首先,交叉验证的目的是为了让被评估的模型达到最优的泛化性能,找到使得模型泛化性能最优的超参值。在全部训练集上重新训练模型,并使用独立测试集对模型性能做出最终评价。
目前在一些论文里倒是没有特别强调这样的操作,很多研究使用的都是第一种:简单交叉验证(毕竟有一个SOTA就完全够了)。但是可以在毕业设计中加入K-折交叉验证,使得算法更加可信!
找到使得模型泛化性能最优的超参值。在全部训练集上重新训练模型,并使用独立测试集对模型性能做出最终评价。
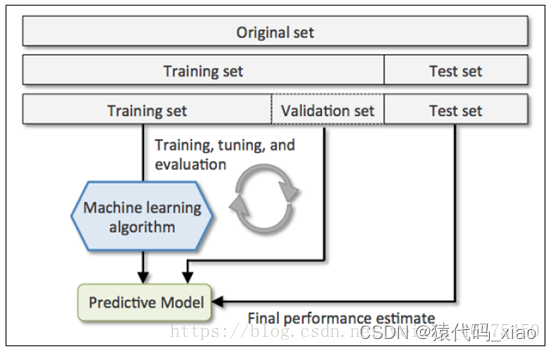
将原始数据随机分为两组,一组做为训练集,一组做为验证集,利用训练集训练分类器,然后利用验证集验证模型,记录最后的分类准确率为此分类器的性能指标。
好处:
处理简单,只需随机把原始数据分为两组即可
坏处:
但没有达到交叉的思想,由于是随机的将原始数据分组,所以最后验证集分类准确率的高低与原始数据的分组有很大的关系,得到的结果并不具有说服性。
做法是将数据集分成两个相等大小的子集,进行两次的分类器训练。在第一次中,一个子集作为训练集,另一个便作为测试集;在第二次训练中,则将训练集与测试集对换,
其并不常用:
主要原因是训练集样本数太少,不足以代表母体样本的分布,导致te测试阶段辨识率容易出现明显落差。

将原始数据分成K组(一般是均分),将每个子集数据分别做一次验证集,其余的K-1组子集数据作为训练集,这样会得到K个模型,用这K个模型最终的验证集的分类准确率的平均数作为此K-CV下分类器的性能指标。K一般大于等于2,实际操作时一般从3开始取,只有在原始数据集合数据量小的时候才会尝试取2。
(K的标准值为10,一般默认都是这个值,但是也要看数据集大小情况。对于非常大的数据集,可以使用K的值为5 ,因为这样可以在获得模型平均性能的准确估计的同时降低在不同折上多次拟合和评估模型的计算成本;如果数据相对较小,可以适当增加K的值,但是如果k的值越大,会导致交叉验证算法产生的模型性能估计具有更高的方差;对于非常小的数据集,使用一次叉验证( LOOCV )技术)
K-CV应用最多,K-CV可以有效的避免过拟合与欠拟合的发生,最后得到的结果也比较具有说服性。
Eg:十折交叉验证
1.将数据集分成十份,轮流将其中9份作为训练数据,1份作为测试数据,进行试验。每次试验都会得出相应的正确率。
2.10次的结果的正确率的平均值作为对算法精度的估计,一般还需要进行多次10折交叉验证(例如10次10折交叉验证),再求其均值,作为对算法准确性的估计
此外:
1.多次 k 折交叉验证再求均值,例如:10 次10 折交叉验证,以求更精确一点。
2.划分时有多种方法,例如对非平衡数据可以用分层采样,就是在每一份子集中都保持和原始数据集相同的类别比例。
3.模型训练过程的所有步骤,包括模型选择,特征选择等都是在单个折叠 fold 中独立执行的。
在数据缺乏的情况下使用,如果设原始数据有N个样本,那么LOO-CV就是N-CV,即每个样本单独作为验证集,其余的N-1个样本作为训练集,故LOO-CV会得到N个模型,用这N个模型最终的验证集的分类准确率的平均数作为此下LOO-CV分类器的性能指标。
优点:
(1)每一回合中几乎所有的样本皆用于训练模型,因此最接近原始样本的分布,这样评估所得的结果比较可靠。
(2)实验过程中没有随机因素会影响实验数据,确保实验过程是可以被复制的。
缺点:
计算成本高,需要建立的模型数量与原始数据样本数量相同。当数据集较大时几乎不能使用。
分层交叉验证(Stratified k-fold cross validation):首先它属于交叉验证类型,分层的意思是说在每一折中都保持着原始数据中各个类别的比例关系,比如说:原始数据有3类,比例为1:2:1,采用3折分层交叉验证,那么划分的3折中,每一折中的数据类别保持着1:2:1的比例,这样的验证结果更加可信。
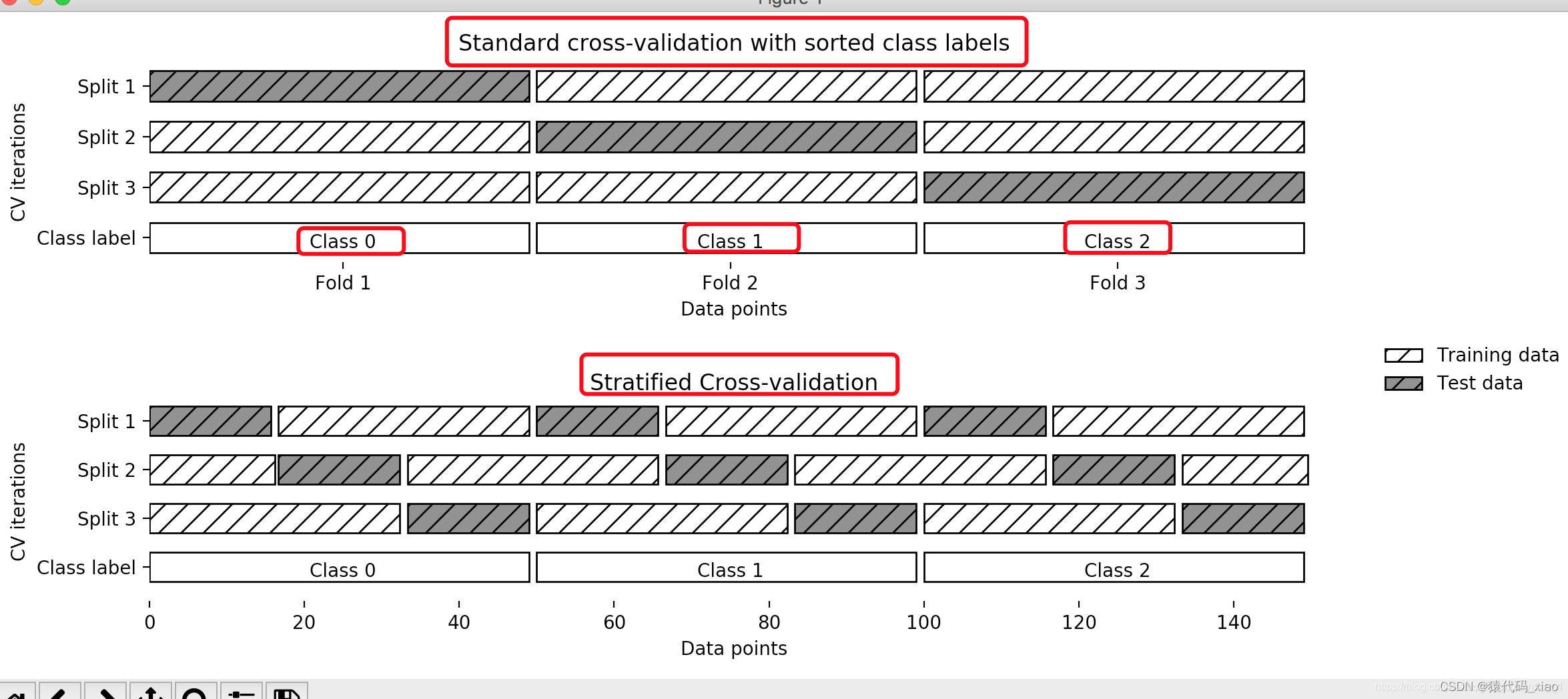
交叉验证按照上面的思路,我们可以自己用Python构建交叉验证的方法,但是因为Sklearn有很方便的交叉验证生成器,所以我们一般不自己费劲造轮子。下面给出的交叉验证生成器返回训练集和测试集拆分的索引,通过轮换使用这些索引进行切片创建训练集和测试集来训练不同的模型,然后计算不同模型的性能的均值和标准差,以评估超参数值的有效性并进一步适当地进行调优。
下面是Python代码,它使用了Class StratifiedKFold类(sklearn.model_selection) :1.创建StratifiedKFold的实例,传递fold参数(n_splits= 10);2.在StratifiedKFold的实例上调用Split方法,切分出K折的训练集和测试集的索引;3.把训练集和测试集数据传递到管道(pipeline)实例中,管道是Sklearn很好的一个类,它相当于构建了一个工作流;4.计算不同模型的评估分数;5.最后计算模型分数的均值和标准差;
from sklearn.model_selection import cross_val_score
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import StratifiedKFold
#创建一个管道(Pipeline)实例,里面包含标准化方法和随机森林模型
pipeline = make_pipeline(StandardScaler(), RandomForestClassifier(n_estimators=100, max_depth=4))
# 创建一个用于得到不同训练集和测试集样本的索引的StratifiedKFold实例,折数为10
strtfdKFold = StratifiedKFold(n_splits=10)
#把特征和标签传递给StratifiedKFold实例
kfold = strtfdKFold.split(X_train, y_train)
#循环迭代,(K-1)份用于训练,1份用于验证,把每次模型的性能记录下来。
scores = []
for k, (train, test) in enumerate(kfold):
pipeline.fit(X_train.iloc[train, :], y_train.iloc[train])
score = pipeline.score(X_train.iloc[test, :], y_train.iloc[test])
scores.append(score)
print('Fold: %2d, Training/Test Split Distribution: %s, Accuracy: %.3f' % (k+1, np.bincount(y_train.iloc[train]), score))
print('\n\nCross-Validation accuracy: %.3f +/- %.3f' %(np.mean(scores), np.std(scores)))
上面只是简单的把数据集轮换划分,但是交叉验证技术往往是用来进行模型优化(超参数优化)。在sklearn.model_selection模块中有一个cross_val_score类用于计算交叉验证分数,它通过将数据重复拆分为训练集和测试集,使用训练集训练估计器,并根据交叉验证的每次迭代的测试集计算分数。cross_val_score的参数包括估计器(具有fit和predict方法)或者是管道 (sklearn.pipeline)、交叉验证对象(object),其中参数cv如果是一个整数,表示分层KFold交叉验证器中的折叠数,如果是小数,表示训练集和验证集的比例;如果没有指定 cv,默认使用5折交叉验证。下面是代码:
from sklearn.model_selection import cross_val_score
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
#创建一个管道(Pipeline)实例,里面包含标准化方法和随机森林模型估计器
pipeline = make_pipeline(StandardScaler(), RandomForestClassifier(n_estimators=100, max_depth=4))
# 设置交叉验证折数cv=10 表示使用带有十折的StratifiedKFold,再把管道和数据集传到交叉验证对象中
scores = cross_val_score(pipeline, X=X_train, y=y_train, cv=10, n_jobs=1)
print('Cross Validation accuracy scores: %s' % scores)
print('Cross Validation accuracy: %.3f +/- %.3f' % (np.mean(scores),np.std(scores)))
给定这段代码defcreate@upgrades=User.update_all(["role=?","upgraded"],:id=>params[:upgrade])redirect_toadmin_upgrades_path,:notice=>"Successfullyupgradeduser."end我如何在该操作中实际验证它们是否已保存或未重定向到适当的页面和消息? 最佳答案 在Rails3中,update_all不返回任何有意义的信息,除了已更新的记录数(这可能取决于您的DBMS是否返回该信息)。http://ar.ru
我想安装一个带有一些身份验证的私有(private)Rubygem服务器。我希望能够使用公共(public)Ubuntu服务器托管内部gem。我读到了http://docs.rubygems.org/read/chapter/18.但是那个没有身份验证-如我所见。然后我读到了https://github.com/cwninja/geminabox.但是当我使用基本身份验证(他们在他们的Wiki中有)时,它会提示从我的服务器获取源。所以。如何制作带有身份验证的私有(private)Rubygem服务器?这是不可能的吗?谢谢。编辑:Geminabox问题。我尝试“捆绑”以安装新的gem..
我希望我的UserPrice模型的属性在它们为空或不验证数值时默认为0。这些属性是tax_rate、shipping_cost和price。classCreateUserPrices8,:scale=>2t.decimal:tax_rate,:precision=>8,:scale=>2t.decimal:shipping_cost,:precision=>8,:scale=>2endendend起初,我将所有3列的:default=>0放在表格中,但我不想要这样,因为它已经填充了字段,我想使用占位符。这是我的UserPrice模型:classUserPrice回答before_val
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我有一些非常大的模型,我必须将它们迁移到最新版本的Rails。这些模型有相当多的验证(User有大约50个验证)。是否可以将所有这些验证移动到另一个文件中?说app/models/validations/user_validations.rb。如果可以,有人可以提供示例吗? 最佳答案 您可以为此使用关注点:#app/models/validations/user_validations.rbrequire'active_support/concern'moduleUserValidationsextendActiveSupport:
当我的预订模型通过rake任务在状态机上转换时,我试图找出如何跳过对ActiveRecord对象的特定实例的验证。我想在reservation.close时跳过所有验证!叫做。希望调用reservation.close!(:validate=>false)之类的东西。仅供引用,我们正在使用https://github.com/pluginaweek/state_machine用于状态机。这是我的预订模型的示例。classReservation["requested","negotiating","approved"])}state_machine:initial=>'requested
我有一个服务模型/表及其注册表。在表单中,我几乎拥有服务的所有字段,但我想在验证服务对象之前自动设置其中一些值。示例:--服务Controller#创建Action:defcreate@service=Service.new@service_form=ServiceFormObject.new(@service)@service_form.validate(params[:service_form_object])and@service_form.saverespond_with(@service_form,location:admin_services_path)end在验证@ser
这里有一个很好的答案解释了如何在Ruby中下载文件而不将其加载到内存中:https://stackoverflow.com/a/29743394/4852737require'open-uri'download=open('http://example.com/image.png')IO.copy_stream(download,'~/image.png')我如何验证下载文件的IO.copy_stream调用是否真的成功——这意味着下载的文件与我打算下载的文件完全相同,而不是下载一半的损坏文件?documentation说IO.copy_stream返回它复制的字节数,但是当我还没有下
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总