2021年11月,随着波卡主网正式开启平行链插槽拍卖,波卡生态顿时成为一股耀眼的新势力。在波卡生态中,Gear则是相对被低估的项目之一。作为波卡智能合约平台,Gear在技术上支持异步编程和并行计算、WASM虚拟机,据称Gear的运行速度大幅高于传统EVM链,其TPS(每秒交易数量)可比以太坊和BSC、Polygon等EVM系公链高出几个数量级。Gear CEO Nikolay Volf也明确表示,Gear将支持DApp开发者使用Rust、C、C++等主流开发语言部署智能合约,并推出适用于不同应用的模板和库,让开发者仅修改部分参数就能轻松地部署DApp,尽可能增强其兼容性。
Gear的定位是一条新公链。但Gear官方未表示支持EVM,这将使其失去目前在区块链开发中占主导、数量广泛的Solidity开发者,不利于Gear生态的快速建设。而其Gear网络节点支持“并行处理”(在同一时刻运行多个任务)和“异步编程”(调用某函数功能的结果可延时返回)的能力可以很大程度上使Gear的TPS比普通公链高出几个数量级。所以可以采用将这两项技术迁移到EVM生态中,提高占主导地位Solidity的TPS。
基础区块链框架是Polkadot网络的重要组成部分。它使希望创建新区块链的团队不必从头开始编写,就可以在网络实施和共识代码上浪费精力。
基础涵盖多个方面,包括共识机制(块终结、验证器投票系统、容错)、网络层(p2p连接、消息发送和数据复制功能)、完整节点模板、数据库抽象、通过WASM的客户端更新机制(无硬叉)和其他重要模块。Gear使用的基板框架。这有助于满足企业级分散项目的最理想需求——容错、复制、标记化、不变性、数据安全和生产级跨平台持久数据库。
Gear本身被实现为一个定制的Substrate运行时,引入了高级本地扩展(通过主机功能)以提高性能。使用Substrate构建区块链允许Gear作为副链部署在任何兼容的中继链上,如Polkadot和Kusama。Polkadot网络Polkadot是下一代区块链协议,旨在联合多个专门构建的区块链,允许它们在规模上无缝运行。
与任何区块链系统一样,Gear保持分布式状态。编译到WebAssembly的运行时代码成为区块链存储状态的一部分。Gear支持无叉运行时升级的定义功能。如果使用最终小工具,也可以保证最终完成状态。
存储状态包括下面的三个组件:
程序代码存储为一个不可变的Wasm blob。每个程序都有一个固定数量的单独内存,在初始化过程中为程序保留,并在消息处理之间保持(所谓的静态区域)。Gear实例为每个程序保留单独的内存空间,并保证其持久性。
一个程序只能在自己专门分配的内存空间内进行读写,不能访问其他程序的内存空间。单个内存空间在程序初始化期间为程序保留,不需要额外费用(包括在程序初始化费用中)。
程序可以从Gear实例提供的内存池中分配更多内存。程序可以以64KB的块为单位分配所需数量的内存页。每个额外的内存块分配都需要一笔gas费。
每个分配的内存块(64KB)分别存储在分布式数据库后端,但在程序访问其内存的运行时,Gear节点会构建连续的运行时内存,并允许程序在其上运行而无需重新加载。

Gear节点使用惰性加载技术,因此如果执行进程需要页面,那么页面会被放入内存,而不是立即加载所有页面。每次程序正常完成执行后,都会保存程序的状态及其内存。
使用持久内存对于确保数据密集型dApps的成功至关重要。在这里,每次需要处理程序时加载程序的传统方法似乎没有得到优化。具有多对多关系的分散应用程序受益于持久内存方法。
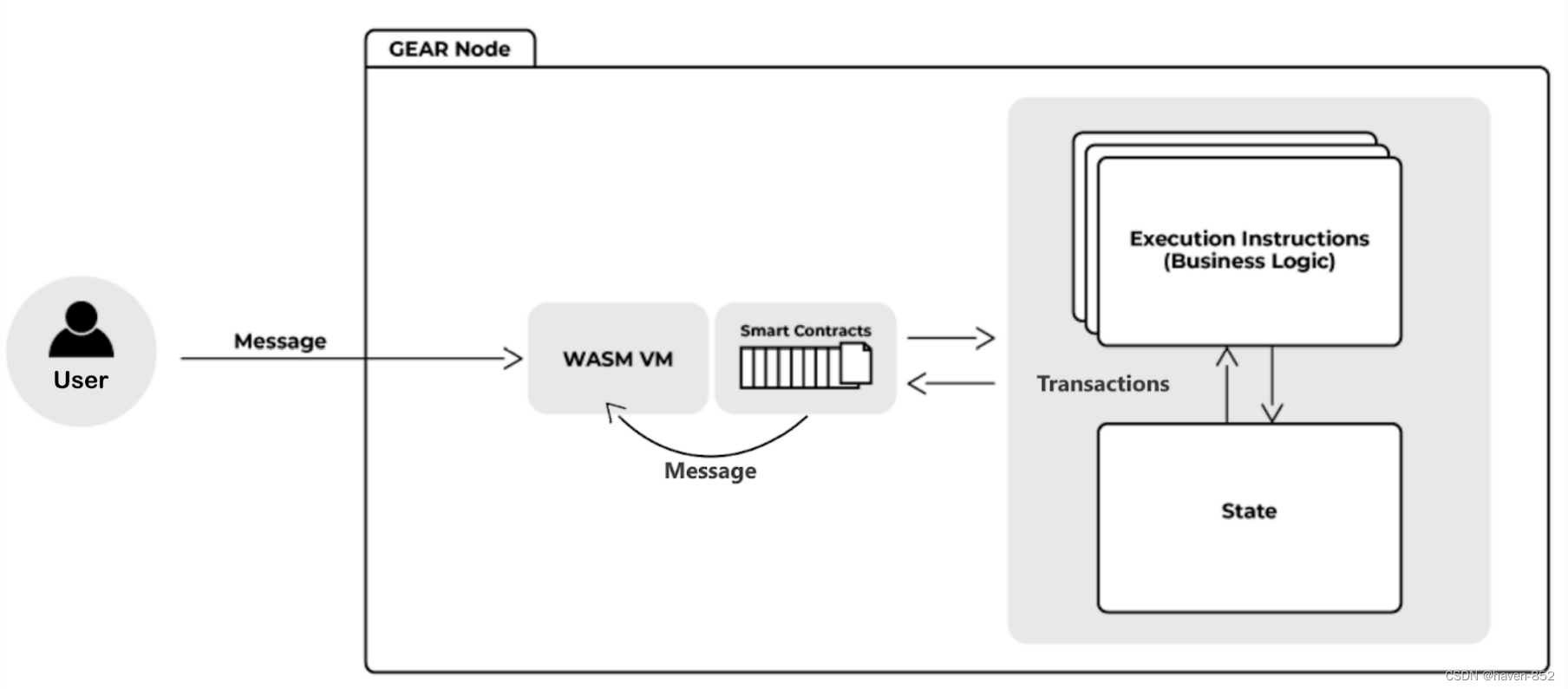
Gear实例包含一个全局消息队列。使用Gear节点,用户可以向特定程序发送包含一条或多条消息的事务。这会填充消息队列。在块构造过程中,消息将出列并路由到特定程序。
对于公共网络,为了防止DoS攻击,需要交易处理的气体/费用。Gear提供了一个余额模块,允许存储用户和程序余额并支付交易费用。
Gear支持以下类型的事务:
并发系统的主要挑战之一是并发控制。它定义了不同程序之间正确的通信顺序,并协调对共享资源的访问。潜在问题包括竞赛条件、死锁和资源匮乏。
并发计算系统可以分为两类通信:
消息传递并发比共享内存并发更容易理解。它通常被认为是一种更健壮的并发编程形式。
通常,消息传递并发比共享内存具有更好的性能特征。在消息传递系统中,每个进程的内存开销和任务切换开销较低。有很多数学理论可以理解消息传递系统,包括Actor模型。
对于进程间通信,Gear使用Actor模型方法。Actor模型越来越受欢迎,并在许多新的编程语言中使用,通常作为一种一流的语言概念。Actor模型的原则是,程序从不共享其状态,只在彼此之间交换消息。
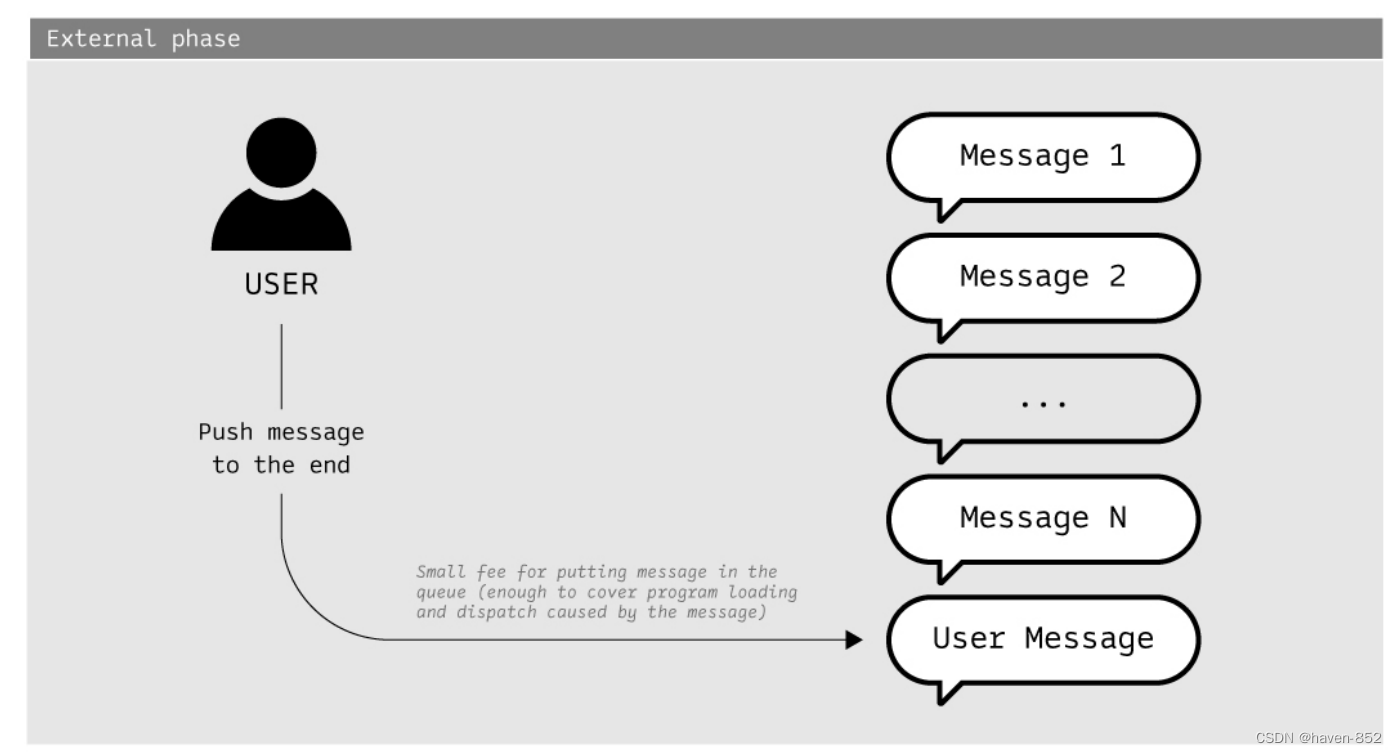
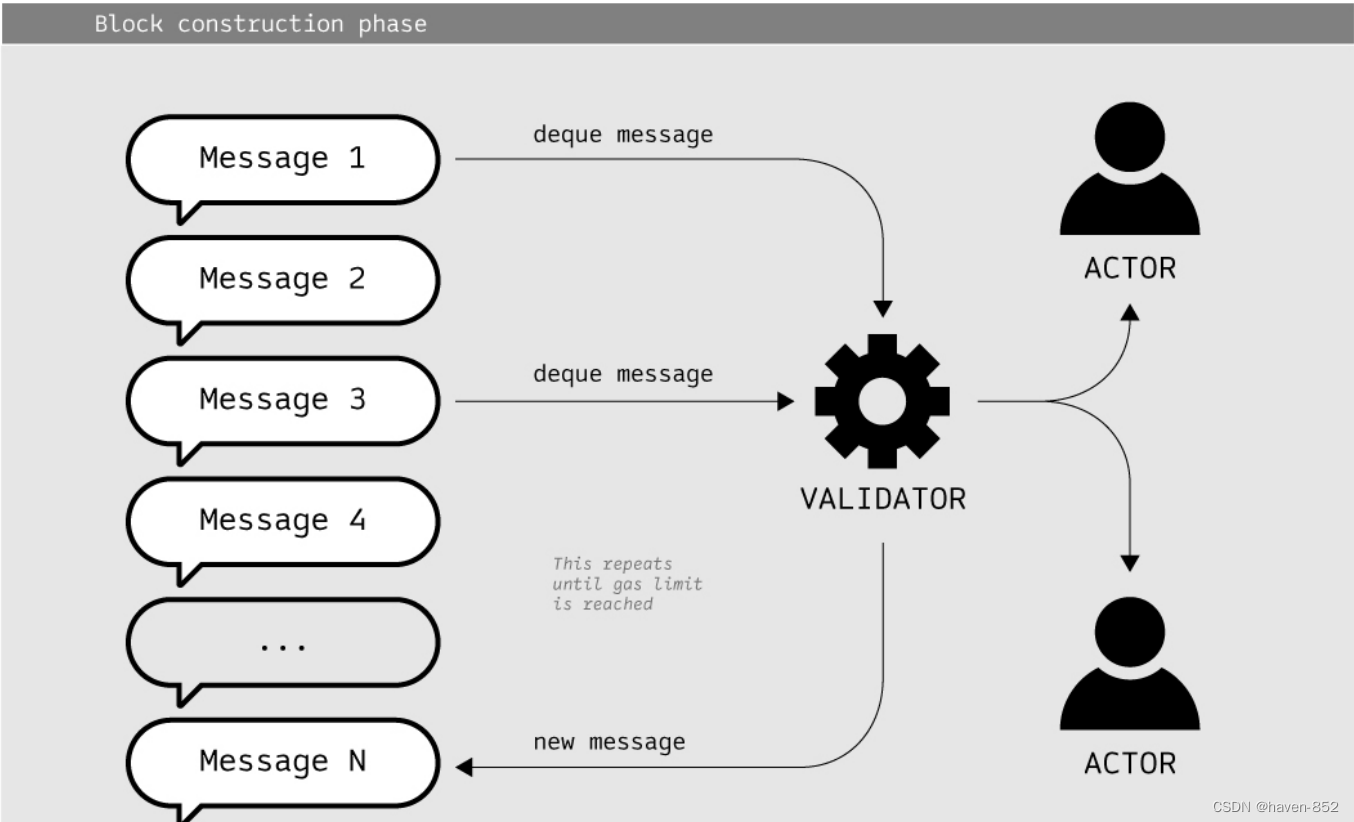
参与者发布出现在消息队列末尾的消息。将消息放入队列需要一些小费用,足以支付消息引起的程序加载和分派。消息由验证器节点出列,并重复此操作,直到达到gas_limit。
虽然在普通的Actor模型中,无法保证消息的顺序,但Gear提供了额外的保证,即两个特定程序之间的消息顺序是保持不变的。
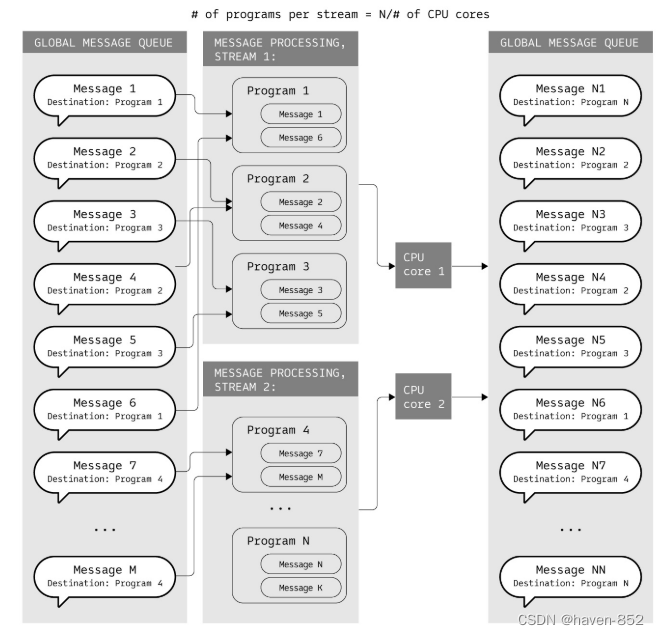
每个程序单独的独立内存空间允许在Gear节点上并行处理消息。消息可以分为多个流,以便并行处理。流的数量是为整个网络配置的,可以等于典型验证器节点的CPU内核数量。每个流都包含用于定义的一组程序的消息。它涉及从其他程序或外部影响(例如,用户的事务)发送的消息。
例如,给定一个消息队列,其中包含针对100个不同程序的消息,以及在配置了2个处理流的网络上运行的Gear节点。Gear引擎使用运行时定义的流数,将目标程序的总数除以流数,并为每个流创建一个消息池(每个流50个程序,由验证器节点的2个CPU核心进行处理)。
程序被分发到不同的流中,每条消息都出现在定义了其目标程序的流中。因此,所有发往特定程序的消息都出现在单个处理流中。
在每个周期中,目标程序可以有多条消息,一个流可以处理多个程序的消息。消息处理的结果是将来自每个流的一组新消息添加到全局消息队列中,然后循环重复。消息处理过程中生成的结果消息通常发送到其他地址(通常返回源或下一个程序)。
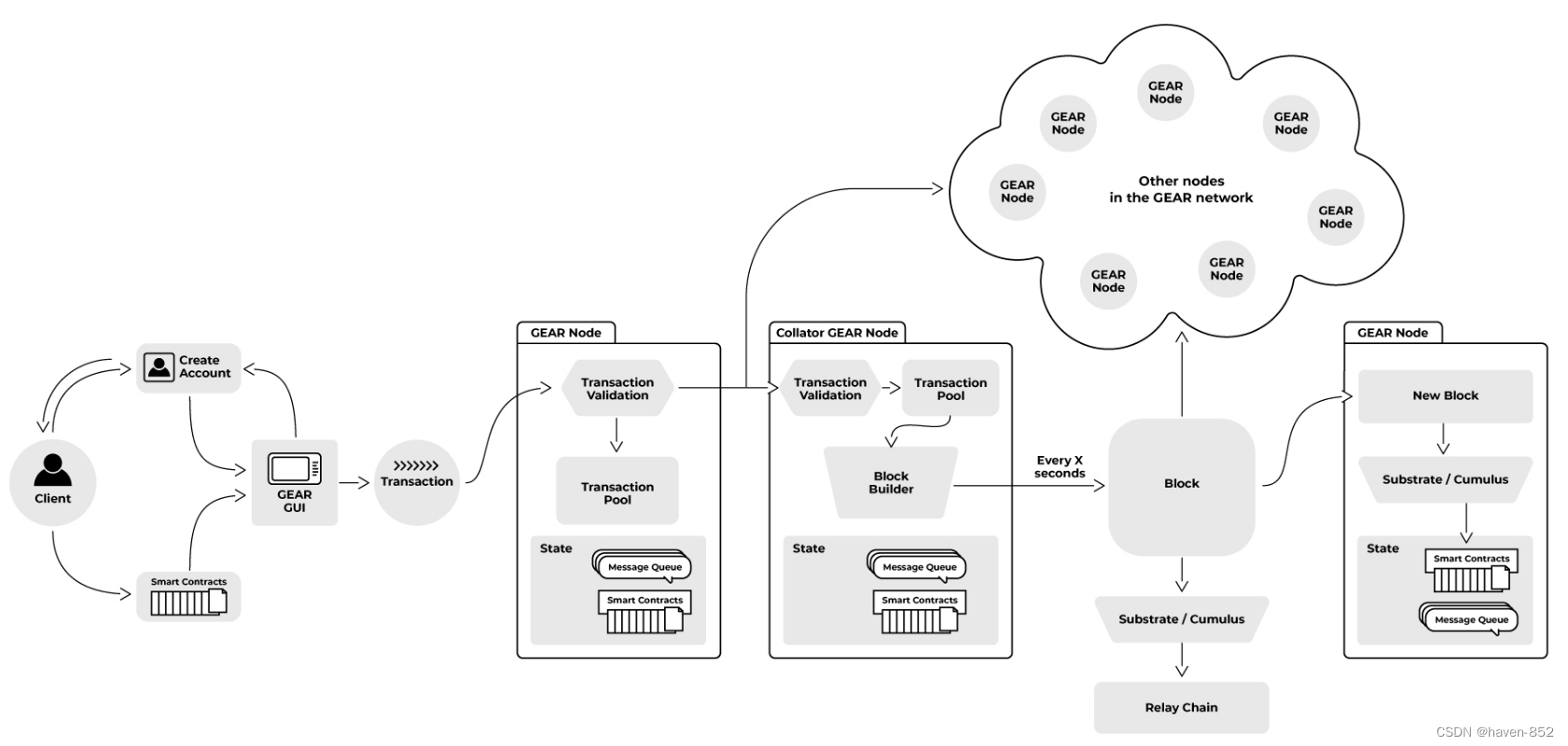
遵循分散原则,Gear网络由许多计算设备组成,这些节点共享一个全局状态。
智能合约开发者(客户端)要做到这一点,客户必须有一个与Gear相连的账户,并有足够的资金支付交易费。
当用户上传程序时,接口将事务发送到任意网络节点。然后,该节点验证事务,如果一切正常,则将其放入事务池,在该池中,它将在网络中的所有节点之间共享。
在Gear中,参与者(用户和程序)通过一条或多条消息相互发送事务。这会填充全局消息队列。网络中的一个特殊节点(collator)将在下一个块中处理事务。在块构造期间,消息在块构造时间的保留空间内出列和处理。建议的区块由其他节点验证,并根据协商一致机制最终确定。消息处理结果以状态保存。
Gear项目优缺点
CSDN优秀解读:https://blog.csdn.net/jiaoyangwm/article/details/1266387752021https://arxiv.org/pdf/2103.14259.pdf关键解读在目标检测中标签分配的最新进展主要寻求为每个GT对象独立定义正/负训练样本。在本文中,我们创新性地从全局的角度重新审视标签分配,并提出将分配程序制定为一个最优传输(OT)问题——优化理论中一个被充分研究的课题。具体来说,我们将每个需求方(锚框)和供应商(GT标签)的单位传输成本定义为他们的分类和回归损失加权之和。在公式化后,找到最好的分配方案即为最小传播成本解决最优传输方案,
Two-StreamConvolutionalNetworksforActionRecognitioninVideos双流网络论文精读论文:Two-StreamConvolutionalNetworksforActionRecognitioninVideos链接:https://arxiv.org/abs/1406.2199本文是深度学习应用在视频分类领域的开山之作,双流网络的意思就是使用了两个卷积神经网络,一个是SpatialstreamConvNet,一个是TemporalstreamConvNet。此前的研究者在将卷积神经网络直接应用在视频分类中时,效果并不好。作者认为可能是因为卷积神经
论文常见数学符号及其含义(科研必备)返回论文和资料目录数学符号在数学领域是非常重要的。在论文中,使用数学符号可以使得论文更加简洁明了,同时也能够准确地描述各种概念和理论。在本篇博客中,我将介绍一些常见的数学符号及其含义(省去特别简单的符号),希望能够帮助读者更好地理解数学论文。高等数学∑i=1nxi\sum_{i=1}^nx_i∑i=1nxi(求和符号):表示将x1,x2,…,xnx_1,x_2,\dots,x_nx1,x2,…,xn中的所有数相加,例如∑i=1nxi\sum_{i=1}^nx_i∑i=1nxi表示将x1,x2,…,xnx_1,x_2,\dots,x_nx1,x
目录文章信息写在前面Background&MotivationMethodDCNV2DCNV3模型架构Experiment分类检测文章信息Title:InternImage:ExploringLarge-ScaleVisionFoundationModelswithDeformableConvolutionsPaperLink:https://arxiv.org/abs/2211.05778CodeLink:https://github.com/OpenGVLab/InternImage写在前面拿到文章之后先看了一眼在ImageNet1k上的结果,确实很高,超越了同等大小下的VAN、RepLK
ChatGPT是一款引人注目的产品,它的突破性功能在各个领域都创造了巨大的需求。仅在发布后的两个月内,就累计了超过1亿的用户。它最突出的功能是能够在几秒钟内完成各种文案创作,包括论文、歌曲、诗歌、睡前故事和散文等。与流行的观点相反,ChatGPT可以做的不仅仅是为你写一篇文章,更有用的是它如何帮助指导您的写作过程和写作方法。接下来手把手教你利用ChatGPT辅助完成写作的五种方法。1.使用ChatGPT生成论文的观点在开始写作之前,我们需要让ChatGPT帮我们充实想法,找到论文切入点。当老师布置论文时,通常会给予学生一个提示,让他们可以自由地表达和分析。这时,我们需要找到论文的角度和思路,然
【前言】去年的这个时候,一边准备考研复试,一边撰写本科毕设论文,读了很多论文,惊叹于其美观的伪代码算法,所以在之前的教程中教大家使用Aurora在Word中插入伪代码,具体可以看使用Aurora在Word中插入算法伪代码教程!!!亲测有效!!!写论文必备https://blog.csdn.net/jucksu/article/details/116307244效果如图所示(附图是本科毕设当中的K-Means聚类算法伪代码),不算很差但不是很美观,包括一些下标,公式,语法,编辑器反应慢,编程体验差,相关参考资料少等方面的缺陷。研究生以来,接触了Latex,学习了overleaf,所以现在教大家使
目录一种简单上手的暴力论文分析方法——以区块链为例【含项目源码】太长不看版本:最终成果:情况说明论文推荐方面论文投稿方面以下是具体的实现,有其他研究方向想自行确定的请仔细阅读,授人以鱼不如授人以渔第一章、确定对象——研究热点的中国计算机研究生第二章、思路——基于爬虫结合关键字过滤暴力获取所需论文信息第一步:从CCF推荐目录中获取网址01、背景介绍02、数据预处理03、数据写入表格第二步:从中科院分区中获取期刊对应分区第三步:从期刊/会议对应网址中爬取到子网页并进入,获取到其中的标题、年份等信息第四步:针对获取到的表格数据进行分析和整理实际爬取数据量【其实就论文的标题+对应年份】
不同格式的符号命名规则符号latex表示意义x\mathcal{x}x$\mathcal{x}$标量x\bm{x}x$\bm{x}$向量x\mathbf{x}x$\mathbf{x}$变量集A\mathbf{A}A$\mathbf{A}$矩阵I\mathbf{I}I$\mathbf{I}$单位矩阵χ\chiχ$\mathbf{\chi}$样本空间或状态空间D\mathcal{D}D$\mathcal{D}$概率分布D\mathbf{D}D$\mathbf{D}$样本数据(数据集)H\mathcal{H}H$\mathcal{H}$假设空间H\mathbf{H}H$\mathbf{H}$假设集L
文章目录一、VisionTransformer论文精读1.1引言1.1.1前言1.1.2摘要1.1.3引言1.2相关工作1.3ViT1.3.1整体结构1.3.2Embedding层结构详解1.3.3TransformerEncoder详解1.3.4MLPHead和`ViT-B/16`模型结构图1.3.5归纳偏置1.3.6Hybrid混合模型试验1.3.7更大尺寸上的微调1.4实验部分1.4.1ViT三个尺寸模型参数对比1.4.2对比其它最新模型1.4.3`visiontrasformer`预训练需要多大的数据规模?(重要论证)1.4.5ViT可视化1.4.6自监督训练1.5附录1.5.1[CL
我正在两篇论文之间实现拖放操作。但是由于我的html正文中有两篇论文,所以我坚持拖动元素的偏移量与光标位置的同步。我对css的经验非常少,这可能会导致问题元素的定位。用例:-用户单击纸2中的元素并开始拖动并转到纸1。在Pointerup上,该元素的克隆被添加到纸1中光标在纸1中的位置。我处理这个问题的策略是:-当用户点击mousedown时1.动态创建div2.创建第三张纸,在新的div中称它为“flypaper”复制要克隆的元素,并将其添加到“flypaper”3.创建一个mousemove监听器,它会用鼠标移动包含“flypaper”的div4.添加一个mouseup事件,当用户释