mysql由于锁机制等等对于大量数据里查找某几条的操作是非常耗时的,索引虽然能大大加快查询的速度,但是需要新增一些内存用于存放索引,
ELK是一款主流的日志平台架构,分布式,毫秒级响应的特性适用于大量数据的筛查,支持api接口访问,但是其缺点在于会使用源文件约2.5倍的空间(以空间换时间了)
1.什么是ELK
2.简单的ELK架构
3.部署安装
ELK 不是一款软件,而是 Elasticsearch、Logstash 和 Kibana 三种软件产品的首字母缩写。这三者都是开源软件,通常配合使用,而且又先后归于 Elastic.co 公司名下,所以被简称为 ELK Stack。根据 Google Trend 的信息显示,ELK Stack 已经成为目前最流行的集中式日志解决方案。
Elasticsearch:分布式搜索和分析引擎,具有高可伸缩、高可靠和易管理等特点。基于 Apache Lucene 构建,能对大容量的数据进行接近实时的存储、搜索和分析操作。通常被用作某些应用的基础搜索引擎,使其具有复杂的搜索功能;
Logstash:数据收集引擎。它支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储到用户指定的位置;
Kibana:数据分析和可视化平台。通常与 Elasticsearch 配合使用,对其中数据进行搜索、分析和以统计图表的方式展示;
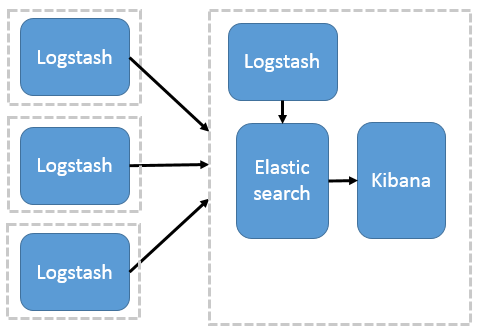
ELK最简单的架构只需要一台机器即可架设
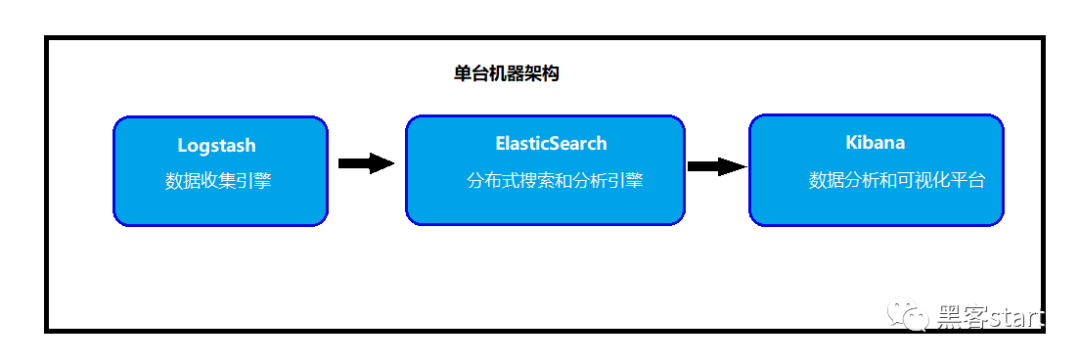
多台服务器分布式的日志搜集: 多台设备通过logstash搜集日志信息,发送到ElasticSearch服务器进行存储,再使用Kibana平台进行可视化分析
java7环境以上
elasticsearch-6.5.4
下载地址:https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.5.4.zip
kibana-6.5.4
下载地址:https://artifacts.elastic.co/downloads/kibana/kibana-6.5.4-windows-x86_64.zip
logstash-8.0.1
下载地址:https://artifacts.elastic.co/downloads/logstash/logstash-8.0.1-windows-x86_64.zip
解压三个压缩包
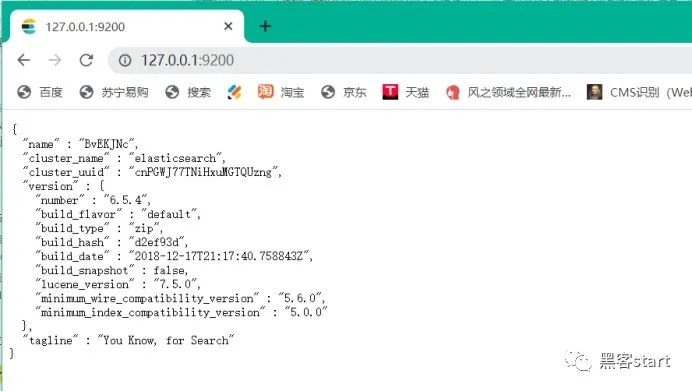
进入/elasticsearch-6.5.4/bin/ ,运行elasticsearch.bat,浏览器访问127.0.0.1:9200如下即成功:
接下来进入kibana-6.5.4-windows-x86_64\bin\ ,运行kibana.bat
浏览器访问http://127.0.0.1:5601端口看到以下界面说明kibana运行成功:
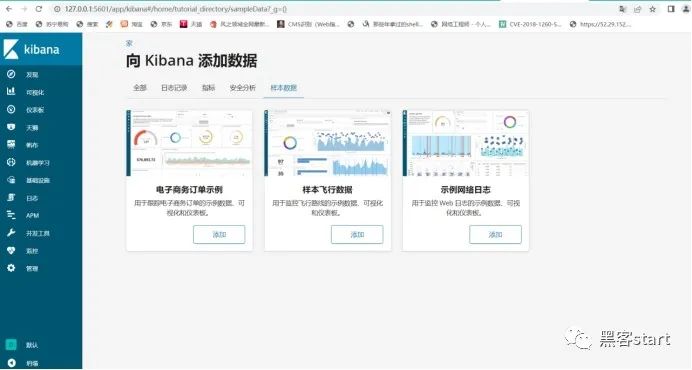
使用py生成一批测试账号密码
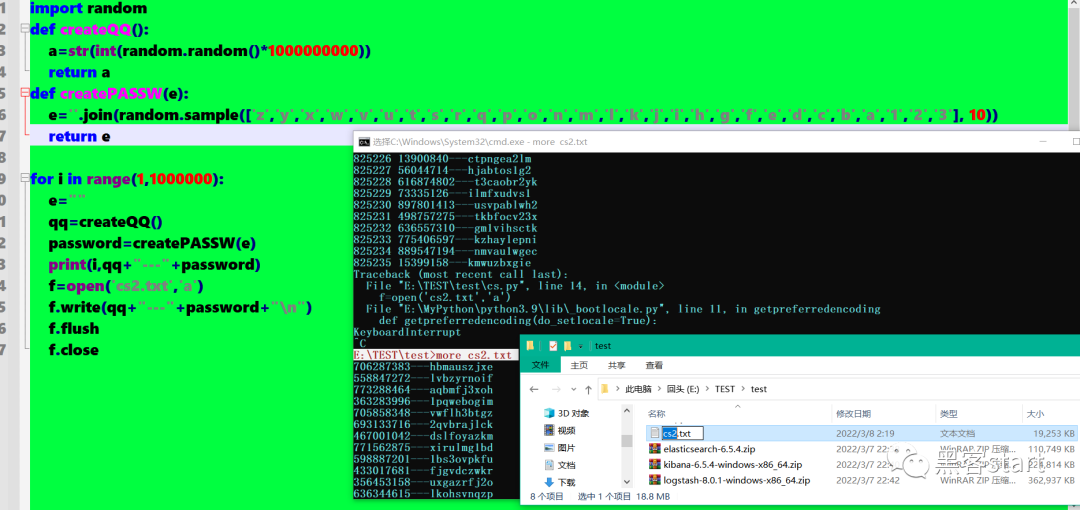
进入\logstash-8.0.1\bin目录,新建编写配置文件test.conf
input { #输入
file{
path=>"E:/TEST/test/cs2.txt" #输入源文件,注意此处不能使用反斜杠
start_position=>beginning #定义开头
}
}
filter { #过滤
csv{
columns=>["qq","password"] #存储的字段名字
separator=>"---" #分割符
}
mutate{ #移除默认的一些输出信息
remove_field=>["message","path","host","@timestamp","@version","original","event","log"]
}
}
output { #输出
elasticsearch{ #对elasticsearch进行配置
hosts=>["127.0.0.1:9200"] #host地址
index=>"wb" #库名
document_type=>"qq" #类型名
}
stdout{
codec=>rubydebug
}
}进入\logstash-8.0.1\bin,执行命令:logstash.bat -f test.conf如图下即开始写入数据
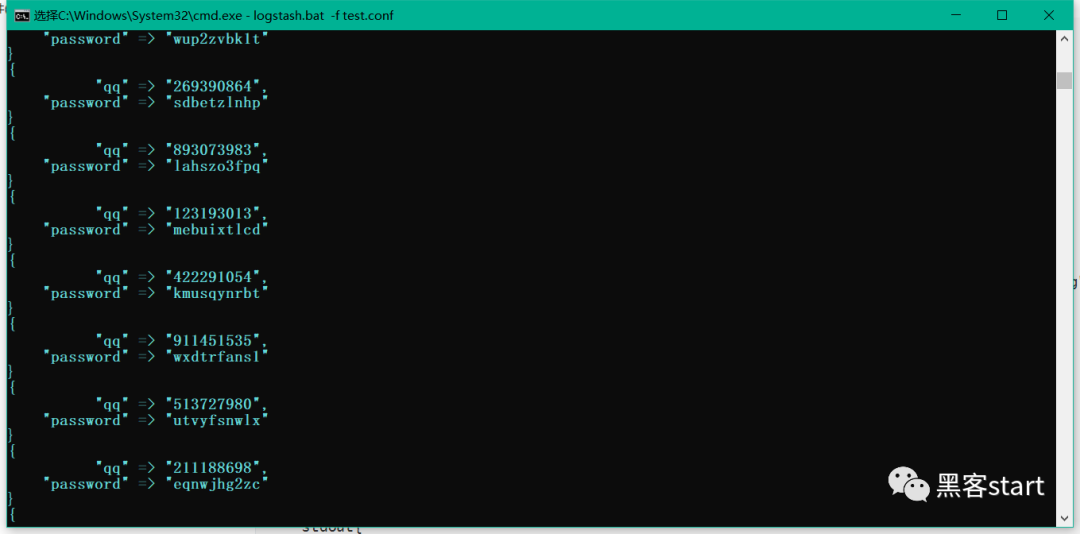
浏览器打开http://127.0.0.1:9200/_cat/indices?v可以看到任务存在了
打开http://127.0.0.1:5601/在managerment->qq->可以看到导入了82万条数据
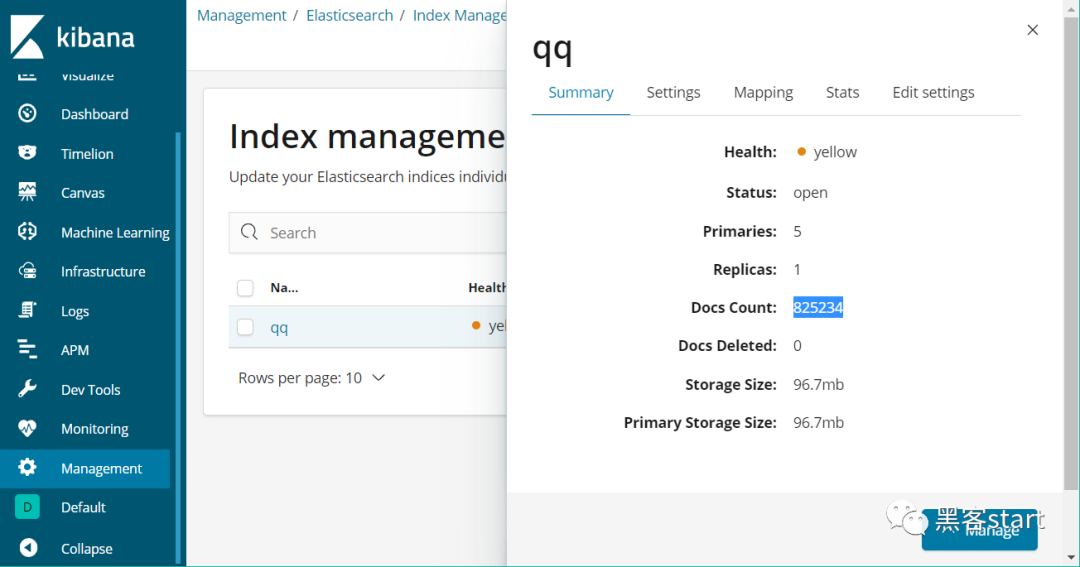
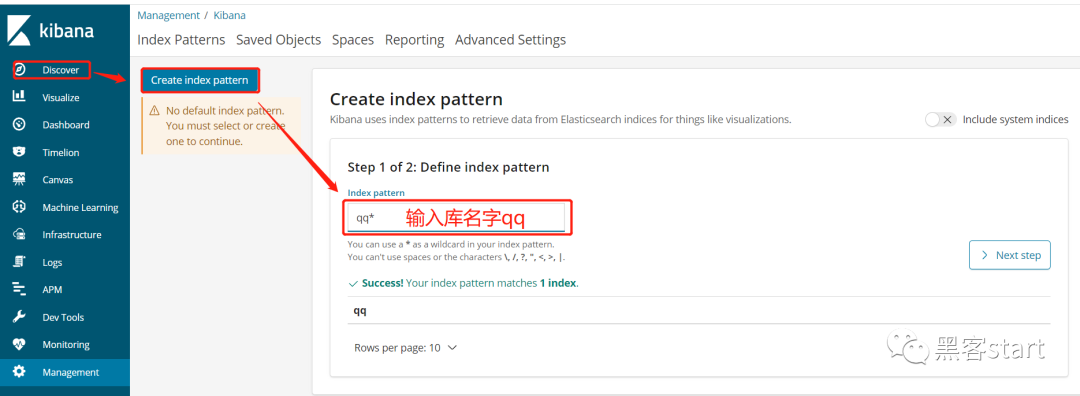
打开http://127.0.0.1:5601/创建一个模式(Managerment->index pattern->create也可以创建),一路下一步确定
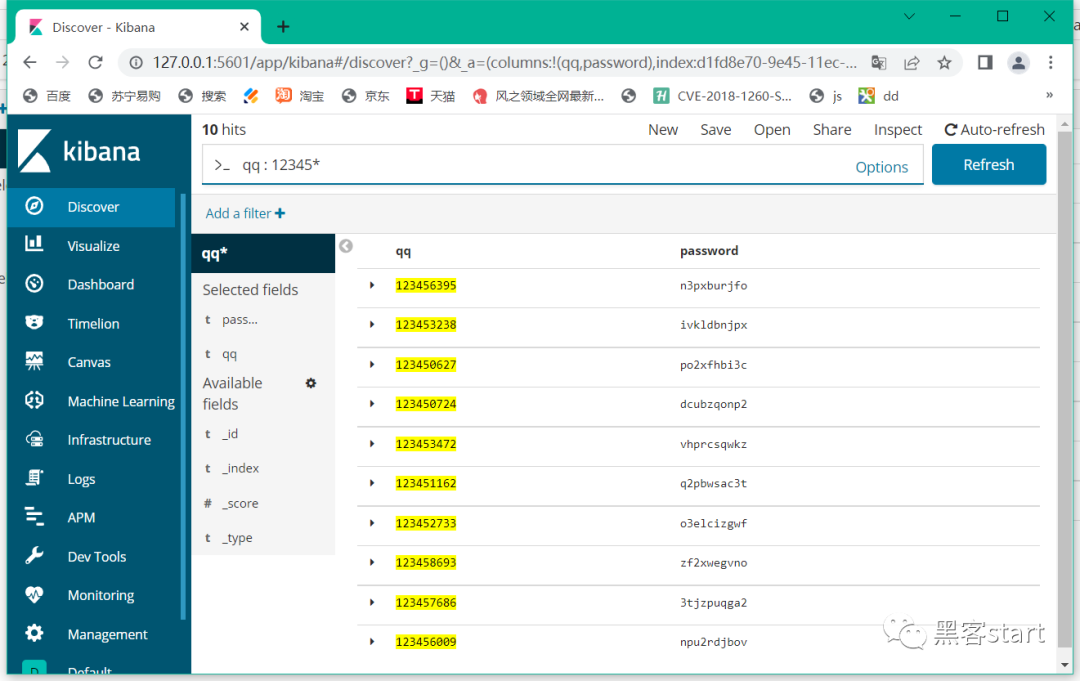
再次点击discover查找输入如qq:12345*(星号为通配符),响应速度非常快,秒出结果,几亿条大概响应时间为5-10s
结语:
心之所向,必是远方
我是Google云的新手,我正在尝试对其进行首次部署。我的第一个部署是RubyonRails项目。我基本上是在关注thisguideinthegoogleclouddocumentation.唯一的区别是我使用的是我自己的项目,而不是他们提供的“helloworld”项目。这是我的app.yaml文件runtime:customvm:trueentrypoint:bundleexecrackup-p8080-Eproductionconfig.ruresources:cpu:0.5memory_gb:1.3disk_size_gb:10当我转到我的项目目录并运行gcloudprevie
在我做的一些网络开发中,我有多个操作开始,比如对外部API的GET请求,我希望它们同时开始,因为一个不依赖另一个的结果。我希望事情能够在后台运行。我找到了concurrent-rubylibrary这似乎运作良好。通过将其混合到您创建的类中,该类的方法具有在后台线程上运行的异步版本。这导致我编写如下代码,其中FirstAsyncWorker和SecondAsyncWorker是我编写的类,我在其中混合了Concurrent::Async模块,并编写了一个名为“work”的方法来发送HTTP请求:defindexop1_result=FirstAsyncWorker.new.async.
在Ruby中,以毫秒为单位获取自纪元(1970)以来的当前系统时间的正确方法是什么?我试过了Time.now.to_i,好像不是我想要的结果。我需要结果显示毫秒并且使用long类型,而不是float或double。 最佳答案 (Time.now.to_f*1000).to_iTime.now.to_f显示包含十进制数字的时间。要获得毫秒数,只需将时间乘以1000。 关于ruby-以毫秒为单位获取当前系统时间,我们在StackOverflow上找到一个类似的问题:
@scores_raw.eachdo|score_raw|#belowiscodeiftimewasbeingsentinmillisecondshh=((score_raw.score.to_i)/100)/3600mm=(hh-hh.to_i)*60ss=(mm-mm.to_i)*60crumbs=[hh,mm,ss]sum=crumbs.first.to_i*3600+crumbs[1].to_i*60+crumbs.last.to_i@scoressum,:hms=>hh.round.to_s+":"+mm.round.to_s+":"+ss.round.to_s}@score
我试图在我的RubyonRails应用程序中调试一个极其缓慢的请求调用。我已设法根据自己的喜好优化Controller方法,Rails的日志告诉我它已在XX毫秒内完成操作(Completed200OKin5049ms(Views:34.9ms|ActiveRecord:76.3ms)).但是,在加载页面时,在浏览器中实际呈现任何内容之前打印此消息很长;最多约15秒的等待时间。Rackmini-profiler证实了这一点,告诉我GET操作(不计算完成Controller操作所花费的时间)花费了14秒左右。(分析器还确认Controller操作的执行时间约为5秒)。我可以接受Contro
我想通过Sinatra应用程序代理远程文件。这需要将带有header的HTTP响应从远程源流式传输回客户端,但我不知道如何在Net::HTTP#提供的block内使用流式API时设置响应header获取响应。例如,这不会设置响应头:get'/file'dostreamdo|out|uri=URI("http://manuals.info.apple.com/en/ipad_user_guide.pdf")Net::HTTP.get_response(uri)do|file|headers'Content-Type'=>file.header['Content-Type']file.re
出于某种原因,在我的开发机器上,我对通过Net::HTTP执行的HTTPS请求的响应非常非常慢。我试过RestClient和HTTParty,它们都有同样的问题。它似乎是凭空冒出来的。我已毫无问题地提出这些请求数百次,但今天它们的速度慢得令人难以忍受。pry(main)>putsTime.now;HTTParty.get('https://api.easypost.com/v2/addresses');putsTime.now;2015-04-2908:07:08-05002015-04-2908:09:39-0500如您所见,响应耗时2.5分钟。不仅仅是这个EasyPostAPIUR
我正在尝试下载一个大文件,然后使用Ruby将该文件发布到REST端点。该文件可能非常大,即超过可以存储在内存中甚至磁盘上的临时文件中的容量。我一直在用Net::HTTP尝试这个,但我愿意接受任何其他库(rest-client等)的解决方案,只要他们做我想做的事情。这是我尝试过的:require'net/http'source_uri=URI("https://example.org/very_large_file")source_request=Net::HTTP::Get.new(source_uri)source_http=Net::HTTP.start(source_uri.ho
我们最近更新了我们网站的SSL证书,在MacOSElCapitan10.11.3上出现以下情况:require'net/http'Net::HTTP.getURI('https://www.google.com')#=>"..."#ThesitewhosecertificategotrenewedNet::HTTP.getURI('https://www.example.com')#=>OpenSSL::SSL::SSLError:SSL_connectreturned=1errno=0state=error:certificateverifyfailed我在Google和StackO
TL;DR:IneedtogetthedifferencebetweenHH:MM:SS.msandHH:MM:SS.msasHH:MM:SS:ms我需要什么:这是一个棘手的问题。我正在尝试计算两个时间戳之间的差异,如下所示:In:00:00:10.520Out:00:00:23.720应该交付:Diff:00:00:13.200我想我应该将时间解析为实际的Time对象并在那里使用差异。这在前一种情况下效果很好,并返回00:0:13.200。什么不起作用:然而,对于某些人来说,这并不能正常工作,因为Ruby使用usec而不是msec:In:00:2:22.760Out:00:2:31.