
actor ChickenFeeder {
let food = "worms"
var numberOfEatingChickens: Int = 0
}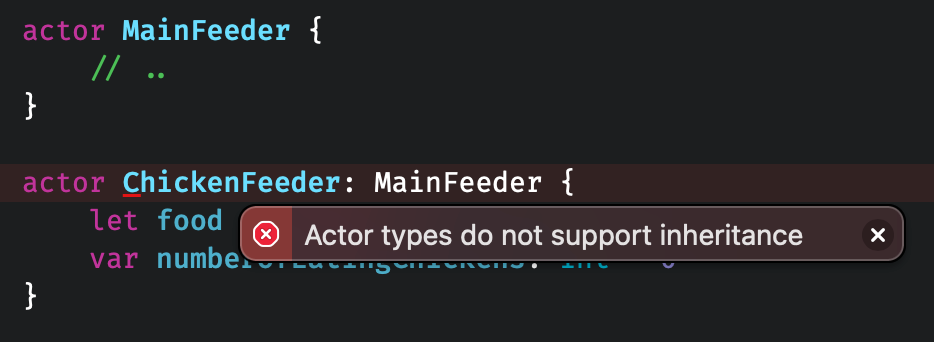 Swift中的Actor几乎和类一样,但不支持继承。Swift 中的 Actor 几乎和类一样,但不支持继承。不支持继承意味着不需要像便利初始化器和必要初始化器、重写、类成员或 open 和 final 语句等功能。然而,最大的区别是由 Actor 的主要职责决定的,即隔离对数据的访问。
Swift中的Actor几乎和类一样,但不支持继承。Swift 中的 Actor 几乎和类一样,但不支持继承。不支持继承意味着不需要像便利初始化器和必要初始化器、重写、类成员或 open 和 final 语句等功能。然而,最大的区别是由 Actor 的主要职责决定的,即隔离对数据的访问。final class ChickenFeederWithQueue {
let food = "worms"
/// 私有支持属性和计算属性的组合允许同步访问。
private var _numberOfEatingChickens: Int = 0
var numberOfEatingChickens: Int {
queue.sync {
_numberOfEatingChickens
}
}
/// 一个并发的队列,允许同时进行多次读取。
private var queue = DispatchQueue(label: "chicken.feeder.queue", attributes: .concurrent)
func chickenStartsEating() {
/// 使用栅栏阻止写入时的读取
queue.sync(flags: .barrier) {
_numberOfEatingChickens += 1
}
}
func chickenStopsEating() {
/// 使用栅栏阻止写入时的读取
queue.sync(flags: .barrier) {
_numberOfEatingChickens -= 1
}
}
}actor ChickenFeeder {
let food = "worms"
var numberOfEatingChickens: Int = 0
func chickenStartsEating() {
numberOfEatingChickens += 1
}
func chickenStopsEating() {
numberOfEatingChickens -= 1
}
} Methods in Actors are isolated for synchronized access.Actors 中的方法是隔离的,以便同步访问。在访问可变属性 numberOfEatingChickens 时,也会发生同样的情况:
Methods in Actors are isolated for synchronized access.Actors 中的方法是隔离的,以便同步访问。在访问可变属性 numberOfEatingChickens 时,也会发生同样的情况: Mutable properties can only be accessed from within the Actor.可变的属性只能从 Actor 内部访问。然而,我们被允许编写以下代码:
Mutable properties can only be accessed from within the Actor.可变的属性只能从 Actor 内部访问。然而,我们被允许编写以下代码:let feeder = ChickenFeeder()
print(feeder.food)let feeder = ChickenFeeder()
await feeder.chickenStartsEating()
print(await feeder.numberOfEatingChickens) // Prints: 1extension ChickenFeeder {
func notifyObservers() {
NotificationCenter.default.post(name: NSNotification.Name("chicken.started.eating"), object: numberOfEatingChickens)
}
}let feeder = ChickenFeeder()
await feeder.chickenStartsEating()
await feeder.notifyObservers()func chickenStartsEating() {
numberOfEatingChickens += 1
notifyObservers()
}let feeder = ChickenFeeder()
await feeder.printWhatChickensAreEating()extension ChickenFeeder {
nonisolated func printWhatChickensAreEating() {
print("Chickens are eating \(food)")
}
}
let feeder = ChickenFeeder()
feeder.printWhatChickensAreEating()extension ChickenFeeder: CustomStringConvertible {
nonisolated var description: String {
"A chicken feeder feeding \(food)"
}
}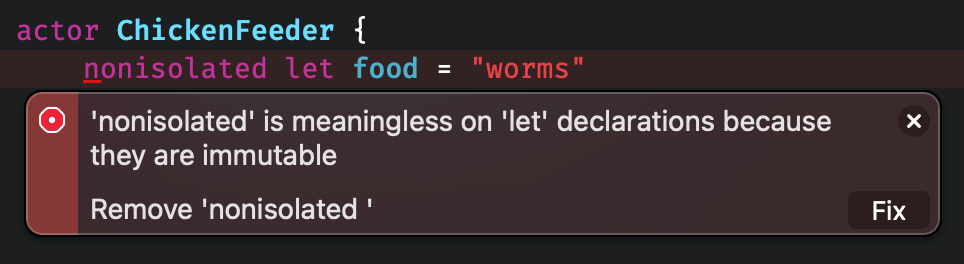 Marking immutable properties nonisolated is redundant.将不可变的属性标记为 nonisolated 是多余的。
Marking immutable properties nonisolated is redundant.将不可变的属性标记为 nonisolated 是多余的。queueOne.async {
await feeder.chickenStartsEating()
}
queueTwo.async {
print(await feeder.numberOfEatingChickens)
}我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
给定这段代码defcreate@upgrades=User.update_all(["role=?","upgraded"],:id=>params[:upgrade])redirect_toadmin_upgrades_path,:notice=>"Successfullyupgradeduser."end我如何在该操作中实际验证它们是否已保存或未重定向到适当的页面和消息? 最佳答案 在Rails3中,update_all不返回任何有意义的信息,除了已更新的记录数(这可能取决于您的DBMS是否返回该信息)。http://ar.ru
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i