在获取视频时,有的网站是将完整的视频链接路径放在了 <vedio></vedio> 中,但是如果直接将如 mp4 文件放在网页中进行加载,如果视频由于时长、清晰度等原因致使过大,可能会导致视频加载速度很慢,所以现在大部分网站采用流媒体网络传输协议(HLS),将一个视频切成了很多个小段,这样只需要加载 m3u8 文件,根据 m3u8 里的索引进行播放,简而言之如果你拉动进度条到一个时间点,就会加载这个时间点前后的视频片段,速度就会快很多,不过对于视频的爬取也会复杂不少。
HLS 即 HTTP Live Streaming 是一个由苹果公司提出的基于 HTTP 的流媒体网络传输协议,他把整个流分成一个个小的基于 HTTP 的文件来下载,每次只下载一些,在开始一个流媒体会话时,客户端会下载一个包含元数据的 extended M3U playlist 文件,用于寻找可用的媒体流,m3u8 即编码格式为 UTF-8 的 M3U 文件。
HLS 协议规定视频的封装格式是 ts,所以 m3u8 文件中,是一个 ts 的列表,也就是告诉浏览器可以播放这些 ts 文件,所以将所有的 ts 文件合并起来就可以得到一个完整的 mp4 视频文件。
ffmpeg 是一套完备的多媒体支持库,它几乎实现了所有当下常见的数据封装格式、多媒体传输协议以及音视频编、解码器,这里通过他将所有的 ts 文件合并成 mp4 视频文件。
ffmpeg Github 官方下载地址:Releases · BtbN/FFmpeg-Builds · GitHub
我下载的是:ffmpeg-master-latest-win64-gpl.zip,下载之后解压即可,bin 目录以下会生成以下三个文件:

以下及安装成功:
视频网页链接:http://www.meijutt.org/fzls/yueyudiyiji/0-1.html

右键点击查看网页源代码,Ctrl + F 检索关键词 <vedio 或者 vedio 会发现检索不到,这里基本可以推测视频是由 m3u8 文件加载出来的,接着 F12 打开开发者人员工具,在 network 中点击 Fetch/XHR 查看网络请求,可以找到 m3u8 文件:

点击打开 m3u8 文件:

更多 m3u8 参数可参考:m3u8文件参数详解
视频直播与视频点播:视频直播和点播的主要区别
Ctrl + F 检索 m3u8 可以看到 m3u8 文件的路径,并发现其放在 iframe 中,即页面层级嵌套了两个子页面,我们需要的 m3u8 文件路径就放在第二个子页面中,我们需要获取 m3u8 文件的路径然后下载其中的 ts 文件并进行合并,但直接获取网页代码是抓取不到这些内容的,因为直接通过 requests 请求拿到的页面源代码是没经过渲染的,所以拿不到 iframe 里面的内容,这里采用 selenium 提取相关信息:
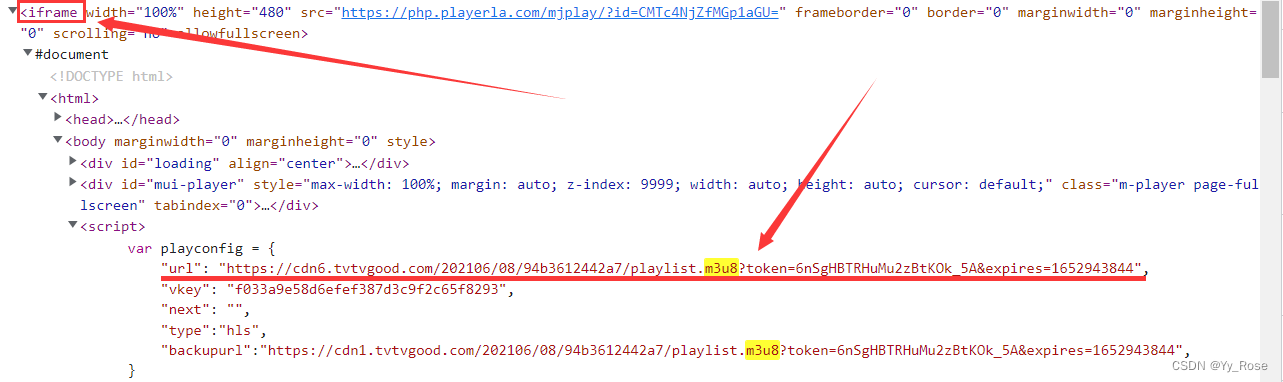
iframe 相关内容可参考:https://blog.csdn.net/Yy_Rose/article/details/121682665
所以基本流程就是:
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver import ChromeOptions
import time
# 浏览器配置
option = ChromeOptions()
option.add_argument("--headless") # 指定无头模式
driver = webdriver.Chrome(options=option)
driver.get(url)
# driver.implicitly_wait(10)
# 等待,避免网页数据没加载完全以至于获取不到
time.sleep(5)
iframe = driver.find_elements(By.TAG_NAME, "iframe")[1]
driver.switch_to.frame(iframe)
time.sleep(5)
# 获取 iframe 中内容
ifm_html = driver.page_source
检索 "url":,只匹配到一个数据,即可通过正则对此进行匹配:
re_url = re.compile(r'"url": "(.*?)"', re.S)
# 获取 m3u8 的地址链接
m3u8_url = re_url.findall(ifm_html)[0]
print(f"m3u8 的地址为:{m3u8_url}")通过获取到的 m3u8 地址,下载保存其中内容:
# 将 m3u8 写入文件
m3u8_file = requests.get(m3u8_url, headers=headers)
with open('越狱.m3u8', mode='wb') as f:
f.write(m3u8_file.content)
print("m3u8 文件下载完毕")
m3u8 文件中前面不带 # 的为 ts 文件路径,总共有 525 个 ts 文件,由于 ts 文件过多,同步一条条下载会导致速度过慢,这里采用异步下载:
async def download_ts(url, name, session):
async with session.get(url) as resp:
# 创建一个新文件夹 movie_ts 并设置为 excluded,下载过程将不占用 pycharm 缓存
async with aiofiles.open(f'movie_ts/{name}.ts', mode='wb') as file:
# 将下载到的内容写入到文件中
await file.write(await resp.content.read())
print(f"{name} 下载完毕")
async def download_movie():
tasks = []
# 从 m3u8 文件中获取每个 ts 文件的下载地址
async with aiohttp.ClientSession() as session:
async with aiofiles.open('越狱.m3u8', mode='r', encoding='utf-8') as f:
async for line in f:
# 去掉前面带 # 的非 ts 数据
if line.startswith('#'):
continue
# 去掉空格和换行
ts_url = line.strip()
# https://pic.url.cn/qqgameedu/0/d54180feb8f34f6f3eba5cebe6b66107_0/0
# 每个 ts 文件以 d54180feb8f34f6f3eba5cebe6b66107_ 命名
domain = "https://pic.url.cn/qqgameedu/0/"
name = ts_url.strip(domain)
# 创建异步任务
task = asyncio.create_task(download_ts(ts_url, name, session))
tasks.append(task)
# 等待任务结束
await asyncio.wait(tasks)
ffmpeg 可以将一个 mp4 格式的视频分解成 ts 文件,并生成一个 m3u8 文件:
ffmpeg -y -i movie.mp4 -vcodec copy -acodec copy -vbsf h264_mp4toannexb movie.ts
ffmpeg -i movie.ts -c copy -map 0 -f segment -segment_list movie.m3u8 -segment_time 5 test-%03d.ts
ffmpeg 可以分解 mp4 文件为一个个 ts 文件,自然也可以使用它将 ts 切片合并成一个完整的 mp4 文件:
将 ts 文件路径写入 txt 文档中,格式例如:
file G:/Python/m3u8/merge/1a0de66077eab0eea7aa9251a9deded4_.tswith open("越狱.m3u8", mode='r', encoding='utf-8') as f:
with open("file.txt", mode='w', encoding='utf-8') as file:
for line in f:
if line.startswith('#'):
continue
line_ts = line.strip()
domain = "https://pic.url.cn/qqgameedu/0/"
ts_name = line_ts.strip(domain)
# 更改路径
ts_path = f"file G:/Python/m3u8/merge/{ts_name}.ts"
file.write(ts_path + "\n")
file.close()
print("保存完毕!")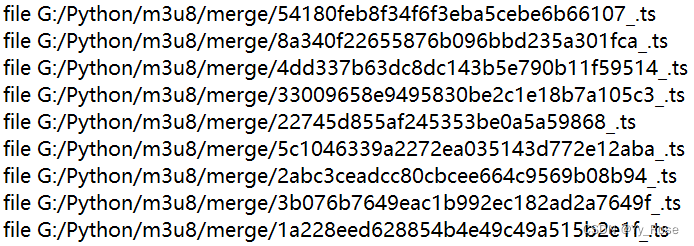
# -safe 0: 防止 Operation not permitted
ffmpeg -y -f concat -safe 0 -i file.txt -strict -2 prison.mp4
ffmpeg -y -f concat -safe 0 -i file.txt -c copy prison.mp4
# 网上还有不少拼接方法 [concat @ 000001935d022e80] Unsafe file name 'G:/XX/XX/XX/X.ts'
file.txt: Operation not permitted
解决办法:加上 -safe 0
[mp4 @ 0000022fe210adc0] Could not find tag for XXX in stream #0, codec not currently supported in container
Could not write header for output file #0 (incorrect codec parameters ?): Invalid argument
Error initializing output stream 0:0 --
解决办法:加上 -strict -2 或者 -acodec aac,表示 aac 音频编码
但我这里 XXX 处显示为 codec bmp,bmp 为位图(点阵图),证明视频被 ffmpeg 解析为了图片,ffmpeg 无法进行拼接,用以上解决方法可以拼接出 mp4 视频文件,但无法播放,所以可以看出 ts 文件后缀被批量修改为 bmp 了,这应该就是为什么将文件后缀改为 ts 可以播放视频,但是无法使用 ffmpeg 进行拼接的原因,文件路径用 Chrome 打开也显示为图片样式:
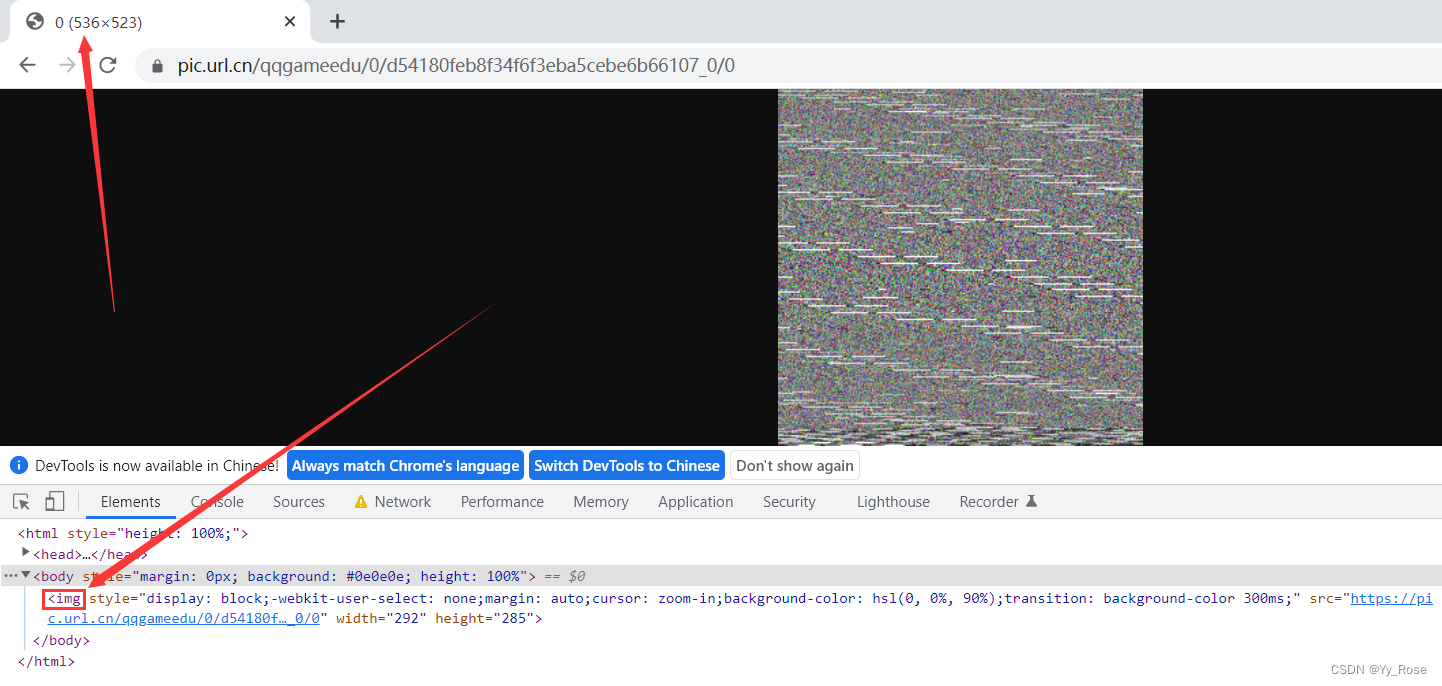
每个 0 即为 ts 片段,content-type:image/bmp,即证明观点,为 bmp(BitMap)格式图片文件:

BMP、PNG、JPG 格式图片的区别:BMP GIF PNG JPG等图片格式的区别和适用情况
二进制文件通过 Notepad++ 的 Hex-Editer 插件可以看到,42 4d 表示为 BM,正常的 ts 文件是以红圈位置为开头的:
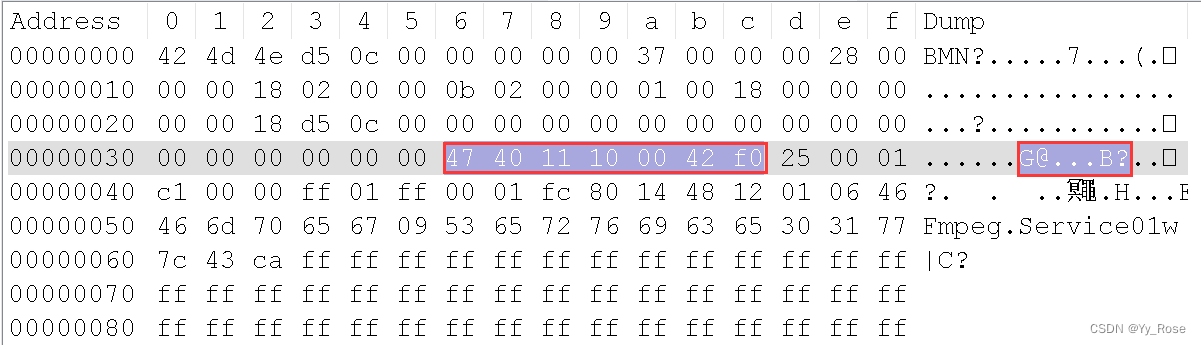
所以将其之前的 delete 后保存即可,或者只删掉 42 4d,再用以下命令即可成功将 ts 合成为 mp4 视频:
ffmpeg -y -f concat -safe 0 -i file.txt -c copy prison.mp4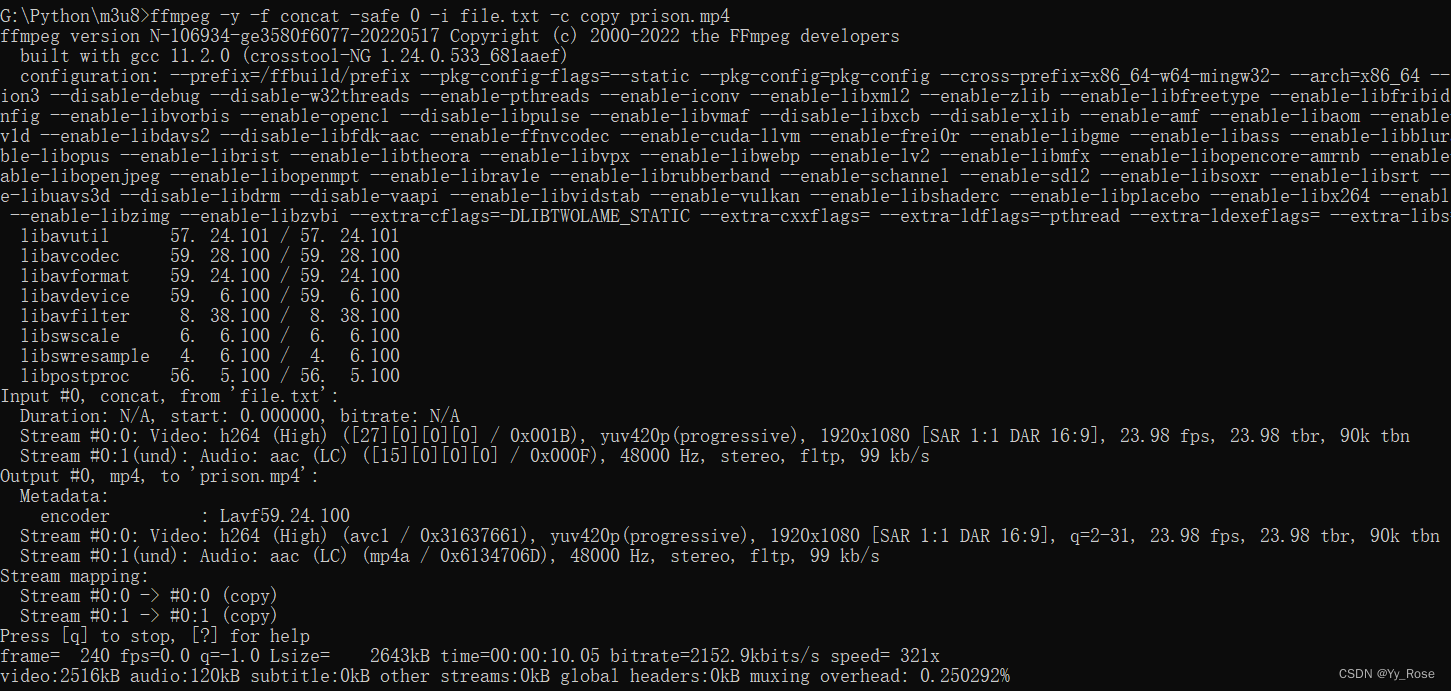
用了两个 ts 片段进行测试,没报错,合并成功,并且能够正常播放视频!!!
ffmpeg 使用可参考:https://blog.csdn.net/matthew0618band/article/details/9830681
以上是对 m3u8 视频文件获取的实战归纳总结,以及 ts 被混淆为图片的解决办法,PNG 格式图片与上述 BMP 格式图片处理方法基本一致,如有见解欢迎评论区或私信指正交流~
参考资料:
https://blog.csdn.net/davidullua/article/details/120562737
https://blog.csdn.net/weixin_43841155/article/details/122229315
https://blog.csdn.net/qq_33697094/article/details/112718101
本文主要介绍在使用Selenium进行自动化测试或者任务时,对于使用了iframe的页面,如何定位iframe中的元素文章目录场景描述解决方案具体代码场景描述当我们在使用Selenium进行自动化测试的时候,可能会遇到一些界面或者窗体是使用HTML的iframe标签进行承载的。对于iframe中的标签,如果直接查找是无法找到的,会抛出没有找到元素的异常。比如近在咫尺的例子就是,CSDN的登录窗体就是使用的iframe,大家可以尝试通过F12开发者模式查看到的tag_name,class_name,id或者xpath来定位中的页面元素,会抛出NoSuchElementException异常。解决
2022/8/4更新支持加入水印水印必须包含透明图像,并且水印图像大小要等于原图像的大小pythonconvert_image_to_video.py-f30-mwatermark.pngim_dirout.mkv2022/6/21更新让命令行参数更加易用新的命令行使用方法pythonconvert_image_to_video.py-f30im_dirout.mkvFFMPEG命令行转换一组JPG图像到视频时,是将这组图像视为MJPG流。我需要转换一组PNG图像到视频,FFMPEG就不认了。pyav内置了ffmpeg库,不需要系统带有ffmpeg工具因此我使用ffmpeg的python包装p
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption
我正在尝试使用以下代码通过将ffmpeg实用程序作为子进程运行并获取其输出并解析它来确定视频分辨率:IO.popen'ffmpeg-i'+path_to_filedo|ffmpegIO|#myparsegoeshereend...但是ffmpeg输出仍然连接到标准输出并且ffmepgIO.readlines是空的。ffmpeg实用程序是否需要一些特殊处理?或者还有其他方法可以获得ffmpeg输出吗?我在WinXP和FedoraLinux下测试了这段代码-结果是一样的。 最佳答案 要跟进mouviciel的评论,您需要使用类似pope
我将Cucumber与Ruby结合使用。通过Selenium-Webdriver在Chrome中运行测试时,我想将下载位置更改为测试文件夹而不是用户下载文件夹。我当前的chrome驱动程序是这样设置的:Capybara.default_driver=:seleniumCapybara.register_driver:seleniumdo|app|Capybara::Selenium::Driver.new(app,:browser=>:chrome,desired_capabilities:{'chromeOptions'=>{'args'=>%w{window-size=1920,1
Asitcurrentlystands,thisquestionisnotagoodfitforourQ&Aformat.Weexpectanswerstobesupportedbyfacts,references,orexpertise,butthisquestionwilllikelysolicitdebate,arguments,polling,orextendeddiscussion.Ifyoufeelthatthisquestioncanbeimprovedandpossiblyreopened,visitthehelpcenter提供指导。9年前关闭。我打算学习Seleni
我一直在工作中使用seleniumIDE。现在我们决定将Seleniumwebdriver与Ruby结合使用。我完全不知道如何设置我的Mac,MacProYosemite10.10.5。在我的终端中,我运行了这些命令:$ruby-e"$(curl-fsSLhttps://raw.githubusercontent.com/Homebrew/install/master/install)"$brewdoctorYoursystemisreadytobrew.$brewinstallruby==>Summary/usr/local/Cellar/openssl/1.0.2d_1:464fi
我正在尝试使用ruby脚本进行一些headless测试。本质上,我在显示器:1上执行Xvfb,然后使用watir-webdriver启动Watir::Browser.new(:firefox)。如果您以root身份运行脚本,效果会很好-我可以运行x11vnc并观察脚本执行浏览器并与之交互。问题是,我需要能够从Rails应用程序调用这个ruby脚本,而不是以root身份运行它...如果我尝试以普通用户身份从命令行运行脚本,Xvfb会启动on:1像往常一样,但Watir不会启动浏览器......它最终会在60秒后超时。通过VNC连接会显示带有鼠标光标的黑屏。我可以从命令行完成所有操
出于某种原因,我必须为Firefox禁用javascript(手动,我们按照提到的步骤执行http://support.mozilla.org/en-US/kb/javascript-settings-for-interactive-web-pages#w_enabling-and-disabling-javascript)。使用Ruby的SeleniumWebDriver如何实现这一点? 最佳答案 是的,这是可能的。而是另一种方式。您首先需要查看链接Selenium::WebDriver::Firefox::Profile#[]=
我正在尝试使用Ruby中的SeleniumWebDriver2.4模拟鼠标移动如果我运行测试,是否应该看到鼠标在我的屏幕上移动?我很困惑。我试过很多不同的方法示例代码:require'selenium-webdriver'driver=Selenium::WebDriver.for:firefoxdriver.navigate.to'http://www.google.com'element=driver.find_element(:id,'gbqfba')那我试过了driver.action.move_to(element).performdriver.mouse.move_to(e