ChatGPT, GPT-3, GPT-3.5, GPT-4, LLaMA, Bard等大型语言模型的一个重要的超参数

大型语言模型能够根据给定的上下文或提示生成新文本,由于神经网络等深度学习技术的进步,这些模型越来越受欢迎。可用于控制生成语言模型行为的关键参数之一是Temperature 参数。在本文中,我们将讨论语言生成模型中Temperature 参数的作用,以及它如何影响生成文本的质量。
Temperature 是一个超参数,可用于控制生成语言模型中生成文本的随机性和创造性。它用于调整模型的softmax输出层中预测词的概率。温度参数定义为在应用 softmax 函数之前用于调整 logits 的比例因子的倒数。
当Temperature 设置为较低的值时,预测词的概率会变尖锐,这意味着选择最有可能的词的概率更高。这会产生更保守和可预测的文本,因为模型不太可能生成意想不到或不寻常的词。另一方面,当Temperature 设置为较高值时,预测词的概率被拉平,这意味着所有词被选择的可能性更大。这会产生更有创意和多样化的文本,因为模型更有可能生成不寻常或意想不到的词。
温度参数通常设置为 0.1 到 1.0 之间的值,具体取决于生成文本中所需的随机性和创造性水平。温度值为 1.0 对应于标准 softmax 函数,其中预测词的概率未按比例缩放。

一般来说,Temperature 越低,GPT-3越有可能选择出现概率较高的单词。当我们想要GPT-3解释概念时,它特别有用,因为答案只有一个。如果想要产生想法或完成一个故事,Temperature 设置的更大会给我们带来更多的多样性。
比如说以下提示:
Prompt: “The quick brown fox”
Temperature = 0.1:
“The quick brown fox jumped over the lazy dog. The quick brown fox jumped over the lazy dog. The quick brown fox jumped over the lazy dog.”
Temperature = 0.5:
“The quick brown fox jumped over the lazy dog. The lazy cat was not impressed. The quick brown fox ran away.”
Temperature = 1.0:
“The quick brown fox jumped over the lazy dog. Suddenly, a flock of birds flew overhead, causing the fox to stop in its tracks. It looked up at the sky, wondering where they were going.”
可以看到,Temperature 对生成文本的质量和创造性有重大影响。低值生成更可预测和重复的文本,而高值生成更多样化和创造性的文本。
神经网络的输出是词汇表中每个单词(实际上是标记)的概率分布,告诉它这些单词中任何一个可能跟随输入文本的可能性。
该概率分布由softmax函数计算:
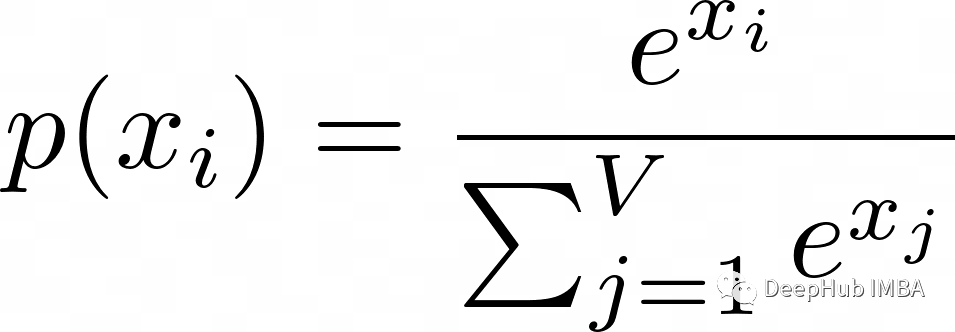
如果将Temperature 参数(T)添加到softmax函数,则公式如下:
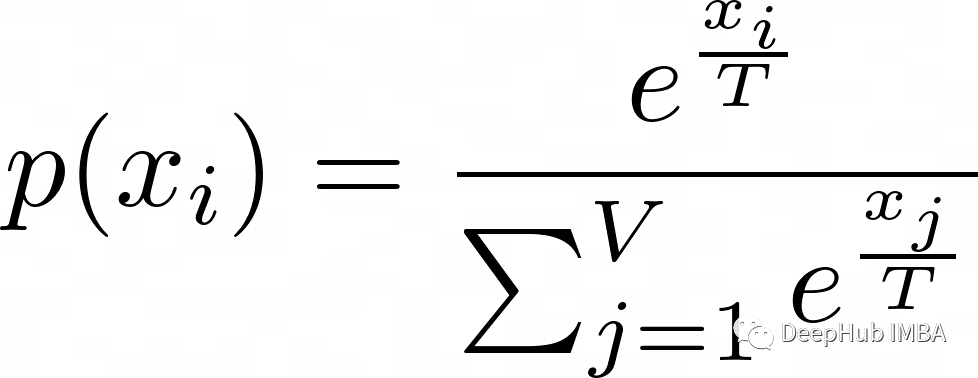
更深入的解释Temperature 参数:
如果当T趋于无穷时会发生什么。每个x_i / T都会趋于0,从而得到一个均匀分布。也就是说概率分布变得更 “平”, 这会导致结果更随机。
当T很小(比如0.1)时会发生什么。每个x_i / T之间的差异变得更加明显(例如5比1变成50比10),这样概率分布变得“更尖”,也就是说结果会更确定。
Temperature 参数是语言生成模型中一个重要的超参数,可用于控制生成文本的随机性和创造性。通过调整该参数,可以生成更保守或更有创意的文本,虽然Temperature 参数是生成高质量文本的强大工具,但需要注意的是,它并不能提高生成语言模型的性能。因为生成文本的质量高度依赖于训练数据的质量、模型的架构以及其他超参数,如学习率和批处理大小。在设计和训练生成语言模型时,必须考虑所有这些因素。
另外就是Temperature 参数可能并不总是提高生成文本的质量,特别是在训练数据有限或有噪声的情况下。在这种情况下,其他技术,如数据增强、正则化或迁移学习可能更有效地提高模型的性能。
最后Temperature 可以控制语言生成模型的行为。通过适当的调整,可以得到我们期望的结果。比如说生成更确定的答案可以降低该值,而生成更发散和创造性的答案可以提高该值,所以尝试一下不同的值,看看这些更改对不的提示有什么影响,这会帮助我们更好的获得想要的结果。
https://avoid.overfit.cn/post/04f2376489184f53a6ae9c5d4b43dc97
作者:Lazy Programmer
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
为什么4.1%2返回0.0999999999999996?但是4.2%2==0.2。 最佳答案 参见此处:WhatEveryProgrammerShouldKnowAboutFloating-PointArithmetic实数是无限的。计算机使用的位数有限(今天是32位、64位)。因此计算机进行的浮点运算不能代表所有的实数。0.1是这些数字之一。请注意,这不是与Ruby相关的问题,而是与所有编程语言相关的问题,因为它来自计算机表示实数的方式。 关于ruby-为什么4.1%2使用Ruby返