摘要:华为云EI DTSE技术布道师王跃,针对统计信息对于查询优化器的重要性,GaussDB(DWS)最新版本的analyze当前能力,与开发者和伙伴朋友们展开交流互动,帮助开发者快速上手使用统计信息的自动收集功能。
在本期《统计信息大揭秘——SQL执行优化之密钥》的主题直播中,我们邀请到华为云EI DTSE技术布道师王跃,针对统计信息对于查询优化器的重要性,GaussDB(DWS)最新版本的analyze当前能力,与开发者和伙伴朋友们展开交流互动,帮助开发者快速上手使用统计信息的自动收集功能。
现阶段市场上的数据库产品,基本上都是基于CBO模型的优化器,在基于CBO模型的优化器中,统计信息是生成最优执行计划的前提,会直接影响到执行计划的选择,因此统计信息的及时收集是尤为重要的。

统计信息主要包括“描述表规模的表级统计信息”和“描述列数据特征的列级统计信息”两部分内容。
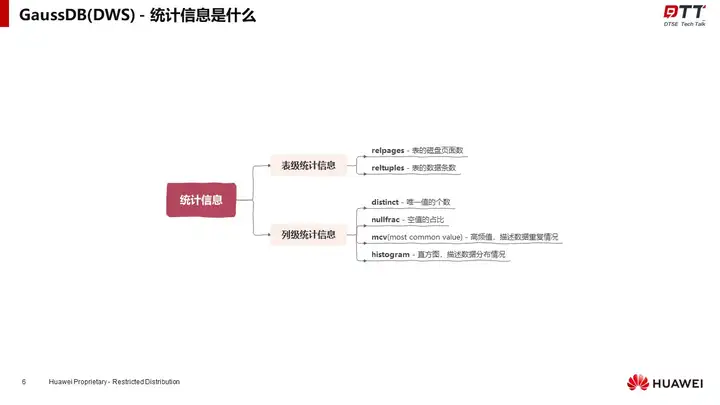
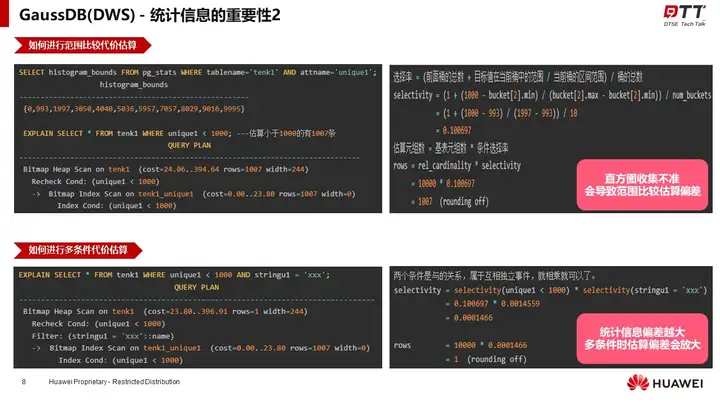
王跃从统计数据在优化器中的运用这一角度,向我们展示了统计信息影响表达小估算的原理、进行等值比较、范围比较、多条件、简单JOIN代价估算的原理,进一步解释了统计信息的重要性。


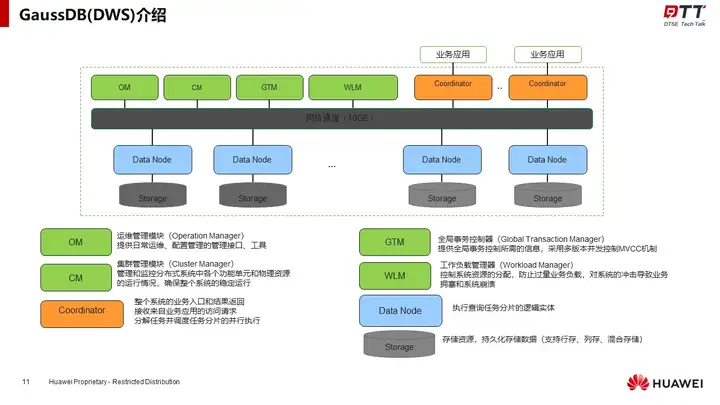
王跃先带我们简单了解了GaussDB(DWS)的部署架构,说明了分布式查询的执行流程和统计信息收集的执行流程。
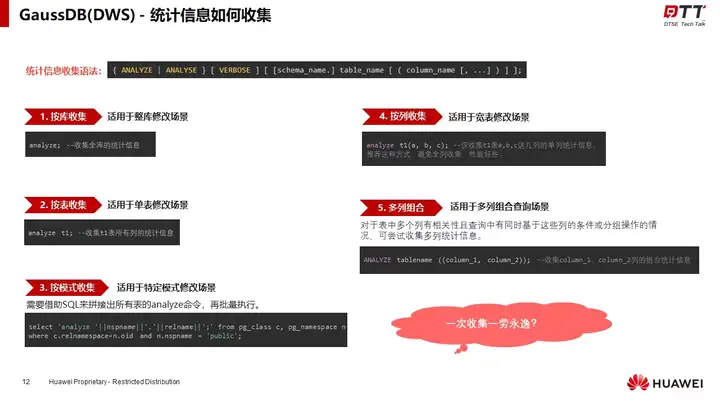
基于此,GaussDB(DWS)共有五种统计信息收集的方法,分别是按库收集、按表收集、按模式收集、按列收集以及多列组合。
GaussDB(DWS)拥有强大的统计信息自动收集能力,通过后台线程轮询收集与优化器同步收集两种方式来实现。王跃建议开发者可以同步开启两种方式,以达到最优的收集功能。
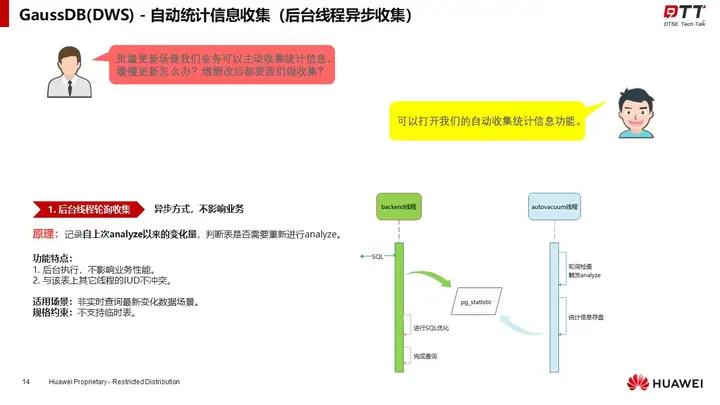
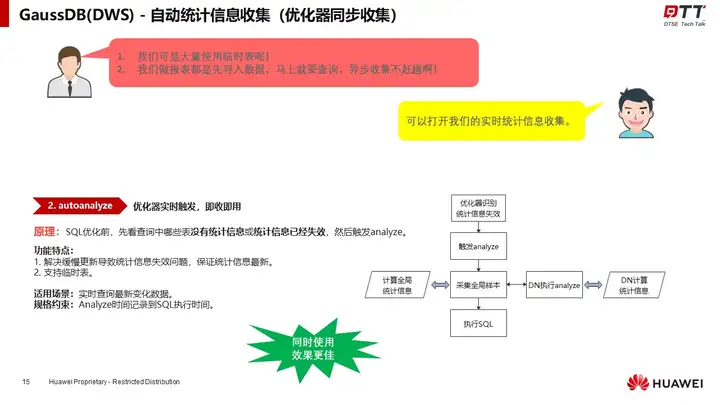
此外,还强调了自动收集的阈值控制方法,同时对收集不及时,统计信息可能失效的场景,提出了一种统计信息推算的兜底策略。确保每个查询都有及时有效的统计信息可用。保证了尽可能最优的执行性能。
通过“基本功能”,“收集方式”,“准确性”,“可靠性”,“估算增强”,详细的介绍了华为云GaussDB(DWS)近年来在统计信息方面的持续耕耘和比较有亮点的特色功能。
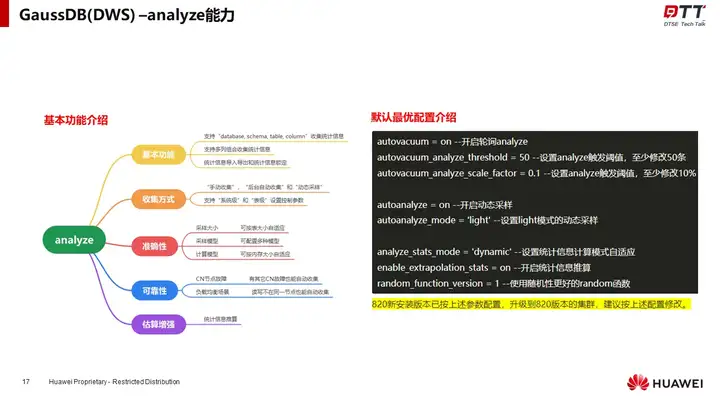
GaussDB(DWS)在analyze的各个执行过程中都进行了精心打造。统计信息是基于对目标数据的采样生成的,所以准确性才是统计信息的关键。
在采样大小,采样模型,计算模型等方面的深入投入,GaussDB(DWS)寻找出了这些问题的最佳答案。
最后给出了一键式统计信息自动收集的最优配置,让用户不再担心统计信息忘记收集的烦恼,帮助开发者专注于自己业务领域,减少统计信息忘收集的困扰。
我们知道了GaussDB(DWS)的统计信息自动收集功能很强大,那我们接下来更关心的是如何检测它的使用效果,如何知道收集的进度和方式。
如何判断统计信息是否失效,给用户提供了三种简单快速识别统计信息未收集的方法:
analyze易运维,通过非常巧妙的方法,将analyze每一步的执行过程和运行模式,详细的展示到活跃会话视图和线程等待视图,王跃也在最后列举了一些使用者最常问到关于analyze的几个TOP问题。

欢迎感兴趣的开发者们收看我们的直播回放,了解更多~
我正在使用i18n从头开始构建一个多语言网络应用程序,虽然我自己可以处理一大堆yml文件,但我说的语言(非常)有限,最终我想寻求外部帮助帮助。我想知道这里是否有人在使用UI插件/gem(与django上的django-rosetta不同)来处理多个翻译器,其中一些翻译器不愿意或无法处理存储库中的100多个文件,处理语言数据。谢谢&问候,安德拉斯(如果您已经在rubyonrails-talk上遇到了这个问题,我们深表歉意) 最佳答案 有一个rails3branchofthetolkgem在github上。您可以通过在Gemfi
我在使用omniauth/openid时遇到了一些麻烦。在尝试进行身份验证时,我在日志中发现了这一点:OpenID::FetchingError:Errorfetchinghttps://www.google.com/accounts/o8/.well-known/host-meta?hd=profiles.google.com%2Fmy_username:undefinedmethod`io'fornil:NilClass重要的是undefinedmethodio'fornil:NilClass来自openid/fetchers.rb,在下面的代码片段中:moduleNetclass
大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我看到这个错误:translationmissing:da.datetime.distance_in_words.about_x_hours我的语言环境文件:http://pastie.org/2944890我的看法:我已将其添加到我的application.rb中:config.i18n.load_path+=Dir[Rails.root.join('my','locales','*.{rb,yml}').to_s]config.i18n.default_locale=:da如果我删除I18配置,帮助程序会处理英语。更新:我在config/enviorments/devolpment
我遵循了教程http://gettingstartedwithchef.com/,第1章。我的运行list是"run_list":["recipe[apt]","recipe[phpap]"]我的phpapRecipe默认Recipeinclude_recipe"apache2"include_recipe"build-essential"include_recipe"openssl"include_recipe"mysql::client"include_recipe"mysql::server"include_recipe"php"include_recipe"php::modul
我在用Ruby执行简单任务时遇到了一件奇怪的事情。我只想用每个方法迭代字母表,但迭代在执行中先进行:alfawit=("a".."z")puts"That'sanalphabet:\n\n#{alfawit.each{|litera|putslitera}}"这段代码的结果是:(缩写)abc⋮xyzThat'sanalphabet:a..z知道为什么它会这样工作或者我做错了什么吗?提前致谢。 最佳答案 因为您的each调用被插入到在固定字符串之前执行的字符串文字中。此外,each返回一个Enumerable,实际上您甚至打印它。试试
如果我使用ruby版本2.5.1和Rails版本2.3.18会怎样?我有基于rails2.3.18和ruby1.9.2p320构建的rails应用程序,我只想升级ruby的版本,而不是rails,这可能吗?我必须面对哪些挑战? 最佳答案 GitHub维护apublicfork它有针对旧Rails版本的分支,有各种变化,它们一直在运行。有一段时间,他们在较新的Ruby版本上运行较旧的Rails版本,而不是最初支持的版本,因此您可能会发现一些关于需要向后移植的有用提示。不过,他们现在已经有几年没有使用2.3了,所以充其量只能让更
如何检查Ruby文件是否是通过“require”或“load”导入的,而不是简单地从命令行执行的?例如:foo.rb的内容:puts"Hello"bar.rb的内容require'foo'输出:$./foo.rbHello$./bar.rbHello基本上,我想调用bar.rb以不执行puts调用。 最佳答案 将foo.rb改为:if__FILE__==$0puts"Hello"end检查__FILE__-当前ruby文件的名称-与$0-正在运行的脚本的名称。 关于ruby-检查是否
大家好!我对我的:username字段进行了一个小的验证,它应该是4到30个字符。我写了一个验证::length=>{:within=>4..30,:message=>I18n.t('activerecord.errors.range')-我想显示一个错误各种错误的消息(不像,太长或太短),但这里有一个问题-我可以将最小值和最大值都传递给翻译,以便有类似的东西:用户名应该在4到30个字符之间。目前我有:range:"shouldbebetween%{count}and%{count}characters",这显然不起作用(只是为了检查)。是否可以从范围中获取这些值?谢谢大家的指教!