核心思想 是:针对每个操作,都要注册一个与其对应的确认和补偿(撤销)操作。分为三个阶段:
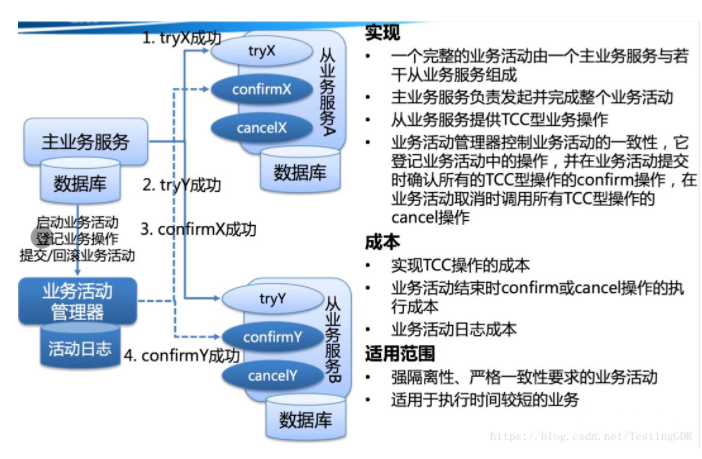
解决了协调者单点,由主业务方发起并完成这个业务活动。业务活动管理器也变成多点,引入集群。
同步阻塞: 引入超时,超时后进行补偿,并且不会锁定整个资源,将资源转换为业务逻辑形式,粒度变小。
数据一致性,有了补偿机制之后,由业务活动管理器控制一致性。
缺点:在Confirm,Cancel中都有可能失败。TCC属于应用层的一种补偿方式,所以需要程序员在实现的时候多写很多补偿的代码,在一些场景中,一些业务流程可能用TCC不太好定义及处理。
以下转自:拜托,面试请不要再问我TCC分布式事务的实现原理!【石杉的架构笔记】
这篇文章,就用大白话+手工绘图,并结合一个电商系统的案例实践,来给大家讲清楚到底什么是TCC分布式事务。
首先说一下,这里可能会牵扯到一些Spring Cloud的原理,如果有不太清楚的同学,可以参考之前的文章:《拜托,面试请不要再问我Spring Cloud底层原理!》。
咱们先来看看业务场景,假设你现在有一个电商系统,里面有一个支付订单的场景。
那对一个订单支付之后,我们需要做下面的步骤:
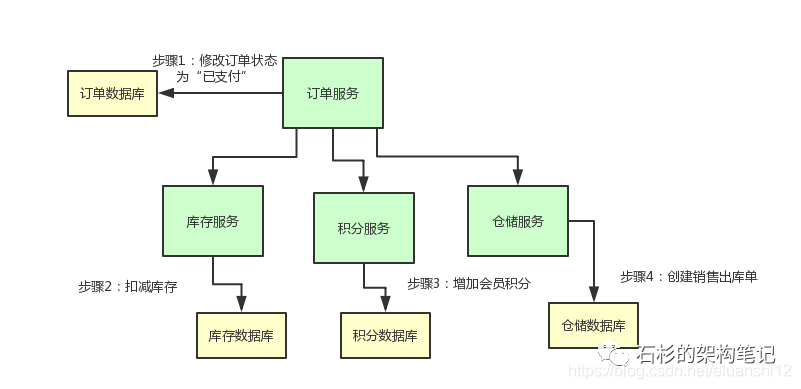
实现一个TCC分布式事务的效果。
上述这几个步骤,要么一起成功,要么一起失败,必须是一个整体性的事务。
举个例子,现在订单的状态都修改为“已支付”了,结果库存服务扣减库存失败。那个商品的库存原来是100件,现在卖掉了2件,本来应该是98件了。
结果呢?由于库存服务操作数据库异常,导致库存数量还是100。这不是在坑人么,当然不能允许这种情况发生了!
但是如果你不用TCC分布式事务方案的话,就用个Spring Cloud开发这么一个微服务系统,很有可能会干出这种事儿来。
我们来看看下面的这个图,直观的表达了上述的过程。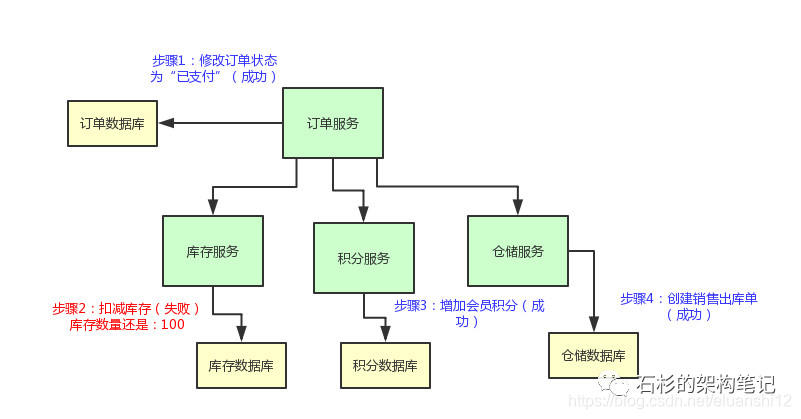
所以说,我们 有必要使用TCC分布式事务机制来保证各个服务形成一个整体性的事务。
上面那几个步骤,要么全部成功,如果任何一个服务的操作失败了,就全部一起回滚,撤销已经完成的操作。
比如说库存服务要是扣减库存失败了,那么订单服务就得撤销那个修改订单状态的操作,然后得停止执行增加积分和通知出库两个操作。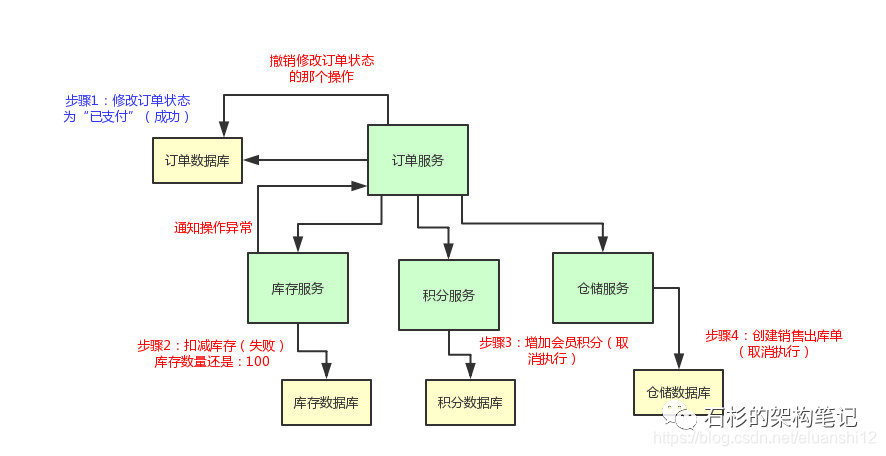
如何来实现一个TCC分布式事务,使得各个服务,要么一起成功?要么一起失败呢?
我们这就来一步一步的分析一下。以一个Spring Cloud开发系统作为背景来解释。
首先,订单服务那儿,他的代码大致来说应该是这样子的: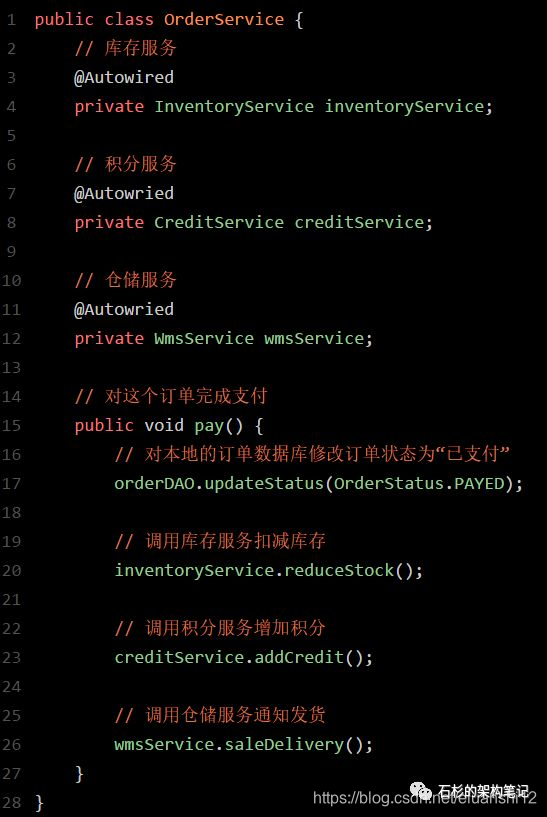
其实就是订单服务完成本地数据库操作之后,通过Spring Cloud的Feign来调用其他的各个服务罢了。但是光是凭借这段代码,是不足以实现TCC分布式事务的啊?!
首先,上面那个订单服务先把自己的状态修改为:OrderStatus.UPDATING。
在pay()方法里,把订单状态(已支付)修改为UPDATING(修改中)。仅代表有人正在修改这个状态。
库存服务直接提供的那个reduceStock()接口里,也别直接扣减库存啊,你可以是冻结掉库存。
举个例子,本来你的库存数量是100,你别直接100 - 2 = 98,扣减这个库存!
你可以把可销售的库存:100 - 2 = 98,设置为98没问题,然后在一个单独的冻结库存的字段里,设置一个2。也就是说,有2个库存是给冻结了。
积分服务的addCredit()接口也是同理,别直接给用户增加会员积分。你可以先在积分表里的一个预增加积分字段加入积分。
比如:用户积分原本是1190,现在要增加10个积分,别直接1190 + 10 = 1200个积分啊!
你可以保持积分为1190不变,在一个预增加字段里,比如说prepare_add_credit字段,设置一个10,表示有10个积分准备增加。
仓储服务的saleDelivery()接口也是同理啊,你可以先创建一个销售出库单,但是这个销售出库单的状态是“UNKNOWN”。
也就是说,刚刚创建这个销售出库单,此时还不确定他的状态是什么呢!
上面这套改造接口的过程,其实就是所谓的TCC分布式事务中的第一个T字母代表的阶段,也就是Try阶段。
总结上述过程,如果你要实现一个TCC分布式事务,首先你的业务的主流程以及各个接口提供的业务含义,不是说直接完成那个业务操作,而是完成一个Try的操作。
这个操作,一般都是锁定某个资源,设置一个预备的状态,冻结部分数据,等等,大概都是这类操作。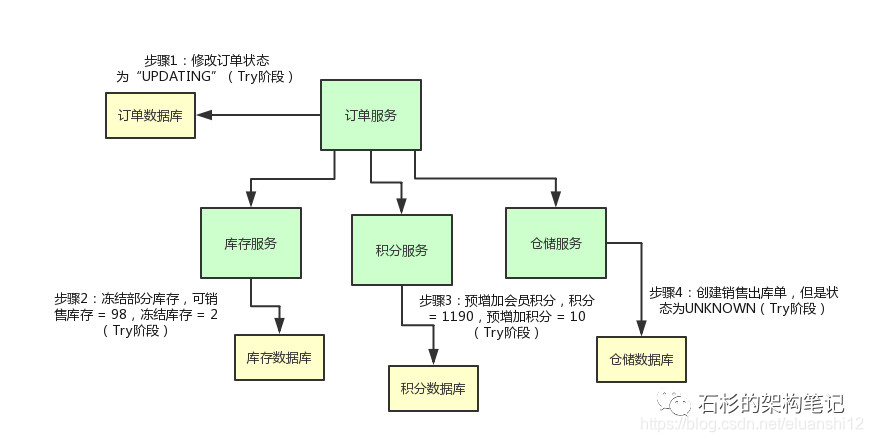
然后就分成两种情况了:
第一种情况是比较理想的,那就是各个服务执行自己的那个Try操作,都执行成功了。此时,就需要依靠TCC分布式事务框架来推动后续的执行了。
这里简单提一句,如果你要玩儿TCC分布式事务,必须引入一款TCC分布式事务框架,比如国内开源的ByteTCC、himly、tcc-transaction。 否则的话,感知各个阶段的执行情况以及推进执行下一个阶段的这些事情,不太可能自己手写实现,太复杂了。
如果你在各个服务里引入了一个TCC分布式事务的框架,订单服务里内嵌的那个TCC分布式事务框架可以感知到,各个服务的Try操作都成功了。
此时,TCC分布式事务框架会控制进入TCC下一个阶段,第一个C阶段,也就是Confirm阶段。为了实现这个阶段,你需要在各个服务里再加入一些代码。
比如说, 订单服务里,你可以加入一个Confirm的逻辑,就是正式把订单的状态设置为“已支付”了,大概是类似下面这样子: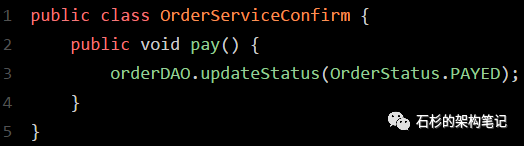
库存服务也是类似的,你可以有一个InventoryServiceConfirm类,里面提供一个reduceStock()接口的Confirm逻辑,这里就是将之前冻结库存字段的2个库存扣掉变为0。
这样的话,可销售库存之前就已经变为98了,现在冻结的2个库存也没了,那就正式完成了库存的扣减。
积分服务也是类似的,可以在积分服务里提供一个CreditServiceConfirm类,里面有一个addCredit()接口的Confirm逻辑,就是将预增加字段的10个积分扣掉,然后加入实际的会员积分字段中,从1190变为1120。
仓储服务也是类似,可以在仓储服务中提供一个WmsServiceConfirm类,提供一个saleDelivery()接口的Confirm逻辑,将销售出库单的状态正式修改为“已创建”,可以供仓储管理人员查看和使用,而不是停留在之前的中间状态“UNKNOWN”了。
好了,上面各种服务的Confirm的逻辑都实现好了,一旦订单服务里面的TCC分布式事务框架感知到各个服务的Try阶段都成功了以后,就会执行各个服务的Confirm逻辑。
订单服务内的TCC事务框架会负责跟其他各个服务内的TCC事务框架进行通信,依次调用各个服务的Confirm逻辑。然后,正式完成各个服务的所有业务逻辑的执行。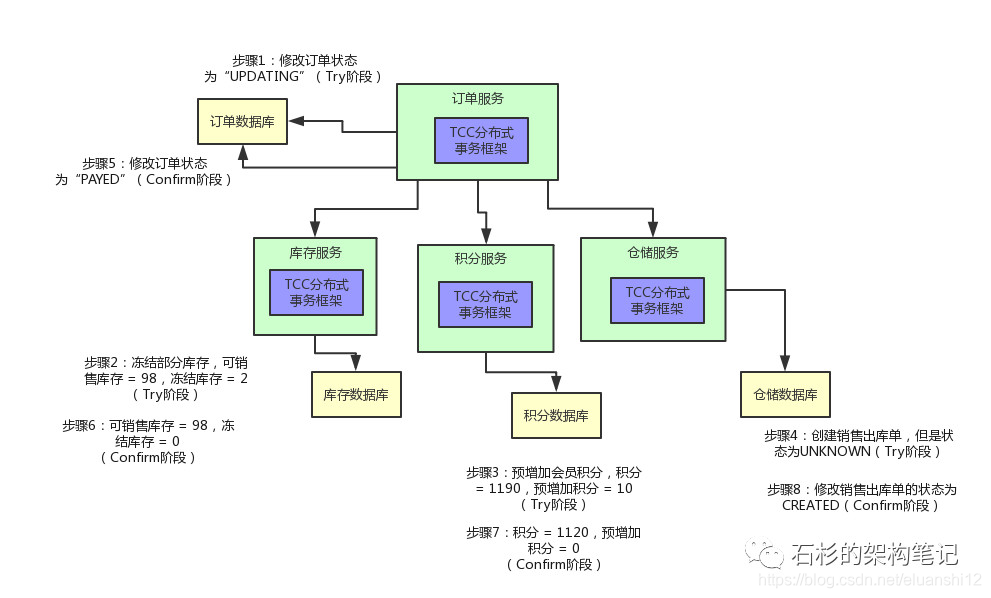
如果是异常的一种情况呢?举个例子:在Try阶段,比如积分服务吧,他执行出错了,此时会怎么样?
那订单服务内的TCC事务框架是可以感知到的,然后他会决定对整个TCC分布式事务进行回滚。
也就是说,会执行各个服务的 第二个C阶段,Cancel阶段。
同样,为了实现这个Cancel阶段,各个服务还得加一些代码。
首先订单服务,他得提供一个OrderServiceCancel的类,在里面有一个pay()接口的Cancel逻辑,就是可以将订单的状态设置为“CANCELED”,也就是这个订单的状态是已取消。
库存服务也是同理,可以提供reduceStock()的Cancel逻辑,就是将冻结库存扣减掉2,加回到可销售库存里去,98 + 2 = 100。
积分服务也需要提供addCredit()接口的Cancel逻辑,将预增加积分字段的10个积分扣减掉。
仓储服务也需要提供一个saleDelivery()接口的Cancel逻辑,将销售出库单的状态修改为“CANCELED”设置为已取消。
然后这个时候,订单服务的TCC分布式事务框架只要感知到了任何一个服务的Try逻辑失败了,就会跟各个服务内的TCC分布式事务框架进行通信,然后调用各个服务的Cancel逻辑。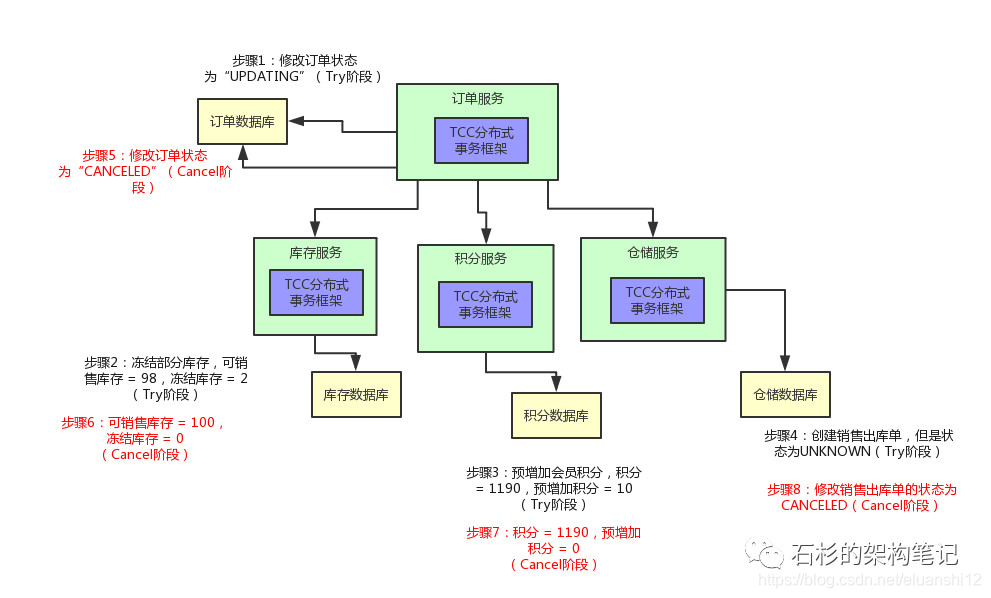
你要玩儿TCC分布式事务的话:
首先需要选择某种TCC分布式事务框架,各个服务里就会有这个TCC分布式事务框架在运行。
然后你原本的一个接口,要改造为3个逻辑,Try-Confirm-Cancel。
这就是所谓的TCC分布式事务。
TCC分布式事务的核心思想,说白了,就是当遇到下面这些情况时,
1.先来Try一下,不要把业务逻辑完成,先试试看,看各个服务能不能基本正常运转,能不能先冻结我需要的资源。
2.如果Try都ok,也就是说,底层的数据库、redis、elasticsearch、MQ都是可以写入数据的,并且你保留好了需要使用的一些资源(比如冻结了一部分库存)。
3.接着,再执行各个服务的Confirm逻辑,基本上Confirm就可以很大概率保证一个分布式事务的完成了。
4.那如果Try阶段某个服务就失败了,比如说底层的数据库挂了,或者redis挂了,等等。
此时就自动执行各个服务的Cancel逻辑,把之前的Try逻辑都回滚,所有服务都不要执行任何设计的业务逻辑。保证大家要么一起成功,要么一起失败。
如果有一些意外的情况发生了,比如说订单服务突然挂了,然后再次重启,TCC分布式事务框架是如何保证之前没执行完的分布式事务继续执行的呢?
所以,TCC事务框架 都是要记录一些分布式事务的活动日志的,可以在磁盘上的日志文件里记录,也可以在数据库里记录。保存下来分布式事务运行的各个阶段和状态。
问题还没完,万一某个服务的Cancel或者Confirm逻辑执行一直失败怎么办呢?
那也很简单,TCC事务框架会通过活动日志记录各个服务的状态。
举个例子,比如发现某个服务的Cancel或者Confirm一直没成功,会不停的重试调用他的Cancel或者Confirm逻辑,务必要他成功!
当然了,如果你的代码没有写什么bug,有充足的测试,而且Try阶段都基本尝试了一下,那么其实一般Confirm、Cancel都是可以成功的!
最后,再给大家来一张图,来看看给我们的业务,加上分布式事务之后的整个执行流程: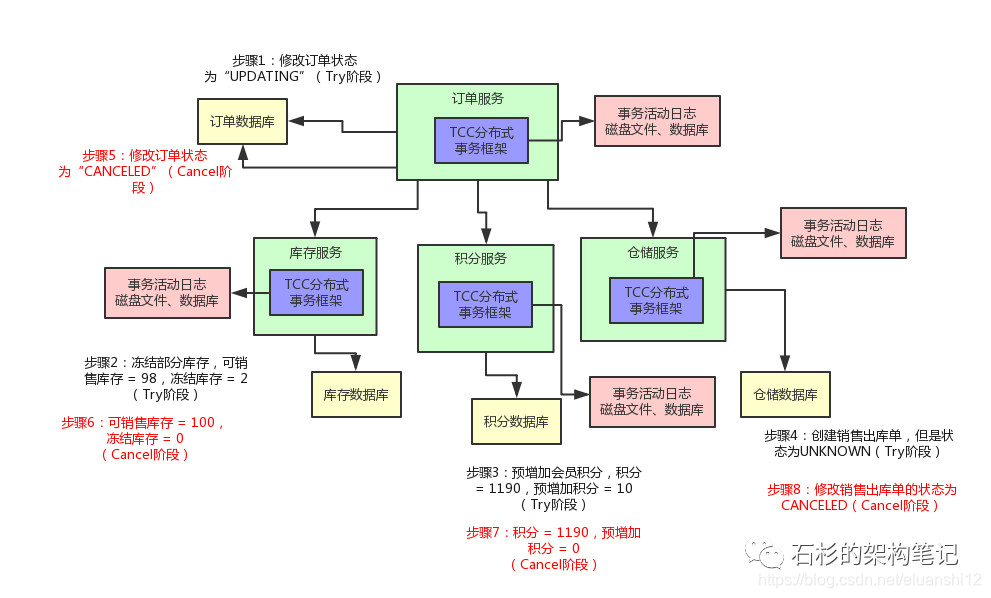
不少大公司里,其实都是自己研发TCC分布式事务框架的,专门在公司内部使用。
不过如果自己公司没有研发TCC分布式事务框架的话,那一般就会选用开源的框架。
这里笔者给大家推荐几个比较不错的框架,都是咱们国内自己开源出去的:ByteTCC,tcc-transaction,himly。
大家有兴趣的可以去他们的github地址,学习一下如何使用,以及如何跟Spring Cloud、Dubbo等服务框架整合使用。
只要把那些框架整合到你的系统里,很容易就可以实现上面那种奇妙的TCC分布式事务的效果了。
我发现ActiveRecord::Base.transaction在复杂方法中非常有效。我想知道是否可以在如下事务中从AWSS3上传/删除文件:S3Object.transactiondo#writeintofiles#raiseanexceptionend引发异常后,每个操作都应在S3上回滚。S3Object这可能吗?? 最佳答案 虽然S3API具有批量删除功能,但它不支持事务,因为每个删除操作都可以独立于其他操作成功/失败。该API不提供任何批量上传功能(通过PUT或POST),因此每个上传操作都是通过一个独立的API调用完成的
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
我已经开始使用mysql2gem。我试图弄清楚一些基本的事情——其中之一是如何明确地执行事务(对于批处理操作,比如多个INSERT/UPDATE查询)。在旧的ruby-mysql中,这是我的方法:client=Mysql.real_connect(...)inserts=["INSERTINTO...","UPDATE..WHEREid=..",#etc]client.autocommit(false)inserts.eachdo|ins|beginclient.query(ins)rescue#handleerrorsorabortentirelyendendclient.commi
保存成功后可以回滚吗?让我有一个带有属性名称、电子邮件等的用户模型。例如u=User.newu.name="test_name"u.email="test@email.com"u.save现在记录将成功保存在数据库中,之后我想回滚我的事务(不是销毁或删除)。有什么想法吗? 最佳答案 您可以通过交易来做到这一点,请参阅http://markdaggett.com/blog/2011/12/01/transactions-in-rails/例子:User.transactiondoUser.create(:username=>'Nemu
我目前正在上一门数据库类(class),其中一个实验室问题让我困惑于如何实现上述内容,事实上,如果可能的话。我试过搜索docs但是定义的交易方式比较模糊。这是我第一次尝试在没有Rails的情况下进行任何数据库操作,所以我有点迷茫。我已经成功地创建了一个到我的postgresql数据库的连接并且可以执行语句,我需要做的最后一件事是根据一个简单的条件回滚一个事务。请允许我向您展示代码:require'pg'@conn=PG::Connection.open(:dbname=>'db_15_11_labs')@conn.prepare('insert','INSERTINTOhouse(ho
如何使用Rails中的事务block一次性更新/保存模型的多个实例?我想更新数百条记录的值;每条记录的值都不同。这不是一个属性的批量更新情况。Model.update_all(attr:value)在这里不合适。MyModel.transactiondothings_to_update.eachdo|thing|thing.score=rand(100)+rand(100)thing.saveendendsave似乎发布了它自己的事务,而不是将更新分批处理到周围的事务中。我希望所有更新都在一次大交易中进行。我怎样才能做到这一点? 最佳答案
给定以下代码:defcreate@something=Something.new(params[:something])thing=@something.thing#anothermodel#modificationofattributesonboth'something'and'thing'omitted#doIneedtowrapitinsideatransactionblock?@something.savething.saveendcreate方法是隐式包装在ActiveRecord事务中,还是需要将其包装到事务block中?如果我确实需要包装它,这是最好的方法吗?
我有一个启动DRb服务的脚本,然后生成处理程序对象并通过DRb.thread.join等待。我希望脚本一直运行直到被明确杀死,所以我添加了trap"INT"doDRb.stop_serviceend在Ruby1.8下成功停止DRb服务并退出,但在1.9下似乎死锁(在OSX10.6.7上)。对该进程进行采样显示在semaphore_wait_signal_trap中有几个线程在旋转。我假设我在调用stop_service时做错了什么,但我不确定是什么。谁能给我任何关于如何正确处理它的指示? 最佳答案 好的,我想我已经找到了解决方案。如
BigData/CloudComputing:基于阿里云技术产品的人工智能与大数据/云计算/分布式引擎的综合应用案例目录来理解技术交互流程目录一、云计算网站建设:部署与发布网站建设:简单动态网站搭建云服务器管理维护云数据库管理与数据迁移云存储:对象存储管理与安全超大流量网站的负载均衡二、大数据MOOC网站日志分析搭建企业级数据分析平台基于LBS的热点店铺搜索基于机器学习PAI实现精细化营销基于机器学习的客户流失预警分析使用DataV制作实时销售数据可视化大屏使用MaxCompute进行数据质量核查使用Quick BI制作图形化报表使用时间序列分解模型预测商品销量三、云安全云平台使用安全云上服务
我不太确定如何表达这一点,所以我只是举个例子。如果我写:some_method(["a","b"],3)我希望它返回某种形式的[{"a"=>0,"b"=>3},{"a"=>1,"b"=>2},{"a"=>2,"b"=>1},{"a"=>3,"b"=>0}]如果我传入some_method(%w(abc),2)期望的返回值应该是[{"a"=>2,"b"=>0,"c"=>0},{"a"=>1,"b"=>1,"c"=>0},{"a"=>1,"b"=>0,"c"=>1},{"a"=>0,"b"=>2,"c"=>0},{"a"=>0,"b"=>1,"c"=>1},{"a"=>0,"b"=>0,"