如果你有一定神经网络的知识基础,想学习GNN图神经网络,可以按顺序参考系列文章:
深度学习 GNN图神经网络(一)图的基本知识
深度学习 GNN图神经网络(二)PyTorch Geometric(PyG)安装
深度学习 GNN图神经网络(三)模型原理及文献分类案例实战
本文介绍GNN图神经网络的思想原理,然后使用Cora数据集对其中的2708篇文献进行分类。用普通的神经网络与GNN图神经网络分别实现,并对比两者之间的效果。
GNN的作用就是对节点进行特征提取,可以看下这个几分钟的视频《简单粗暴带你快速理解GNN》。
比如说这里有一张图,包含5个节点,每个节点有三个特征值:
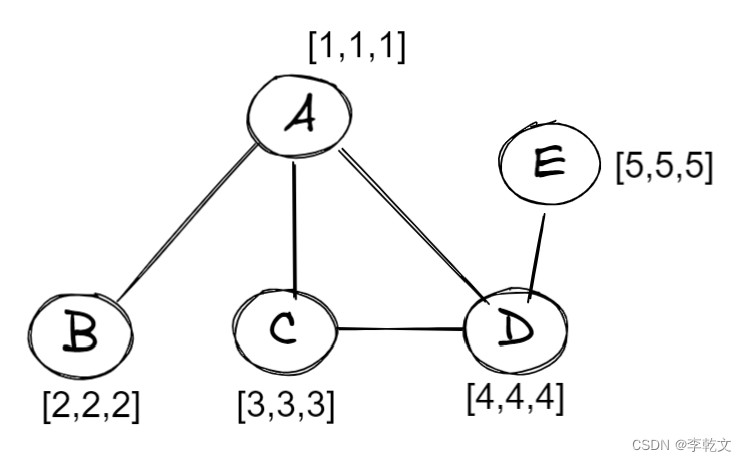
节点A的特征值
x
a
=
[
1
,
1
,
1
]
x_a=[1,1,1]
xa=[1,1,1],节点B的特征值
x
b
=
[
2
,
2
,
2
]
x_b=[2,2,2]
xb=[2,2,2] …
我们依次对所有节点的特征值进行更新:
新的信息=自身的信息 + 所有邻居点的信息
所有邻居点信息的表达有几种:
我们以求和为例:
x
^
a
=
σ
(
w
a
x
a
+
w
b
x
b
+
w
c
x
c
)
\hat{x}_a=\sigma(w_ax_a+w_bx_b+w_cx_c)
x^a=σ(waxa+wbxb+wcxc)
x
^
b
=
σ
(
w
b
x
b
+
w
a
x
a
)
\hat{x}_b=\sigma(w_bx_b+w_ax_a)
x^b=σ(wbxb+waxa)
x
^
c
=
σ
(
w
c
x
c
+
w
a
x
a
+
w
d
x
d
)
\hat{x}_c=\sigma(w_cx_c+w_ax_a+w_dx_d)
x^c=σ(wcxc+waxa+wdxd)
x
^
d
=
σ
(
w
d
x
d
+
w
a
x
a
+
w
c
x
c
)
\hat{x}_d=\sigma(w_dx_d+w_ax_a+w_cx_c)
x^d=σ(wdxd+waxa+wcxc)
x
^
e
=
σ
(
w
e
x
e
+
w
d
x
d
)
\hat{x}_e=\sigma(w_ex_e+w_dx_d)
x^e=σ(wexe+wdxd)
其中,
w
w
w是各自节点的权重参数,
σ
\sigma
σ是激活函数。
求所有邻居点信息并更新特征值的操作叫做消息传递、信息聚合或图卷积(跟CNN卷积神经网络中的卷积是两回事)。
我们再以简单的求平均为例(忽略权重),得到特征平均值后,将其传入神经网络,输出两个值,这时节点的特征值个数就变成了两个。这整个结构叫做图卷积网络(GCN)。
当然设计几层GCN或者输出值个数,我们都是可以自定义的。
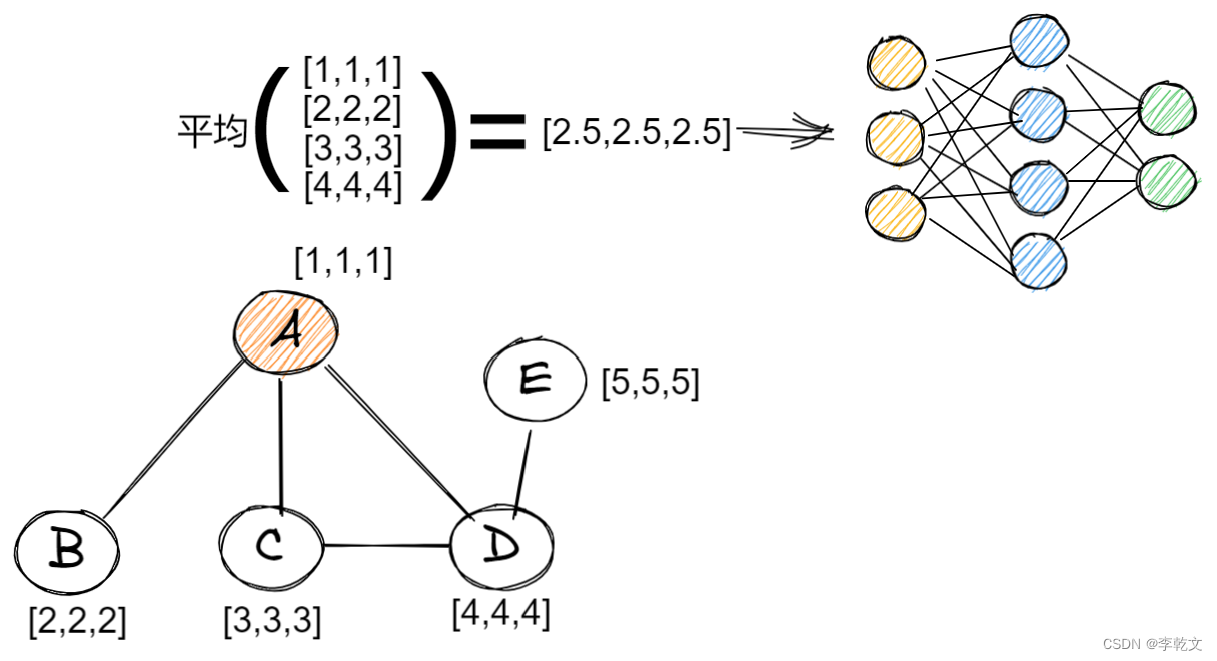
在经历第一次更新操作后:
A中有B、C、D的信息;
B中有A的信息;
C中有A、D的信息;
D中有A、C、E的信息;
E中有D的信息;
在经历第二次更新操作后:
A中有B、C、D、E的信息;
⋮
\vdots
⋮
E中有A、C、D、E的信息;
如此循环,节点逐渐包含更多其他节点的信息,只是权重不同。
PS:过年了,这段写得有点仓促,如有错误恳请纠正。作者也会在这留下TODO,后续参考更多的资料进行校正。祝兔年快乐~ 😃
Cora数据集由2708篇机器学习论文组成。 这些论文分为七类:
每个论文样本包含1433个特征值,由0/1组成,表示论文内容是否包含某关键字。
数据集中的边表示论文引用关系。
我们首先引入Cora数据集,看看图数据集的格式:
from torch_geometric.datasets import Planetoid
from torch_geometric.transforms import NormalizeFeatures
# 手动下载https://gitee.com/jiajiewu/planetoid
# 或者https://linqs-data.soe.ucsc.edu/public/lbc/cora.tgz
dataset=Planetoid(root="./data/Planetoid",name='Cora',transform=NormalizeFeatures())
print(f'num_features={dataset.num_features}')
print(f'num_classes={dataset.num_classes}')
print(dataset.data)
print(dataset.data.edge_index.T)
输出结果:
num_features=1433
num_classes=7
Data(x=[2708, 1433], edge_index=[2, 10556], y=[2708], train_mask=[2708], val_mask=[2708], test_mask=[2708])
tensor([[ 0, 633],
[ 0, 1862],
[ 0, 2582],
...,
[2707, 598],
[2707, 1473],
[2707, 2706]])
num_features=1433:有1433个特征值
num_classes=7:有7种类型
x=[2708,1433]:数据包含2708篇论文,每篇论文有1433个特征值
edge_index=[2, 10556]:每条边连接两篇论文,存在10556条边,即论文间有10556次引用关系
y=[2708]:有2708个标签(0-6)
首先,我们使用多层感知器,即普通的神经网络进行分类测试。
定义网络模型:
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
class MLP(nn.Module):
def __init__(self):
# 初始化Pytorch父类
super().__init__()
# 定义神经网络层
self.model = nn.Sequential(
nn.Linear(dataset.num_features, 16),
nn.ReLU(),
nn.Linear(16, dataset.num_classes),
)
# 创建损失函数,使用交叉熵误差
self.loss_function = nn.CrossEntropyLoss()
# 创建优化器,使用Adam梯度下降
self.optimiser = torch.optim.Adam(self.parameters(), lr=0.01,weight_decay=5e-4)
# 训练次数计数器
self.counter = 0
# 训练过程中损失值记录
self.progress = []
# 前向传播函数
def forward(self, inputs):
return self.model(inputs)
# 训练函数
def train(self, inputs, targets):
# 前向传播计算,获得网络输出
outputs = self.forward(inputs)
# 计算损失值
loss = self.loss_function(outputs[dataset.data.train_mask], targets)
# 累加训练次数
self.counter += 1
# 每10次训练记录损失值
if (self.counter % 10 == 0):
self.progress.append(loss.item())
# 每10000次输出训练次数
if (self.counter % 100 == 0):
print(f"counter={self.counter}, loss={loss.item()}")
# 梯度清零, 反向传播, 更新权重
self.optimiser.zero_grad()
loss.backward()
self.optimiser.step()
# 测试函数
def test(self, inputs, targets):
# 前向传播计算,获得网络输出
outputs = self.forward(inputs)
pred=outputs.argmax(dim=1)
test_correct=pred[dataset.data.test_mask]==targets
return (test_correct.sum()/dataset.data.test_mask.sum()).item()
# 绘制损失变化图
def plot_progress(self):
plt.plot(range(100),self.progress)
迭代训练:
M = MLP()
for i in range(1000):
M.train(dataset.data.x,dataset.data.y[dataset.data.train_mask])
运行结果:
counter=100, loss=0.0084211565554142
counter=200, loss=0.0063483878038823605
counter=300, loss=0.0051103029400110245
counter=400, loss=0.004452046472579241
counter=500, loss=0.0040738522075116634
counter=600, loss=0.0038454567547887564
counter=700, loss=0.003702200250700116
counter=800, loss=0.0036090961657464504
counter=900, loss=0.0035553970374166965
counter=1000, loss=0.0035170542541891336
输出损失值变化图:
M.plot_progress()
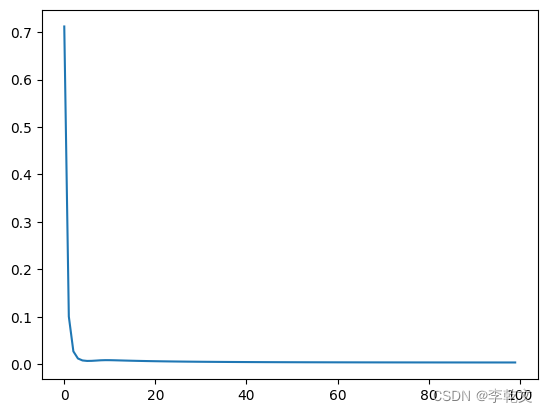
测试结果:
M.test(dataset.data.x,dataset.data.y[dataset.data.test_mask])
运行结果:
0.5730000138282776
可以看到,准确率大概为57.3%,效果比较差。
现在我们构建GNN图神经网络进行分类测试。
import torch
import torch.nn as nn
from torch_geometric.nn import GCNConv
import matplotlib.pyplot as plt
class GNN(nn.Module):
def __init__(self):
# 初始化Pytorch父类
super().__init__()
# 定义神经网络层,torch_geometric有自己的Sequential实现
# 报错信息https://github.com/pyg-team/pytorch_geometric/discussions/3726
# 见https://pytorch-geometric.readthedocs.io/en/latest/modules/nn.html#torch_geometric.nn.sequential.Sequential
# self.model = nn.Sequential(
# GCNConv(dataset.num_features, 16),
# nn.ReLU(),
# GCNConv(16, dataset.num_classes),
# )
self.conv1=GCNConv(dataset.num_features, 16)
self.conv2=GCNConv(16, dataset.num_classes)
# 创建损失函数,使用交叉熵误差
self.loss_function = nn.CrossEntropyLoss()
# 创建优化器,使用Adam梯度下降
self.optimiser = torch.optim.Adam(self.parameters(), lr=0.01,weight_decay=5e-4)
# 训练次数计数器
self.counter = 0
# 训练过程中损失值记录
self.progress = []
# 前向传播函数
def forward(self, x, edge_index):
# return self.model(x, edge_index)
x=self.conv1(x,edge_index)
x=x.relu()
x=self.conv2(x, edge_index)
return x
# 训练函数
def train(self, x, edge_index, targets):
# 前向传播计算,获得网络输出
outputs = self.forward(x, edge_index)
# 计算损失值
loss = self.loss_function(outputs[dataset.data.train_mask], targets)
# 累加训练次数
self.counter += 1
# 每10次训练记录损失值
if (self.counter % 10 == 0):
self.progress.append(loss.item())
# 每10000次输出训练次数
if (self.counter % 100 == 0):
print(f"counter={self.counter}, loss={loss.item()}")
# 梯度清零, 反向传播, 更新权重
self.optimiser.zero_grad()
loss.backward()
self.optimiser.step()
# 测试函数
def test(self, x, edge_index, targets):
# 前向传播计算,获得网络输出
outputs = self.forward(x, edge_index)
pred=outputs.argmax(dim=1)
test_correct=pred[dataset.data.test_mask]==targets
return (test_correct.sum()/dataset.data.test_mask.sum()).item()
# 绘制损失变化图
def plot_progress(self):
plt.plot(range(100),self.progress)
迭代训练:
G = GNN()
for i in range(1000):
G.train(dataset.data.x,dataset.data.edge_index,dataset.data.y[dataset.data.train_mask])
运行结果:
counter=100, loss=0.01617591269314289
counter=200, loss=0.010460852645337582
counter=300, loss=0.008510907180607319
counter=400, loss=0.007648027036339045
counter=500, loss=0.007218983490020037
counter=600, loss=0.006993760820478201
counter=700, loss=0.0068700965493917465
counter=800, loss=0.006797503679990768
counter=900, loss=0.006750799715518951
counter=1000, loss=0.006724677048623562
输出损失值变化图:
G.plot_progress()
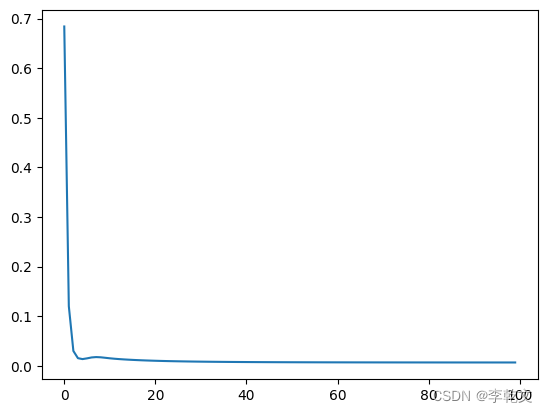
测试结果:
G.test(dataset.data.x,dataset.data.edge_index,dataset.data.y[dataset.data.test_mask])
运行结果:
0.8059999942779541
可以看到,准确率大概为80.6%,效果好了很多。
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我有一些非常大的模型,我必须将它们迁移到最新版本的Rails。这些模型有相当多的验证(User有大约50个验证)。是否可以将所有这些验证移动到另一个文件中?说app/models/validations/user_validations.rb。如果可以,有人可以提供示例吗? 最佳答案 您可以为此使用关注点:#app/models/validations/user_validations.rbrequire'active_support/concern'moduleUserValidationsextendActiveSupport:
对于Rails模型,是否可以/建议让一个类的成员不持久保存到数据库中?我想将用户最后选择的类型存储在session变量中。由于我无法从我的模型中设置session变量,我想将值存储在一个“虚拟”类成员中,该成员只是将值传递回Controller。你能有这样的类(class)成员吗? 最佳答案 将非持久属性添加到Rails模型就像任何其他Ruby类一样:classUser扩展解释:在Ruby中,所有实例变量都是私有(private)的,不需要在赋值前定义。attr_accessor创建一个setter和getter方法:classUs
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序
我正在使用Rails3.1并在一个论坛上工作。我有一个名为Topic的模型,每个模型都有许多Post。当用户创建新主题时,他们也应该创建第一个Post。但是,我不确定如何以相同的形式执行此操作。这是我的代码:classTopic:destroyaccepts_nested_attributes_for:postsvalidates_presence_of:titleendclassPost...但这似乎不起作用。有什么想法吗?谢谢! 最佳答案 @Pablo的回答似乎有你需要的一切。但更具体地说...首先改变你View中的这一行对此#