目录
链接: 面试题库
https://www.bloghut.cn/questionBank
(1)、将用户信息导出为excel表格(导出数据…)
(2)、将Excel表中的信息录入到网站数据库(习题上传…)
(3)开发中经常会设计到excel的处理,如导出Excel,导入Excel到数据库中!操作Excel目前比较流行的就是Apache POI和阿里巴巴的easyExcel !
是什么:组件,工具
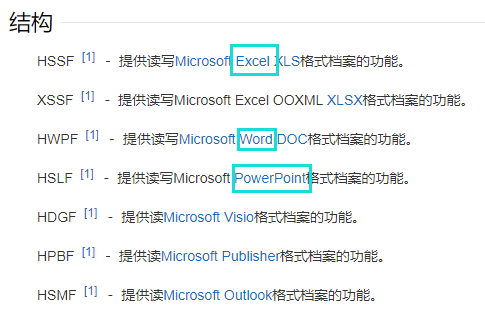
Apache POI 是用Java编写的免费开源的跨平台的 Java API,Apache POI提供API给Java程式对Microsoft Office格式档案读和写的功能。
官网:
https://poi.apache.org/
官网:
https://www.yuque.com/easyexcel/doc/easyexcel
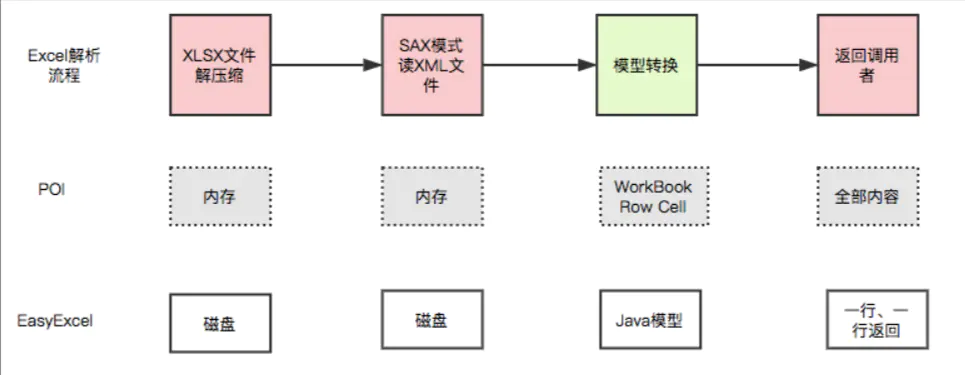
Java领域解析,生成Excel比较有名的框架有Apache poi,jxl等,但他们都存在一个严重的问题就是非常的耗内存,如果你的系统并发量不大的话可能还行,但是一旦并发上来后一定会OOM或者JVM频繁的full gc.
EasyExcel是阿里巴巴开源的一个excel处理框架,以使用简单,节省内存著称,EasyExcel能大大减少占用内存的主要原因是在解析Excel时没有将文件数据一次性全部加载到内存中,而是从磁盘上一行行读取数据,逐个解析。
EasyExcel采用一行一行的解析模式,并将一行的解析结果以观察者的模式通知处理(AnalysisEventListener)。
03和07版本的写,就是对象不同,方法一样
最大行列得数量不同:
xls最大只有65536行、256列
xlsx可以有1048576行、16384列
<!--xls(03)-->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>3.9</version>
</dependency>
<!--xlsx(07)-->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>3.9</version>
</dependency>
poi 操作xls的
poi-ooxml 操作xlsx的
操作的版本不同,使用的工具类也不同
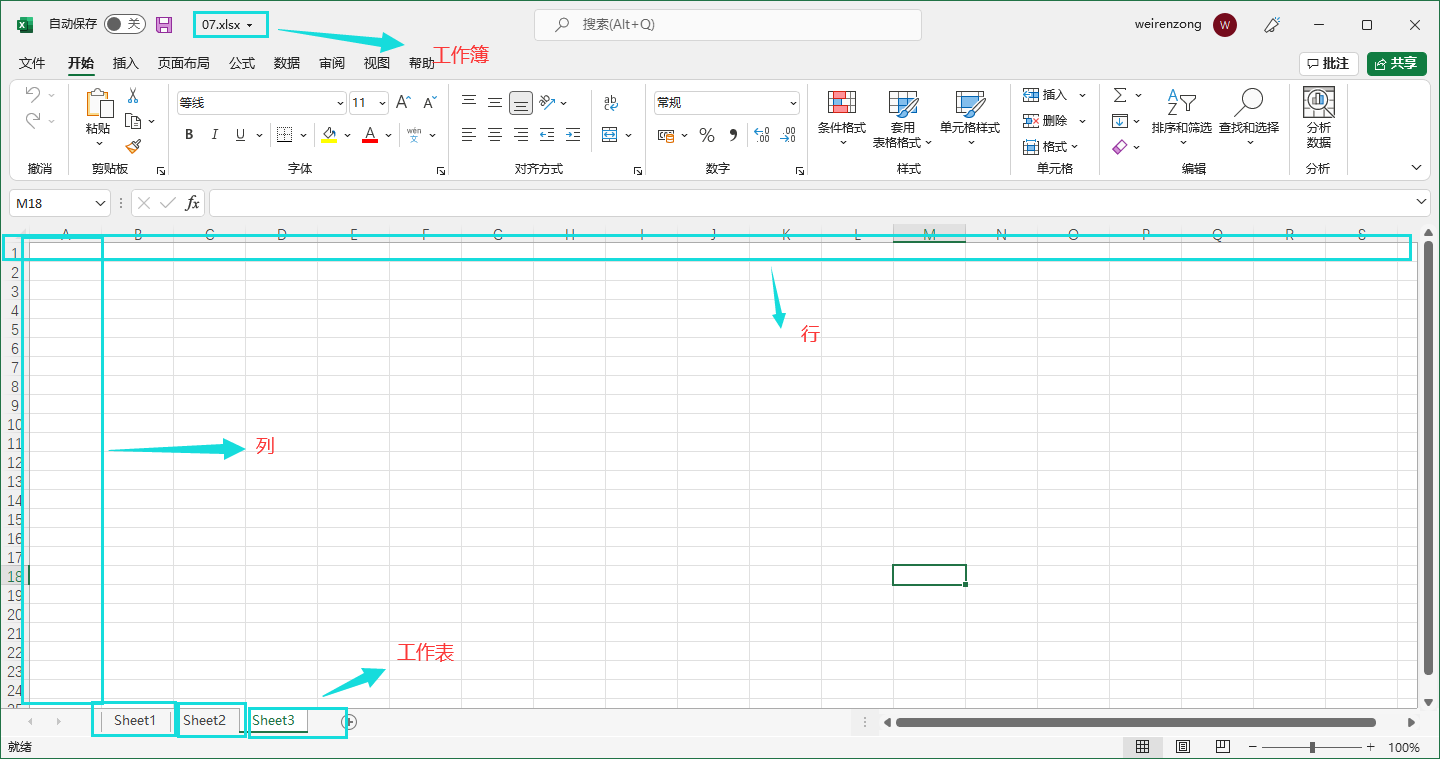
工作簿:
工作表:
行:
列:
package cn.bloghut;
import org.apache.poi.hssf.usermodel.HSSFWorkbook;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.ss.usermodel.Workbook;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
import org.joda.time.DateTime;
import org.junit.jupiter.api.Test;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.util.Date;
/**
* @Classname ExcelWrite
* @Description TODO
* @Date 2022/1/7 12:41
* @Created by 闲言
*/
public class ExcelWrite {
String PATH = "G:\\狂\\POIStudy\\xy-poi";
/**
* 写工作簿 03版本
*/
@Test
public void Write03() throws Exception {
//1.创建一个工作簿
Workbook workbook = new HSSFWorkbook();
//2.创建 一个工作表
Sheet sheet = workbook.createSheet("闲言粉丝统计表");
//3.创建一行
Row row1 = sheet.createRow(0);
//4.创建一个单元格
//(1,1)
Cell cell1 = row1.createCell(0);
cell1.setCellValue("今日新增观众");
//(1,2)
Cell cell2 = row1.createCell(1);
cell2.setCellValue(666);
//创建第二行
Row row2 = sheet.createRow(1);
//(2,1)
Cell cell21 = row2.createCell(0);
cell21.setCellValue("统计时间");
//(2,2)
Cell cell22 = row2.createCell(1);
String datetime = new DateTime().toString("yyyy-MM-dd HH:mm:ss");
cell22.setCellValue(datetime);
//生成一张表(IO流),03版本就是使用xls结尾
FileOutputStream fos = new FileOutputStream(PATH + "闲言观众统计表03.xls");
//输出
workbook.write(fos);
//关闭流
fos.close();
System.out.println("文件生成完毕");
}
/**
* 写工作簿 07版本
*/
@Test
public void Write07() throws Exception {
//1.创建一个工作簿
Workbook workbook = new XSSFWorkbook();
//2.创建 一个工作表
Sheet sheet = workbook.createSheet("闲言粉丝统计表");
//3.创建一行
Row row1 = sheet.createRow(0);
//4.创建一个单元格
//(1,1)
Cell cell1 = row1.createCell(0);
cell1.setCellValue("今日新增观众");
//(1,2)
Cell cell2 = row1.createCell(1);
cell2.setCellValue(666);
//创建第二行
Row row2 = sheet.createRow(1);
//(2,1)
Cell cell21 = row2.createCell(0);
cell21.setCellValue("统计时间");
//(2,2)
Cell cell22 = row2.createCell(1);
String datetime = new DateTime().toString("yyyy-MM-dd HH:mm:ss");
cell22.setCellValue(datetime);
//生成一张表(IO流),03版本就是使用xlsx结尾
FileOutputStream fos = new FileOutputStream(PATH + "闲言观众统计表07.xlsx");
//输出
workbook.write(fos);
//关闭流
fos.close();
System.out.println("文件生成完毕");
}
}
注意对象一个区别,文件后缀
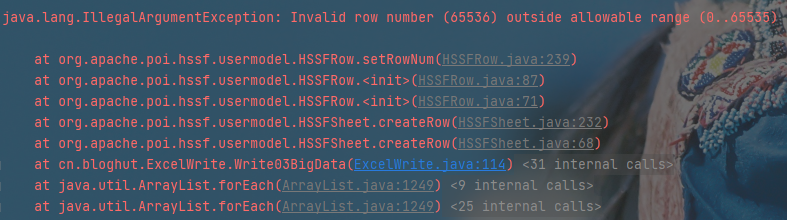
缺点:最多只能处理65536行,否则会抛异常
java.lang.IllegalArgumentException: Invalid row number (65536) outside allowable range (0..65535)
优点:过程中写入缓存,不操作磁盘,最后一次性吸入磁盘,速度快
@Test
public void Write03BigData() throws Exception{
//时间
long begin = System.currentTimeMillis();
//1.创建一个工作簿
Workbook workbook = new HSSFWorkbook();
//2.创建一个表
Sheet sheet = workbook.createSheet("第一页");
//写入数据
for (int rowNum = 0;rowNum<65536;rowNum++){
//3.创建行
Row row = sheet.createRow(rowNum);
for (int CellNum = 0;CellNum<10;CellNum++){
Cell cell = row.createCell(CellNum);
cell.setCellValue(CellNum);
}
}
System.out.println("over");
//获取io流
FileOutputStream fos = new FileOutputStream(PATH+"Write03BigData.xls");
//生成一张表
workbook.write(fos);
fos.close();
long end = System.currentTimeMillis();
System.out.println("耗时:"+(end-begin));
}
结果:

缺点:写数据时速度非常慢,非常耗内存,也会发生内存溢出,如100万条。
优点:可以写较大数据量,如20万条。
@Test
public void Write07BigData() throws Exception{
//时间
long begin = System.currentTimeMillis();
//1.创建一个工作簿
Workbook workbook = new XSSFWorkbook();
//2.创建一个表
Sheet sheet = workbook.createSheet("第一页");
//写入数据
for (int rowNum = 0;rowNum<65537;rowNum++){
//3.创建行
Row row = sheet.createRow(rowNum);
for (int CellNum = 0;CellNum<10;CellNum++){
Cell cell = row.createCell(CellNum);
cell.setCellValue(CellNum);
}
}
System.out.println("over");
//获取io流
FileOutputStream fos = new FileOutputStream(PATH+"Write03BigData.xlsx");
//生成一张表
workbook.write(fos);
fos.close();
long end = System.currentTimeMillis();
System.out.println("耗时:"+(end-begin));
}
结果:

优点:可以写非常大的数据量,如100万条甚至更多条写数据速度快,占用更少的内存
注意:
产生临时文件,需要清理临时文件默认由100条记录被保存在内存中,如果超过这数量,则最前面的数据被写入临时文件new SXSSFWorkbook(数量)@Test
public void Write07BigDataS() throws Exception{
//时间
long begin = System.currentTimeMillis();
//1.创建一个工作簿
Workbook workbook = new SXSSFWorkbook();
//2.创建一个表
Sheet sheet = workbook.createSheet("第一页");
//写入数据
for (int rowNum = 0;rowNum<100000;rowNum++){
//3.创建行
Row row = sheet.createRow(rowNum);
for (int CellNum = 0;CellNum<10;CellNum++){
Cell cell = row.createCell(CellNum);
cell.setCellValue(CellNum);
}
}
System.out.println("over");
//获取io流
FileOutputStream fos = new FileOutputStream(PATH+"Write03BigDataS.xlsx");
//生成一张表
workbook.write(fos);
fos.close();
//清除临时文件
((SXSSFWorkbook) workbook).dispose();
long end = System.currentTimeMillis();
System.out.println("耗时:"+(end-begin));
}
SXSSFWorkbook-来至官方的解释︰实现"BigGridDemo"策略的流式XSSFWorkbook版本。这允许写入非常大的文件而不会耗尽内存,因为任何时候只有可配置的行部分被保存在内存中。
请注意,仍然可能会消耗大量内存,这些内存基于您正在使用的功能,例如合并区域,注.…….当然只存储在内存中,因此如果广泛使用,可能需要大量内存。
再使用POI的时候!内存问题Jprofile !
@Test
public void Read03() throws Exception{
//1.获取文件流
FileInputStream fis = new FileInputStream(PATH+"xy-poi闲言观众统计表03.xls");
//2.创建一个工作簿。使用excel能操作的这边都可以操作!
Workbook workbook = new HSSFWorkbook(fis);
//3.获取表
Sheet sheet = workbook.getSheetAt(0);
//4.获取第一行
Row row1 = sheet.getRow(0);
//5.获取第一列
Cell cell1 = row1.getCell(0);
//6.获取第一行第一列的值
String stringCellValue = cell1.getStringCellValue();
//获取第二列
Cell cell2 = row1.getCell(1);
//获取第一行第二列的值
double numericCellValue = cell2.getNumericCellValue();
System.out.println(stringCellValue+" | "+numericCellValue);
fis.close();
}
注意获取值的类型即可
@Test
public void Read07() throws Exception{
//1.获取文件流
FileInputStream fis = new FileInputStream(PATH+"xy-poi闲言观众统计表07.xlsx");
//2.创建一个工作簿。使用excel能操作的这边都可以操作!
Workbook workbook = new XSSFWorkbook(fis);
//3.获取表
Sheet sheet = workbook.getSheetAt(0);
//4.获取第一行
Row row1 = sheet.getRow(0);
//5.获取第一列
Cell cell1 = row1.getCell(0);
//6.获取第一行第一列的值
String stringCellValue = cell1.getStringCellValue();
//获取第二列
Cell cell2 = row1.getCell(1);
//获取第一行第二列的值
double numericCellValue = cell2.getNumericCellValue();
System.out.println(stringCellValue+" | "+numericCellValue);
fis.close();
}
注意获取值的类型即可
@Test
public void CellType03() throws Exception{
//获取文件流
FileInputStream fis = new FileInputStream(PATH+"明显表.xls");
//获取一个工作簿
Workbook workbook = new HSSFWorkbook(fis);
//获取一个工作表
Sheet sheet = workbook.getSheetAt(0);
//获取第一行内容
Row row = sheet.getRow(0);
if (row != null){
//获取所有的列
int Cells = row.getPhysicalNumberOfCells();
for (int col = 0;col < Cells;col++){
//获取当前列
Cell cell = row.getCell(col);
if (cell != null){
//获取当前行的第 col 列的值
String cellValue = cell.getStringCellValue();
System.out.print(cellValue+" | ");
}
}
}
//获取标准的内容
//获取有多少行
int rowCount = sheet.getPhysicalNumberOfRows();
//从1开始,第一行是标题
for (int rowNum = 1;rowNum < rowCount;rowNum++){
Row rowData = sheet.getRow(rowNum);
if (rowData != null){
//获取当前行的列数
int cellCount = rowData.getPhysicalNumberOfCells();
System.out.println();
for (int col = 0;col < cellCount;col++){
//获取当前列的值
Cell cellData = rowData.getCell(col);
//打印当前行当前列的值
System.out.print("["+(rowNum+1)+"-"+(col+1)+"]");
//匹配列的类型
if (cellData != null){
//获取列的类型
int cellType = cellData.getCellType();
String cellValue = "";
switch (cellType){
case Cell.CELL_TYPE_STRING://字符串
System.out.print("[string]");
cellValue = cellData.getStringCellValue();
break;
case Cell.CELL_TYPE_BOOLEAN://布尔
System.out.print("[boolean]");
cellValue = String.valueOf(cellData.getBooleanCellValue());
break;
case Cell.CELL_TYPE_BLANK://空
System.out.print("[blank]");
break;
case Cell.CELL_TYPE_NUMERIC://数字(日期、普通数字)
System.out.print("[numeric]");
if (HSSFDateUtil.isCellDateFormatted(cellData)){
//如果是日期
System.out.print("[日期] ");
Date date = cellData.getDateCellValue();
cellValue = new DateTime(date).toString("yyyy-MM-dd HH:mm:ss");
}else {
//不是日期格式,防止数字过长
System.out.print("[转换字符串输出] ");
//转为字符串
cellData.setCellType(HSSFCell.CELL_TYPE_STRING);
cellValue = cellData.toString();
}
break;
case Cell.CELL_TYPE_ERROR://错误
System.out.print("[error]");
break;
}
System.out.print("["+cellValue+"]\n");
}
}
}
}
System.out.println();
System.out.println("over");
fis.close();
}
如果是07版本的Excel ,只需要将HSSFWorkbook类修改为XSSFWorkbook类。将xls文件修改为xlsx文件即可

结果:

<!--easyExcel-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>2.2.0-beta2</version>
</dependency>
1.格式类
@Getter
@Setter
@EqualsAndHashCode
public class DemoData {
@ExcelProperty("字符串标题")
private String string;
@ExcelProperty("日期标题")
private Date date;
@ExcelProperty("数字标题")
private Double doubleData;
/**
* 忽略这个字段
*/
@ExcelIgnore
private String ignore;
}
2.写的方法
@Test
public void simpleWrite(){
// 写法1
String fileName = PATH+"EasyTest.xlsx";
//write(fileName,格式类)
//sheet(表名)
//doWrite(数据)
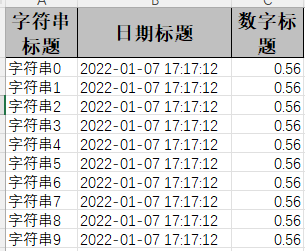
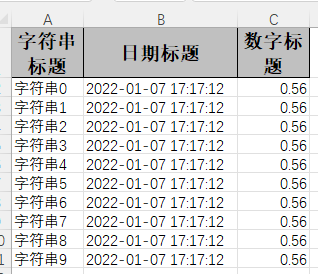
EasyExcel.write(fileName,DemoData.class).sheet("模板").doWrite(data());
}
结果
固定套路:
1、写入:固定类格式进行写入
2、读取:根据监听器设置的规则进行读取
演示读取以下excel表格数据
1.格式类
@Getter
@Setter
@EqualsAndHashCode
public class DemoData {
private String string;
private Date date;
private Double doubleData;
}
2.监听器
package cn.bloghut.esay;
import com.alibaba.excel.context.AnalysisContext;
import com.alibaba.excel.event.AnalysisEventListener;
import com.alibaba.fastjson.JSON;
import java.util.ArrayList;
import java.util.List;
// 有个很重要的点 DemoDataListener 不能被spring管理,要每次读取excel都要new,然后里面用到spring可以构造方法传进去
public class DemoDataListener extends AnalysisEventListener<DemoData> {
private static final int BATCH_COUNT = 100;
private List<DemoData> cachedDataList = new ArrayList<>(BATCH_COUNT);
private DemoDAO demoDAO;
public DemoDataListener() {
// 这里是demo,所以随便new一个。实际使用如果到了spring,请使用下面的有参构造函数
demoDAO = new DemoDAO();
}
public DemoDataListener(DemoDAO demoDAO) {
this.demoDAO = demoDAO;
}
/**
* 读取数据会执行invoke 方法
* DemoData 类型
* AnalysisContext 分析上下文
*
* @param data
* @param context
*/
@Override
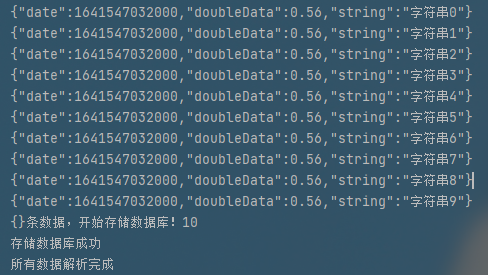
public void invoke(DemoData data, AnalysisContext context) {
System.out.println(JSON.toJSONString(data));
cachedDataList.add(data);
// 达到BATCH_COUNT了,需要去存储一次数据库,防止数据几万条数据在内存,容易OOM
if (cachedDataList.size() >= BATCH_COUNT) {
saveData();
// 存储完成清理 list
cachedDataList.clear();
}
}
/**
* 所有数据解析完成了 都会来调用
*
* @param context
*/
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
// 这里也要保存数据,确保最后遗留的数据也存储到数据库
saveData();
System.out.println("所有数据解析完成");
}
/**
* 加上存储数据库
*/
private void saveData() {
System.out.println("{}条数据,开始存储数据库!"+cachedDataList.size());
demoDAO.save(cachedDataList);
System.out.println("存储数据库成功");
}
}
DAO类(不操作数据库,用不到)
public class DemoDAO {
public void save(List<DemoData> list) {
// 如果是mybatis,尽量别直接调用多次insert,自己写一个mapper里面新增一个方法batchInsert,所有数据一次性插入
}
}
测试
@Test
public void simpleRead() throws Exception{
String fileName = PATH+"EasyTest.xlsx";
EasyExcel.read(fileName,DemoData.class,new DemoDataListener()).sheet().doRead();
}
结果
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
我基本上来自Java背景并且努力理解Ruby中的模运算。(5%3)(-5%3)(5%-3)(-5%-3)Java中的上述操作产生,2个-22个-2但在Ruby中,相同的表达式会产生21个-1-2.Ruby在逻辑上有多擅长这个?模块操作在Ruby中是如何实现的?如果将同一个操作定义为一个web服务,两个服务如何匹配逻辑。 最佳答案 在Java中,模运算的结果与被除数的符号相同。在Ruby中,它与除数的符号相同。remainder()在Ruby中与被除数的符号相同。您可能还想引用modulooperation.