Google Earth Engine(GEE) 是一个基于 Google 云服务基础设施的遥感大数据分析平台,它结合 Google 强大的云计算能力与 NASA、ESA、NOAA 等机构的空间数据,用于在全球尺度解决一些非常重要的社会问题:森林退化、粮食安全、灾害预警、水资源管理、气候监测以及环境保护等。

发展背景
2008 年,手握 40 多年 LandSat 数据的美国地质调查局(USGS)逐步将自 1972 年以来的所有 LandSat 存档数据免费向公众开放,成为开放遥感数据的急先锋。随后 ESA 哥白尼计划下的 Sentinel-1/2/3/5、NOAA 的 MODIS 等卫星项目产生的空间数据加入免费大军,为 GEE 的出现奠定了数据基础。
2011 年,Google 决定放弃对 Google Earth Enterprise 的深入开发,转而协同卡耐基梅隆大学、NASA、USGS 的技术人员一起设计更具技术前瞻性的 Google Earth Engine。两款产品都简称 GEE,但却代表了 Google 在不同时期对地球科学与遥感大数据的认知。
2012 年,Goodchild 等人 提出,“卫星以及地面传感器所提供的地理信息数据量的迅速增长,正在鼓励产生一种新的、第四类的、大数据的科学范式,这种范式强调国际间合作、数据密集型分析、巨大的计算资源以及高端的可视化方式”。至此,地理信息云计算的概念逐渐浮出水面。
2013 年,GEE 作为 Google 内部孵化项目,开始在行业内曝光,并积极寻求与外部的合作。
2015 年,GEE 公测上线,在全球遥感与地理信息行业产生较大反响,标志着遥感云计算时代的正式到来。
2016 年,GEE 开发团队在一年内人员数量翻倍,在 Google Cloud Platform(GCP)的助力之下,开始为新兴的商业遥感应用提供解决方案。
2017 年,Google 正式开源 Google Earth Enterprise,简称 OpenGEE,由社区驱动开发与技术维护。同年,GEE 团队发布论文 Google Earth Engine: Planetary-scale geospatial analysis for everyone,全面介绍了 GEE 出现的时代背景、平台架构、数据集、基本语法、计算效率以及未来的挑战,引起国内外科研单位及相关从业人员的广泛关注,GEE 逐渐被大家应用于实际科研与生产之中。
GEE 结合了 PB 级卫星影像和地理空间数据集,以及全球尺度的分析功能,使科学家、研究人员和开发人员可以使用它来监测变化,绘制趋势并量化地球表面的差异。
GEE 基于 Google Cloud 架设,最底层为数据存储,包括 20 级栅格和 22 级矢量瓦片数据,Fusion Table 已经弃用;第二层为云计算层,分为即时响应计算和批量计算;第三层为网络化的 REST(Representational State Transfer,表现层状态转换)APIs 服务;第四层为客户端库,用 JavaScript 和 Python 解析 REST APIs,可称为 JavaScript API 和 Python API;顶层为交互层,JavaScript API 对应 Code Editor,Python API 对应三方开发的网页或本地应用。
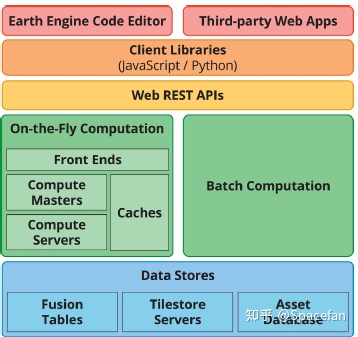
GEE 系统架构
得益于 Google 良好的底层技术生态,GEE 的应用潜力逐渐被众多用户挖掘。尤其在近来来迅猛发展的人工智能技术领域,GEE Python API 可无缝与 TensorFlow 框架相结合,实现智能遥感大数据分析。
综上所述,GEE 具有如下鲜明的技术特点:
GEE 包含 PB 级海量地理信息空间数据,主要有:
官方统计,GEE 数据中心包含超过 200 个公共数据集、500 多万张影像,并以每天大约 4000 张影像的速度递增。其不完整的数据集目录参见:Earth Engine Data Catalog。

GEE 公有数据集
GEE 的普及离不开丰富的学习资源,首推官方系统性的介绍文档:https://developers.google.com/earth-engine,其中的 JavaScript and Python Guides、API Reference 和 Earth Engine Community Content 部分是初学者的不二之选。其次,推荐澳大利亚查尔斯·达尔文大学 GEARS 团队的 GEE 教程。以及,华人吴秋生老师的系列视频教程:https://space.bilibili.com/527404442/video,和他开发的 geemap 模块教程。吴秋生老师还写有 Awesome-GEE,对 GEE 学习资源做了较为全面的归总。
对英文无感的童鞋可以看 王金柱 同学的入门视频教程:遥感大数据平台 Google Earth Engine 教学视频,以及知乎大佬 无形的风 写的系列教程。若想快速系统学习 GEE,而且家里有矿的,可直接阅读《遥感云计算与科学分析:应用与实践》一书。

遥感云计算与科学分析:应用与实践
当然,再多的学习资源都比不上一次走心的实践操作。下面就为大家演示,如何利用 MODIS 数据制作 2020 年 5 月至 2021 年 5 月全中国植被指数时序。
首先,从 全国地理信息资源目录服务系统 下载全国行政边界矢量数据,导入到 GEE。然后,建立研究区域,并裁剪中国行政边界。
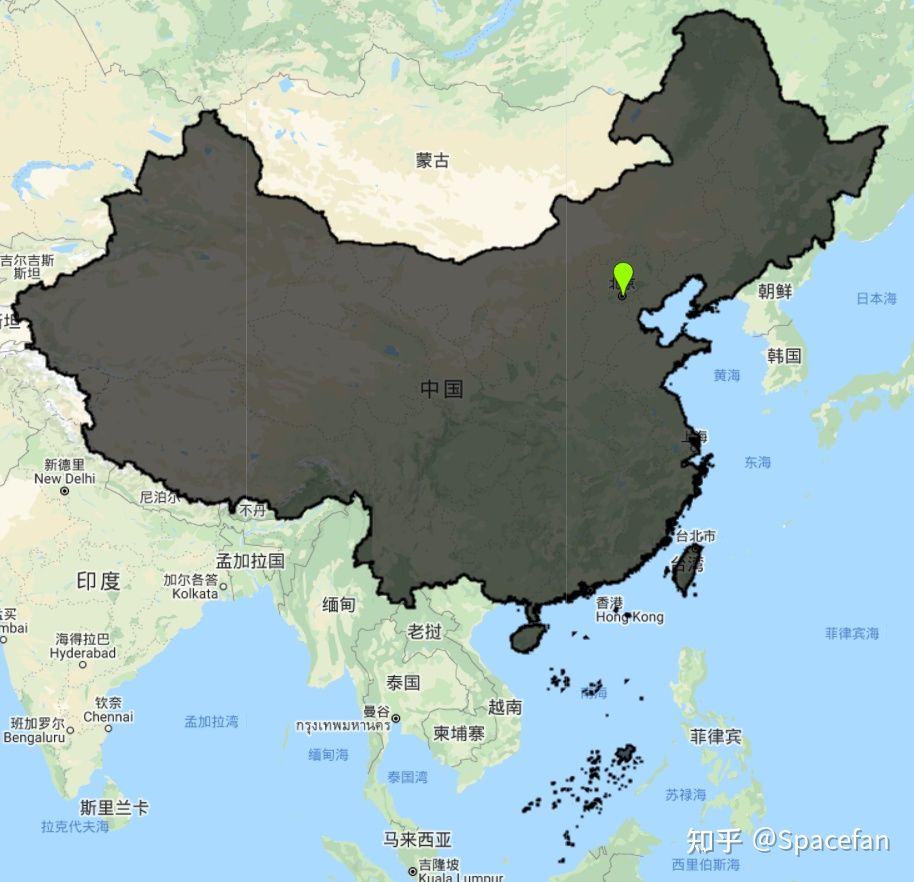
中国行政边界
随后,加载 MODIS 植被指数产品,并进行数据筛选。
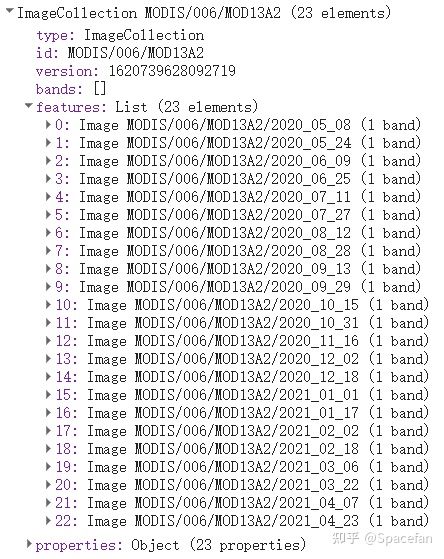
筛选得到的 MODIS 数据集
最后,将筛选得到的影像组成时序,并以直观的配色方案输出至终端显示。
全国 2020~2021 年植被指数时序
从时序图可见,植被的生成变化情况随时间沿纬度带呈潮汐状。这与太阳相对赤道的偏角在南北纬 23.5° 之间移动有关,此现象的具体研究参见:Nicholson, 2019。在世界范围内,无论规模大小,都可以发现相似的植被生产力季节性变化模式。
PS:后台回复“全国植被指数时序”获取完整示例代码。
作为一个集成的一体化工具,GEE 不局限于专业的遥感或地理空间信息应用开发,还能广泛服务于缺乏计算资源的消费级人群。
本文从 发展背景、技术特点、数据集 与 学习资源 四个方面简要介绍了 GEE 全球尺度遥感云计算平台,并以全国 2020~2021 植被指数时序制作为例展示了 GEE 在大尺度遥感数据分析方面的巨大应用潜力。
希望本文能抛砖引玉,为 GEE 初学者提供具有建设性意义的入门参考!
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
我对如何计算通过{%assignvar=0%}赋值的变量加一完全感到困惑。这应该是最简单的任务。到目前为止,这是我尝试过的:{%assignamount=0%}{%forvariantinproduct.variants%}{%assignamount=amount+1%}{%endfor%}Amount:{{amount}}结果总是0。也许我忽略了一些明显的东西。也许有更好的方法。我想要存档的只是获取运行的迭代次数。 最佳答案 因为{{incrementamount}}将输出您的变量值并且不会影响{%assign%}定义的变量,我
给定一个nxmbool数组:[[true,true,false],[false,true,true],[false,true,true]]有什么简单的方法可以返回“该列中有多少个true?”结果应该是[1,3,2] 最佳答案 使用转置得到一个数组,其中每个子数组代表一列,然后将每一列映射到其中的true数:arr.transpose.map{|subarr|subarr.count(true)}这是一个带有inject的版本,应该在1.8.6上运行,没有任何依赖:arr.transpose.map{|subarr|subarr.in
给定两个大小相等的数组,如何找到不考虑位置的匹配元素的数量?例如:[0,0,5]和[0,5,5]将返回2的匹配项,因为有一个0和一个5共同;[1,0,0,3]和[0,0,1,4]将返回3的匹配项,因为0有两场,1有一场;[1,2,2,3]和[1,2,3,4]将返回3的匹配项。我尝试了很多想法,但它们都变得相当粗糙和令人费解。我猜想有一些不错的Ruby习惯用法,或者可能是一个正则表达式,可以很好地回答这个解决方案。 最佳答案 您可以使用count完成它:a.count{|e|index=b.index(e)andb.delete_at
Ruby中如何“一般地”计算以下格式(有根、无根)的JSON对象的数量?一般来说,我的意思是元素可能不同(例如“标题”被称为其他东西)。没有根:{[{"title":"Post1","body":"Hello!"},{"title":"Post2","body":"Goodbye!"}]}根包裹:{"posts":[{"title":"Post1","body":"Hello!"},{"title":"Post2","body":"Goodbye!"}]} 最佳答案 首先,withoutroot代码不是有效的json格式。它将没有包
目标我正在尝试计算自给定日期以来周的距离,而无需跳过任何步骤。我更喜欢用普通的Ruby来做,但ActiveSupport无疑是一个可以接受的选择。我的代码我写了以下内容,这似乎可行,但对我来说似乎还有很长的路要走。require'date'DAYS_IN_WEEK=7.0defweeks_sincedate_stringdate=Date.parsedate_stringdays=Date.today-dateweeks=days/DAYS_IN_WEEKweeks.round2endweeks_since'2015-06-15'#=>32.57ActiveSupport的#weeks
技术选型1,前端小程序原生MINA框架cssJavaScriptWxml2,管理后台云开发Cms内容管理系统web网页3,数据后台小程序云开发云函数云开发数据库(基于MongoDB)云存储4,人脸识别算法基于百度智能云实现人脸识别一,用户端效果图预览老规矩我们先来看效果图,如果效果图符合你的需求,就继续往下看,如果不符合你的需求,可以跳过。1-1,登录注册页可以看到登录页有注册入口,注册页如下我们的注册,需要管理员审核,审核通过后才可以正常登录使用小程序1-2,个人中心页登录成功以后,我们会进入个人中心页我们在个人中心页可以注册人脸,因为我们做人脸识别签到,需要先注册人脸才可以进行人脸比对,进
如何计算两个字符串之间的字符交集?例如(假设我们有一个名为String.intersection的方法):"abc".intersection("ab")=2"hello".intersection("hallo")=4好的,男孩女孩们,感谢你们的大量反馈。更多示例:"aaa".intersection("a")=1"foo".intersection("bar")=0"abc".intersection("bc")=2"abc".intersection("ac")=2"abba".intersection("aa")=2一些补充说明:维基百科定义intersection如下:Int
给定一个包含各种语言字符的UTF-8文件,我如何计算它包含的唯一字符的数量,同时排除选定数量的符号(例如:“!”、“@”、"#",".")从这个算起? 最佳答案 这是一个bash解决方案。:)bash$perl-CSD-ne'BEGIN{$s{$_}++forsplit//,q(!@#.)}$s{$_}++||$c++forsplit//;END{print"$c\n"}'*.utf8 关于python-如何计算文件中唯一字符的数量?,我们在StackOverflow上找到一个类似的问题