如今2023了,大多数javaweb架构都是springboot微服务,一个前端功能请求后台可能是多个不同的服务共同协做完成的。例如用户下单功能,js转发到后台网关gateway服务,然后到鉴权spring-sercurity服务,然后到业务订单服务,然后到支付服务,后续还有发货、客户标签等等服务。
其中每个服务会启动多个实例做负载均衡,这样一来我们想看这个功能的完成流程日志,需要找到对应的服务器ip,日志文件在哪,其中又要确定具体负载转发到哪些台服务器上了。 如果是生产问题想要快速定位原因,需要一套解决方案!
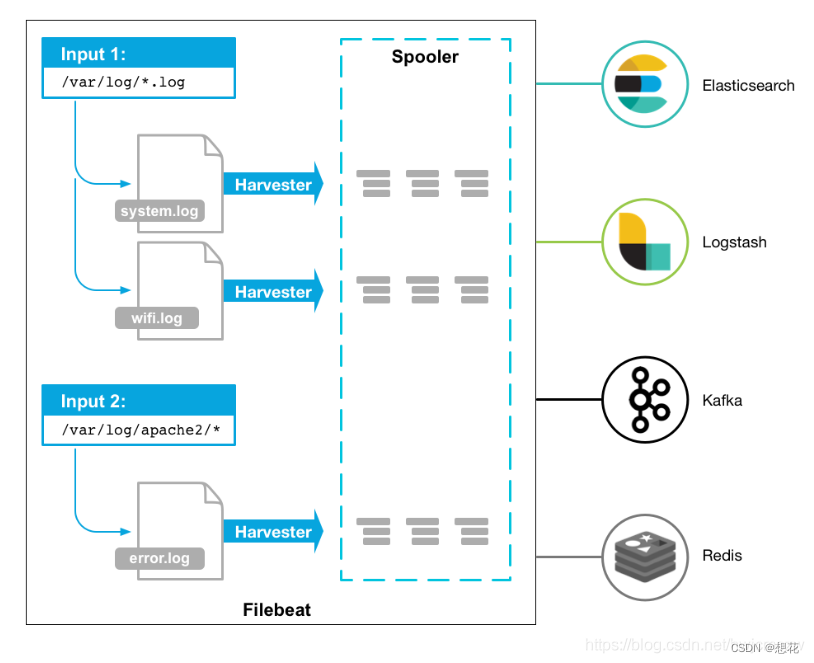
spring cloud(springBoot+服务发现+网关+负载熔断等netflex)。本人目前使用的是springboot+eureka+gateway+springSercurity+openfeign+springConfig 配合业务功能涉及中间件redis、quartz、kafka、mysql、elasticsearch
js发起ajax请求后台网关服务
网关服务集成了maven<artifactId>spring-cloud-starter-zipkin</artifactId>依赖,会自动给当前的请求header中添加tranceId字段和spanId字段。这两个字段值随机生成。其中tranceId等于spanId在header中没有这两个字段的时候:例如tranceId=123a,spanId=123a 并添加到header中。并且打印日志的时候会把这个信息打印出来
之后网关根据请求路径转发到业务服务A,A服务的zipkin发现header中有tranceId信息,就只生成spanId,例如tranceId=123a,spanId=231b 并添加到header中。并且打印日志的时候会把这个信息打印出来。
A服务又rpc调用了B服务。B服务的zipkin发现header中有tranceId信息,就只生成spanId,例如tranceId=123a,spanId=342h 并添加到header中。并且打印日志的时候会把这个信息打印出来。
调用完结返回前端响应。
到此服务器的日志文件就会新增上述的日志。然后filebeat工具监听到了各个服务的新日志,读取并推送到kafka
消息队列的topic下生产新数据,logstash工具提前配置并启动消费kafka, 处理并保存数据到elasticsearch。这里好奇为什么不直接通过filebeat直接推送es,或者springboot的log框架直接通过appender直接推送es呢?
持久化es之后,通过kibana查询日志,查询条件是tranceId=123a即可查询出完整的日志。
我分了两部分,有些是部署在服务器上的jar,我就通过filebeat采集;有些是部署到本地笔记本上的服务,直接在logback.xml配置一个appender输出到kafka,不经过filebeat。
input {
kafka{
bootstrap_servers => "node101:30701"
client_id => "logstash_kafka_consumer_id"
group_id => "logstash_kafka_consumer_group"
auto_offset_reset => "latest"
consumer_threads => 1
decorate_events => true
topics => ["logstash"]
}
}
filter{
}
output{
elasticsearch{
hosts => ["node101:30600"]
index => "logstash-%{+YYYY.MM.dd}"
}
}
filebeat.modules:
filebeat.prospectors:
- type: log
enabled: true
paths:
- /spring-boot-logs/*/user.*.log
#include_lines: ["^ERR", "^WARN"]
# 适用于日志中每一条日志占据多行的情况,比如各种语言的报错信息调用栈
multiline:
pattern: '^[[:space:]]'
negate: false
match: after
processors:
- drop_fields:
fields: ["metadata", "prospector", "offset", "beat", "source","type"]
output.kafka:
hosts: ["node101:30701"]
topic: logstash
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: elk
name: ssx-elk-dm
namespace: ssx
spec:
replicas: 1
selector: #标签选择器,与上面的标签共同作用
matchLabels: #选择包含标签app:mysql的资源
app: elk
template: #这是选择或创建的Pod的模板
metadata: #Pod的元数据
labels: #Pod的标签,上面的selector即选择包含标签app:mysql的Pod
app: elk
spec: #期望Pod实现的功能(即在pod中部署)
hostAliases: #给pod添加hosts网络
- ip: "192.168.0.101"
hostnames:
- "node101"
- ip: "192.168.0.102"
hostnames:
- "node102"
- ip: "192.168.0.103"
hostnames:
- "node103"
containers: #生成container,与docker中的container是同一种
- name: ssx-elasticsearch6-c
image: 9d77v/elasticsearch:6.2.4 #配置阿里的镜像,直接pull即可
ports:
- containerPort: 9200 # 开启本容器的80端口可访问
- containerPort: 9300 # 开启本容器的80端口可访问
env: #容器运行前需设置的环境变量列表
- name: discovery.type #环境变量名称
value: "single-node" #环境变量的值 这是mysqlroot的密码 因为是纯数字,需要添加双引号 不然编译报错
volumeMounts:
- mountPath: /usr/share/elasticsearch/data #这是mysql容器内保存数据的默认路径
name: c-v-path-elasticsearch-data
- mountPath: /usr/share/elasticsearch/logs #这是mysql容器内保存数据的默认路径
name: c-v-path-elasticsearch-logs
- mountPath: /usr/share/elasticsearch/.cache #这是mysql容器内保存数据的默认路径
name: c-v-path-elasticsearch-cache
- mountPath: /etc/localtime #时间同步
name: c-v-path-lt
- name: ssx-kibana-c
image: wangxiaopeng65/kibana:6.2.4 #配置阿里的镜像,直接pull即可
ports:
- containerPort: 5601 # 开启本容器的80端口可访问
env: #容器运行前需设置的环境变量列表
- name: ELASTICSEARCH_URL #环境变量名称
value: "http://localhost:9200" #环境变量的值 这是mysqlroot的密码 因为是纯数字,需要添加双引号 不然编译报错
volumeMounts:
- mountPath: /usr/share/kibana/data2 #无用,我先看看那些挂载需要
name: c-v-path-kibana
- mountPath: /etc/localtime #时间同步
name: c-v-path-lt
- name: ssx-logstash-c
image: docker.elastic.co/logstash/logstash:6.2.4 #配置阿里的镜像,直接pull即可
env: #容器运行前需设置的环境变量列表
- name: "xpack.monitoring.enabled" #禁用登录验证
value: "false" #环境变量的值 这是mysqlroot的密码 因为是纯数字,需要添加双引号 不然编译报错
args: ["-f","/myconf/logstash.conf"]
volumeMounts:
- mountPath: /myconf #配置
name: c-v-path-logstash-conf
- mountPath: /usr/share/logstash/data #data
name: c-v-path-logstash-data
- mountPath: /etc/localtime #时间同步
name: c-v-path-lt
- name: ssx-filebeat-c
image: elastic/filebeat:6.2.4 #配置阿里的镜像,直接pull即可
env: #容器运行前需设置的环境变量列表
volumeMounts:
- mountPath: /usr/share/filebeat/filebeat.yml #配置
name: c-v-path-filebeat-conf
- mountPath: /usr/share/filebeat/data #配置
name: c-v-path-filebeat-data
- mountPath: /spring-boot-logs #data
name: c-v-path-filebeat-spring-logs
- mountPath: /etc/localtime #时间同步
name: c-v-path-lt
volumes:
- name: c-v-path-elasticsearch-data #和上面保持一致 这是本地的文件路径,上面是容器内部的路径
hostPath:
path: /home/app/apps/k8s/for_docker_volume/elk/elasticsearch6/data #此路径需要实现创建 注意要给此路径授权777权限 不然pod访问不到
- name: c-v-path-elasticsearch-logs #和上面保持一致 这是本地的文件路径,上面是容器内部的路径
hostPath:
path: /home/app/apps/k8s/for_docker_volume/elk/elasticsearch6/logs #此路径需要实现创建 注意要给此路径授权777权限 不然pod访问不到
- name: c-v-path-elasticsearch-cache #和上面保持一致 这是本地的文件路径,上面是容器内部的路径
hostPath:
path: /home/app/apps/k8s/for_docker_volume/elk/elasticsearch6/.cache #此路径需要实现创建 注意要给此路径授权777权限 不然pod访问不到
- name: c-v-path-kibana #和上面保持一致 这是本地的文件路径,上面是容器内部的路径
hostPath:
path: /home/app/apps/k8s/for_docker_volume/elk/kibana #此路径需要实现创建 注意要给此路径授权777权限 不然pod访问不到
- name: c-v-path-logstash-conf
hostPath:
path: /home/app/apps/k8s/for_docker_volume/elk/logstash/myconf
- name: c-v-path-logstash-data
hostPath:
path: /home/app/apps/k8s/for_docker_volume/elk/logstash/data
- name: c-v-path-lt
hostPath:
path: /etc/localtime #时间同步
- name: c-v-path-filebeat-conf
hostPath:
path: /home/app/apps/k8s/for_docker_volume/elk/filebeat/myconf/filebeat.yml
- name: c-v-path-filebeat-data
hostPath:
path: /home/app/apps/k8s/for_docker_volume/elk/filebeat/data
- name: c-v-path-filebeat-spring-logs
hostPath:
path: /home/ssx/appdata/ssx-log/docker-log
nodeSelector: #把此pod部署到指定的node标签上
kubernetes.io/hostname: node101
---
apiVersion: v1
kind: Service
metadata:
labels:
app: elk
name: ssx-elk-sv
namespace: ssx
spec:
ports:
- port: 9000 #我暂时不理解,这个设置 明明没用到?
name: ssx-elk-last9200
protocol: TCP
targetPort: 9200 # 容器nginx对外开放的端口 上面的dm已经指定了
nodePort: 30600 #外网访问的端口
- port: 9010 #我暂时不理解,这个设置 明明没用到?
name: ssx-elk-last9300
protocol: TCP
targetPort: 9300 # 容器nginx对外开放的端口 上面的dm已经指定了
nodePort: 30601 #外网访问的端口
- port: 9011 #我暂时不理解,这个设置 明明没用到?
name: ssx-kibana
protocol: TCP
targetPort: 5601 # 容器nginx对外开放的端口 上面的dm已经指定了
nodePort: 30602 #外网访问的端口
selector:
app: elk
type: NodePort
我在app/helpers/sessions_helper.rb中有一个帮助程序文件,其中包含一个方法my_preference,它返回当前登录用户的首选项。我想在集成测试中访问该方法。例如,这样我就可以在测试中使用getuser_path(my_preference)。在其他帖子中,我读到这可以通过在测试文件中包含requiresessions_helper来实现,但我仍然收到错误NameError:undefinedlocalvariableormethod'my_preference'.我做错了什么?require'test_helper'require'sessions_hel
我一直很高兴地使用DelayedJob习惯用法:foo.send_later(:bar)这会调用DelayedJob进程中对象foo的方法bar。我一直在使用DaemonSpawn在我的服务器上启动DelayedJob进程。但是...如果foo抛出异常,Hoptoad不会捕获它。这是任何这些包中的错误...还是我需要更改某些配置...或者我是否需要在DS或DJ中插入一些异常处理来调用Hoptoad通知程序?回应下面的第一条评论。classDelayedJobWorker 最佳答案 尝试monkeypatchingDelayed::W
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
前置步骤我们都操作完了,这篇开始介绍jenkins的集成。话不多说,看操作1、登录进入jenkins后会让你选择安装插件,选择第一个默认的就行。安装完成后设置账号密码,重新登录。2、配置JDK和Git都需要执行路径,所以需要先把执行路径找到,先进入服务器的docker容器,2.1JDK的路径root@69eef9ee86cf:/usr/bin#echo$JAVA_HOME/usr/local/openjdk-82.2Git的路径root@69eef9ee86cf:/#whichgit/usr/bin/git3、先配置JDK和Git。点击:ManageJenkins>>GlobalToolCon
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
三分钟集成Tap防沉迷SDK(Unity版)一、SDK介绍基于国家对上线所有游戏必须增加防沉迷功能的政策下,TapTap推出防沉迷SDK,供游戏开发者进行接入;允许未成年用户在周五、六、日以及法定节假日晚上8:00-9:00进行游戏,防沉谜时间段进入游戏会弹窗进行提示!开发环境要求:Unity2019.4或更高版本iOS10或更高版本Android5.0(APIlevel21)或更高版本🔗Unity集成Demo参考链接🔗UnityTapSDK功能体验APK下载链接二、集成前准备1.创建应用进入开发者后台,按照提示开始创建应用;2.开通服务在使用TDS实名认证和防沉迷服务之前,需要在上面创建的应
目录SpringBootStarter是什么?以前传统的做法使用SpringBootStarter之后starter的理念:starter的实现: 创建SpringBootStarter步骤在idea新建一个starter项目、直接执行下一步即可生成项目。 在xml中加入如下配置文件:创建proterties类来保存配置信息创建业务类:创建AutoConfiguration测试如下:SpringBootStarter是什么? SpringBootStarter是在SpringBoot组件中被提出来的一种概念、简化了很多烦琐的配置、通过引入各种SpringBootStarter包可以快速搭建出一
我被这个难住了。到目前为止教程中的一切都进行得很顺利,但是当我将这段代码添加到我的/spec/requests/users_spec.rb文件中时,事情开始变得糟糕:describe"success"doit"shouldmakeanewuser"dolambdadovisitsignup_pathfill_in"Name",:with=>"ExampleUser"fill_in"Email",:with=>"ryan@example.com"fill_in"Password",:with=>"foobar"fill_in"Confirmation",:with=>"foobar"cl
我需要一些指导来了解如何将Angular整合到rails中。选择Rails的原因:我喜欢他们偏执的做事方式。还有迁移,gem真的很酷。使用angular的原因:我正在研究和寻找最适合SPA的框架。Backbone似乎太抽象了。我不得不在Angular和Ember之间做出选择。我首先开始阅读Angular,它对我来说很有意义。所以我从来没有去读过关于ember的文章。使用Angular和Rails的原因:我研究并尝试使用小型框架,例如grape、slim(是的,我也使用php)。但我觉得需要坚持项目的长期范围。我个人喜欢用Rails的方式做事。这就是我需要帮助的地方,我在Rails4中有
有没有人有在Maven中运行用Ruby编写的单元测试的经验。任何输入,如要使用的库/maven插件,将不胜感激!我们已经在使用Maven+hudson+Junit。但是我们正在引入Ruby单元测试,找不到任何同样好的组合。 最佳答案 我建议让Maven使用ExecMavenPlugin启动rake测试(exec:exec目标)并使用ci_reportergem生成单元测试结果的XML文件,Hudson、Bamboo等可以读取该文件,以与JUnit测试相同的格式显示测试结果。如果您不需要使用mvntest运行Ruby测试,您也可以只使