它。我做了PDFkit的文档所说的一切......现在我在尝试加载PDF时遇到了这个错误。这里是错误:commandfailed:"/usr/local/bin/wkhtmltopdf""--margin-right""0.75in""--page-size""Letter""--margin-top""0.75in""--margin-bottom""0.75in""--encoding""UTF-8""--margin-left""0.75in""-
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我花了三天的时间用头撞墙,试图弄清楚为什么简单的“rake”不能通过我的规范文件。如果您遇到这种情况:任何文件夹路径中都不要有空格!。严重地。事实上,从现在开始,您命名的任何内容都没有空格。这是我的控制台输出:(在/Users/*****/Desktop/LearningRuby/learn_ruby)$rake/Users/*******/Desktop/LearningRuby/learn_ruby/00_hello/hello_spec.rb:116:in`require':cannotloadsuchfile--hello(LoadError) 最佳
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion在首页我有:汽车:VolvoSaabMercedesAudistatic_pages_spec.rb中的测试代码:it"shouldhavetherightselect"dovisithome_pathit{shouldhave_select('cars',:options=>['volvo','saab','mercedes','audi'])}end响应是rspec./spec/request
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo
有没有办法在这个简单的get方法中添加超时选项?我正在使用法拉第3.3。Faraday.get(url)四处寻找,我只能先发起连接后应用超时选项,然后应用超时选项。或者有什么简单的方法?这就是我现在正在做的:conn=Faraday.newresponse=conn.getdo|req|req.urlurlreq.options.timeout=2#2secondsend 最佳答案 试试这个:conn=Faraday.newdo|conn|conn.options.timeout=20endresponse=conn.get(url
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
我意识到这可能是一个非常基本的问题,但我现在已经花了几天时间回过头来解决这个问题,但出于某种原因,Google就是没有帮助我。(我认为部分问题在于我是一个初学者,我不知道该问什么......)我也看过O'Reilly的RubyCookbook和RailsAPI,但我仍然停留在这个问题上.我找到了一些关于多态关系的信息,但它似乎不是我需要的(尽管如果我错了请告诉我)。我正在尝试调整MichaelHartl'stutorial创建一个包含用户、文章和评论的博客应用程序(不使用脚手架)。我希望评论既属于用户又属于文章。我的主要问题是:我不知道如何将当前文章的ID放入评论Controller。
使用Ruby1.9.2运行IDE提示说需要gemruby-debug-base19x并提供安装它。但是,在尝试安装它时会显示消息Failedtoinstallgems.Followinggemswerenotinstalled:C:/ProgramFiles(x86)/JetBrains/RubyMine3.2.4/rb/gems/ruby-debug-base19x-0.11.30.pre2.gem:Errorinstallingruby-debug-base19x-0.11.30.pre2.gem:The'linecache19'nativegemrequiresinstall
我的工作要求我为某些测试自动生成电子邮件。我一直在四处寻找,但未能找到可以快速实现的合理解决方案。它需要在outlook而不是其他邮件服务器中,因为我们有一些奇怪的身份验证规则,我们需要保存草稿而不是仅仅发送邮件的选项。显然win32ole可以做到这一点,但我找不到任何相当简单的例子。 最佳答案 假设存储了Outlook凭据并且您设置为自动登录到Outlook,WIN32OLE可以很好地完成此操作:require'win32ole'outlook=WIN32OLE.new('Outlook.Application')message=