本文基础知识大部分来自于大学学习的 计算机组成原理,计算机科学技术导论等教材
编程语言中,多数都会由byte类型,那byte类型是一个什么样的概念呢,占用字节数为1,为什么值范围是-128~127呢,带着这样的疑问我们进入话题
十进制数 97 和-97对应的二进制 1100001 和 -1100001
在数学中,是将正号“十”和负号“一”放在绝对值前面来表示该数是正数还是负数的。而在计算机中则使用符号位来表示正、负数。符号位规定放在数的最前面,并用“0”表示正数,用“1”表示负数。这样,数的符号也数码化了。在计算机中,负数有三种表示方法:原码、反码和补码。任何正数的原码、补码和反码的形式完全相同,而负数则有各种不同的表示形式。为区分起见,将原来用一般形式表示的数X称为机器数的真值,而将数在计算机内的各种编码表示称为机器数,根据表示方法的不同分别记为[X]原、[X]反和[X]补等
在由日常数据转换为计算机硬件能够直接识别、处理的机器数时,需要解决三个问题
1. 只能采用二进制数,每位数码非0即1;2. 将符号位数字化,如用0表示正号,用1表示负号;3. 采用什么编码方法表示数值。
原码表示法约定:让数码序列的最高位为符号位,符号位为0表示该数为正,为1表示该数为负;数码序列的其余部分为有效数值,用二进制数绝对值表示。
97对应的 原码:0 1100001 -97对应的原码:1 1100001
正数的反码是其本身(等于原码);负数的反码是将原码中除符号位以外的所有位(数值位)取反,也就是 0 变成 1,1 变成 0
97 的 原码和反码都是:0 1100001
-97 的原码:1 1100001
-97 的反码:1 0011110
假设 我们用原码进行加减法操作,示例 十进制 -2 对应二进制 1 0000010,十进制 3 对应二进制 0 0000011,正数之间是不会有问题的,但负数相加就会出现一些问题
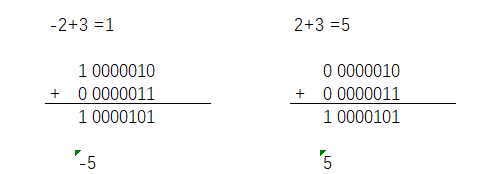
为了克服原码表示法在加、减运算中的缺点,引入了补码表示法,并以此作为加、减运算的基础。引入补码表示法的目的是:让符号位也作为数值的一部分直接参与运算,以简化加、减运算的规则,同时又能化减为加。下面举个例子说明补码的思想:
如 时钟。时钟以12为一个计数循环,在有模运算中称为“以12为模”。13点舍去模12后,就是1点。从0点位置出发,沿反时针方向将时针拨动-1格(即-1点),等同于沿顺时针方向拨动11格(即11点)。换句话说,在以12为模的前提下,-1可以映射为+11。由此我们得到启发:在有模运算中,一个负数可以用一个与它互为补码的正数来代替。
补码示例

注:数的原码表示形式简单,适合于进行乘除运算,但用原码表示的数进行加减运算比较复杂。引入补码以后,减法运算可以使用加法来实现,且数的符号位也可以当作运算值一样参加运算,因此在计算机中大都采用补码来进行加减运算。
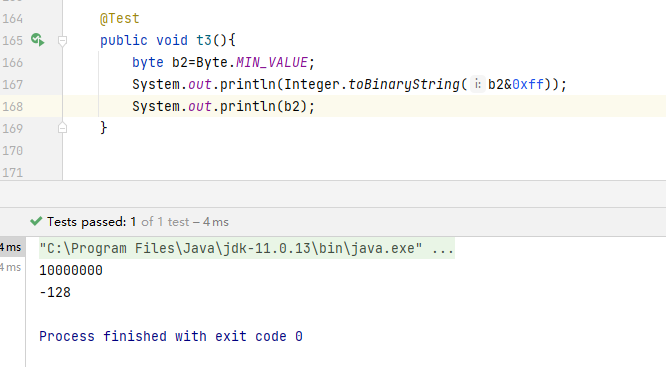
在绝大多数语言中 Byte结构都是 1字节 范围 [-128,127]
这个参考上文讲的 机器数 是计算机里存储的,计算机可以识别的数,所以 Byte 1字节是8位,可以表示的范围是 0000 0000 ~ 1111 1111,注意此处存储的是 原数值的补码
正数部分:正数的补码还是自己,即 0000 0000 ~ 0111 1111 表示范围是 [0,127] ,
负数部分:负数的补码 是该数的原码除负号位外各位取反,然后在最后一位加1,
即 1111 1111 ~ 1000 0000 对应的原值 1 0000 0000 ~ 1000 0001 即为 [-128,-1]
注意:其实有的时候很难理解 把 1000 0000 转换为 -128,这个原因是 高位被截断,其实他的原码应该是 1 0000 0000 然后取补码得到 1000 0000
以下为Java代码示例
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame
您将如何构建一个简单的Sinatra应用程序?我正在制作,我希望该应用具有以下功能:“应用程序”更像是一个包含所有信息的管理仪表板。然后另一个应用程序将通过REST访问信息。我还没有创建仪表板,只是从数据库中获取东西session和身份验证(尚未实现)您可以上传图片,其他应用可以显示这些图片我已经使用RSpec创建了一个测试文件通过Prawn生成报告目前的设置是这样的:app.rbtest_app.rb因为我实际上只有应用程序和测试文件。到目前为止,我已经将Datamapper用于ORM,将SQLite用于数据库。这是我的第一个Ruby/Sinatra项目,所以欢迎任何和所有建议-我应
我想编写一个ruby脚本来递归复制目录结构,但排除某些文件类型。因此,给定以下目录结构:folder1folder2file1.txtfile2.txtfile3.csfile4.htmlfolder2folder3file4.dll我想复制这个结构,但不包含.txt和.cs文件。因此,生成的目录结构应如下所示:folder1folder2file4.htmlfolder2folder3file4.dll 最佳答案 您可以使用查找模块。这是一个代码片段:require"find"ignored_extensions=[".cs"
对于我正在编写的Rails3应用程序,我正在考虑从本地文件系统上的XML、YAML或JSON文件中读取一些配置数据。重点是:我应该把这些文件放在哪里?Rails应用程序中是否有用于存储此类内容的默认位置?附带说明一下,我的应用程序部署在Heroku上。 最佳答案 我经常做的是:如果文件是通用配置文件:我在目录/config中创建一个YAML文件,每个环境有一个上层key如果我为每个环境(大项目)创建一个文件:我为每个环境创建一个YAML并将它们存储在/config/environments/然后我在加载YAML的地方创建了一个初始化
在我的mac上安装几个东西时遇到这个问题,我认为这个问题来自将我的豹子升级到雪豹。我认为这个问题也与macports有关。/usr/local/lib/libz.1.dylib,filewasbuiltfori386whichisnotthearchitecturebeinglinked(x86_64)有什么想法吗?更新更具体地说,这发生在安装nokogirigem时日志看起来像:xslt_stylesheet.c:127:warning:passingargument1of‘Nokogiri_wrap_xml_document’withdifferentwidthduetoproto
我刚刚开始从Ruby1.8.7升级到Ruby1.9.2(使用RVM)。我的所有应用程序都使用“脚本/服务器”(或“rails服务器”)和1.9.2运行,但是,只有Rails3.0.0RC应用程序可以与Passenger一起使用。Rails2.3.8应用给出的错误信息是:invalidbytesequenceinUS-ASCII我猜这是一个Passenger问题。我使用找到的RVM指南安装了Passenger2.2.15here.任何想法如何修复这个错误?谢谢。我已更新以包含堆栈跟踪:/Users/kevin/.rvm/gems/ruby-1.9.2-p0/gems/actionpack
尝试在我的Rails应用程序中导入CSV文件时,出现错误UTF-8中的无效字节序列。一切正常,直到我添加了一个gsub方法来将其中一个CSV列与我的数据库中的一个字段进行比较。当我导入CSV文件时,我想检查每一行的地址是否包含在特定客户端的不同地址数组中。我有一个带有alt_addresses属性的客户端模型,其中包含客户端地址的几种不同可能格式。然后我有一个引用模型(如果您熟悉本地SEO,您就会知道这个术语)。引用模型没有地址字段,但它有一个nap_correct?字段(NAP代表“姓名”、“地址”、“电话号码”)。如果CSV行的名称、地址和电话号码与我在该客户的数据库中拥有的相同,
1.回顾.TransportServicepublicclassTransportServiceextendsAbstractLifecycleComponentTransportService:方法:1publicfinalTextendsTransportResponse>voidsendRequest(finalTransport.Connectionconnection,finalStringaction,finalTransportRequestrequest,finalTransportRequestOptionsoptions,TransportResponseHandlerT>