首先从GitHub克隆到服务器上。
git clone https://github.com/ki9mu/ARL-plus-docker/
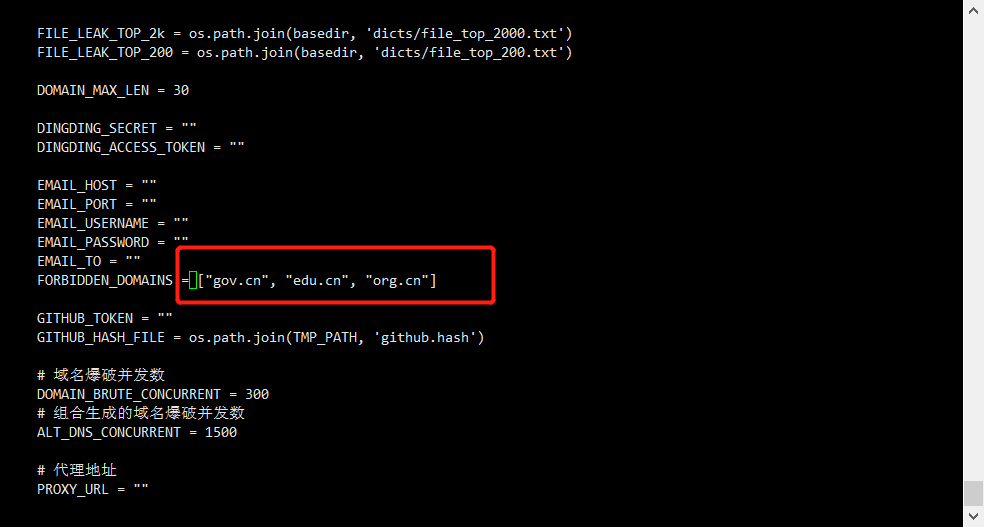
因为ARL在配置文件里设置了黑名单,有时候项目为GOV或者EDU之类的时候无法进行扫描,所以在这里修改一下配置文件就可以解除限制。
cd ARL-plus-docker/
vi config-docker.yaml在这里删掉黑名单里的几项就可以了

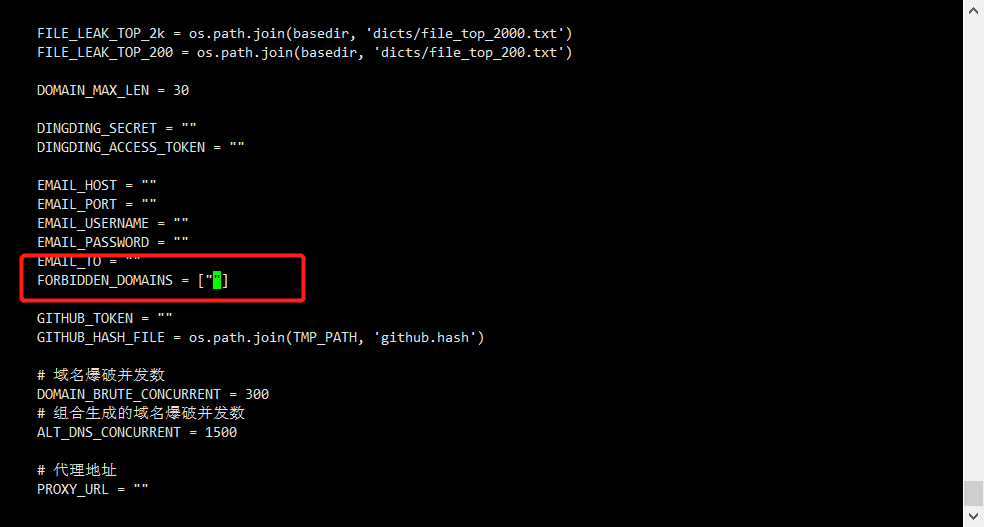
修改后:

增加和修改riskiq以及fofa API

再增强版里添加了Oneforall的模块,所以在配置文件里需要打开,因为clone下来的代码里默认是Flase,这里将需要想打开的开关替换为Ttue即可。
vi oneforall-config/setting.py 
修改后:
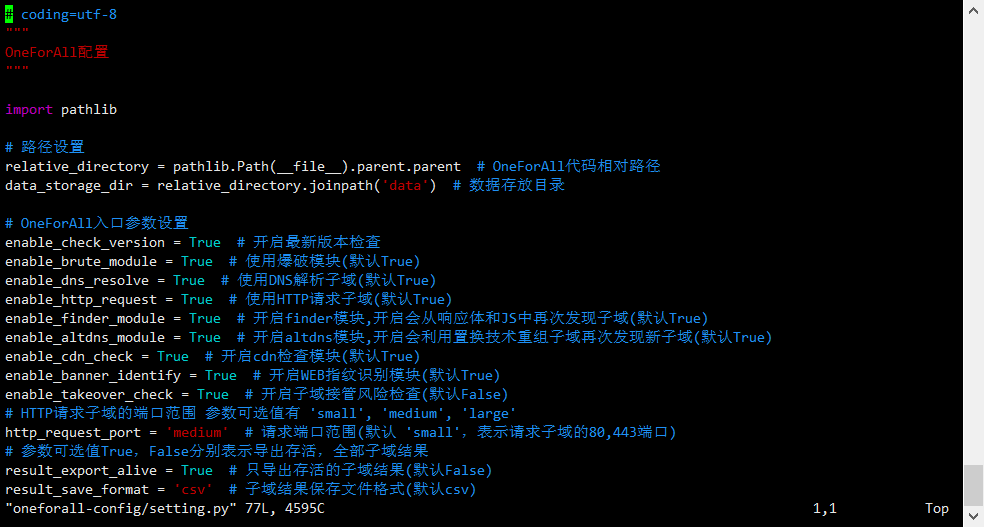
修改为配置文件之后就开始启动docker,先添加一个volume,然后docker-compose up -d就可以直接启动,拉取镜像的时候如果很慢可以换一下docker源。
docker volume create --name=arl_db
docker-compose up -d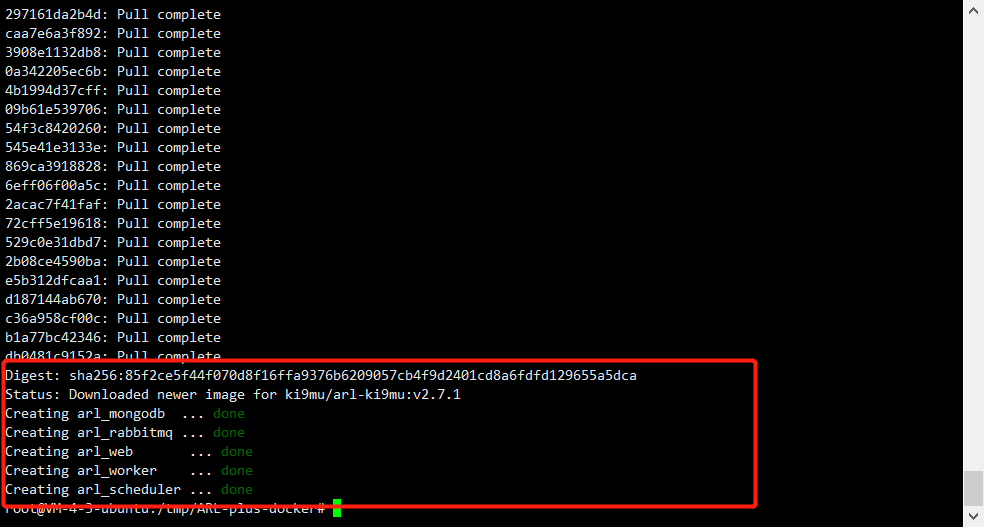
当看到一排done就说明成功了,这时候还需要进容器修改一下python代码,因为在python脚本里也有黑名单。先使用docker ps看一下容器的ID,然后进入这个容器进行修改,使用vi进行编辑。
docker ps #查看容器ID
docker exec -it 对应ID bash
vi app/config.py 修改前:
安装成功之后,添加一下指纹,让你的灯塔有更强大的指纹。
地址:https://vps:5003/
默认账密:admin\arlpass
git clone https://github.com/loecho-sec/ARL-Finger-ADD
cd ARL-Finger-ADD
python ARL-Finger-ADD.py -O https://vps:5003/ admin arlpass
用默认密码登陆,然后在右上角修改掉默认密码就可以愉快的使用了。
我想扫描未知数量的行,直到扫描完所有行。我如何在ruby中做到这一点?例如:putreturnsbetweenparagraphsforlinebreakadd2spacesatend_italic_or**bold**输入不是来自"file",而是通过STDIN。 最佳答案 在ruby中有很多方法可以做到这一点。大多数情况下,您希望一次处理一行,例如,您可以使用whileline=getsend或STDIN.each_linedo|line|end或者通过使用-n开关运行ruby,例如,这意味着上述循环之一(在每次迭代中将
如何扫描上传文件中的病毒、木马等?只是想阻止一些用户上传一些讨厌的东西。我正在使用Heroku和AmazonS3。 最佳答案 Checkoutthis它支持REST/JSON防病毒网络服务。 关于ruby-on-rails-Rails/Heroku-如何对上传的文件进行反病毒扫描?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/9640516/
Ruby(1.9.3)文档似乎暗示scan等同于=~除了scan返回多个匹配项,而=~仅返回第一个匹配项,并且scan返回匹配数据,而=~返回索引。但是,在下面的示例中,这两种方法似乎对相同的字符串和表达式返回不同的结果。这是为什么?1.9.3p0:002>str="PerlandPython-thetwolanguages"=>"PerlandPython-thetwolanguages"1.9.3p0:008>exp=/P(erl|ython)/=>/P(erl|ython)/1.9.3p0:009>str=~exp=>01.9.3p0:010>str.scanexp=>[["er
一、扫描原因 (1)寻找到网站后台管理 (2)寻找未授权界面 (3)寻找网站更多隐藏信息 (4)通过使用目录扫描可以让我们发现这个网站存在多少个目录,多少个页面,探索出网站的整体结构。通过目录扫描我们还能扫描敏感文件,后台文件,数据库文件,和信息泄漏文件等等。二、方法1、robots.txt (1)Robots协议(RobotsExclusionProtocol)“网络爬虫排除标准”,网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。 (2)同时也记录网站所具有基本的目录。
根据theOnigurumadocumentation,\d字符类型匹配:decimaldigitcharUnicode:General_Category--Decimal_Number但是,在包含所有Decimal_Number字符的字符串中扫描\d会导致仅匹配拉丁文0-9数字:#encoding:utf-8require'open-uri'html=open("http://www.fileformat.info/info/unicode/category/Nd/list.htm").readdigits=html.scan(/U\+([\da-f]{4})/i).flatten.
我在lib/tasks/foo.rake中有这个:Rake::Task["assets:precompile"].enhancedoprint">>>>>>>>hellofromprecompile"endRake::Task["assets:precompile:nondigest"].enhancedoprint">>>>>>>>hellofromprecompile:nondigest"end当我在本地运行rakeassets:precompile时,两条消息都会被打印出来。当我推送到heroku时,只打印非摘要消息。然而,accordingtothebuildpack,推送正在
InternetDownloadManager介绍2023最佳下载利器。InternetDownloadManager(简称IDM)是一款Windows平台功能强大的多线程下载工具,国外非常受欢迎。支持断点续传,支持嗅探视频音频,接管所有浏览器,具有站点抓取、批量下载队列、计划任务下载,自动识别文件名、静默下载、网盘下载支持等功能。一款下载器软件,也可以叫它网页嗅探下载工具可以理解为和迅雷差不多,但是没有迅雷那么多广告,而且功能也更加强大(ps:我也是不久前知道迅雷可以下载网页的视频了)。这是一款互联网下载管理器,看着名字挺长的,但它还有一个简称,你一定知道:IDM,在很多论坛技术贴中被称为H
快捷目录前言一、涉及到的相关技术简介二、具体实现过程及踩坑杂谈1.安卓手机改造成linux系统实现方案2.改造后的手机Linux中软件的安装3.手机Linux中安装MySQL5.7踩坑实录4.手机Linux中安装软件的正确方法三、Linux服务器部署前后端分离项目流程1.前提准备(安装必要软件,搭建环境):2.前后端分离项目的详细部署过程:总结前言总体概述:本篇文章隶属于“手机改造服务器部署前后端分离项目”系列专栏,该专栏将分多个板块,每个板块独立成篇来详细记录:手机(安卓)改造成个人服务器(Linux)、Linux中安装软件、配置开发环境、部署JAVA+VUE+MySQL5.7前后端分离项目
我想获取索引以及扫描结果"abab".scan(/a/)我不仅想拥有=>["a","a"]还有那些比赛的索引[1,3]有什么建议吗? 最佳答案 试试这个:res=[]"abab".scan(/a/)do|c|res[["a",0],["a",2]] 关于ruby-在ruby中获取字符串扫描结果的索引,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/3520208/
我是Ruby的新手,一直使用String.scan来搜索数字的第一次出现。返回值在嵌套数组中有点奇怪,但我只是去[0][0]获取我想要的值。(我确定它有它的用途,只是我还没有使用它。)我刚刚发现有一个String.match方法。而且似乎更方便,因为返回的数组不是嵌套的。这是两者的一个例子,第一个是扫描:>>'a1-nightstay'.scan(/(a)?(\d*)[-]night/i).to_a=>[["a","1"]]然后是匹配>>'a1-nightstay'.match(/(a)?(\d*)[-]night/i).to_a=>["a1-night","a","1"]我已经检查了