Grafana 读音:/grəˈfɑːnˌɑː/
Grafana 中文入门教程
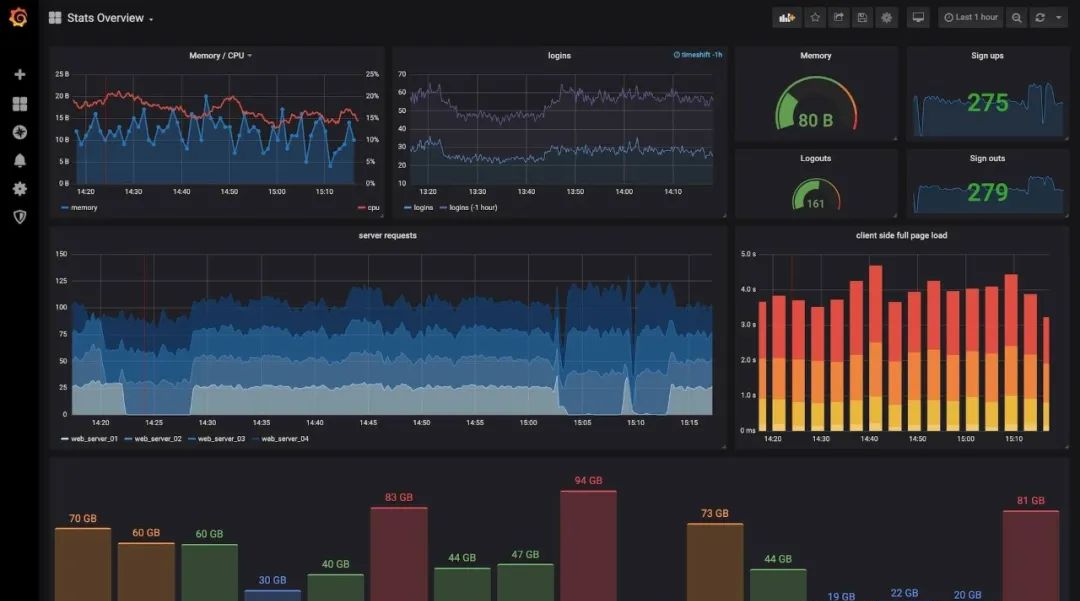
在大厂工作久了,时常对一些工具的存在觉得理所当然。
比如说,需要计算资源的时候,一个配置文件就可以要来两百台虚拟化好的机子。需要试下缓存?点下鼠标就可以要到几十个配置好的 Redis 结点。
最省心的是,这些工具都已经根据工作流配置好了:鉴权、优化、网络连接等等通通不用你操心。
但一切要自己撸起袖子干的时候,开始发现各种踩坑。拿 Grafana 和服务监控来说:
开始前首先要问一个问题,Grafana 到底是什么。
Grafana 读音:/grəˈfɑːnˌɑː/, 是一个监控仪表系统,它是由 Grafana Labs 公司开源的的一个系统监测 (System Monitoring) 工具。它可以大大帮助你简化监控的复杂度,你只需要提供你需要监控的数据,它就可以帮你生成各种可视化仪表。同时它还有报警功能,可以在系统出现问题时通知你。
Grafana 不对数据源作假设,它支持以下各种数据,也就是说如果你的数据源是以下任意一种,它都可以帮助生成仪表。同时在市面上,如果 Grafana 称第二,那么应该没有敢称第一的仪表可视化工具了。因此,如果你搞定了 Grafana,它几乎是一个会陪伴你到各个公司的一件称心应手的兵器。
通常来说,对于一个运行时的复杂系统,你是不太可能在运行时一边检查代码一边调试的。因此,你需要在各种关键点加上监控。
用开车作为例子:车子本身是一个极其复杂的系统,而当你的车在高速上以 120 公里的速度狂奔时出现了噪音,你是不可能这时候边开车边打开发动机盖子来查原因的。通常来说,好一点的车会有内置电脑,在车子出问题时,告诉你左边轮胎胎压有问题,或是发动机缺水了之类。而这些检测,就是系统监控的一个例子。
对于驾驶员来说,他们开车时只关心几个指标:
通过仪表盘,你不一定能清楚地了解车子出问题的具体原因,但至少可以给你一个大概的方向。比如- 说,如果水温很高时出现了问题,你大概率可以尝试加点水降温来尝试是否解决问题。
把上面的车换成计算机系统或者一个软件系统也是一样:仪表盘就是你的速度表和水温表,通过这些表盘你可以实时了解你的系统运行情况。
仪表盘应用极广,我能想到的一些例子:
用一个卡拉搜索的实践作例子:
我们希望卡拉搜索能提供游戏级的搜索性能,比 Elastic Search 还快十倍。那么这就要求我们 99% 的搜索结果在 5-10 毫秒内要完成。因此,我们就需要添加这么一个仪表盘,能实时知道用户搜索的延迟,并且当搜索延迟超过 10 毫秒时通知到我们。
综上,在任何需要监控系统运行状况的地方就大概率会用到仪表盘,而用到仪表盘的时候就可以用 Grafana (不管你用什么语言)
为了简化各种系统不一致的乱七八糟问题,我们用 Docker 来安装 Grafana。(如果还没有安装 Docker 可以参考我们的教程 [如何安装 Docker](/tutorials/how-to-install-and-use-docker-on-ubuntu)。
Docker 的配置文件如下,就算你从来没用过 docker 也不用操心,我会在下文里一行一行讲明白。请不要复制粘贴代码,直接到本文的 GitHub 页 clone 代码即可,我会保证 GitHub 上的代码处理最新状态:https://github.com/Kalasearch/grafana-tutorial[5]
version: '3.4'
services:
prometheus:
image: prom/prometheus
container_name: prometheus
hostname: prometheus
ports:
- 9090:9090
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
prometheus-exporter:
image: prom/node-exporter
container_name: prometheus-exporter
hostname: prometheus-exporter
ports:
- 9100:9100
grafana:
image: grafana/grafana
container_name: grafana
hostname: grafana
ports:
- 3000:3000
volumes:
- ./grafana.ini:/etc/grafana/grafana.ini
在这里我们启动了三个服务
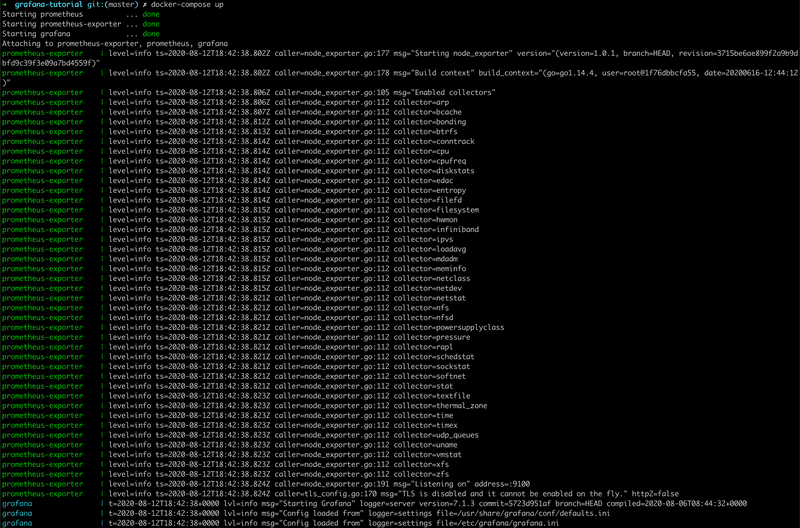
那么就说明服务已经跑起来了。注意,在之后的所有步骤中,你的 docker 应该处于运行状态。
在跑起来服务之后,到你的浏览器中,复制 http://localhost:3000 应该就可以看到 Grafana 跑起来的初始登录界面。初始的用户名是 admin,密码也是 admin。输入之后,会要求你改密码
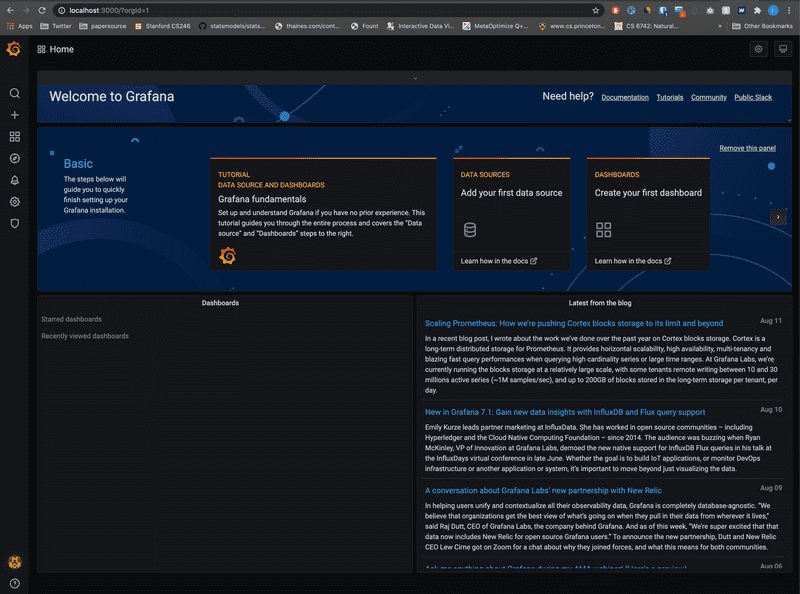
然后就可以进入 Grafana 的主界面了:
到这里,你的 Grafana 就已经搭起来了。注意到 Docker 的配置文件中我们创建了三个服务,这三个服务之间分别有什么关系呢?
或者说,Grafana 和时序数据库,数据源之间有什么关系呢?请看下文 Grafana 工作原理
上面说到,Grafana 是一个仪表盘,而仪表盘必然是用来显示数据的。
Grafana 本身并不负责数据层,它只提供了通用的接口,让底层的数据库可以把数据给它。而我们起的另一个服务,叫 Prometheus (中文名普罗米修斯数据库)则是负责存储和查询数据的。
也就是说,Grafana 每次要展现一个仪表盘的时候,会向 Prometheus 发送一个查询请求。
那么配置里的另一个服务 Prometheus-exporter 又是什么呢?
这个就是你真正监测的数据来源了,Prometheus-exporter 这个服务,会查询你的本地电脑的信息,比如内存还有多少、CPU 负载之类,然后将数据导出至普罗米修斯数据库。
在真实世界中,你的目的是监控你自己的服务,比如你的 Web 服务器,你的数据库之类。
那么你就需要在你自己的服务器中把数据发送给普罗米修斯数据库。当然,你完全可以把数据发送给 MySQL (Grafana 也支持),但普罗米修斯几乎是标配的时序数据库,强烈建议你用。
用一张图[6]来说明它们之间的关系:
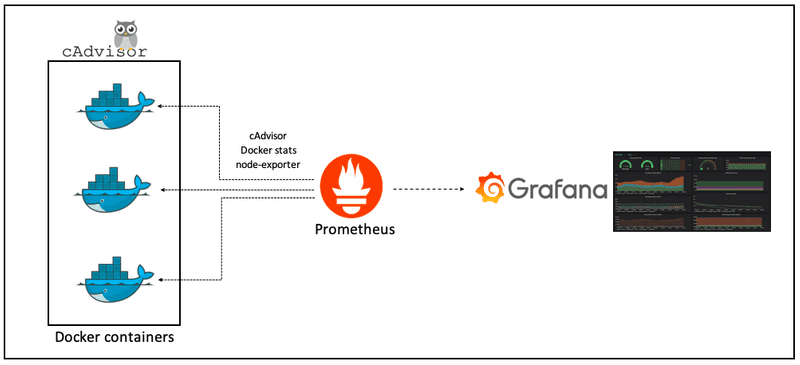
这里,最左边的 Docker 服务会将服务的数据发送给中间的普罗米修斯(对应上文的 Prometheus-exporter),而最右边的 Grafana 会查询中间的普罗米修斯,来展示仪表盘。
关于普罗米修斯本身也可以写一篇很长的教程了,这里我们先暂时略去不表。
现在我们来搭建你的第一个仪表盘。
进入 Grafana 后,在左侧你会发现有一个 Data Source 即数据源选项
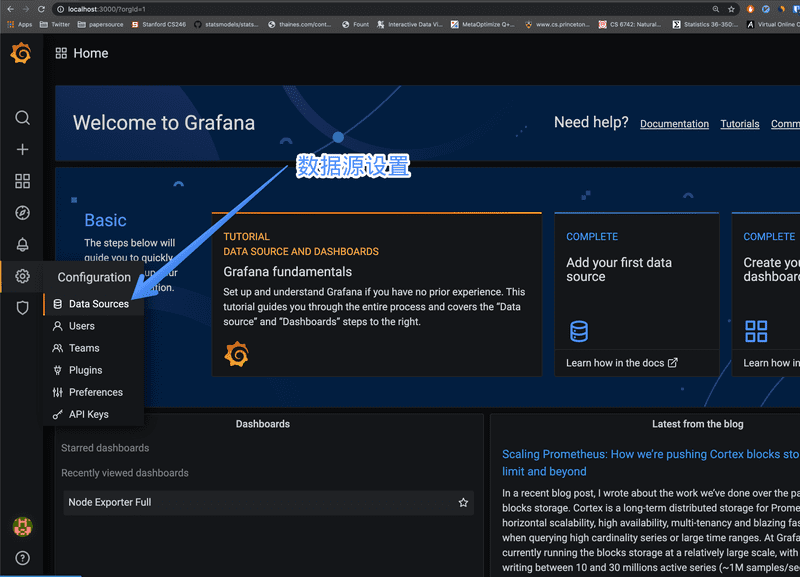
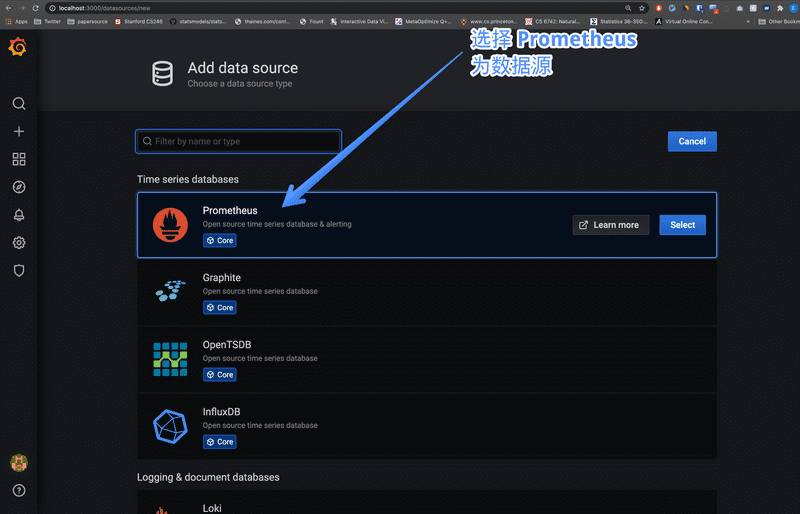
点击后进入,点 Add Data Source 即添加数据源,选择 Prometheus
之后设置数据源 URL。请注意,Promethues 的工作原理(下一个教程中会讲)是通过轮询一个 HTTP 请求来获取数据的,而 Grafana 在获取数据源的时候也是通过一个 HTTP 请求,因此这个地方你需要告诉 Grafana 你的 Prometheus 的数据端点是什么。
这里我们填入 http://prometheus:9090 就可以了。
你可能会问,为什么不是 localhost:9090 呢?原因是,我们用了 docker-compose 起的三个服务,可以把它们想象成三台独立的服务器,因此需要用一个域名来互相通信。我们在 docker-compose.yml 中设置的普罗米修斯服务器的名字就叫 prometheus,因此这里需要用前者。
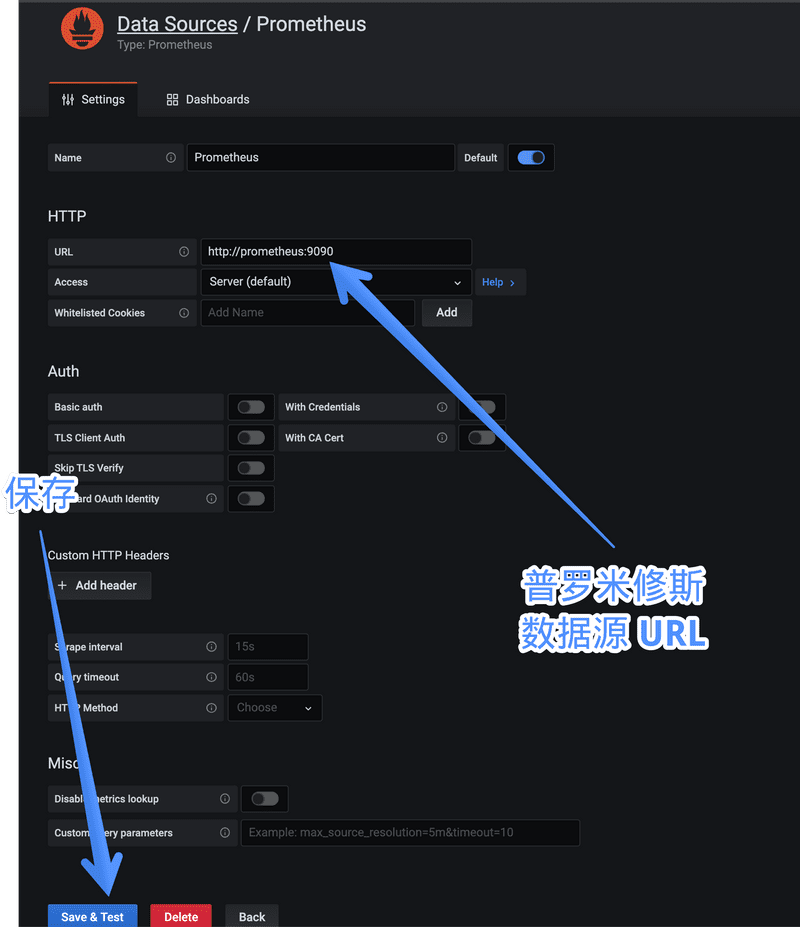
点确认时一定要确认出现 Data source is working 这个检测,这时表明你的 Grafana 已经跟普罗米修斯说上话了
在 Grafana 里,仪表盘的配置可以通过图形化界面进行,但配置好的仪表盘是以 JSON 存储的。这也就是说,如果你把你的 JSON 数据分享出去,别人导入就可以直接导入同样的仪表盘(前提是你们的监测数据一样)。
对于我们的例子来说,回忆一下,因为我们用了 prometheus-exporter 也就是本机的系统信息监控,那么我们可以先找一个同样用了这个数据源的仪表盘。在 Grafana 网站上,你其实可以找到很多别人已经做好的仪表,可以用来监测非常多标准化的服务。
Grafana 的仪表盘市场:https://grafana.com/grafana/dashboards[8]
比如说针对以下一些服务的标准仪表盘就可以在这里找到
那么,这里我们就用一个标准的仪表盘:https://grafana.com/grafana/dashboards/1860[9]
在左侧的加号里,点 Import 即导入,在出现的界面中填入 1860 即我们要导入的仪表盘编号即可。
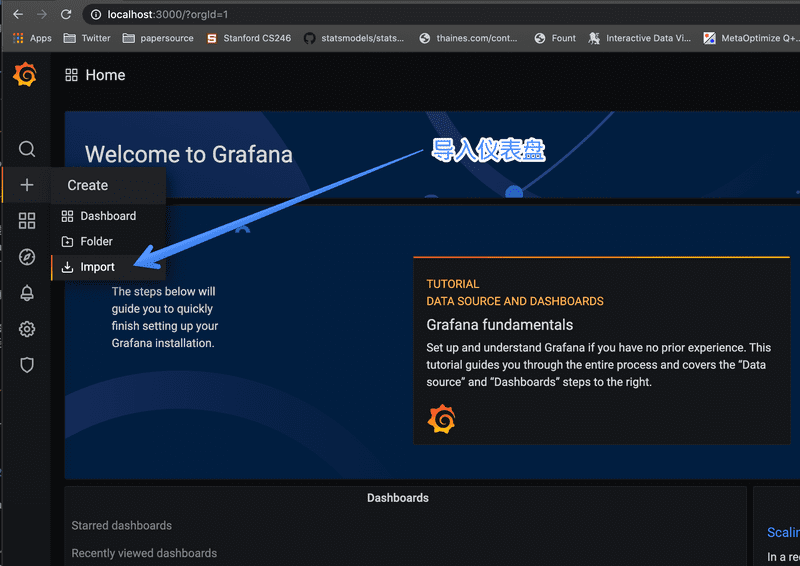
然后填入你需要的信息,比如仪表盘名字等
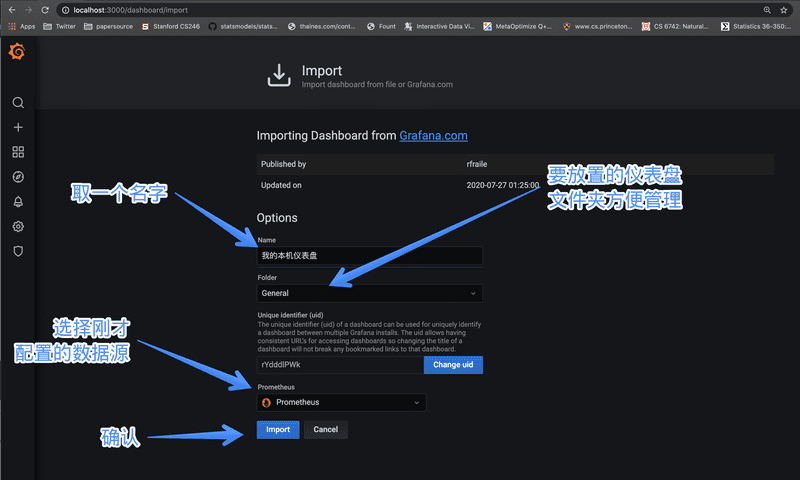
确认之后 Grafana 就会根据你的本机信息,生成类似 CPU 负载,内存和 I/O 之类的信息。我的磁盘状况如图:
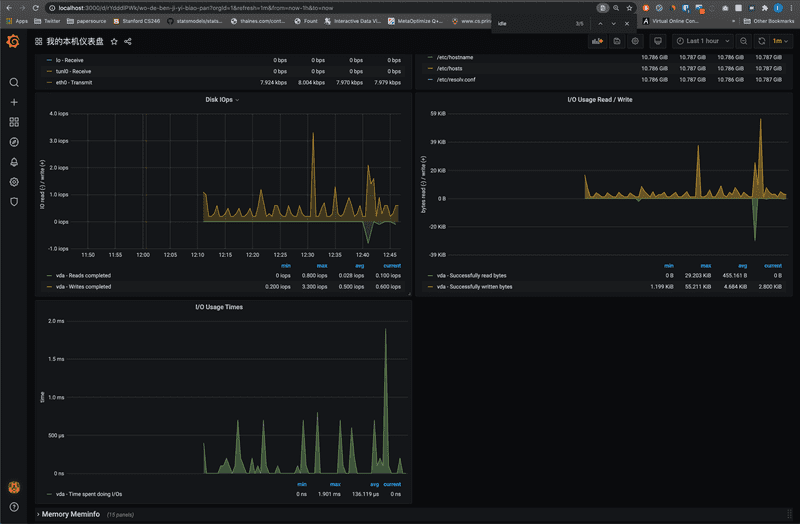
要注意的是,这里的信息真正监控的是你的 Docker 中的系统信息。如果你只给你的 Docker 分配 1 个核和 2G 内存,那么这里应该看到的就是 1 个核和 2G 内存
最后,在上面导入信息的基础上,你就可以开始创建和你的服务、业务相关的仪表盘了。
但在这步之前,你需要先在你的服务中开始记录一些数据。
如何在各种语言中记录你关注的数据?
拿卡拉搜索举例子,我们关注用卡拉搜索的 APP 的搜索响应速度,所以自然我们需要在所有搜索请求处记录延迟。
对于你的服务,你需要根据自己的业务确认哪些数据是重要的,关于如何记录数据,如何思考运维等,我会在之后的博客中继续深入讨论。如果你想更深入地了解这个领域,推荐阅读 Google 运维手册这本书,英文名叫《Google SRE Book》,免费的书。
包括如何用 Prometheus 查询数据
普罗米修斯本身也是个非常大的话题,我们会在之后的博客中继续讨论。普罗米修斯包括所有其它时序数据库通常都会定义一个查询语言,比如说 PromQL,如果需要熟练地构建仪表盘的话,需要对这个查询语言有一定了解。
如何手动生成一个仪表盘
假设你已经按上面的步骤生成了一个基本的仪表盘,那么现在可以开始手动添加仪表盘了。同样是点左侧的加号,点 Dashboard 就可以进入添加仪表盘的界面。
这里我们选择一个数据叫 scrape_duration_seconds,先不用管它的含义是什么,就当它是双 11 的销售额好了:
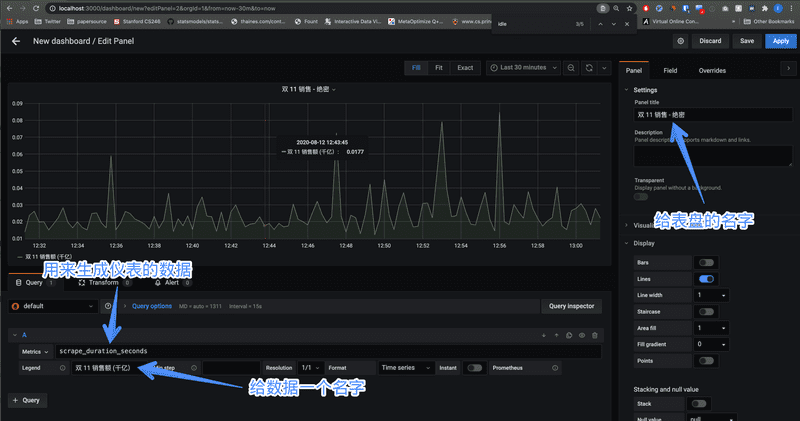
添加好后点右上角的 Apply 或 Save 你的仪表盘就被保存了。这时候,用一个大屏幕展示一下,庆祝一下双十一又过了千亿吧
这篇文章里我们从头到尾介绍了如何用 Grafana 生成仪表盘,如何配置和连接数据源,以及如何导入和创建一个仪表盘。
如果你的 App 或小程序需要搜索功能,也可以到卡拉搜索首页[10]了解一下我们的托管搜索服务。花 5 分钟接入,我们就可以帮你为你的用户提供比 ElasticSearch 还快 10 倍的搜索体验,提高转化率和用户留存。
本文参考了以下文章:
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我想要做的是有2个不同的Controller,client和test_client。客户端Controller已经构建,我想创建一个test_clientController,我可以使用它来玩弄客户端的UI并根据需要进行调整。我主要是想绕过我在客户端中内置的验证及其对加载数据的管理Controller的依赖。所以我希望test_clientController加载示例数据集,然后呈现客户端Controller的索引View,以便我可以调整客户端UI。就是这样。我在test_clients索引方法中试过这个:classTestClientdefindexrender:template=>
如果您尝试在Ruby中的nil对象上调用方法,则会出现NoMethodError异常并显示消息:"undefinedmethod‘...’fornil:NilClass"然而,有一个tryRails中的方法,如果它被发送到一个nil对象,它只返回nil:require'rubygems'require'active_support/all'nil.try(:nonexisting_method)#noNoMethodErrorexceptionanymore那么try如何在内部工作以防止该异常? 最佳答案 像Ruby中的所有其他对象
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion为什么SecureRandom.uuid创建一个唯一的字符串?SecureRandom.uuid#=>"35cb4e30-54e1-49f9-b5ce-4134799eb2c0"SecureRandom.uuid方法创建的字符串从不重复?
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
我想让一个yaml对象引用另一个,如下所示:intro:"Hello,dearuser."registration:$introThanksforregistering!new_message:$introYouhaveanewmessage!上面的语法只是它如何工作的一个例子(这也是它在thiscpanmodule中的工作方式。)我正在使用标准的rubyyaml解析器。这可能吗? 最佳答案 一些yaml对象确实引用了其他对象:irb>require'yaml'#=>trueirb>str="hello"#=>"hello"ir
我的问题的一个例子是体育游戏。一场体育比赛有两支球队,一支主队和一支客队。我的事件记录模型如下:classTeam"Team"has_one:away_team,:class_name=>"Team"end我希望能够通过游戏访问一个团队,例如:Game.find(1).home_team但我收到一个单元化常量错误:Game::team。谁能告诉我我做错了什么?谢谢, 最佳答案 如果Gamehas_one:team那么Rails假设您的teams表有一个game_id列。不过,您想要的是games表有一个team_id列,在这种情况下
英文版英文链接关注公众号在“亚特兰蒂斯的回声”中踏上一段难忘的冒险之旅,深入未知的海洋深处。足智多谋的考古学家AriaSeaborne偶然发现了一件古代神器,揭示了一张通往失落之城亚特兰蒂斯的隐藏地图。在她神秘的导师内森·兰登教授的指导和勇敢的冒险家亚历克斯·默瑟的帮助下,阿丽亚开始了一段危险的旅程,以揭开这座传说中城市的真相。他们的冒险之旅带领他们穿越险恶的大海、神秘的岛屿和充满陷阱和谜语的致命迷宫。随着Aria潜在的魔法能力的觉醒,她被睿智勇敢的QueenNeria的幻象所指引,她让她为即将到来的挑战做好准备。三人组揭开亚特兰蒂斯令人惊叹的隐藏文明,并了解到邪恶的巫师马拉卡勋爵试图利用其古