文章目录
什么是多环境?其实就是说你的电脑上写的程序最终要放到别人的服务器上去运行。每个计算机环境不一样,这就是多环境。常见的多环境开发主要兼顾3种环境设置,开发环境——自己用的,测试环境——自己公司用的,生产环境——甲方爸爸用的。因为这是绝对不同的三台电脑,所以环境肯定有所不同,比如连接的数据库不一样,设置的访问端口不一样等等。

那什么是多环境开发?就是针对不同的环境设置不同的配置属性即可。比如你自己开发时,配置你的端口如下:
server:
port: 80
如何想设计两组环境呢?中间使用三个减号分隔开
server:
port: 80
---
server:
port: 81
如何区分两种环境呢?起名字呗
spring:
profiles: pro
server:
port: 80
---
spring:
profiles: dev
server:
port: 81
那用哪一个呢?设置默认启动哪个就可以了
spring:
profiles:
active: pro # 启动pro
---
spring:
profiles: pro
server:
port: 80
---
spring:
profiles: dev
server:
port: 81
就这么简单,再多来一组环境也OK
spring:
profiles:
active: pro # 启动pro
---
spring:
profiles: pro
server:
port: 80
---
spring:
profiles: dev
server:
port: 81
---
spring:
profiles: test
server:
port: 82
其中关于环境名称定义上述格式是过时格式,标准格式如下
spring:
config:
activate:
on-profile: pro
总结
将所有的配置都放在一个配置文件中,尤其是每一个配置应用场景都不一样,这显然不合理,于是就有了将一个配置文件拆分成多个配置文件的想法。拆分后,每个配置文件中写自己的配置,主配置文件中写清楚用哪一个配置文件就好了。
主配置文件
spring:
profiles:
active: pro # 启动pro
环境配置文件
server:
port: 80
环境配置文件因为每一个都是配置自己的项,所以连名字都不用写里面了。那问题是如何区分这是哪一组配置呢?使用文件名区分。
application-pro.yaml
server:
port: 80
application-dev.yaml
server:
port: 81
文件的命名规则为:application-环境名.yml
上图中的application.yml就是我们说的主配置文件,其他的都是环境配置文件。
在配置文件中,如果某些配置项所有环境都一样,可以将这些项写入到主配置中,只有哪些有区别的项才写入到环境配置文件中。
总结
可以使用独立配置文件定义环境属性
独立配置文件便于线上系统维护更新并保障系统安全性
SpringBoot最早期提供的配置文件格式是properties格式的,这种格式的多环境配置也可以了解一下。
主配置文件
spring.profiles.active=pro
环境配置文件
application-pro.properties
server.port=80
application-dev.properties
server.port=81
文件的命名规则为:application-环境名.properties
总结
properties文件多环境配置仅支持多文件格式 作为程序员在搞配置的时候往往处于一种分久必合合久必分的局面。开始先写一起,后来为了方便维护就拆分。对于多环境开发也是如此,下面给大家说一下如何基于多环境开发做配置独立管理,务必掌握。
准备工作
将所有的配置根据功能对配置文件中的信息进行拆分,并制作成独立的配置文件,命名规则如下
使用
使用include属性在激活指定环境的情况下,同时对多个环境进行加载使其生效,多个环境间使用逗号分隔
spring:
profiles:
active: dev
include: devDB,devRedis,devMVC
比较一下,现在相当于加载dev配置时,再加载对应的3组配置,从结构上就很清晰,用了什么,对应的名称是什么
注意
当主环境dev与其他环境有相同属性时,主环境属性生效;其他环境中有相同属性时,最后加载的环境属性生效
改良
但是上面的设置也有一个问题,比如我要切换dev环境为pro时,include也要修改。因为include属性只能使用一次,这就比较麻烦了。SpringBoot从2.4版开始使用group属性替代include属性,降低了配置书写量。简单说就是我先写好,你爱用哪个用哪个。
spring:
profiles:
active: dev
group:
"dev": devDB,devRedis,devMVC
"pro": proDB,proRedis,proMVC
"test": testDB,testRedis,testMVC
现在再来看,如果切换dev到pro,只需要改一下是不是就结束了?完美!
总结
最后说一个冲突问题。就是maven和SpringBoot同时设置多环境的话怎么搞。
要想处理这个冲突问题,你要先理清一个关系,究竟谁在多环境开发中其主导地位。也就是说如果现在都设置了多环境,谁的应该是保留下来的,另一个应该遵从相同的设置。
maven是做什么的?项目构建管理的,最终生成代码包的,SpringBoot是干什么的?简化开发的。简化,又不是其主导作用。最终还是要靠maven来管理整个工程,所以SpringBoot应该听maven的。整个确认后下面就好做了。大体思想如下:
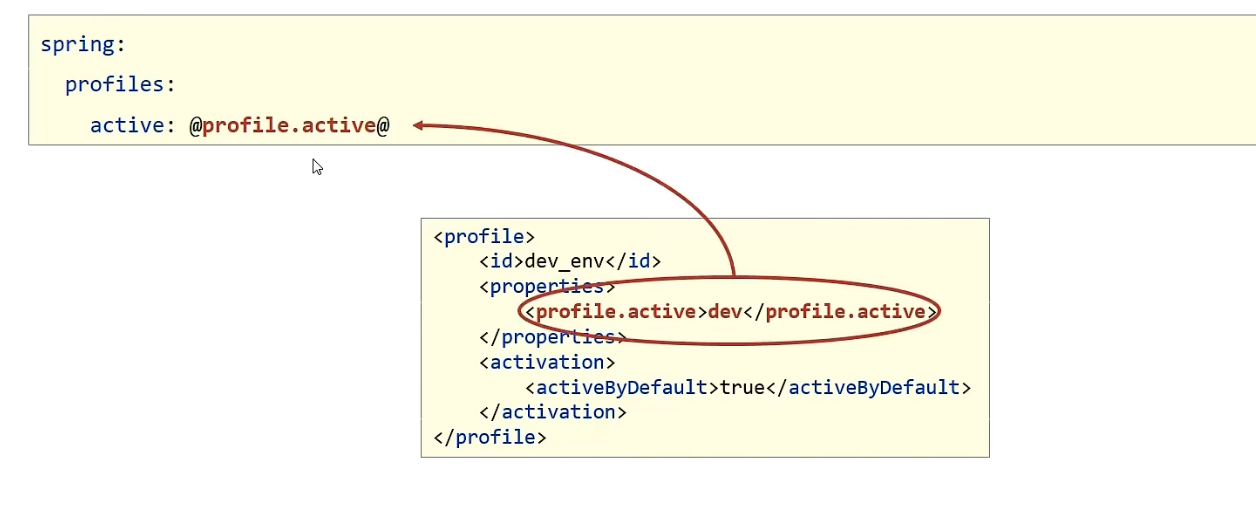
maven中设置多环境(使用属性方式区分环境)
<profiles>
<profile>
<id>env_dev</id>
<properties>
<profile.active>dev</profile.active>
</properties>
<activation>
<activeByDefault>true</activeByDefault> <!--默认启动环境-->
</activation>
</profile>
<profile>
<id>env_pro</id>
<properties>
<profile.active>pro</profile.active>
</properties>
</profile>
</profiles>
SpringBoot中读取maven设置值
spring:
profiles:
active: @profile.active@
上面的@属性名@就是读取maven中配置的属性值的语法格式。
总结
日志其实就是记录程序日常运行的信息,主要作用如下:
日志的使用格式非常固定,直接上操作步骤:
步骤①:添加日志记录操作
@RestController
@RequestMapping("/books")
public class BookController extends BaseClass{
private static final Logger log = LoggerFactory.getLogger(BookController.class);
@GetMapping
public String getById(){
log.debug("debug...");
log.info("info...");
log.warn("warn...");
log.error("error...");
return "springboot is running...2";
}
}
上述代码中log对象就是用来记录日志的对象,下面的log.debug,log.info这些操作就是写日志的API了。
结果:

默认的我们的系统在启动起来的时候,日志级别是info级别,所以这里我们只能看到info以及其上的日志信息
步骤②:设置日志输出级别
日志设置好以后可以根据设置选择哪些参与记录。这里是根据日志的级别来设置的。日志的级别分为6种,分别是:
一般情况下,开发时候使用DEBUG,上线后使用INFO,运维信息记录使用WARN即可。下面就设置一下日志级别:
# 开启debug模式,输出调试信息,常用于检查系统运行状况
debug: true
在开启了debug模式之后我们在开启项目的时候会有大篇幅的文字,这个模式我们一般在项目上线之后的检测才会使用到。
这么设置太简单粗暴了,日志系统通常都提供了细粒度的控制
# 开启debug模式,输出调试信息,常用于检查系统运行状况
debug: true
# 设置日志级别,root表示根节点,即整体应用日志级别
logging:
level:
root: debug
我们设置成debug级别之后,再运行就可以看到:
还可以再设置更细粒度的控制(例如我们不想看框架里面的debug日志)
步骤③:设置日志组,控制指定包对应的日志输出级别,也可以直接控制指定包对应的日志输出级别
logging:
# 设置日志组
group:
# 自定义组名,设置当前组中所包含的包
ebank: com.nefu.controller,com.nefu.service
level:
root: warn
# 为对应组设置日志级别
ebank: debug
# 为对包设置日志级别
com.nefu.controller: debug
说白了就是总体设置一下,每个包设置一下,如果感觉设置的麻烦,就先把包分个组,对组设置。
总结
写代码的时候每个类都要写创建日志记录对象,这个可以优化一下,使用前面用过的lombok技术给我们提供的工具类即可。
@RestController
@RequestMapping("/books")
public class BookController extends BaseClass{
private static final Logger log = LoggerFactory.getLogger(BookController.class); //这一句可以不写了
}
导入lombok后使用注解搞定,日志对象名为log
@Slf4j //这个注解替代了下面那一行
@RestController
@RequestMapping("/books")
public class BookController extends BaseClass{
private static final Logger log = LoggerFactory.getLogger(BookController.class); //这一句可以不写了
}
日志已经能够记录了,但是目前记录的格式是SpringBoot给我们提供的,如果想自定义控制就需要自己设置了。先分析一下当前日志的记录格式。

对于单条日志信息来说,日期,触发位置,记录信息是最核心的信息。级别用于做筛选过滤,PID与线程名用于做精准分析。了解这些信息后就可以DIY日志格式了。
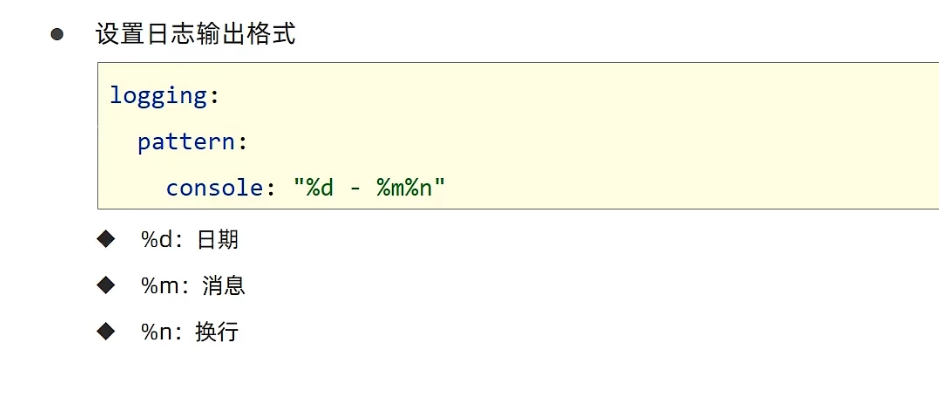
模拟的官方日志模板的书写格式:
logging:
pattern:
console: "%d %clr(%p) --- [%16t] %clr(%-40.40c){cyan} : %m %n"
日志信息显示,记录已经控制住了,下面就要说一下日志的转存了。日志不能仅显示在控制台上,要把日志记录到文件中,方便后期维护查阅。
对于日志文件的使用存在各种各样的策略,例如每日记录,分类记录,报警后记录等。这里主要研究日志文件如何记录。
记录日志到文件中格式非常简单,设置日志文件名即可。
logging:
file:
name: server.log
虽然使用上述格式可以将日志记录下来了,但是面对线上的复杂情况,一个文件记录肯定是不能够满足运维要求的,通常会每天记录日志文件,同时为了便于维护,还要限制每个日志文件的大小。下面给出日志文件的常用配置方式:
logging:
logback:
rollingpolicy: #代表日志的滚动
max-file-size: 3KB #文件大小限度
file-name-pattern: server.%d{yyyy-MM-dd}.%i.log #滚动日志的文件名怎么启
以上格式是基于logback日志技术设置每日日志文件的设置格式,要求容量到达3KB以后就转存信息到第二个文件中。文件命名规则中的%d标识日期,%i是一个递增变量,用于区分日志文件。
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m