目前,我们公司各团队配置中心使用各异,电商使用的是 Spring Cloud Config,支付使用的是 Apollo,APP 团队使用的是 Apollo+Nacos。为了更好地应对公司业务的发展,统一基础设施技术栈必不可少。
图片来源:直播《如何做好微服务基础设施选型》–李运华
此外,电商团队使用的 Spring Cloud Config 面临以下技术痛点:
2014年9月开源,Spring Cloud 生态组件,可以和 Spring Cloud 体系无缝整合。
2016年5月,携程开源的一款可靠的分布式配置管理中心。能够集中化管理应用不同环境、不同集群的配置,配置修改后能够实时推送到应用端,并且具备规范的权限、流程治理等特性,适用于微服务配置管理场景。
2018年6月,阿里开源的一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。它孵化于阿里巴巴,成长于十年双十一的洪峰考验,沉淀了简单易用、稳定可靠、性能卓越的核心竞争力。
| 比较项 | Nacos | Apollo | Spring Cloud Config | |
|---|---|---|---|---|
| 社区活跃度 | 开源时间 | 2018.6 | 2016.5 | 2014.9 |
| github关注 | 20.5k | 26K | 1.7K | |
| 文档 | 完善 | 完善 | 完善 | |
| 性能 | 单机读(QPS) | 15000 | 9000 | 7(限流所致) |
| 单机写(QPS) | 1800 | 1100 | 5(限流所致) | |
| 可用性 | 停服影响(配置服务) | 已启动的客户端不影响 | 已启动的客户端不影响 | 已启动的客户端不影响 |
| 部署模式 | 集群 | 集群 | 集群 | |
| 易用性 | 配置生效时间 | 实时 | 实时 | 重启生效,或手动refresh生效 |
| 数据一致性 | HTTP异步通知 | 数据库模拟消息队列,Apollo定时读消息 一分钟实时生效 | Git保证数据一致性,Config-server从Git读数据 | |
| 配置界面 | 支持 | 支持 | 不支持 | |
| 配置格式校验 | 支持 | 支持 | 不支持 | |
| 配置回滚 | 支持 | 支持 | 支持(基于git的回滚) | |
| 版本管理 | 支持 | 支持 | 支持(基于git的版本管理) | |
| 客户端支持语言 | 官方java 非官方 Go、Python、NodeJS、C++ | 官方java .net 非官方 Go、Python、NodeJS、PHP、C++ | ||
| 客户端使用 | nacos client | apollo client | cloud config client | |
| 安全性 | 权限管理 | 支持 | 完善 数据权限都比较完善 | 支持(git) |
| 授权/审计/审核 | 支持 | 界面上直接操作且支持修改和发布权限分离 | 依赖git权限管理 | |
| 数据加密 | 不支持 | 不支持 | 加密和解密属性值 | |
| 架构复杂度 | 运维成本 | Nacos+MySQL(部署简单) | Config+Admin+Portal+MySQL(部署复杂) | Config-server+Git+MQ(部署复杂) |
| 服务依赖 | 自身就是注册发现中心 阿里云两个功能隔开了 | 分布式 需要注册中心 内置了eureka | 需要注册中心 | |
| 灰度发布 | 支持 客户端配置 且路由规则客户端计算 耦合高 繁琐 | 支持 服务端配置 且路由规则服务端计算 客户端透明 简单 | 支持 | |
| 邮件服务 | 不支持 | 支持 | 不支持 | |
| 查询配置监听 | 支持 | 支持 | 支持 |
处理器:Intel® Core™ i5-9500 CPU @ 3.00GHz 3.00 GHz
系统:window 10
内测:16G
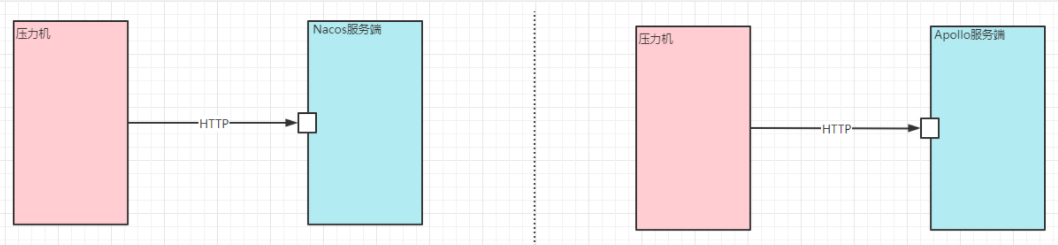
测试结果如下:
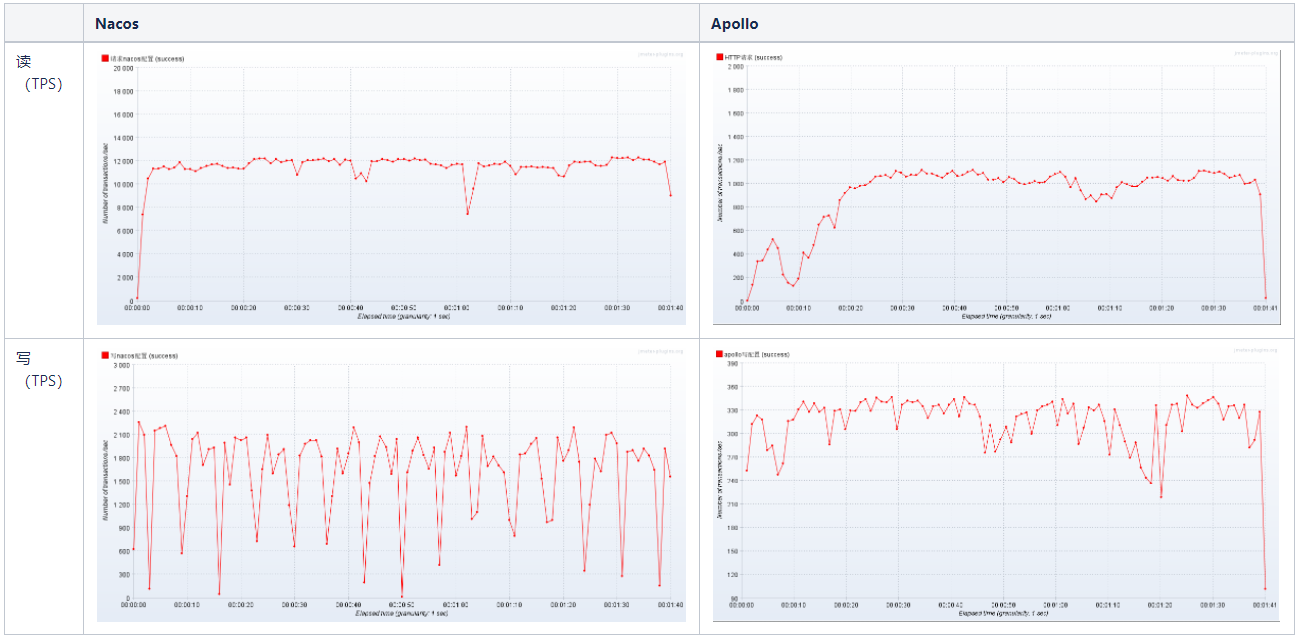
通过压测发现,Nacos读配置的TPS大约是11000左右 ,写配置TPS大约是1800左右,而Apollo读配置TPS大约是1100,写配置TPS大约310,Nacos读写性能优势非常明显。
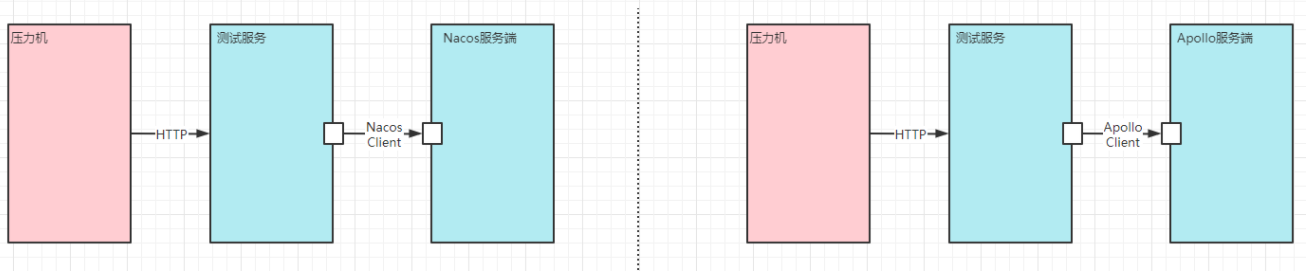
测试结果如下:
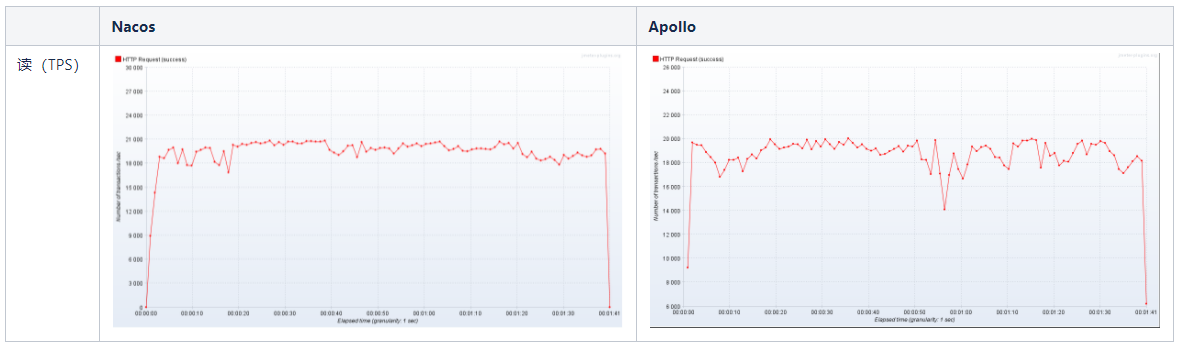
可见,读性能相差不大。
| 选择的原因 | 不选择的原因 | |
|---|---|---|
| Nacos | 统一技术栈能解决现有技术痛点运维成本低 | |
| Apollo | 依赖 Eureka | |
| Spring Cloud Config |
参考文档:
参考文档:https://nacos.io/en-us/docs/quick-start-spring-boot.html
去除 spring-cloud-config 依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-config</artifactId>
</dependency>
添加 Nacos 依赖:
<dependency>
<groupId>com.alibaba.boot</groupId>
<artifactId>nacos-config-spring-boot-starter</artifactId>
<version>0.1.8</version>
</dependency>
将原 bootstrap.yml 文件中的 config 配置替换成 nacos 的配置。
spring:
application:
name: {应用名}
cloud: # 移除
config: # 移除
uri: http://config-center.alpha-intra.dbses.com/conf # 移除
label: alpha # 移除
替换结果如下:
spring:
application:
name: {应用名}
nacos:
config:
server-addr: http://ec-nacos.dbses.com
namespace: alpha
group: {组名}
// dataId 对应服务的配置
@NacosPropertySource(groupId = "${nacos.config.group}", dataId = "${spring.application.name}.yml", first = true)
public class WebApplication {
public static void main(String[] args) {
SpringApplication.run(WebApplication.class, args);
}
}
方式一:使用@NacosValue
使用此种方法需要在@NacosPropertySource 需加上 autoRefreshed=true。示例代码如下:
@NacosPropertySource(groupId = "infra", dataId = "zebra-service.yml", first = true, autoRefreshed = true)
public class WebApplication {
public static void main(String[] args) {
SpringApplication.run(WebApplication.class, args);
}
}
nacos 配置如下:
test1:
config: 2
接口代码如下:
@RestController
public class TestController {
@NacosValue(value = "${test1.config}", autoRefreshed = true)
private String config;
@GetMapping("/config")
public String getConfig() {
return config;
}
}
方式二:使用@NacosConfigurationProperties
示例代码如下:
@Configuration
@Data
@NacosConfigurationProperties(prefix = "test2", dataId = "zebra-service.yml", groupId = "infra", autoRefreshed = true)
public class TestConfig {
private List<String> config;
private Map<String, String> map;
@Override
public String toString() {
return "TestConfig{" + "config=" + config + ", map=" + map + '}';
}
}
nacos 配置如下:
test2:
config:
- yang
- wang
map:
courier: yang
zebra: wang
接口代码如下:
@RestController
public class TestController {
@Autowired
private TestConfig testConfig;
@GetMapping("/config2")
public String getConfig2() {
return testConfig.toString();
}
}
注意
动态刷新map,修改了key会累加,不会删除原来的key。例如将 zebra-service.yml 配置中的 test2.map.zebra 改为 test2.map.zebr 后,获取的结果如下:
TestConfig{config=[yang, wang], map={courier=yang, zebra=wang, zebr=wang}}
方式三:使用@NacosConfigListener
nacos 配置如下:
test1:
config: 2
示例代码如下:
@RestController
public class TestController {
@Value(value = "${test1.config}")
private String config;
@GetMapping("/config")
public String getConfig() {
return config;
}
@NacosConfigListener(dataId = "zebra-service.yml", groupId = "infra")
public void testConfigChange(String newContent) {
YamlPropertiesFactoryBean yamlFactory = new YamlPropertiesFactoryBean();
yamlFactory.setResources(new ByteArrayResource(newContent.getBytes()));
Properties commonsProperties = yamlFactory.getObject();
this.config = commonsProperties.getProperty("test1.config"));
}
}
问题描述
我们的项目之前读取了许多公共配置,现想要读取公共配置,该怎么办?
问题解决
使用 @NacosPropertySources 注解即可加入多个配置文件。
样例代码:
@NacosPropertySources({
@NacosPropertySource(groupId = "infra", dataId = "captcha-service.yml", first = true),
@NacosPropertySource(groupId = "commons", dataId = "__common_eureka_.yml")
})
public class WebApplication {
public static void main(String[] args) {
SpringApplication.run(WebApplication.class, args);
}
}
这里的 first = true 表示这个文件的配置优先级是最高的。
问题描述
作为开发人员,我们可能需要本地启动程序来进行调试,但此时本地启动的程序连接的是 alpha 环境的配置。如果修改 alpha 环境的配置,又可能影响 alpha 及其他人的程序运行。
面对这种情况,我们怎么管理配置的优先级?
下面以 test1.config 配置为例。nacos 配置文件如下:
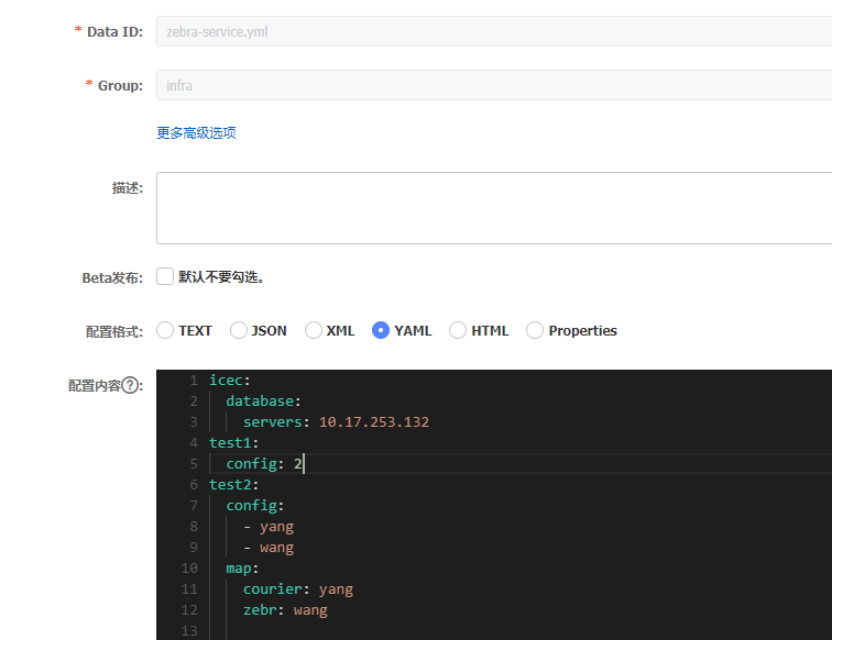
启动配置如下:
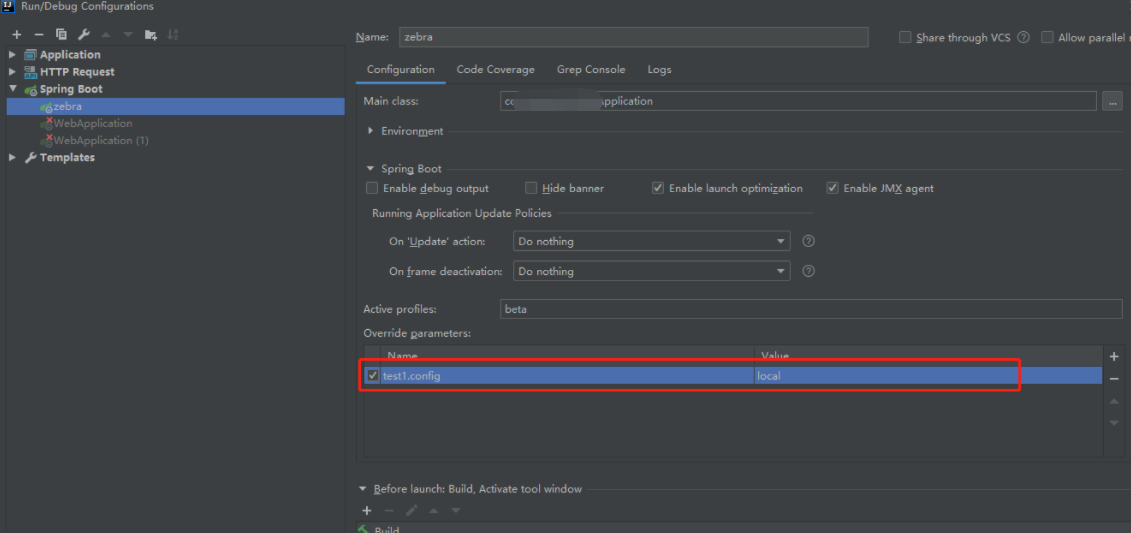
测试代码如下:
@RestController
public class TestController {
@NacosValue(value = "${test1.config}", autoRefreshed = true)
private String config1;
@GetMapping("/config1")
public String getConfig1() {
return config1;
}
}
执行结果为:
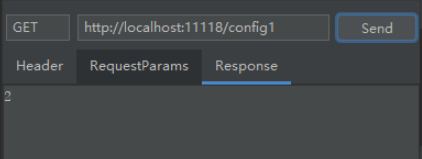
本地的配置并没有达到覆盖的效果。
问题分析
我们不妨先改造一下程序启动类。
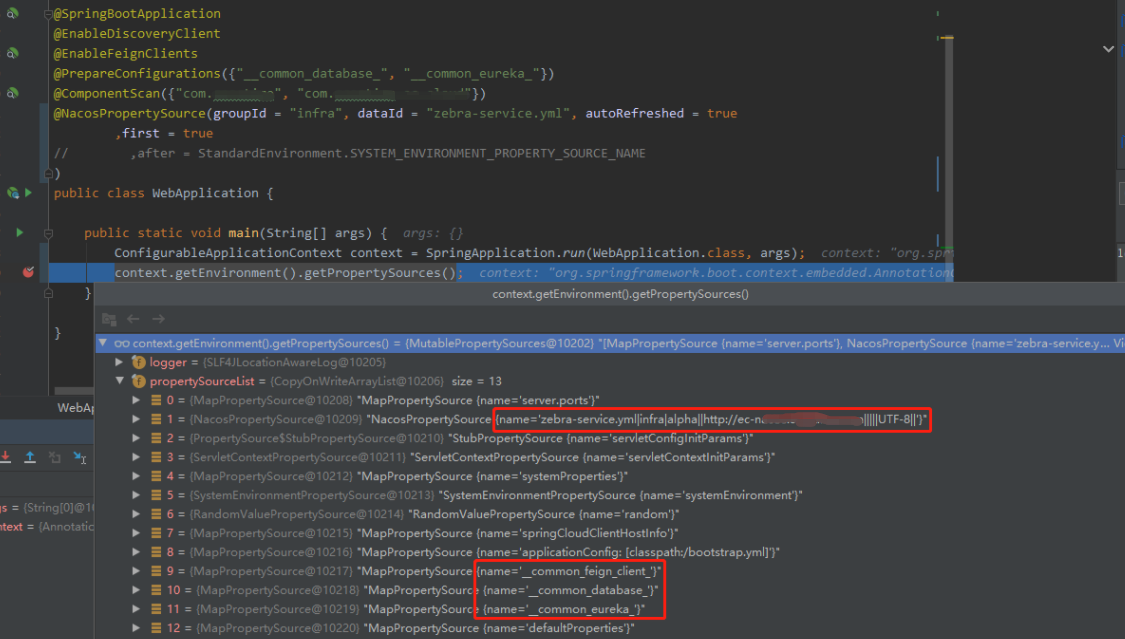
通过断点可以看到,应用配置(这里指 nacos 中的 zebra-service.yml,下同)的优先级是在公共配置之前的,这点是必要的。
应用配置必须在公共配置之前。
但是应用配置也在系统变量(systemProperties)、系统环境(systemEnvironment)之前。所以我们配置的 test1.config 并没有生效为 local。
稍作修改一下:
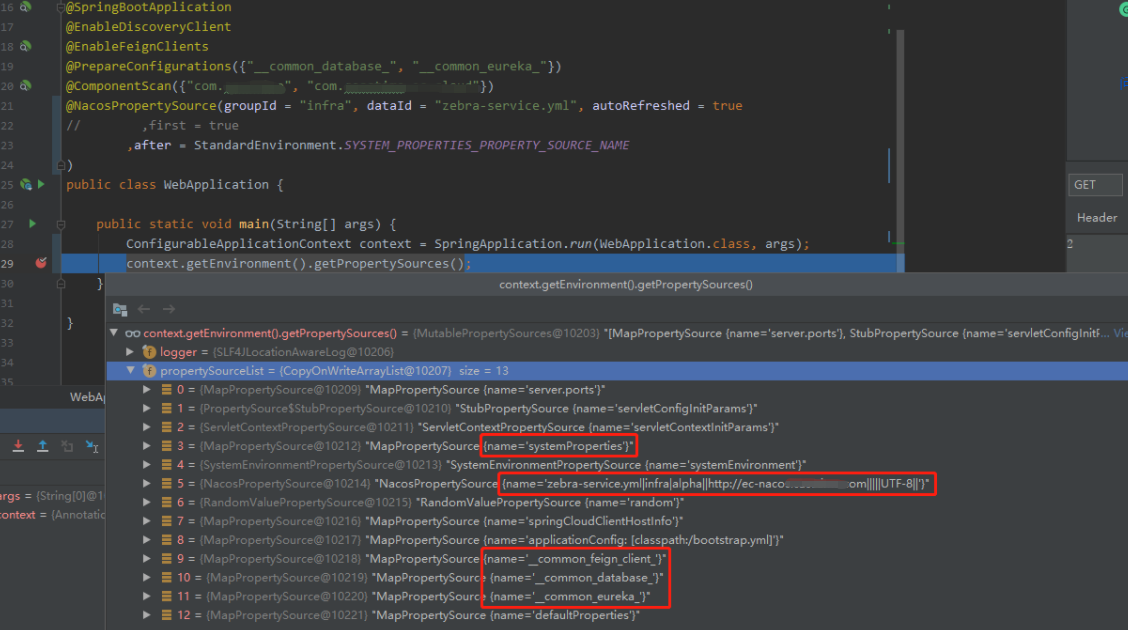
问题解决
再测试一下本地配置是否覆盖。
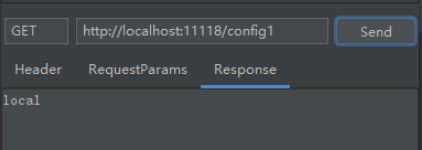
本地的配置已达到覆盖的效果。最终的启动类代码为:
@SpringBootApplication
@EnableDiscoveryClient
@EnableFeignClients
@PrepareConfigurations({"__common_database_", "__common_eureka_"})
@NacosPropertySource(groupId = "infra", dataId = "zebra-service.yml", autoRefreshed = true
,after = StandardEnvironment.SYSTEM_PROPERTIES_PROPERTY_SOURCE_NAME
)
public class WebApplication {
public static void main(String[] args) {
SpringApplication.run(WebApplication.class, args);
}
}
本文由博客一文多发平台 OpenWrite 发布!
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我有一个在Linux服务器上运行的ruby脚本。它不使用rails或任何东西。它基本上是一个命令行ruby脚本,可以像这样传递参数:./ruby_script.rbarg1arg2如何将参数抽象到配置文件(例如yaml文件或其他文件)中?您能否举例说明如何做到这一点?提前谢谢你。 最佳答案 首先,您可以运行一个写入YAML配置文件的独立脚本:require"yaml"File.write("path_to_yaml_file",[arg1,arg2].to_yaml)然后,在您的应用中阅读它:require"yaml"arg
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
注意:本文主要掌握DCN自研无线产品的基本配置方法和注意事项,能够进行一般的项目实施、调试与运维AP基本配置命令AP登录用户名和密码均为:adminAP默认IP地址为:192.168.1.10AP默认情况下DHCP开启AP静态地址配置:setmanagementstatic-ip192.168.10.1AP开启/关闭DHCP功能:setmanagementdhcp-statusup/downAP设置默认网关:setstatic-ip-routegeteway192.168.10.254查看AP基本信息:getsystemgetmanagementgetmanaged-apgetrouteAP配
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
我认为我的问题最好用一个例子来描述。假设我有一个名为“Thing”的简单模型,它有一些简单数据类型的属性。像...Thing-foo:string-goo:string-bar:int这并不难。数据库表将包含具有这三个属性的三列,我可以使用@thing.foo或@thing.bar之类的东西访问它们。但我要解决的问题是当“foo”或“goo”不再包含在简单数据类型中时会发生什么?假设foo和goo代表相同类型的对象。也就是说,它们都是“Whazit”的实例,只是数据不同。所以现在事情可能看起来像这样......Thing-bar:int但是现在有一个新的模型叫做“Whazit”,看起来
我是ruby的新手,正在配置IRB。我喜欢pretty-print(需要'pp'),但总是输入pp来漂亮地打印它似乎很麻烦。我想做的是默认情况下让它漂亮地打印出来,所以如果我有一个var,比如说,'myvar',然后键入myvar,它会自动调用pretty_inspect而不是常规检查。我从哪里开始?理想情况下,我将能够向我的.irbrc文件添加一个自动调用的方法。有什么想法吗?谢谢! 最佳答案 irb中默认pretty-print对象正是hirb被迫去做。Theseposts解释hirb如何将几乎所有内容转换为ascii表。虽
我有一个要在我的Rails3项目中使用的数组扩展方法。它应该住在哪里?我有一个应用程序/类,我最初把它放在(array_extensions.rb)中,在我的config/application.rb中我加载路径:config.autoload_paths+=%W(#{Rails.root}/应用程序/类)。但是,当我转到railsconsole时,未加载扩展。是否有一个预定义的位置可以放置我的Rails3扩展方法?或者,一种预先定义的方式来添加它们?我知道Rails有自己的数组扩展方法。我应该将我的添加到active_support/core_ext/array/conversion