Bert+BiLSTM做情感分析
情感分析一类的任务比如商品评价正负面分析,敏感内容分析,用户感兴趣内容分析、甚至安全领域的异常访问日志分析等等实际上都可以用文本分类的方式去做,情感分析的问题本质是个二分类或者多分类的问题。
BERT的全称为Bidirectional Encoder Representation from Transformers,是一个预训练的语言表征模型。它强调了不再像以往一样采用传统的单向语言模型或者把两个单向语言模型进行浅层拼接的方法进行预训练,而是采用新的masked language model(MLM),以致能生成深度的双向语言表征。
该模型有以下主要优点:
1)采用MLM对双向的Transformers进行预训练,以生成深层的双向语言表征。
2)预训练后,只需要添加一个额外的输出层进行fine-tune,就可以在各种各样的下游任务中取得state-of-the-art的表现。在这过程中并不需要对BERT进行任务特定的结构修改。
今天我们使用Bert+BiLSTM实现对菜品正负评价的情感分析预测!
数据集是我们搜集了一些菜品的正负评价,正面的评价标记为1,负面评价标记为0,将其保存为csv文件。

将数据集放在工程的根目录
下载地址:https://huggingface.co/bert-base-chinese/tree/main。
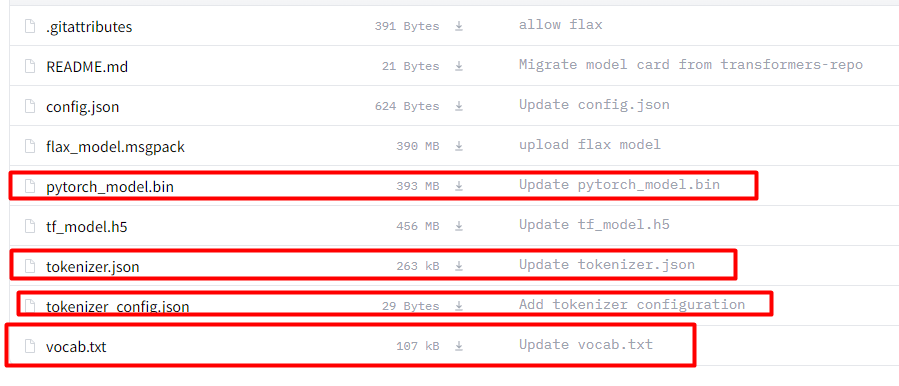
我们的数据集是中文,所以,选择中文的预训练模型,这点要注意,如果选择其他的可能会出现不收敛的情况。将下图中画红框的文件加载下来。
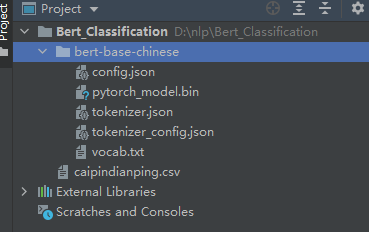
在工程的根目录,新建文件夹“bert_base_chinese”,将下载的模型放进去,如下图:
思路:将bert做为嵌入层提取特征,然后传入BiLSTM,最后使用全连接层输出分类。创建bert_lstm模型,代码如下:
class bert_lstm(nn.Module):
def __init__(self, bertpath, hidden_dim, output_size,n_layers,bidirectional=True, drop_prob=0.5):
super(bert_lstm, self).__init__()
self.output_size = output_size
self.n_layers = n_layers
self.hidden_dim = hidden_dim
self.bidirectional = bidirectional
#Bert ----------------重点,bert模型需要嵌入到自定义模型里面
self.bert=BertModel.from_pretrained(bertpath)
for param in self.bert.parameters():
param.requires_grad = True
# LSTM layers
self.lstm = nn.LSTM(768, hidden_dim, n_layers, batch_first=True,bidirectional=bidirectional)
# dropout layer
self.dropout = nn.Dropout(drop_prob)
# linear and sigmoid layers
if bidirectional:
self.fc = nn.Linear(hidden_dim*2, output_size)
else:
self.fc = nn.Linear(hidden_dim, output_size)
#self.sig = nn.Sigmoid()
def forward(self, x, hidden):
batch_size = x.size(0)
#生成bert字向量
x=self.bert(x)[0] #bert 字向量
# lstm_out
#x = x.float()
lstm_out, (hidden_last,cn_last) = self.lstm(x, hidden)
#print(lstm_out.shape) #[32,100,768]
#print(hidden_last.shape) #[4, 32, 384]
#print(cn_last.shape) #[4, 32, 384]
#修改 双向的需要单独处理
if self.bidirectional:
#正向最后一层,最后一个时刻
hidden_last_L=hidden_last[-2]
#print(hidden_last_L.shape) #[32, 384]
#反向最后一层,最后一个时刻
hidden_last_R=hidden_last[-1]
#print(hidden_last_R.shape) #[32, 384]
#进行拼接
hidden_last_out=torch.cat([hidden_last_L,hidden_last_R],dim=-1)
#print(hidden_last_out.shape,'hidden_last_out') #[32, 768]
else:
hidden_last_out=hidden_last[-1] #[32, 384]
# dropout and fully-connected layer
out = self.dropout(hidden_last_out)
#print(out.shape) #[32,768]
out = self.fc(out)
return out
def init_hidden(self, batch_size):
weight = next(self.parameters()).data
number = 1
if self.bidirectional:
number = 2
if (USE_CUDA):
hidden = (weight.new(self.n_layers*number, batch_size, self.hidden_dim).zero_().float().cuda(),
weight.new(self.n_layers*number, batch_size, self.hidden_dim).zero_().float().cuda()
)
else:
hidden = (weight.new(self.n_layers*number, batch_size, self.hidden_dim).zero_().float(),
weight.new(self.n_layers*number, batch_size, self.hidden_dim).zero_().float()
)
return hidden
bert_lstm需要的参数功6个,参数说明如下:
–bertpath:bert预训练模型的路径
–hidden_dim:隐藏层的数量。
–output_size:分类的个数。
–n_layers:lstm的层数
–bidirectional:是否是双向lstm
–drop_prob:dropout的参数
定义bert的参数,如下:
class ModelConfig:
batch_size = 2
output_size = 2
hidden_dim = 384 #768/2
n_layers = 2
lr = 2e-5
bidirectional = True #这里为True,为双向LSTM
# training params
epochs = 10
# batch_size=50
print_every = 10
clip=5 # gradient clipping
use_cuda = USE_CUDA
bert_path = 'bert-base-chinese' #预训练bert路径
save_path = 'bert_bilstm.pth' #模型保存路径
batch_size:batchsize的大小,根据显存设置。
output_size:输出的类别个数,本例是2.
hidden_dim:隐藏层的数量。
n_layers:lstm的层数。
bidirectional:是否双向
print_every:输出的间隔。
use_cuda:是否使用cuda,默认使用,不用cuda太慢了。
bert_path:预训练模型存放的文件夹。
save_path:模型保存的路径。
需要下载transformers和sentencepiece,执行命令:
conda install sentencepiece
conda install transformers
数据集按照7:3,切分为训练集和测试集,然后又将测试集按照1:1切分为验证集和测试集。
代码如下:
model_config = ModelConfig()
data=pd.read_csv('caipindianping.csv',encoding='utf-8')
result_comments = pretreatment(list(data['comment'].values))
tokenizer = BertTokenizer.from_pretrained(model_config.bert_path)
result_comments_id = tokenizer(result_comments,
padding=True,
truncation=True,
max_length=200,
return_tensors='pt')
X = result_comments_id['input_ids']
y = torch.from_numpy(data['sentiment'].values).float()
X_train,X_test, y_train, y_test = train_test_split( X,
y,
test_size=0.3,
shuffle=True,
stratify=y,
random_state=0)
X_valid,X_test,y_valid,y_test = train_test_split(X_test,
y_test,
test_size=0.5,
shuffle=True,
stratify=y_test,
random_state=0)
训练详见train_model函数,验证详见test_model,单次预测详见predict函数。
代码和模型链接:
https://download.csdn.net/download/hhhhhhhhhhwwwwwwwwww/36305682
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
目录0专栏介绍1平面2R机器人概述2运动学建模2.1正运动学模型2.2逆运动学模型2.3机器人运动学仿真3动力学建模3.1计算动能3.2势能计算与动力学方程3.3动力学仿真0专栏介绍?附C++/Python/Matlab全套代码?课程设计、毕业设计、创新竞赛必备!详细介绍全局规划(图搜索、采样法、智能算法等);局部规划(DWA、APF等);曲线优化(贝塞尔曲线、B样条曲线等)。?详情:图解自动驾驶中的运动规划(MotionPlanning),附几十种规划算法1平面2R机器人概述如图1所示为本文的研究本体——平面2R机器人。对参数进行如下定义:机器人广义坐标
网站的日志分析,是seo优化不可忽视的一门功课,但网站越大,每天产生的日志就越大,大站一天都可以产生几个G的网站日志,如果光靠肉眼去分析,那可能看到猴年马月都看不完,因此借助网站日志分析工具去分析网站日志,那将会使网站日志分析工作变得更简单。下面推荐两款网站日志分析软件。第一款:逆火网站日志分析器逆火网站日志分析器是一款功能全面的网站服务器日志分析软件。通过分析网站的日志文件,不仅能够精准的知道网站的访问量、网站的访问来源,网站的广告点击,访客的地区统计,搜索引擎关键字查询等,还能够一次性分析多个网站的日志文件,让你轻松管理网站。逆火网站日志分析器下载地址:https://pan.baidu.
一、机器人介绍 此处是基于MATLABRVC工具箱,对ABB-IRB-1200型号的微型机械臂进行正逆向运动学分析,并利Simulink工具实现对机械臂进行具有动力学参数的末端轨迹规划仿真,最后根据机械模型设计Simulink-Adams联合仿真。 图1.ABBIRB 1200尺寸参数示意图ABBIRB 1200提供的两种型号广泛适用于各作业,且两者间零部件通用,两种型号的工作范围分别为700 mm 和 900 mm,大有效负载分别为 7 kg 和5 kg。 IRB 1200 能够在狭小空间内能发挥其工作范围与性能优势,具有全新的设计、小型化的体积、高效的性能、易于集成、便捷的接
目录一.大致如下常见问题:(1)找不到程序所依赖的Qt库version`Qt_5'notfound(requiredby(2)CouldnotLoadtheQtplatformplugin"xcb"in""eventhoughitwasfound(3)打包到在不同的linux系统下,或者打包到高版本的相同系统下,运行程序时,直接提示段错误即segmentationfault,或者Illegalinstruction(coredumped)非法指令(4)ldd应用程序或者库,查看运行所依赖的库时,直接报段错误二.问题逐个分析,得出解决方法:(1)找不到程序所依赖的Qt库version`Qt_5'
我想使用ruby-prof和JMeter分析Rails应用程序。我对分析特定Controller/操作/或模型方法的建议方法不感兴趣,我想分析完整堆栈,从上到下。所以我运行这样的东西:RAILS_ENV=productionruby-prof-fprof.outscript/server>/dev/null然后我在上面运行我的JMeter测试计划。然而,问题是使用CTRL+C或SIGKILL中断它也会在ruby-prof可以写入任何输出之前杀死它。如何在不中断ruby-prof的情况下停止mongrel服务器? 最佳答案
文章目录认识unity打包目录结构游戏逆向流程Unity游戏攻击面可被攻击原因mono的打包建议方案锁血飞天无限金币攻击力翻倍以上统称内存挂透视自瞄压枪瞬移内购破解Unity游戏防御开发时注意数据安全接入第三方反作弊系统外挂检测思路狠人自爆实战查看目录结构用il2cppdumper例子2-森林whoishe后记认识unity打包目录结构dll一般很大,因为里面是所有的游戏功能编译成的二进制码游戏逆向流程开发人员代码被编译打包到GameAssembly.dll中使用il2ppDumper工具,并借助游戏名_Data\il2cpp_data\Metadata\global-metadata.dat
最近在工作中,看到一些新手测试同学,对接口测试存在很多疑问,甚至包括一些从事软件测试3,5年的同学,在聊到接口时,也是一知半解;今天借着这个机会,对接口测试做个实战教学,顺便总结一下经验,分享给大家。计划拆分成4个模块跟大家做一个分享,(接口测试、接口基础知识、接口自动化、接口进阶)感兴趣的小伙伴记得关注,希望对你的日常工作和求职面试,带来一些帮助。注:文章较长有5000多字,希望小伙伴们认真看完,当然有些内容对小白同学不是太友好,如果你需要详细了解其中的一些概念或者名词,请在文章之后留言,后续我将针对大家的疑问,整理输出一些大家感兴趣的文章。随着开发模式的迭代更新,前后端分离已不是新的概念,
在笔者前面有一篇文章《驱动开发:断链隐藏驱动程序自身》通过摘除驱动的链表实现了断链隐藏自身的目的,但此方法恢复时会触发PG会蓝屏,偶然间在网上找到了一个作者介绍的一种方法,觉得有必要详细分析一下他是如何实现的进程隐藏的,总体来说作者的思路是最终寻找到MiProcessLoaderEntry的入口地址,该函数的作用是将驱动信息加入链表和移除链表,运用这个函数即可动态处理驱动的添加和移除问题。MiProcessLoaderEntry(pDriverObject->DriverSection,1)添加MiProcessLoaderEntry(pDriverObject->DriverSection,
目录1. 研究范围定义2. 流程中台市场分析3. 厂商评估:微宏科技4. 入选证书 1. 研究范围定义近年来,随着外部市场环境快速变化、客户需求愈发多样,企业逐渐意识到,自身业务需要更加敏捷、高效,具备根据市场需求快速迭代的能力。业务流程的自动化能够帮助企业实现业务的敏捷高效,因此受到越来越多企业的关注。企业的“自动化武器库”品类丰富,包括低/零代码平台、RPA、BPM、AI等。企业可以使用多项自动化工具,但结果往往是各项自动化工具处于各自的“自动化烟囱”之中,仅能实现碎片式自动化。例如,某企业的IT团队可能在使用低代码平台、财务团队可能在使用RPA、呼叫中心则可能在使用聊天机器人。自动