一、LinkedHashMap
1.定义:
LinkedHashMap是HashMap和双向链表的合二为一,即一个将所有Entry节点链入一个双向链表的HashMap(LinkedHashMap = HashMap + 双向链表)

LinkedHashMap的原理图:
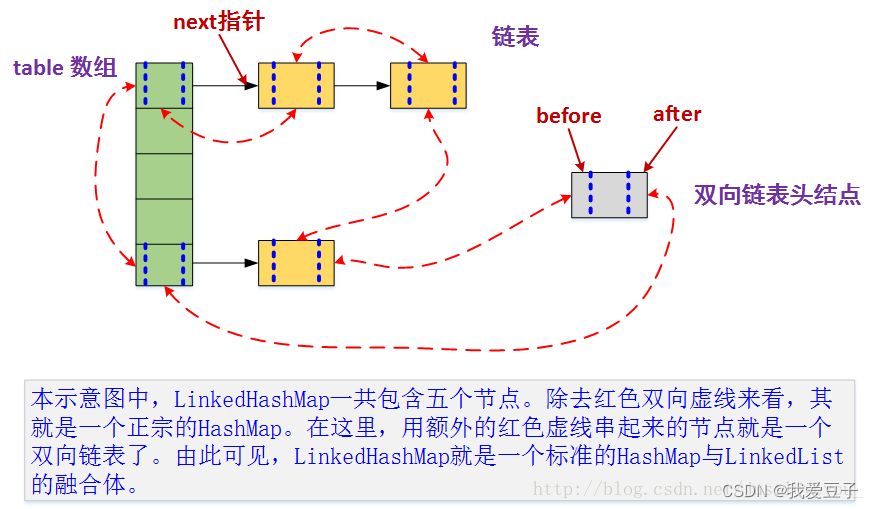
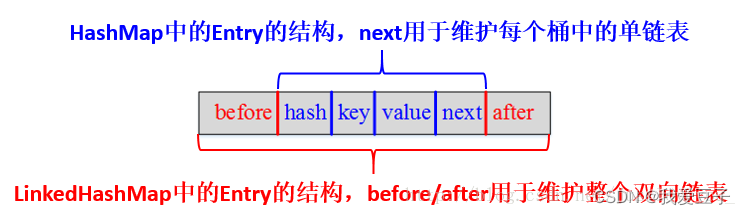
LinkedHashMap和HashMap的Entry结构图:
2.LinkedHashMap在JDK中的定义
LinkedHashMap继承关系:
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>LinkedHashMap成员变量:
private static final long serialVersionUID = 3801124242820219131L;
private transient Entry<K,V> header;//双向链表头节点,也即哨兵节点,里面不存储任何信息
private final boolean accessOrder;//有序性标识LinkedHashMap构造方法(5种):
//传入的参数为初始容量,加载因子,调用了父类的构造方法,按照插入顺序
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
//传入的参数的初始容量,调用父类的构造方法,取得键值对的顺序是插入顺序
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
//无参构造,调用父类的构造方法,取得键值对的顺序是插入顺序
public LinkedHashMap() {
super();
accessOrder = false;
}
//传入的参数是一个Map的集合,调用父类的构造方法,取得键值对的顺序是插入顺序
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super(m);
accessOrder = false;
}
//传入的参数为初始容量,加载因子,有序性标识(键值对保持顺序),调用了父类的构造方法
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}LinkedHashMap的init()方法:
由 LinkedHashMap的五种构造方法可知:
//Hashmap
/**
* Constructs an empty <tt>HashMap</tt> with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
table = new Entry[DEFAULT_INITIAL_CAPACITY];
init();
}
//LinkedHashmap
@Override
void init() {
//header初始化
//hash为-1,其他的参数均为null
//也就是说这个header不在数组中
//只是用来标志开始元素和标志结束元素的
header = new Entry<>(-1, null, null, null);
header.before = header.after = header;
}LinkedHashMap基本数据结构(Entry:具体结构图在定义中):
private static class Entry<K,V> extends HashMap.Entry<K,V> {
// These fields comprise the doubly linked list used for iteration.
Entry<K,V> before, after;
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}LinkedHashMap(Map<? extends K, ? extends V> m):
/**
* Constructs an insertion-ordered <tt>LinkedHashMap</tt> instance with
* the same mappings as the specified map. The <tt>LinkedHashMap</tt>
* instance is created with a default load factor (0.75) and an initial
* capacity sufficient to hold the mappings in the specified map.
*
* @param m the map whose mappings are to be placed in this map
* @throws NullPointerException if the specified map is null
*/
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super(m); // 调用HashMap对应的构造函数
accessOrder = false; // 迭代顺序的默认值
}3.LinkedHashMap的快速存取
LinkedHashMap 的存储实现 : put(key, vlaue)
public V put(K key, V value) {
if (table == EMPTY_TABLE) { //数组为null时
inflateTable(threshold); //给数组根据阈值分配内容空间
}
if (key == null) //key为null时
return putForNullKey(value);
int hash = hash(key); //通过key计算hash
int i = indexFor(hash, table.length); //计算在数组中的索引位置
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
//使用的是LinkedHashMap重写的方法
1
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//addEntry调用的是LinkedHashMap重写了的方法
2
addEntry(hash, key, value, i);
return null;
}void recordAccess(HashMap<K,V> m) { 1
//将传入的HashMap类型的m强制转换成LinkedHashMap类型的
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
//accessOrder默认的是false,当accessOrder为true时进入
if (lm.accessOrder) {
lm.modCount++;
//移除当前节点
remove();
3
addBefore(lm.header);
}
}
void addEntry(int hash, K key, V value, int bucketIndex) { 2
// 重写了HashMap中的createEntry方法
createEntry(hash, key, value, bucketIndex);
// Remove eldest entry if instructed
Entry<K,V> eldest = header.after; //还是header自身
if (removeEldestEntry(eldest)) { 4
removeEntryForKey(eldest.key);
} else {
//扩容到原来的2倍
if (size >= threshold) 5
resize(2 * table.length);
}
}
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) { 4
return false;
}
void createEntry(int hash, K key, V value, int bucketIndex) {
// 向哈希表中插入Entry,这点与HashMap中相同
//创建新的Entry并将其链入到数组对应桶的链表的头结点处,
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<K,V>(hash, key, value, old);
table[bucketIndex] = e;
//在每次向哈希表插入Entry的同时,都会将其插入到双向链表的尾部,
//这样就按照Entry插入LinkedHashMap的先后顺序来迭代元素
//(LinkedHashMap根据双向链表重写了迭代器)
//同时,新put进来的Entry是最近访问的Entry,把其放在链表末尾 ,也符合LRU算法的实现
e.addBefore(header);
size++;
}
//插入有序不做处理,在访问有序做相应处理:addBefore(将当前节点插到header的前面)
private void addBefore(Entry<K,V> existingEntry) { 3
after = existingEntry; //existingEntry即为header
before = existingEntry.before;
before.after = this; //this即为要插入的节点
after.before = this;
}
void resize(int newCapacity) { 5
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
// 若 oldCapacity 已达到最大值,直接将 threshold 设为 Integer.MAX_VALUE
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return; // 直接返回
}
// 否则,创建一个更大的数组
Entry[] newTable = new Entry[newCapacity];
//将每条Entry重新哈希到新的数组中
6
transfer(newTable); //LinkedHashMap对它所调用的transfer方法进行了重写
table = newTable;
threshold = (int)(newCapacity * loadFactor); // 重新设定 threshold
}
void transfer(HashMap.Entry[] newTable) { 6
int newCapacity = newTable.length;
// 与HashMap相比,借助于双向链表的特点进行重哈希使得代码更加简洁
for (Entry<K,V> e = header.after; e != header; e = e.after) {
int index = indexFor(e.hash, newCapacity); // 计算每个Entry所在的桶
// 将其链入桶中的链表
e.next = newTable[index];
newTable[index] = e;
}
}LinkedHashMap 的读取实现 :get(Object key)
public V get(Object key) {
//调用父类HashMap的getEntry()方法,取得要查找的元素
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null)
return null;
// 记录访问顺序
e.recordAccess(this);
return e.value;
}
private static class Entry<K,V> extends HashMap.Entry<K,V> {
// These fields comprise the doubly linked list used for iteration.
Entry<K,V> before, after;
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
//在HashMap的put和get方法中,会调用该方法,在HashMap中该方法为空;
//在LinkedHashMap中,
//当按访问顺序排序时,该方法会将当前节点插入到链表尾部(头结点的前一个节点),
//否则不做任何事
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
if (lm.accessOrder) {
lm.modCount++;
//移除当前节点
remove();
//将当前节点插入到头结点前面
addBefore(lm.header);
}
}
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}二、LinkeList与LRU(Least recently used,最近最少使用)算法
当accessOrder标志位为true时,表示双向链表中的元素按照访问的先后顺序排列,可以看到,虽然Entry插入链表的顺序依然是按照其put到LinkedHashMap中的顺序,但put和get方法均有调用recordAccess方法(put方法在key相同时会调用)
recordAccess方法判断accessOrder是否为true,如果是,则将当前访问的Entry(put进来的Entry或get出来的Entry)移到双向链表的尾部(key不相同时,put新Entry时,会调用addEntry,它会调用createEntry,该方法同样将新插入的元素放入到双向链表的尾部,既符合插入的先后顺序,又符合访问的先后顺序,因为这时该Entry也被访问了)
当标志位accessOrder的值为false时,表示双向链表中的元素按照Entry插入LinkedHashMap到中的先后顺序排序,即每次put到LinkedHashMap中的Entry都放在双向链表的尾部,这样遍历双向链表时,Entry的输出顺序便和插入的顺序一致,这也是默认的双向链表的存储顺序
当标志位accessOrder的值为false时,虽然也会调用recordAccess方法,但不做任何操作
具体分析代码见内容一、LinkedList
1.使用LinkedList实现LRU算法
public class LRU<K,V> extends LinkedHashMap<K, V> implements Map<K, V>{
private static final long serialVersionUID = 1L;
public LRU(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor, accessOrder);
}
/**
* @description 重写LinkedHashMap中的removeEldestEntry方法,当LRU中元素多余6个时,
* 删除最不经常使用的元素
* @author rico
* @created 2017年5月12日 上午11:32:51
* @param eldest
* @return
* @see java.util.LinkedHashMap#removeEldestEntry(java.util.Map.Entry)
*/
@Override
protected boolean removeEldestEntry(java.util.Map.Entry<K, V> eldest) {
// TODO Auto-generated method stub
if(size() > 6){
return true;
}
return false;
}
public static void main(String[] args) {
LRU<Character, Integer> lru = new LRU<Character, Integer>(
16, 0.75f, true);
String s = "abcdefghijkl";
for (int i = 0; i < s.length(); i++) {
lru.put(s.charAt(i), i);
}
System.out.println("LRU中key为h的Entry的值为: " + lru.get('h'));
System.out.println("LRU的大小 :" + lru.size());
System.out.println("LRU :" + lru);
}
}代码运行结果图
2.LinkedList有序性原理分析
LinkedHashMap 增加了双向链表头结点header 和 标志位accessOrder两个属性用于保证迭代顺序。但是要想真正实现其有序性,还差临门一脚,那就是重写HashMap 的迭代器,其源码实现如下:
private abstract class LinkedHashIterator<T> implements Iterator<T> {
Entry<K,V> nextEntry = header.after;
Entry<K,V> lastReturned = null;
/**
* The modCount value that the iterator believes that the backing
* List should have. If this expectation is violated, the iterator
* has detected concurrent modification.
*/
int expectedModCount = modCount;
public boolean hasNext() { // 根据双向列表判断
return nextEntry != header;
}
public void remove() {
if (lastReturned == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
LinkedHashMap.this.remove(lastReturned.key);
lastReturned = null;
expectedModCount = modCount;
}
Entry<K,V> nextEntry() { // 迭代输出双向链表各节点
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (nextEntry == header)
throw new NoSuchElementException();
Entry<K,V> e = lastReturned = nextEntry;
nextEntry = e.after;
return e;
}
}
// Key 迭代器,KeySet
private class KeyIterator extends LinkedHashIterator<K> {
public K next() { return nextEntry().getKey(); }
}
// Value 迭代器,Values(Collection)
private class ValueIterator extends LinkedHashIterator<V> {
public V next() { return nextEntry().value; }
}
// Entry 迭代器,EntrySet
private class EntryIterator extends LinkedHashIterator<Map.Entry<K,V>> {
public Map.Entry<K,V> next() { return nextEntry(); }
}三、总结
参考文章:
(LRU与linkedlist建议看Github)Java-Tutorial/Java集合详解5:深入理解LinkedHashMap和LRU缓存.md at master · h2pl/Java-Tutorial · GitHub
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
Ⅰ软件测试基础一、软件测试基础理论1、软件测试的必要性所有的产品或者服务上线都需要测试2、测试的发展过程3、什么是软件测试找bug,发现缺陷4、测试的定义使用人工或自动的手段来运行或者测试某个系统的过程。目的在于检测它是否满足规定的需求。弄清预期结果和实际结果的差别。5、测试的目的以最小的人力、物力和时间找出软件中潜在的错误和缺陷6、测试的原则28原则:20%的主要功能要重点测(eg:支付宝的支付功能,其他功能都是次要的)80%的错误存在于20%的代码中7、测试标准8、测试的基本要求功能测试性能测试安全性测试兼容性测试易用性测试外观界面测试可靠性测试二、质量模型衡量一个优秀软件的维度①功能性功
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear