文章目录
在实施DFMEA阶段中,要求、潜在失效模式、潜在失效后果、潜在失效原因和现有设计控制措施等 5 个为基础项, 它们的分析是决定 DFMEA实施成功与否的关键;严重度(S),频度(O),探测度(D),风险优先系数(RPN)和建议的纠正措施为衍生项。只有基础项确定之后, 衍生项才可以随之确定。
严重度是指对一个特定失效模式的最严重的影响后果的评价等级。严重度是在单个FMEA范围内的一个相对级别。评估标准小组应当同意一个评估标准和评级系统,即使为单个过程分析而更改,也应始终一致地应用此标准。 (标准指南可参见下面的表格)。不建议更改严重度为9和10的评级标准。严重度等级评为1的失效模式不应当再进一步分析。
| 后果 | 判定准则:产品影响严重度 | 严重度级别 |
|---|---|---|
| 不符合安全和/或法规要求 | 潜在失效模式影响车辆安全运行和/或不符合政府法规的情形。失效发生时无警告 | 10 |
| 潜在失效模式影响车辆安全运行和/或不符合政府法规的情形。失效发生时有警告 | 9 | |
| 主要功能丧失和/或降级 | 丧失基本功能(车辆不能运行,不影响安全) | 8 |
| 主要功能降级(车辆可运行,但性能层次下降) | 7 | |
| 次要功能丧失和/或降低 | 次要功能丧失 (车辆可运行,但舒适性/便利性等功能失效) | 6 |
| 丧失次要功能(车辆可运行,但舒适性/便利性等功能层次降低) | 5 | |
| 干扰 | 汽车可运行,但外观/噪音等项目不舒服,并且大多数(>75%)顾客会发现这些缺陷 | 4 |
| 汽车可运行,但外观/噪音等项目不舒服,并且许多(50%)顾客会发现这些缺陷 | 3 | |
| 汽车可运行,但外观/噪音等项目不舒服,并且少数(<25%)有辨别能力的顾客会发现这些缺陷 | 2 | |
| 无影响 | 没有可识别的后果 | 1 |
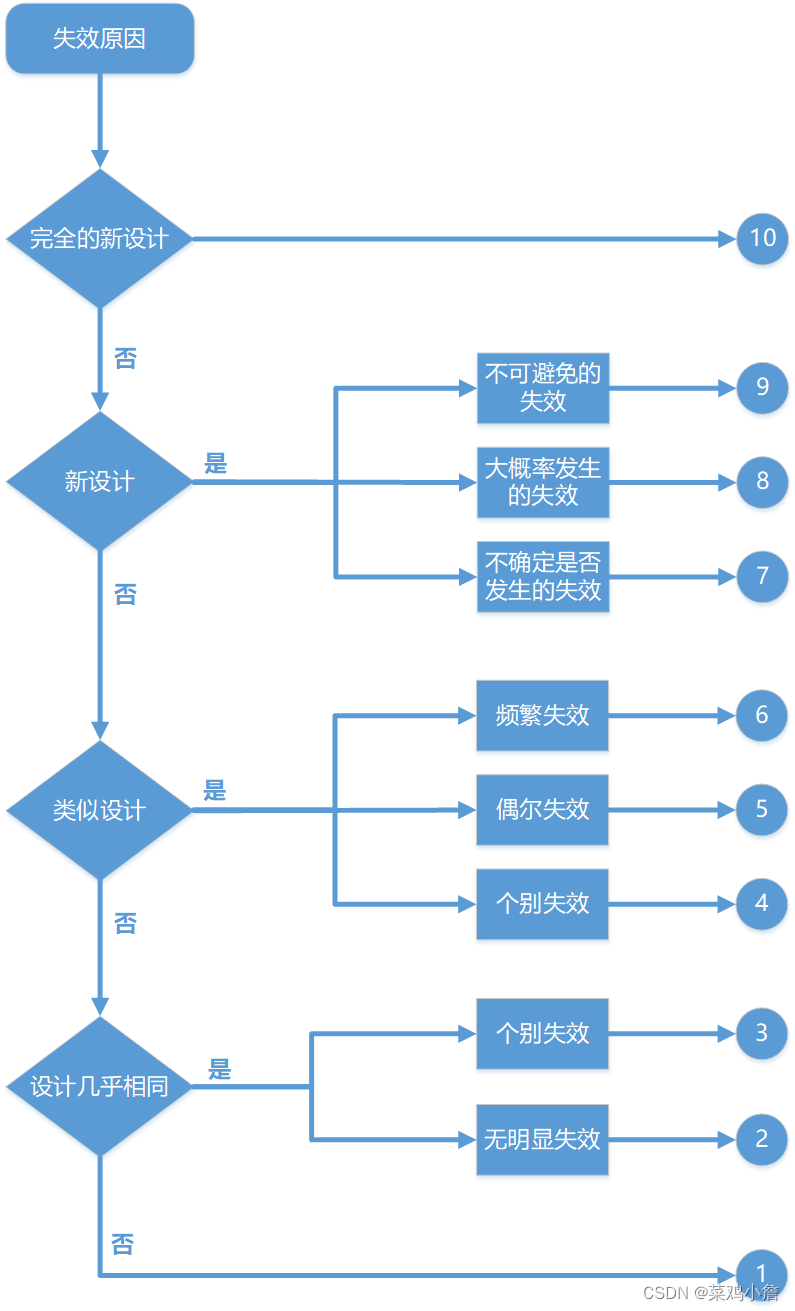
下方的分析流程仅供参考:
发生频度是指一个特定原因/机制的发生的可能性。此原因会在设计寿命内导致失效模式发生。发生可能性的等级评估代表的是相对意义,而不是绝对的值(参见下表) 。应当有一个一致的发生频度的评级系统以确保连续性。发生频度是一个FMEA范围内的相对评级,不是绝对反映实际的发生可能性。
| 失效可能性 | 评价准则:针对DFMEA要因发生率(设计寿命/项目可靠性/车辆) | 评价准则:针对DFMEA要因发生率(事件/项目/车辆) | 等级 |
|---|---|---|---|
| 非常高 | 无历史的新技术/新设计 | ≥100次每1000个,≥1次每10辆 | 10 |
| 高 | 新设计,新应用或使用寿命/操作条件的改变情况下不可避免的失效 | 50次每1000个,1次每20辆 | 9 |
| 新设计,新应用或使用寿命/操作条件的改变情况下很可能发生的失效 | 20次每1000个,1次每50辆 | 8 | |
| 新设计,新应用或使用寿命/操作条件的改变情况下不确定是否会发生的失效 | 10次每1000个,1次每100辆 | 7 | |
| 一般 | 与类似设计相关或在设计模拟和测试中频繁失效 | 2次每1000个,1次每500辆 | 6 |
| 与类似设计相关或在设计模拟和测试中偶然发生的失效 | 0.5次每1000个,1次每2000辆 | 5 | |
| 与类似设计相关或在设计模拟和测试中较少发生的失效 | 0.1次每1000个,1次每10000辆 | 4 | |
| 低 | 仅仅在与几乎相同的设计关联或在设计模拟和测试发生的失效 | 0.01次每1000个,1次每100000辆 | 3 |
| 在与几乎相同的设计关联或在设计模拟和试验时不能观察的失效 | ≤0.001次每1000个,≤1次每1,000,000辆 | 2 | |
| 非常低 | 失效通过预防控制来消除 | 失效通过预防控制消除 | 1 |
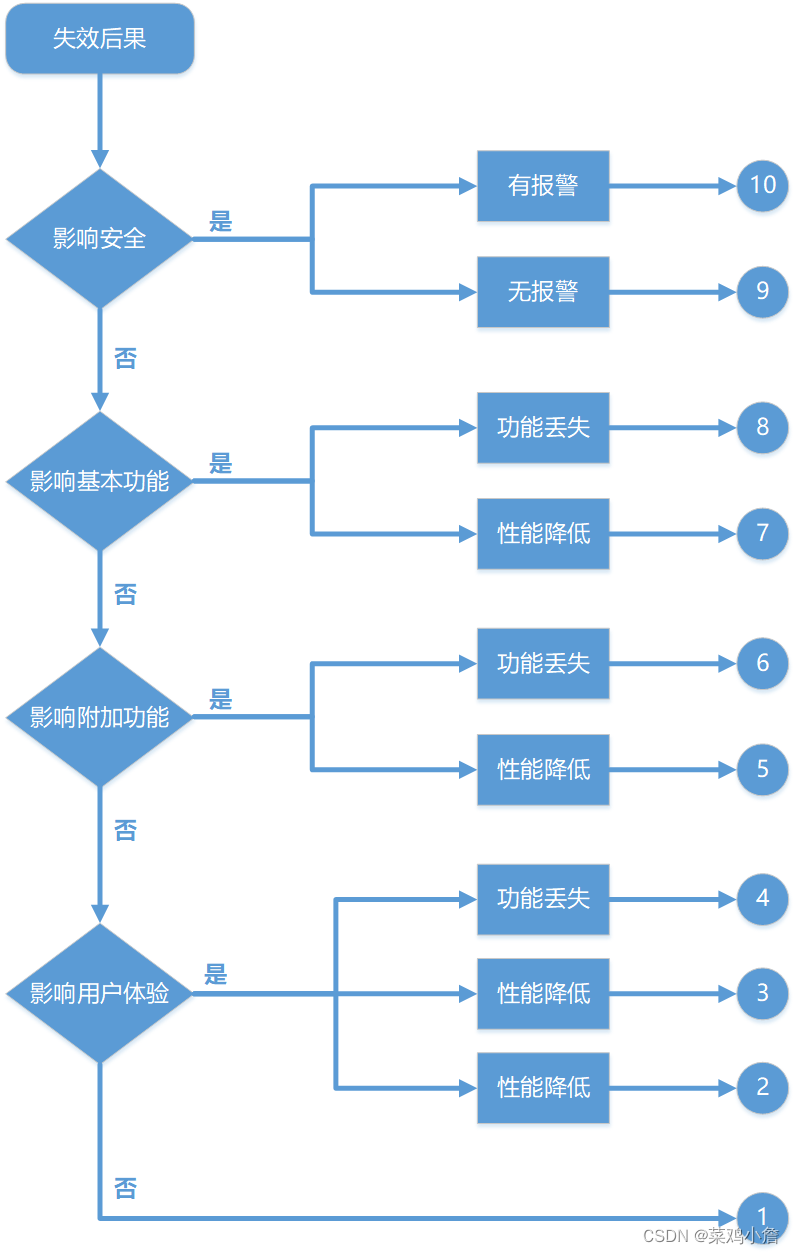
下方的分析流程仅供参考:
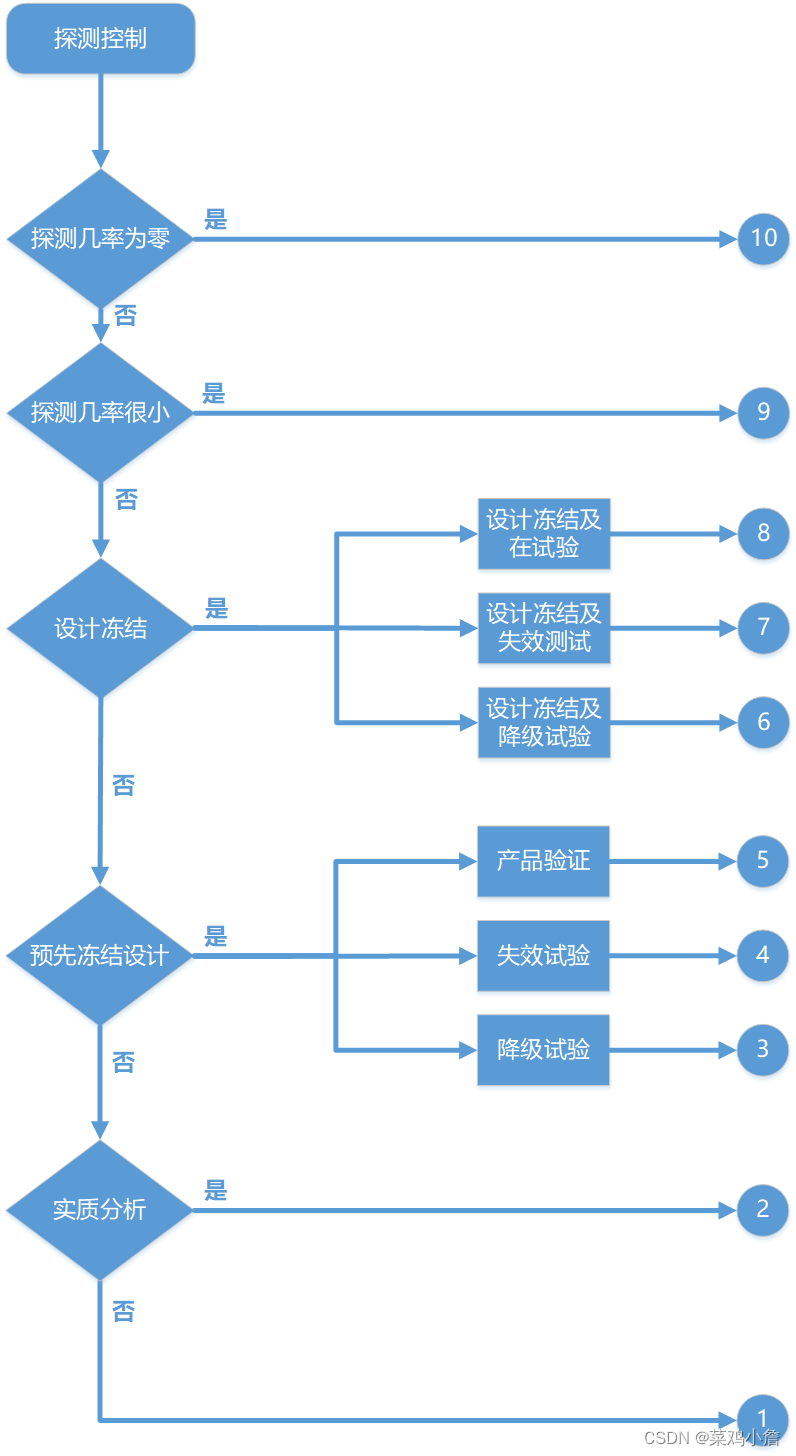
探测度是指现行设计控制发现栏里,所列出的最佳的探测控制相关的等级。当识别到不止一个的控制的时候,建议将每个控制的探测等级包括在控制描述内,并且在探测度栏里记录等级最低的评分。现行设计控制探测度的建议方法是,首先假定失效已经发生,然后评估现有设计控制探测此失效模式的能力。不要因为发生频度等级低,就理所当然认为探测度等级也一定低。评估设计控制探测低频次的失效模式,或者降低失效进入设计发布过程的风险的能力是十分重要的。探测度是在单个的FMEA范围内的一个相对评级。 为了达到更低的等级, 就应对设计控制 ( 分析或验证活动)进行改进。
| 探测几率 | 评价准则:被设计控制发行的可能性 | 探测情况 | 等级 |
|---|---|---|---|
| 没有探测机会 | 没有现有设计控制;不能探测或不能分析 | 没有探测的可能性 | 10 |
| 探测机会很小 | 设计分析/探测有微弱的探测能力;实际的分析(如CAE,FEA,etc.)与期望的实际操作条件不相关 | 任何阶段探测的机会都很小 | 9 |
| 设计冻结 | 在设计冻结以及在试验通过/失败的情况预先投放后的产品验证/确认 | 后加工问题 | 8 |
| 在设计冻结和在失效测试实验的情况下的预先投放后的产品验证/确认 | 源头探测 | 7 | |
| 在设计冻结以及在降级试验情况下预先投放后的产品验证/确认 | 后加工问题 | 6 | |
| 预冻结设计 | 使用通过/失效试验进行产品验证,预先冻结设计 | 源头探测 | 5 |
| 使用失效试验预先冻结设计的产品确认 | 后加工问题 | 4 | |
| 使用降级试验(如数据趋势、之前/之后值等)预先冻结设计的产品确认 | 源头探测 | 3 | |
| 实质分析 | 设计分析/探测控制有强探测能力,在实际或期望运作条件下预先停止设计与实质性分析高相关 | 错误探测/问题预防 | 2 |
| 失效预防 | 通过设计解决方案充分执行预防,失效要因或失效模式将不会发生 | 不需要探测/应用防错 | 1 |
当小组完成失效模式与影响、原因与控制的初始识别,包括严重度、发生频度、探测度的等级评估,小组必须决定是否还要进一步采取措施降低风险。由于资源、时间、技术等其它因素的固有限制,小组必须选取最佳的优先措施。当严重度等级达到9或10,小组必须确保该风险已经通过现有设计控制或建议措施阐明此风险(在FMEA内有记录)。风险优先系数(RPN):帮助决定优先措施的方法之一就是使用风险顺序数:
风险优先系数RPN=严重度( s)×发生频度(O)×探测度(D)
在单独的FMEA范围内,数值可以在1到1000之间变化。第四版手册不推荐使用RPN阀值来决定是否需要采取措施。使用阀值意味着RPN是衡量相对风险的方法,而且不要求持续的改进。关于RPN改进的标准,与行业有关,与企业的目标及成本效益计划有关。实际运用过程中,这一标准在60-150之间不等。最严格的是摩托罗拉,定的是60分;北京现代定的是80分,大部分制造企业定的是100分。在实际车用项目中,通常取S值8以上,RPN值100以上时,需要采取强制措施,降低两者的值或提出建议措施。FMEA手册第五版取消RPN的选项,采用矩阵AP的方式评定风险。现第五版手册英文版已经有了,大家网上查看一下。谨记时代的发展,跟上时代的步伐。
在以下示例中,我无法理解Ruby运算符的优先级:x=1&&y=2由于&&的优先级高于=,我的理解是类似于+和*运算符:1+2*3+4解析为1+(2*3)+4它应该等于:x=(1&&y)=2但是,所有Ruby源代码(包括内部语法解析器Ripper)都将其解析为x=(1&&(y=2))为什么?编辑[08.01.2016]让我们关注一个子表达式:1&&y=2根据优先规则,我们应该尝试将其解析为:(1&&y)=2这没有意义,因为=需要特定的LHS(变量、常量、[]数组项等)。但是既然(1&&y)是一个正确的表达式,那么解析器应该如何处理呢?我试过咨询Ruby的parse.y,但它太像意大利面条
题目描述小张买了 n 件白色的衣服,他觉得所有衣服都是一种颜色太单调,希望对这些衣服进行染色,每次染色时,他会将某种颜色的所有衣服寄去染色厂,第 i 件衣服的邮费为 ai 元,染色厂会按照小张的要求将其中一部分衣服染成同一种任意的颜色,之后将衣服寄给小张,请问小张要将 n 件衣服染成不同颜色的最小代价是多少?输入描述第一行为一个整数 n ,表示衣服的数量。第二行包括 n 个整数a1,a2...an 表示第 i 件衣服的邮费为 ai 元。(1≤n≤10^5,1≤ai≤10^9 )输出描述输出一个整数表示小张所要花费的最小代价。输入输出样例输入551321输出25 思考🤔:题意:意思是
这里有两个测试:if[1,2,3,4].include?2&&nil.nil?puts:helloend#=>和if[1,2,3,4].include?(2)&&nil.nil?puts:helloend#=>hello上面告诉我&&比方法参数有更高的优先级,所以它逻辑上和2&&nil.nil?是真的,并将它作为参数传递给include?但是,有这个测试:if[1,2,3,4].include?2andnil.nil?puts:helloend#=>hello所以这告诉我方法参数和“and”具有相同的优先级(或者方法参数高于“and”)因为它传递了2以包含?在处理“和”之前。注意:我知
是否可以使用Amazon简单排队服务创建优先级队列?最初我找不到关于这个主题的任何内容,这就是我创建两个队列的原因。一个普通队列和一个优先队列。我正在根据我定义的规则将消息排入此队列,但在出列消息时会出现困惑。如何对队列进行长时间轮询,使我的队列组合表现得像一个优先级队列? 最佳答案 我认为您通过创建两个队列走在正确的轨道上-一个普通队列和一个优先级队列。在这种情况下,您不一定需要长时间轮询。由于优先队列中的消息优先于普通队列中的消息,您可以采用如下方法:轮询优先级队列,直到没有更多消息为止。轮询普通队列并在普通队列中的每条消息后重
运算符优先级的一些信息来源likethis表示!、~、+、-等一元运算符具有更高优先级比赋值=。但是,以下表达式是可能的:!a=true#=>false(withwarning)a#=>true~a=1#=>-2a#=>1+a=1#=>1a#=>1-a=1#=>-1a#=>1考虑到这些结果,我能想到的唯一可能的解释是这些一元运算符的优先级低于赋值。如果是这样的话,那就意味着我上面提到的信息是错误的。哪个是正确的?有不同的解释吗? 最佳答案 我的编程ruby书(第2版)也将一元运算符列为具有比赋值更高的优先级。一元运算符被赋予最高
我将向您展示来自rubykoans的代码片段教程。考虑下一个代码:classMyAnimalsLEGS=2classBird实际上问题在评论中(我用星号突出显示了它(尽管它打算以粗体显示))。有人可以解释一下吗?提前致谢! 最佳答案 这里有答案:Ruby:explicitscopingonaclassdefinition.但也许它不是很清楚。如果您阅读链接的文章,它将帮助您找到答案。基本上,Bird是在MyAnimals的范围内声明的,在解析常量时具有更高的优先级。Oyster位于MyAnimals命名空间中,但未在该范围内声明。将
查看下面的作业,我假设该作业在low_priority队列上运行。classGuestsCleanupJob我同意这一点,但这只是队列的名称对吗?它实际上与优先级无关。例如,如果我创建了一个队列名为:my_queue的作业,它将被视为具有与:low_priority队列相同的优先级。从文档中我无法找到任何表明我可以对排队的作业进行优先排序的信息。我知道delayed_jobs有这个功能,但我在active_job中没有找到它。 最佳答案 优先级取决于实际的QueueAdapter以及此适配器的配置方式。如果您的适配器不支持优先级或未
以前的答案answer类似question是错误的。Ruby中均未提及方法调用documentation也不在communitywiki.不带括号的方法调用高于或or似乎比没有括号的方法调用具有更低的优先级:putsfalseortrue相当于(putsfalse)ortrue并显示false。注意:我知道不应该使用or。尽管如此,这仍然是一个很好的例子,表明某些运算符的优先级确实低于方法调用。低于||putsfalse||true相当于puts(false||true)并显示true。带括号的方法调用用于方法调用的括号don'tseem进行分组:puts(falseortrue)#S
我的RubyonRails应用程序中有几个模型,如“Plan”、“Tester”、“Module”等。使用activeadmingem,我想为每个实体创建一个页面,并将每个实体放在下面几个不同的菜单。所以我的代码如下所示:ActiveAdmin.registerPlandomenuparent:'Planning',priority:1ActiveAdmin.registerTesterdomenuparent:'Planning',priority:2ActiveAdmin.registerModuledomenuparent:'Bundle',priority:1ActiveAdm
这个问题在这里已经有了答案:Differencebetween"and"and&&inRuby?(8个答案)关闭7年前。我对Ruby中的and/&&/=关键字有疑问。ruby文档说所提到的关键字的优先级是:(1)&&、(2)=、(3)and。我有我写的这段代码:deff(n)nendifa=f(2)andb=f(4)thenputs"1)#{a}#{b}"endifa=f(2)&&b=f(4)thenputs"2)#{a}#{b}"end输出是:1)24[预期]2)44[为什么?]出于某种原因,使用&&会导致a和b的计算结果都为4?