paper:Denoising Diffusion Probabilistic Models(https://arxiv.org/abs/2006.11239)
本文代码地址:pytorch cifar10:https://github.com/w86763777/pytorch-ddpm
超参数设置使用absl包中flags进行管理,
–num_res_blocks是Unet中每个level的resnet数量,
–attn是attention block,向这些层中添加注意力,
这个是后面我们加入condition的途径,非常重要。
flags.DEFINE_multi_integer('attn', [1], help='add attention to these levels')
flags.DEFINE_integer('num_res_blocks', 2, help='# resblock in each level')
这里通过“pip install absl-py”就可以安装absl,然后通过“from absl import app, flags”,FLAGS = flags.FLAGS
flags.DEFINE_bool(‘train’, False, help=‘train from scratch’)就可以使用了
–beta_1,–beta_T对应于 β 1 \beta_1 β1和 β T \beta_T βT,实际的 β t \beta_t βt是在 β 1 \beta_1 β1, β T \beta_T βT中线性采样得到的。DDPM原文中研究了是否固定 β t \beta_t βt对实验结果的影响,后面很多论文也做了对比实验探索是否 β \beta β线性增长对实验效果的影响。
T是采样的步长,这个对采样质量和生成时间影响非常大。T越大,采样时间越长,3060Ti显卡采样一个batch的数据设置需要20小时。但是T越大并不是质量越高,呈二次函数关系。(随着T增大,生成质量先变好再变差)
flags.DEFINE_float('beta_1', 1e-4, help='start beta value')
flags.DEFINE_float('beta_T', 0.02, help='end beta value')
flags.DEFINE_integer('T', 1000, help='total diffusion steps')
–image_size根据数据集实际情况设置,这是影响生成时间的重要因素,size和时间呈指数倍爆炸增长。
flags.DEFINE_integer('img_size', 32, help='image size')
由于不同的数据集unet channel、T、image size等关键参数是不一样的,因此针对不同的数据集用不同的txt文件进行管理。
--T=1000
--attn=1
--batch_size=128
--beta_1=0.0001
--beta_T=0.02
--ch=128
--ch_mult=1
--ch_mult=2
--ch_mult=2
--ch_mult=2
--dropout=0.1
--ema_decay=0.9999
--noeval
--eval_step=0
--fid_cache=./stats/cifar10.train.npz
--nofid_use_torch
--grad_clip=1.0
--img_size=32
--logdir=./logs/DDPM_CIFAR10_EPS
--lr=0.0002
--mean_type=epsilon
--num_images=50000
--num_res_blocks=2
--num_workers=4
--noparallel
--sample_size=64
--sample_step=1000
--save_step=5000
--total_steps=800000
--train
--var_type=fixedlarge
--warmup=5000
以加载cifar10数据集为例:
# dataset
dataset = CIFAR10(
root='./data', train=True, download=True,
transform=transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]))
dataloader = torch.utils.data.DataLoader(
dataset, batch_size=FLAGS.batch_size, shuffle=True, num_workers=FLAGS.num_workers, drop_last=True)
datalooper = infiniteloop(dataloader)
每个loop使用next()方法即可加载输入的图像 x 0 x_0 x0:
x_0 = next(datalooper).to(device)
原文的loss计算公式:
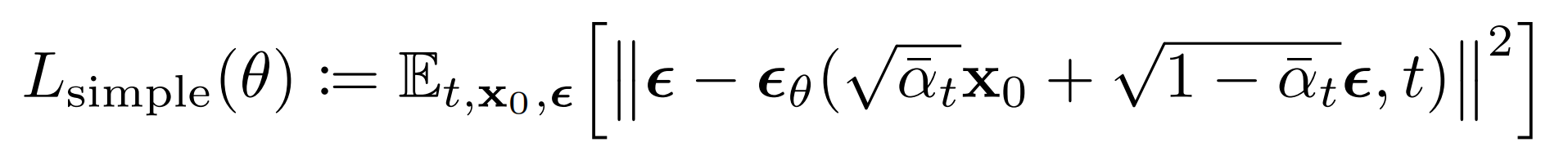
计算的是纯噪声noise ϵ \epsilon ϵ 和 ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ , t ) \boldsymbol{\epsilon}_{\theta}\left(\sqrt{\bar{\alpha}_{t}} \mathbf{x}_{0}+\sqrt{1-\bar{\alpha}_{t}} \boldsymbol{\epsilon}, t\right) ϵθ(αˉtx0+1−αˉtϵ,t)之间的损失(均方差):【因为噪声 ϵ θ \boldsymbol{\epsilon}_{\theta} ϵθ可以通过 x t x_t xt 以及 时间步 t t t 计算得出,所以这里输入进model的是x_t 和 t】,其中noise ϵ \epsilon ϵ 的size和输入的图像 x_0 是一样的:
noise = torch.randn_like(x_0)
loss = F.mse_loss(self.model(x_t, t), noise, reduction='none')
因为要计算它们之间的损失,为了计算出noise ϵ θ \boldsymbol{\epsilon}_{\theta} ϵθ,所以需要求出 x t x_t xt,也就是(x_t)
1、根据 β 1 \beta_1 β1和 β T \beta_T βT计算所有的 β t \beta_t βt
DDPM原始的论文设置的是线性增长,后面不少文章设置了指数增长等其他方式,只要满足足够小假设即可。
self.register_buffer('betas', torch.linspace(beta_1, beta_T, T).double())
2、计算 α t \alpha_t αt
α t = 1 − β t \alpha_t = 1 - \beta_t αt=1−βt
alphas = 1. - self.betas
3、累乘得到 α ˉ t \bar{\alpha}_{t} αˉt
alphas_bar = torch.cumprod(alphas, dim=0)
最后将这些一同写入buffer即可:
sqrt_alphas_bar =
α
ˉ
t
\sqrt{\bar{\alpha}_{t}}
αˉt,
sqrt_one_minus_alphas_bar =
1
−
α
ˉ
t
\sqrt{1-\bar{\alpha}_{t}}
1−αˉt
self.register_buffer('sqrt_alphas_bar', torch.sqrt(alphas_bar))
self.register_buffer('sqrt_one_minus_alphas_bar', torch.sqrt(1. - alphas_bar))
x t x_t xt的具体的计算公式如下:
x t = α ˉ t x 0 + 1 − α ˉ t ϵ x_t = \sqrt{\bar{\alpha}_{t}} \mathbf{x}_{0}+\sqrt{1-\bar{\alpha}_{t}} \boldsymbol{\epsilon} xt=αˉtx0+1−αˉtϵ
其中时刻信息 t 是通过 α ˉ t \bar{\alpha}_{t} αˉt 表现的。不难写出计算代码,其中extract函数的作用是选取特定下标 t 的参数信息并转换成特定维度用于广播。:
# 其中v是sqrt_alphas_bar、sqrt_one_minus_alphas_bar这种,t是时间步,x_shape是x的维度
# 其中extract函数的作用是:将alphas这种转为特定时间步t下的alphas
def extract(v, t, x_shape):
"""
Extract some coefficients at specified timesteps, then reshape to [batch_size, 1, 1, 1, 1, ...] for broadcasting purposes.
"""
out = torch.gather(v, index=t, dim=0).float()
return out.view([t.shape[0]] + [1] * (len(x_shape) - 1))
计算得到 x t x_t xt
x_t = (extract(self.sqrt_alphas_bar, t, x_0.shape) * x_0 +
extract(self.sqrt_one_minus_alphas_bar, t, x_0.shape) * noise)

# below: log calculation clipped because the posterior variance is 0 at the beginning of the diffusion chain
self.register_buffer('posterior_log_var_clipped', torch.log(torch.cat([self.posterior_var[1:2], self.posterior_var[1:]])))
self.register_buffer('posterior_mean_coef1', torch.sqrt(alphas_bar_prev) * self.betas / (1. - alphas_bar))
self.register_buffer('posterior_mean_coef2', torch.sqrt(alphas) * (1. - alphas_bar_prev) / (1. - alphas_bar))
def predict_xstart_from_xprev(self, x_t, t, xprev):
assert x_t.shape == xprev.shape
# (xprev - coef2*x_t) / coef1
return (
extract(1. / self.posterior_mean_coef1, t, x_t.shape) * xprev -
extract(self.posterior_mean_coef2 / self.posterior_mean_coef1, t, x_t.shape) * x_t
)
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
我正在为一个项目制作一个简单的shell,我希望像在Bash中一样解析参数字符串。foobar"helloworld"fooz应该变成:["foo","bar","helloworld","fooz"]等等。到目前为止,我一直在使用CSV::parse_line,将列分隔符设置为""和.compact输出。问题是我现在必须选择是要支持单引号还是双引号。CSV不支持超过一个分隔符。Python有一个名为shlex的模块:>>>shlex.split("Test'helloworld'foo")['Test','helloworld','foo']>>>shlex.split('Test"
我不确定传递给方法的对象的类型是否正确。我可能会将一个字符串传递给一个只能处理整数的函数。某种运行时保证怎么样?我看不到比以下更好的选择:defsomeFixNumMangler(input)raise"wrongtype:integerrequired"unlessinput.class==FixNumother_stuffend有更好的选择吗? 最佳答案 使用Kernel#Integer在使用之前转换输入的方法。当无法以任何合理的方式将输入转换为整数时,它将引发ArgumentError。defmy_method(number)
两者都可以defsetup(options={})options.reverse_merge:size=>25,:velocity=>10end和defsetup(options={}){:size=>25,:velocity=>10}.merge(options)end在方法的参数中分配默认值。问题是:哪个更好?您更愿意使用哪一个?在性能、代码可读性或其他方面有什么不同吗?编辑:我无意中添加了bang(!)...并不是要询问nobang方法与bang方法之间的区别 最佳答案 我倾向于使用reverse_merge方法:option
我有一个只接受一个参数的方法:defmy_method(number)end如果使用number调用方法,我该如何引发错误??通常,我如何定义方法参数的条件?比如我想在调用的时候报错:my_method(1) 最佳答案 您可以添加guard在函数的开头,如果参数无效则引发异常。例如:defmy_method(number)failArgumentError,"Inputshouldbegreaterthanorequalto2"ifnumbereputse.messageend#=>Inputshouldbegreaterthano
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru