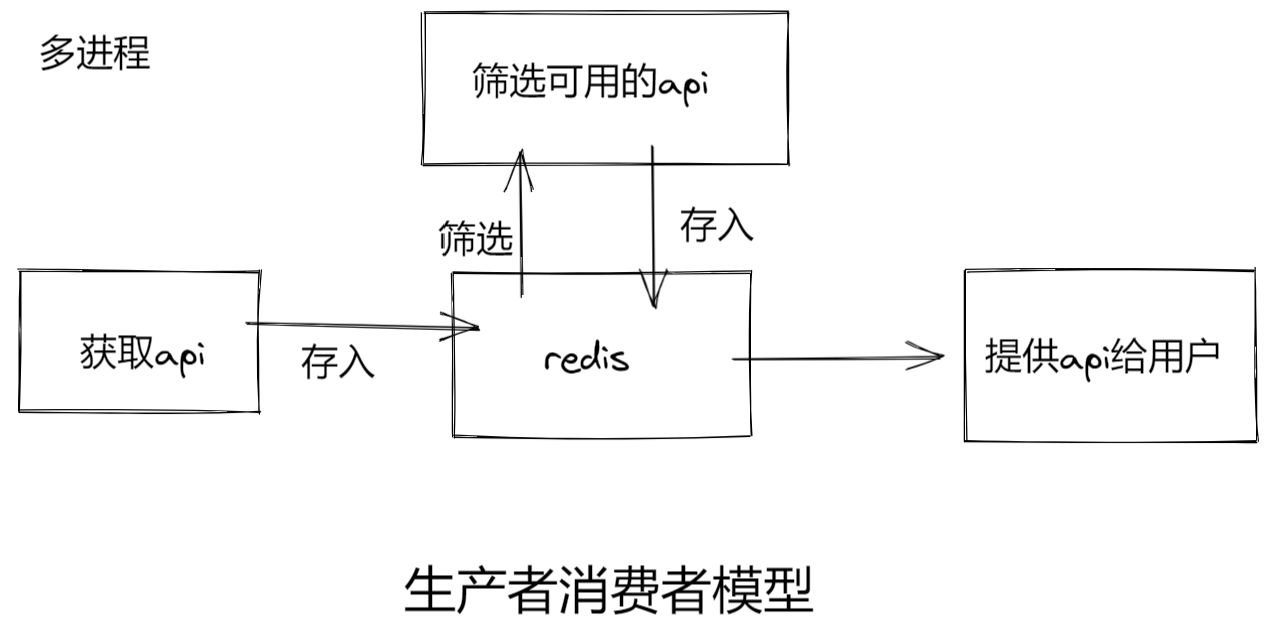
需要解决的问题:
使用什么方式存储ip
文件存储
缺点: 打开文件修改文件操作较麻烦
mysql
缺点: 查询速度较慢
mongodb
缺点: 查询速度较慢. 没有查重功能
redis --> 使用redis存储最为合适
所以 -> 数据结构采用redis中的zset有序集合
获取ip的网站
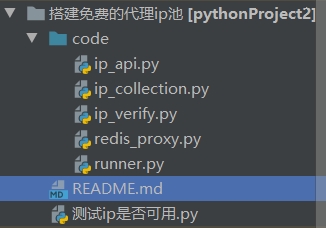
项目架构???
项目结构图
项目结构如下:
code文件夹
redis_proxy.py
# -*- encoding:utf-8 -*- # @time: 2022/7/4 11:32 # @author: Maxs_hu """ 这里用来做redis中间商. 去控制redis和ip之间的调用关系 """ from redis import Redis import random class RedisProxy: def __init__(self): # 连接到redis数据库 self.red = Redis( host='localhost', port=6379, db=9, password=123456, decode_responses=True ) # 1. 存储到redis中. 存储之前需要提前判断ip是否存在. 防止将已存在的ip的score抵掉 # 2. 需要校验所有的ip. 查询ip # 3. 验证可用性. 可用分值拉满. 不可用扣分 # 4. 将可用的ip查出来返回给用户 # 先给满分的 # 再给有分的 # 都没有分. 就不给 def add_ip(self, ip): # 外界调用并传入ip # 判断ip在redis中是否存在 if not self.red.zscore('proxy_ip', ip): self.red.zadd('proxy_ip', {ip: 10}) print('proxy_ip存储完毕', ip) else: print('存在重复', ip) def get_all_proxy(self): # 查询所有的ip功能 return self.red.zrange('proxy_ip', 0, -1) def set_max_score(self, ip): self.red.zadd('proxy_ip', {ip: 100}) # 注意是引号的格式 def deduct_score(self, ip): # 先将分数查询出来 score = self.red.zscore('proxy_ip', ip) # 如果有分值.那就扣一分 if score > 0: self.red.zincrby('proxy_ip', -1, ip) else: # 如果分值已经扣的小于0了. 那么可以直接删除了 self.red.zrem('proxy_ip', ip) def effect_ip(self): # 先将ip通过分数筛选出来 ips = self.red.zrangebyscore('proxy_ip', 100, 100, 0, -1) if ips: return random.choice(ips) else: # 没有满分的 # 将九十分以上的筛选出来 ips = self.red.zrangebyscore('proxy_ip', 11, 99, 0, -1) if ips: return random.choice(ips) else: print('无可用ip') return None
ip_collection.py
# -*- encoding:utf-8 -*- # @time: 2022/7/4 11:32 # @author: Maxs_hu """ 这里用来收集ip """ from redis_proxy import RedisProxy import requests from lxml import html from multiprocessing import Process import time import random def get_kuai_ip(red): url = "https://free.kuaidaili.com/free/intr/" headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36" } resp = requests.get(url, headers=headers) etree = html.etree et = etree.HTML(resp.text) trs = et.xpath('//table//tr') for tr in trs: ip = tr.xpath('./td[1]/text()') port = tr.xpath('./td[2]/text()') if not ip: # 将不含有ip值的筛除 continue proxy_ip = ip[0] + ":" + port[0] red.add_ip(proxy_ip) def get_unknown_ip(red): url = "https://ip.jiangxianli.com/" headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36" } resp = requests.get(url, headers=headers) etree = html.etree et = etree.HTML(resp.text) trs = et.xpath('//table//tr') for tr in trs: ip = tr.xpath('./td[1]/text()') port = tr.xpath('./td[2]/text()') if not ip: # 将不含有ip值的筛除 continue proxy_ip = ip[0] + ":" + port[0] red.add_ip(proxy_ip) def get_happy_ip(red): page = random.randint(1, 5) url = f'http://www.kxdaili.com/dailiip/2/{page}.html' headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36" } resp = requests.get(url, headers=headers) etree = html.etree et = etree.HTML(resp.text) trs = et.xpath('//table//tr') for tr in trs: ip = tr.xpath('./td[1]/text()') port = tr.xpath('./td[2]/text()') if not ip: # 将不含有ip值的筛除 continue proxy_ip = ip[0] + ":" + port[0] red.add_ip(proxy_ip) def get_nima_ip(red): url = 'http://www.nimadaili.com/' headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36" } resp = requests.get(url, headers=headers) etree = html.etree et = etree.HTML(resp.text) trs = et.xpath('//table//tr') for tr in trs: ip = tr.xpath('./td[1]/text()') # 这里存在空值. 所以不能在后面加[0] if not ip: continue red.add_ip(ip[0]) def get_89_ip(red): page = random.randint(1, 26) url = f'https://www.89ip.cn/index_{page}.html' headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36" } resp = requests.get(url, headers=headers) etree = html.etree et = etree.HTML(resp.text) trs = et.xpath('//table//tr') for tr in trs: ip = tr.xpath('./td[1]/text()') if not ip: continue red.add_ip(ip[0].strip()) def main(): # 创建一个redis实例化对象 red = RedisProxy() print("开始采集数据") while 1: try: # 这里可以添加各种采集的网站 print('>>>开始收集快代理ip') get_kuai_ip(red) # 收集快代理 # get_unknown_ip(red) # 收集ip print(">>>开始收集开心代理ip") get_happy_ip(red) # 收集开心代理 print(">>>开始收集泥马代理ip") # get_nima_ip(red) # 收集泥马代理 print(">>>开始收集89代理ip") get_89_ip(red) time.sleep(60) except Exception as e: print('ip储存出错了', e) time.sleep(60) if __name__ == '__main__': main() # 创建一个子进程 # p = Process(target=main) # p.start()
ip_verify.py
# -*- encoding:utf-8 -*- # @time: 2022/7/4 11:34 # @author: Maxs_hu """ 这里用来验证ip的可用性: 使用携程发送请求增加效率 """ from redis_proxy import RedisProxy from multiprocessing import Process import asyncio import aiohttp import time async def verify_ip(ip, red, sem): timeout = aiohttp.ClientTimeout(total=10) # 设置网页等待时间不超过十秒 try: async with sem: async with aiohttp.ClientSession() as session: async with session.get(url='http://www.baidu.com/', proxy='http://'+ip, timeout=timeout) as resp: page_source = await resp.text() if resp.status in [200, 302]: # 如果可用. 加分 red.set_max_score(ip) print('验证没有问题. 分值拉满~', ip) else: # 如果不可用. 扣分 red.deduct_score(ip) print('问题ip. 扣一分', ip) except Exception as e: print('出错了', e) red.deduct_score(ip) print('问题ip. 扣一分', ip) async def task(red): ips = red.get_all_proxy() sem = asyncio.Semaphore(30) # 设置每次三十的信号量 tasks = [] for ip in ips: tasks.append(asyncio.create_task(verify_ip(ip, red, sem))) if tasks: await asyncio.wait(tasks) def main(): red = RedisProxy() time.sleep(5) # 初始的等待时间. 等待采集到数据 print("开始验证可用性") while 1: try: asyncio.run(task(red)) time.sleep(100) except Exception as e: print("ip_verify出错了", e) time.sleep(100) if __name__ == '__main__': main() # 创建一个子进程 # p = Process(target=main()) # p.start()
ip_api.py
# -*- encoding:utf-8 -*- # @time: 2022/7/4 11:35 # @author: Maxs_hu """ 这里用来提供给用户ip接口. 通过写后台服务器. 用户访问我们的服务器就可以得到可用的代理ip: 1. flask 2. sanic --> 今天使用这个要稍微简单一点 """ from redis_proxy import RedisProxy from sanic import Sanic, json from sanic_cors import CORS from multiprocessing import Process # 创建一个app app = Sanic('ip') # 随便给个名字 # 解决跨域问题 CORS(app) red = RedisProxy() @app.route('maxs_hu_ip') # 添加路由 def api(req): # 第一个请求参数固定. 请求对象 ip = red.effect_ip() return json({"ip": ip}) def main(): # 让sanic跑起来 app.run(host='127.0.0.1', port=1234) if __name__ == '__main__': main() # p = Process(target=main()) # p.start()
runner.py
# -*- encoding:utf-8 -*- # @time: 2022/7/5 17:36 # @author: Maxs_hu from ip_api import main as api_run from ip_collection import main as coll_run from ip_verify import main as veri_run from multiprocessing import Process def main(): # 设置互不干扰的三个进程 p1 = Process(target=api_run) # 只需要将目标函数的内存地址传过去即可 p2 = Process(target=coll_run) p3 = Process(target=veri_run) p1.start() p2.start() p3.start() if __name__ == '__main__': main()
测试ip是否可用.py
# -*- encoding:utf-8 -*-
# @time: 2022/7/5 18:15
# @author: Maxs_hu
import requests
def get_proxy():
url = "http://127.0.0.1:1234/maxs_hu_ip"
resp = requests.get(url)
return resp.json()
def main():
url = 'http://mip.chinaz.com/?query=' + get_proxy()["ip"]
proxies = {
"http": 'http://' + get_proxy()["ip"],
"https": 'http://' + get_proxy()["ip"] # 目前代理只支持http请求
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36",
}
resp = requests.get(url, proxies=proxies, headers=headers)
resp.encoding = 'utf-8'
print(resp.text) # 物理位置
if __name__ == '__main__':
main()
项目运行截图:
redis储存截图:
出于纯粹的兴趣,我很好奇如何按顺序创建PI,而不是在过程结果之后生成数字,而是让数字在过程本身生成时显示。如果是这种情况,那么数字可以自行产生,我可以对以前看到的数字实现垃圾收集,从而创建一个无限系列。结果只是在Pi系列之后每秒生成一个数字。这是我通过互联网筛选的结果:这是流行的计算机友好算法,类机器算法:defarccot(x,unity)xpow=unity/xn=1sign=1sum=0loopdoterm=xpow/nbreakifterm==0sum+=sign*(xpow/n)xpow/=x*xn+=2sign=-signendsumenddefcalc_pi(digits
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我对最新版本的Rails有疑问。我创建了一个新应用程序(railsnewMyProject),但我没有脚本/生成,只有脚本/rails,当我输入ruby./script/railsgeneratepluginmy_plugin"Couldnotfindgeneratorplugin.".你知道如何生成插件模板吗?没有这个命令可以创建插件吗?PS:我正在使用Rails3.2.1和ruby1.8.7[universal-darwin11.0] 最佳答案 随着Rails3.2.0的发布,插件生成器已经被移除。查看变更日志here.现在
如何使用RSpec::Core::RakeTask初始化RSpecRake任务?require'rspec/core/rake_task'RSpec::Core::RakeTask.newdo|t|#whatdoIputinhere?endInitialize函数记录在http://rubydoc.info/github/rspec/rspec-core/RSpec/Core/RakeTask#initialize-instance_method没有很好的记录;它只是说:-(RakeTask)initialize(*args,&task_block)AnewinstanceofRake
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion为什么SecureRandom.uuid创建一个唯一的字符串?SecureRandom.uuid#=>"35cb4e30-54e1-49f9-b5ce-4134799eb2c0"SecureRandom.uuid方法创建的字符串从不重复?
我正在阅读SandiMetz的POODR,并且遇到了一个我不太了解的编码原则。这是代码:classBicycleattr_reader:size,:chain,:tire_sizedefinitialize(args={})@size=args[:size]||1@chain=args[:chain]||2@tire_size=args[:tire_size]||3post_initialize(args)endendclassMountainBike此代码将为其各自的属性输出1,2,3,4,5。我不明白的是查找方法。当一辆山地自行车被实例化时,因为它没有自己的initialize方法
我有一个存储主机名的Ruby数组server_names。如果我打印出来,它看起来像这样:["hostname.abc.com","hostname2.abc.com","hostname3.abc.com"]相当标准。我想要做的是获取这些服务器的IP(可能将它们存储在另一个变量中)。看起来IPSocket类可以做到这一点,但我不确定如何使用IPSocket类遍历它。如果它只是尝试像这样打印出IP:server_names.eachdo|name|IPSocket::getaddress(name)pnameend它提示我没有提供服务器名称。这是语法问题还是我没有正确使用类?输出:ge
我正在尝试按0-9和a-z的顺序创建数字和字母列表。我有一组值value_array=['0','1','2','3','4','5','6','7','8','9','a','b','光盘','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','','u','v','w','x','y','z']和一个组合列表的数组,按顺序,这些数字可以产生x个字符,比方说三个list_array=[]和一个当前字母和数字组合的数组(在将它插入列表数组之前我会把它变成一个字符串,]current_combo['0','0','0']
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵