1
/ \
2 3
/ \ \
4 5 6
层次遍历使用 BFS 实现,利用的就是 BFS 一层一层遍历的特性;而前序、中序、后序遍历利用了 DFS 实现。
前序、中序、后序遍只是在对节点访问的顺序有一点不同,其它都相同。
① 前序
void dfs(TreeNode root) {
visit(root);
dfs(root.left);
dfs(root.right);
}
② 中序
void dfs(TreeNode root) {
dfs(root.left);
visit(root);
dfs(root.right);
}
③ 后序
void dfs(TreeNode root) {
dfs(root.left);
dfs(root.right);
visit(root);
}
给你一棵二叉树的根节点 root ,返回其节点值的 后序遍历 。
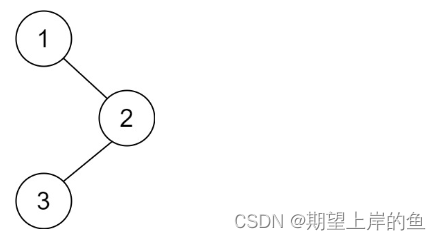
输入:root = [1,null,2,3]
输出:[3,2,1]
输入:root = []
输出:[]
输入:root = [1]
输出:[1]
提示:
进阶: 递归算法很简单,你可以通过迭代算法完成吗?
法一:DFS
法二:迭代
后序的迭代遍历可以理解成 ” 前序遍历 “ 的反转:(前序遍历)
法一:递归
Java
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public List<Integer> ans = new ArrayList<>();
public List<Integer> postorderTraversal(TreeNode root) {
dfs(root);
return ans;
}
public void dfs(TreeNode root){
if(root == null) return;
dfs(root.left);
dfs(root.right);
ans.add(root.val);
}
}
C++
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<int> ans;
vector<int> postorderTraversal(TreeNode* root) {
dfs(root);
return ans;
}
void dfs(TreeNode* root){
if(root == nullptr) return;
dfs(root->left);
dfs(root->right);
ans.push_back(root->val);
}
};
法二:迭代
Java
class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> ans = new ArrayList<>();
if(root == null) return ans;
Stack<TreeNode> stk = new Stack<>();
stk.push(root);
while(!stk.isEmpty()){
root = stk.pop();
ans.add(root.val);
if(root.left != null) stk.push(root.left);
if(root.right != null) stk.push(root.right);
}
Collections.reverse(ans);
return ans;
}
}
C++
class Solution {
public:
vector<int> postorderTraversal(TreeNode* root) {
vector<int> ans;
if(root == nullptr) return ans;
stack<TreeNode*> stk;
stk.push(root);
while(!stk.empty()){
root = stk.top();
stk.pop();
ans.push_back(root->val);
if(root->left != nullptr) stk.push(root->left);
if(root->right != nullptr) stk.push(root->right);
}
reverse(ans.begin(), ans.end());
return ans;
}
};

n 是二叉树的节点数。每一个节点恰好被遍历一次。题目来源:力扣。
放弃一件事很容易,每天能坚持一件事一定很酷,一起每日一题吧!
关注我 leetCode专栏,每日更新!
我有多个ActiveRecord子类Item的实例数组,我需要根据最早的事件循环打印。在这种情况下,我需要打印付款和维护日期,如下所示:ItemAmaintenancerequiredin5daysItemBpaymentrequiredin6daysItemApaymentrequiredin7daysItemBmaintenancerequiredin8days我目前有两个查询,用于查找maintenance和payment项目(非排他性查询),并输出如下内容:paymentrequiredin...maintenancerequiredin...有什么方法可以改善上述(丑陋的)代
我有一个服务模型/表及其注册表。在表单中,我几乎拥有服务的所有字段,但我想在验证服务对象之前自动设置其中一些值。示例:--服务Controller#创建Action:defcreate@service=Service.new@service_form=ServiceFormObject.new(@service)@service_form.validate(params[:service_form_object])and@service_form.saverespond_with(@service_form,location:admin_services_path)end在验证@ser
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
ValidPalindromeGivenastring,determineifitisapalindrome,consideringonlyalphanumericcharactersandignoringcases. [#125]Example:"Aman,aplan,acanal:Panama"isapalindrome."raceacar"isnotapalindrome.Haveyouconsiderthatthestringmightbeempty?Thisisagoodquestiontoaskduringaninterview.Forthepurposeofthisproblem
所以这可能有点令人困惑,但请耐心等待。简而言之,我想遍历具有特定键值的所有属性,然后如果值不为空,则将它们插入到模板中。这是我的代码:属性:#===DefaultfileConfigurations#default['elasticsearch']['default']['ES_USER']=''default['elasticsearch']['default']['ES_GROUP']=''default['elasticsearch']['default']['ES_HEAP_SIZE']=''default['elasticsearch']['default']['MAX_OP
我正在我的Rails项目中安装Grape以构建RESTfulAPI。现在一些端点的操作需要身份验证,而另一些则不需要身份验证。例如,我有users端点,看起来像这样:moduleBackendmoduleV1classUsers现在如您所见,除了password/forget之外的所有操作都需要用户登录/验证。创建一个新的端点也没有意义,比如passwords并且只是删除password/forget从逻辑上讲,这个端点应该与用户资源。问题是Grapebefore过滤器没有像except,only这样的选项,我可以在其中说对某些操作应用过滤器。您通常如何干净利落地处理这种情况?
在我做的一些网络开发中,我有多个操作开始,比如对外部API的GET请求,我希望它们同时开始,因为一个不依赖另一个的结果。我希望事情能够在后台运行。我找到了concurrent-rubylibrary这似乎运作良好。通过将其混合到您创建的类中,该类的方法具有在后台线程上运行的异步版本。这导致我编写如下代码,其中FirstAsyncWorker和SecondAsyncWorker是我编写的类,我在其中混合了Concurrent::Async模块,并编写了一个名为“work”的方法来发送HTTP请求:defindexop1_result=FirstAsyncWorker.new.async.
我们有一个字符串:“”这个正则表达式://i如何从当前字符串中获取所有匹配项? 最佳答案 "".scan(//)参见scan在ruby-docs上 关于ruby-如何遍历Ruby中所有正则表达式匹配的字符串?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/6857852/
是否可以在所有delayed_job任务之前运行一个方法?基本上,我们试图确保每个运行delayed_job的服务器都有我们代码的最新实例,所以我们想运行一个方法来在每个作业运行之前检查它。(我们已经有了“check”方法并在别处使用它。问题只是关于如何从delayed_job中调用它。) 最佳答案 现在有一种官方方法可以通过插件来做到这一点。这篇博文通过示例清楚地描述了如何执行此操作http://www.salsify.com/blog/delayed-jobs-callbacks-and-hooks-in-rails(本文中描述
我无法从for循环中获取变量。似乎i(var)是稍后计算的,而不是我完全需要的类定义。ree-1.8.7-2010.02>classPatree-1.8.7-2010.02?>foriin39..47ree-1.8.7-2010.02?>define_method("a#{i}".to_sym)doree-1.8.7-2010.02>putsiree-1.8.7-2010.02?>endree-1.8.7-2010.02?>endree-1.8.7-2010.02?>end#=>39..47ree-1.8.7-2010.02>p=Pat.new#=>#ree-1.8.7-2010.02