偶然一天把某项目文档传到手机上,用手机自带的阅读器方便随时拿出来查阅。看着我那好久没点开的阅读器,再看着书架上摆着几本不知道是多久之前导入的小说。
闭上眼,我仿佛看到那时候的自己。侧躺着缩在被窝里,亮度调到最低,看的津津有味。
睁开眼,一声短叹,心中五味杂陈,时间像箭一样飞逝而去,过去静止不动,未来姗姗来迟。
正好最近又重温了下python,准备做一个简单的获取小说txt文件的程序。
win + r 输入cmd
命令行输入
pip install requests
pip install pyquery
嫌麻烦pycharm直接搜索包安装就行
纯属爱好,仅供学习
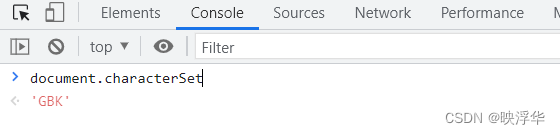
老样子,F12进控制台,输入 document.chartset 查看网页编码

1 # 请求网页 获取网页数据
2 def GetHTMLText(url: str) -> str:
3 res = requests.get(url=url, headers=GetHeader(), proxies=GetProxy())
4 res.encoding = "GBK"
5 html: str = res.text
6 return html
测试地址:---
Ctrl + Shift + C ,选择章节目录任意一章
可以发现章节目录class="zjlist"下的<dd>标签内含有每一章节的信息,该章节的url和章节名
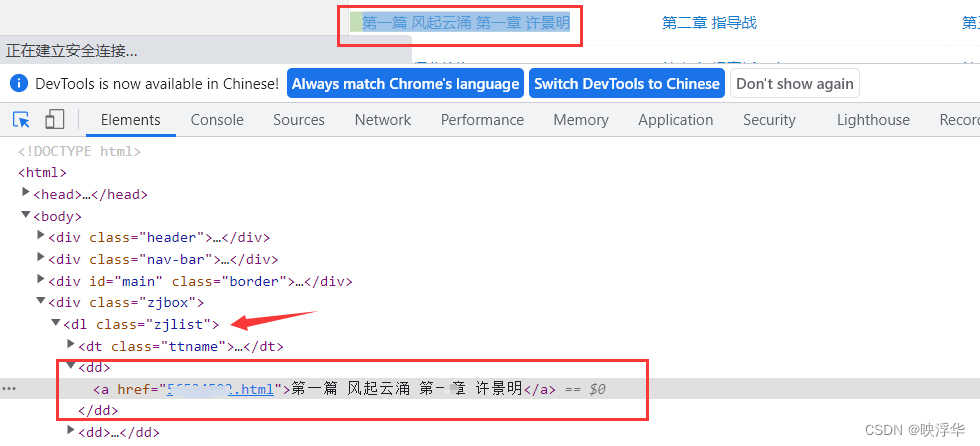
代码如下:
1 # 获取章节目录
2 def GetPageTree(doc: pQ) -> pQ:
3 pageTree: pQ = doc('.zjlist dd a')
4 return pageTree
GBK转码:
在搜索框内输入名称,searchkey=,后就是该名称对应的GBK编码

将链接后的编码输进进行解码,得到你所输入的文字内容
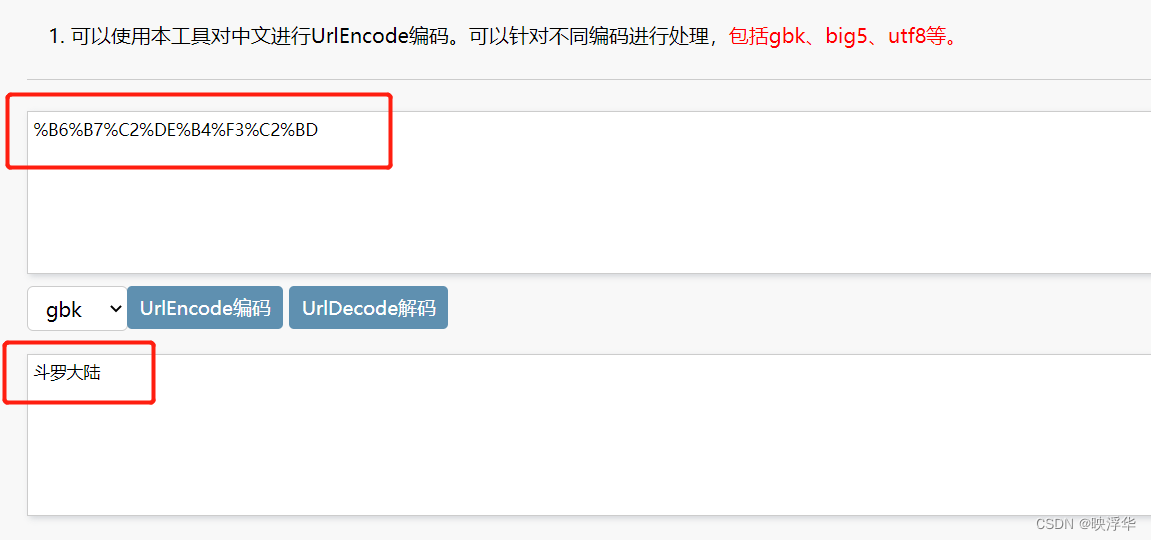
代码如下:
1 # 输入转码 获取搜索到的书籍链接
2 def GetSearchUrl(Novel_Name: str) -> str:
3 StrToGbk: bytes = Novel_Name.encode("gbk")
4 GbkToStr: str = str(StrToGbk)
5 Url_input = GbkToStr[2:-1].replace("\\x", "%").upper()
6 Url = "---" + "searchtype=articlename&searchkey="
7 return Url + Url_input
搜索到小说之后跳转到搜索到的网页,可能会出现两种情况
一种是一次搜索到结果
还有一种是搜索到多种结果,需要对这个网页再做一次解析筛选
判断网页容器的id="info",是否有这个节点
代码如下:
1 # 抓取模式
2 def GetModel(doc: pQ) -> bool:
3 if doc('#info'):
4 return True # 一次搜索到,不需要筛选
5 else:
6 return False
1 import os
2 import requests
3 import time
4 import re
5 from random import choice
6 from pyquery import PyQuery as pQ
7
8
9 # 获取请求头
10 def GetHeader() -> dict:
11 header = [ # 请求头
12 {
13 "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.67 Safari/537.36"
14 },
15 {
16 "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1"
17 },
18 {
19 "User-Agent": "Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1"
20 },
21 {
22 "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36"
23 },
24 {
25 "User-Agent": "Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10"
26 },
27 {
28 "User-Agent": "Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10"
29 },
30 {
31 "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36"
32 },
33 {
34 "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36"
35 },
36 {
37 "User-Agent": "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0)"
38 },
39 {
40 "User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50"
41 }
42 ]
43 return choice(header)
44
45
46 # 获取代理
47 def GetProxy() -> dict:
48 proxies = [ # 代理
49 {
50 "Https": "60.170.204.30:8060"
51 },
52 {
53 "Https": "103.37.141.69:80"
54 },
55 {
56 "Https": "183.236.232.160:8080"
57 },
58 {
59 "Https": "202.55.5.209:8090"
60 },
61 {
62 "Https": "202.55.5.209:8090"
63 }
64 ]
65 return choice(proxies)
66
67
68 # 输入转码 获取搜索到的书籍链接
69 def GetSearchUrl(Novel_Name: str) -> str:
70 StrToGbk: bytes = Novel_Name.encode("gbk")
71 GbkToStr: str = str(StrToGbk)
72 Url_input = GbkToStr[2:-1].replace("\\x", "%").upper()
73 Url = "---" + "modules/article/search.php?searchtype=articlename&searchkey="
74 return Url + Url_input
75
76
77 # 请求网页 获取网页数据
78 def GetHTMLText(url: str) -> str:
79 res = requests.get(url=url, headers=GetHeader(), proxies=GetProxy())
80 # Console --- document.charset ---'GBK'
81 res.encoding = "GBK"
82 html: str = res.text
83 return html
84
85
86 # 获取网页解析
87 def GetParse(url: str) -> pQ:
88 text = GetHTMLText(url)
89 doc: pQ = pQ(text)
90 return doc
91
92
93 # 获取小说名
94 def GetNovelName(doc: pQ) -> str:
95 con = doc('#info')
96 novel_name: str = con('h1').text().split(' ')[0]
97 return novel_name
98
99
100 # 获取章节目录
101 def GetPageTree(doc: pQ) -> pQ:
102 pageTree: pQ = doc('.zjlist dd a')
103 return pageTree
104
105
106 # 提取章节链接跳转后的页面内容 id="content"
107 def GetNovel(url) -> str:
108 doc = GetParse(url)
109 con = doc('#content')
110 novel: str = con.text()
111 return novel
112
113
114 # 获取总页数
115 def GetPageNums(doc: pQ):
116 pageNums = doc('.form-control option')
117 return pageNums
118
119
120 # 获取novel主页链接
121 def GetHomeUrl(doc: pQ) -> str:
122 PageNums = GetPageNums(doc)
123 for page in PageNums.items():
124 if page.text() == "第1页":
125 return page.attr('value')
126
127
128 # 抓取模式
129 def GetModel(doc: pQ) -> bool:
130 if doc('#info'):
131 return True # 一次搜索到,不需要筛选
132 else:
133 return False
134
135
136 # 搜索到结果开始抓取
137 # Args_url---novel主页链接
138 # ms---间隔时间,单位:ms
139 # url_ 主网站
140 def GetDate_1(Args_url: str, doc: pQ, ms: int, url_: str = "---") -> None:
141 NovelName = GetNovelName(doc)
142 PageNums = GetPageNums(doc)
143 file_path = os.getcwd() + "\\" + NovelName # 文件存储路径
144 setDir(file_path) # 判断路径是否存在,不存在创建,存在删除
145 Seconds: float = ms / 1000.0
146 for page in PageNums.items():
147 url = url_ + page.attr('value') # 每一页的链接
148 currentPage = page.text() # 当前页
149 doc: pQ = GetParse(url)
150 page_tree = GetPageTree(doc)
151 for page_Current in page_tree.items():
152 page_name: str = page_Current.text() # 章节名
153 page_link = page_Current.attr('href') # 章节链接
154 novel = page_name + "\n\n" + GetNovel(Args_url + page_link) + "\n\n" # 文章内容
155 page_Name = clean_file_name(page_name) # 处理后的章节名
156 download_path = file_path + "\\" + NovelName + ".txt" # 文件下载路径
157 with open(download_path, "a", encoding="utf-8") as f:
158 f.write(novel)
159 print("正在下载 {}...".format(page_Name))
160 time.sleep(Seconds)
161 f.close()
162 print("{}下载成功\n".format(page_Name))
163 print("{}下载完成\n".format(currentPage))
164 print("{}下载完成!".format(NovelName))
165
166
167 # 搜索到重复结果,需要进行筛选.匹配成功返回首页的网址
168 def GetUrl_2(doc: pQ, SearchName: str) -> str:
169 con = doc('.odd a').items()
170 for Title in con:
171 if Title.text() == SearchName:
172 url: str = Title.attr('href')
173 return url
174
175
176 # 文件处理
177 def setDir(filepath):
178 if not os.path.exists(filepath): # 如果文件夹不存在就创建
179 os.mkdir(filepath)
180 else:
181 for i in os.listdir(filepath): # os.listdir(filepath)返回一个列表,里面是当前目录下面的所有东西的相对路径
182 file_data = filepath + "\\" + i # 当前文件夹下文件的绝对路径
183 if os.path.isfile(file_data):
184 os.remove(file_data) # 文件存在-删除
185
186
187 # 异常文件名处理
188 def clean_file_name(filename: str):
189 invalid_chars = '[\\\/:*??"<>|]'
190 replace_char = '-'
191 return re.sub(invalid_chars, replace_char, filename)
192
193
194 # 保存文件
195 def SaveFile(url: str, searchName: str):
196 doc = GetParse(url)
197 url_: str = "---" #懂得都懂
198 try:
199 if GetModel(doc):
200 url = url_ + GetHomeUrl(doc)
201 doc = doc
202 else:
203 url = GetUrl_2(doc, searchName)
204 doc = GetParse(url)
205 GetDate_1(Args_url=url, doc=doc, ms=100)
206 except Exception as result:
207 print("{}".format(result))
208 finally:
209 print("请输入有效书名")
210
211
212 # 输入名字搜索
213 def main():
214 SearchName = input("请输入需要下载的书名:")
215 url = GetSearchUrl(SearchName)
216 SaveFile(url, SearchName)
217
218
219 if __name__ == "__main__":
220 main()

按名称搜索跟直接拿首页链接原理差不多,只不过多了个筛选的操作
以上就是今天要分享的内容,时间原因还有很多可以优化的地方,后面有时间再改吧……
最后说说自己的一些想法,为什么现在对小说没什么感觉了。
看小说除了让我的鼻梁上戴着的东西越来越厚之外,还让我的作息变得一团糟。我是个管不住自己的人,以前看小说最着迷的时候,除了吃饭睡觉,剩下时间全拿来看小说了。
当然,看小说也并不像我说的那样百害无一利,但是要注意合理安排好自己的时间,劳逸结合。?
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub
我使用Nokogiri(Rubygem)css搜索寻找某些在我的html里面。看起来Nokogiri的css搜索不喜欢正则表达式。我想切换到Nokogiri的xpath搜索,因为这似乎支持搜索字符串中的正则表达式。如何在xpath搜索中实现下面提到的(伪)css搜索?require'rubygems'require'nokogiri'value=Nokogiri::HTML.parse(ABBlaCD3"HTML_END#my_blockisgivenmy_bl="1"#my_eqcorrespondstothisregexmy_eq="\/[0-9]+\/"#FIXMEThefoll
我真的为这个而疯狂。我一直在搜索答案并尝试我找到的所有内容,包括相关问题和stackoverflow上的答案,但仍然无法正常工作。我正在使用嵌套资源,但无法使表单正常工作。我总是遇到错误,例如没有路线匹配[PUT]"/galleries/1/photos"表格在这里:/galleries/1/photos/1/edit路线.rbresources:galleriesdoresources:photosendresources:galleriesresources:photos照片Controller.rbdefnew@gallery=Gallery.find(params[:galle
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
我想解析一个已经存在的.mid文件,改变它的乐器,例如从“acousticgrandpiano”到“violin”,然后将它保存回去或作为另一个.mid文件。根据我在文档中看到的内容,该乐器通过program_change或patch_change指令进行了更改,但我找不到任何在已经存在的MIDI文件中执行此操作的库.他们似乎都只支持从头开始创建的MIDI文件。 最佳答案 MIDIpackage会为您完成此操作,但具体方法取决于midi文件的原始内容。一个MIDI文件由一个或多个音轨组成,每个音轨是十六个channel中任何一个上的
本文主要介绍在使用Selenium进行自动化测试或者任务时,对于使用了iframe的页面,如何定位iframe中的元素文章目录场景描述解决方案具体代码场景描述当我们在使用Selenium进行自动化测试的时候,可能会遇到一些界面或者窗体是使用HTML的iframe标签进行承载的。对于iframe中的标签,如果直接查找是无法找到的,会抛出没有找到元素的异常。比如近在咫尺的例子就是,CSDN的登录窗体就是使用的iframe,大家可以尝试通过F12开发者模式查看到的tag_name,class_name,id或者xpath来定位中的页面元素,会抛出NoSuchElementException异常。解决
2022/8/4更新支持加入水印水印必须包含透明图像,并且水印图像大小要等于原图像的大小pythonconvert_image_to_video.py-f30-mwatermark.pngim_dirout.mkv2022/6/21更新让命令行参数更加易用新的命令行使用方法pythonconvert_image_to_video.py-f30im_dirout.mkvFFMPEG命令行转换一组JPG图像到视频时,是将这组图像视为MJPG流。我需要转换一组PNG图像到视频,FFMPEG就不认了。pyav内置了ffmpeg库,不需要系统带有ffmpeg工具因此我使用ffmpeg的python包装p