一、概述
使用mysqldumpslow工具定位到慢查询语句之后,可以使用explain或describe工具做针对性的分析查询语句。
MySQL种有专门负责优化SELECT语句的优化器模块:通过计算分析系统中收集到的统计信息,为客户端请求的Query提供他认为最优的执行计划。
这个执行计划展示了接下来具体执行查询的方式,比如多表连接的顺序是什么,对于每个表采用什么访问方法来具体执行查询等等。MySQL提供了EXPLAIN语句来帮助我们查看某个查询语句的具体执行计划,看懂EXPLAIN语句的各个输出项,可以有针对性的提升我们查询语句的性能。
二、基本语法
explain 查询语句; select、insert、update、delete都可使用
例如:explain select * from user limit 10;
explain语句输出的各列作用如下:
| 列名 | 描述 |
| id | 在一个大的查询语句种,每一个select关键字都对应一个唯一的id |
| select_type | select关键字对应的那个查询的类型 |
| table | 表名 |
| partitions | 匹配的分区信息 |
| type | 针对单表的访问方法 |
| possible_keys | 可能用到的索引 |
| key | 实际上用到的索引 |
| key_len | 实际用到的索引长度 |
| ref | 当使用索引列等值查询时,与索引列进行等值匹配的对象信息 |
| rows | 预估的需要读取的记录数 |
| filtered | 某个表经过搜索条件过滤后剩余记录条数的百分比 |
| exea | 一些额外信息 |
三、数据准备
执行以下代码,为分析explain做准备
#创建表
CREATE TABLE s1 (
id INT AUTO_INCREMENT,
key1 VARCHAR(100),
key2 INT,
key3 VARCHAR(100),
key_part1 VARCHAR(100),
key_part2 VARCHAR(100),
key_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
INDEX idx_key1 (key1),
UNIQUE INDEX idx_key2 (key2),
INDEX idx_key3 (key3),
INDEX idx_key_part(key_part1, key_part2, key_part3)
) ENGINE=INNODB CHARSET=utf8;
CREATE TABLE s2 (
id INT AUTO_INCREMENT,
key1 VARCHAR(100),
key2 INT,
key3 VARCHAR(100),
key_part1 VARCHAR(100),
key_part2 VARCHAR(100),
key_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
INDEX idx_key1 (key1),
UNIQUE INDEX idx_key2 (key2),
INDEX idx_key3 (key3),
INDEX idx_key_part(key_part1, key_part2, key_part3)
) ENGINE=INNODB CHARSET=utf8;
#创建存储函数:
DELIMITER //
CREATE FUNCTION rand_string1(n INT)
RETURNS VARCHAR(255) #该函数会返回一个字符串
BEGIN
DECLARE chars_str VARCHAR(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
DECLARE return_str VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));
SET i = i + 1;
END WHILE;
RETURN return_str;
END //
DELIMITER ;
SET GLOBAL log_bin_trust_function_creators=1;
#创建存储过程:
DELIMITER //
CREATE PROCEDURE insert_s1 (IN min_num INT (10),IN max_num INT (10))
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO s1 VALUES(
(min_num + i),
rand_string1(6),
(min_num + 30 * i + 5),
rand_string1(6),
rand_string1(10),
rand_string1(5),
rand_string1(10),
rand_string1(10));
UNTIL i = max_num
END REPEAT;
COMMIT;
END //
DELIMITER ;
DELIMITER //
CREATE PROCEDURE insert_s2 (IN min_num INT (10),IN max_num INT (10))
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO s2 VALUES(
(min_num + i),
rand_string1(6),
(min_num + 30 * i + 5),
rand_string1(6),
rand_string1(10),
rand_string1(5),
rand_string1(10),
rand_string1(10));
UNTIL i = max_num
END REPEAT;
COMMIT;
END //
DELIMITER ;
#调用存储过程
CALL insert_s1(10001,10000);
CALL insert_s2(10001,10000);
SELECT COUNT(*) FROM s1;
SELECT COUNT(*) FROM s2;
四、explain各列详解
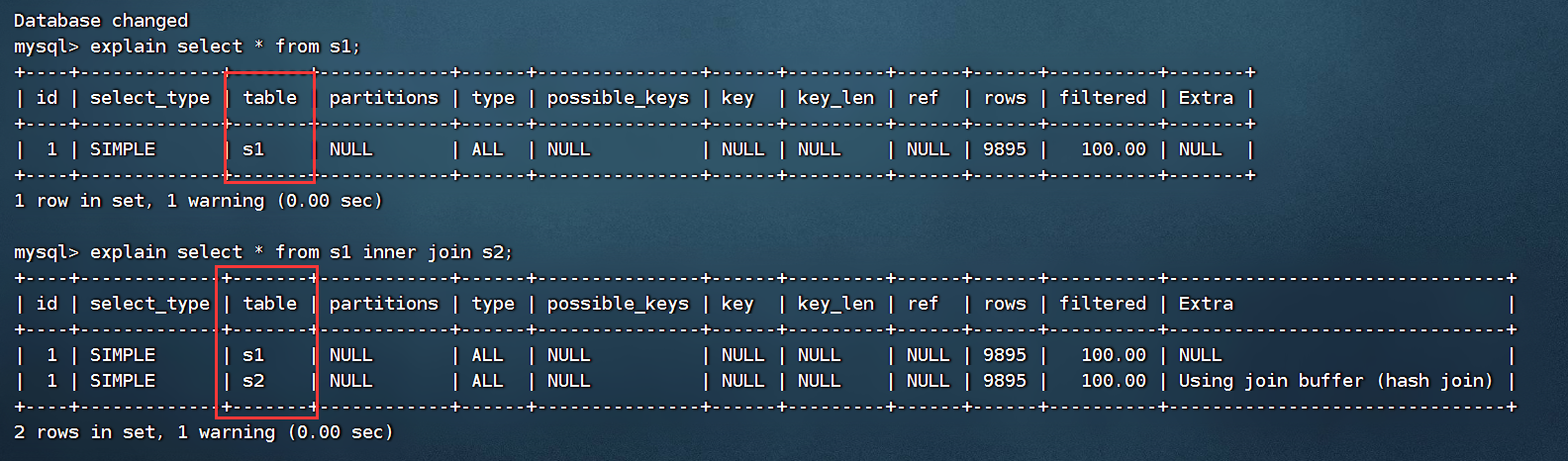
1、table:表名
查询的每一个行记录对应着一个单表
explain select * from s1;
explain select * from s1 inner join s2;
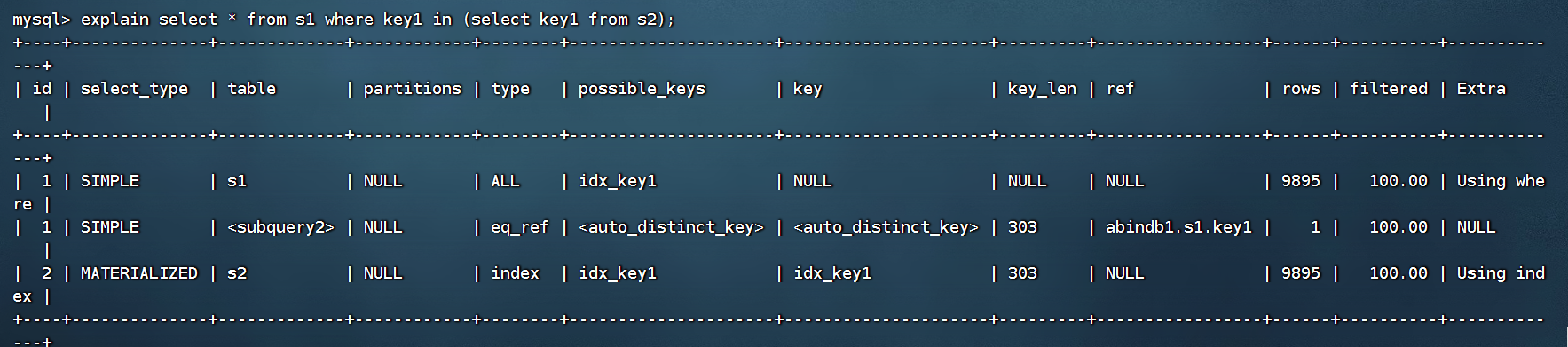
2、id:在一个大的查询语句中,每一个select关键字都对应一个唯一的id
explain select * from s1where key1 = 'a';
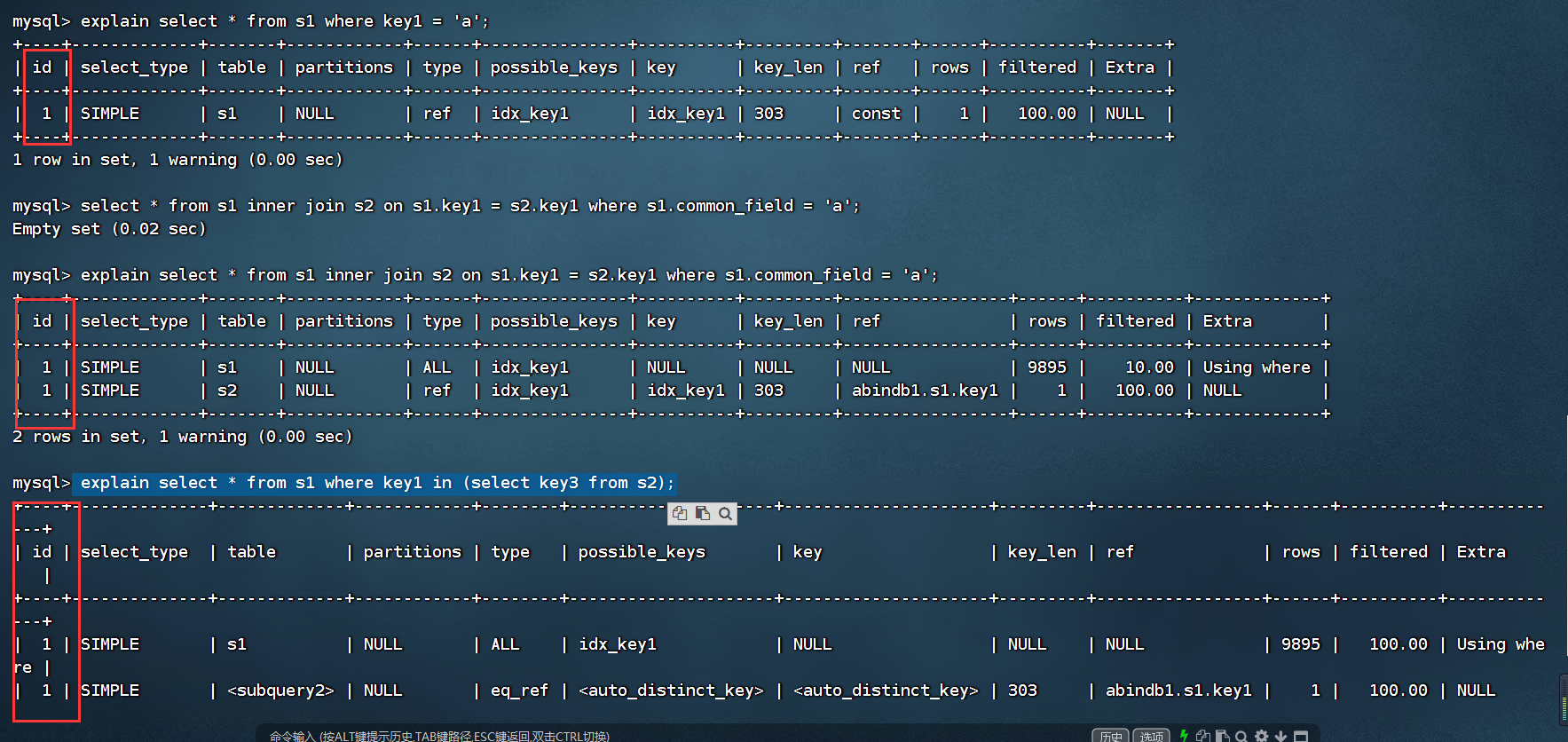
总结:
id如果相同,可以认为是一组,从上往下执行
在所有组种,id越大,优先级越高,越先执行
每一个id号码表示一趟独立的查询,一个SQL查询的趟数越少越好。
3、select_type:select关键字对应的那个查询的类型,确定小查询在大查询种扮演什么角色
①查询语句中不包含UNION或者子查询的查询都算是SIMPLE类型
explain select * from s1;

②连接查询也是SIMPLE
explain select * from s1 inner join s2;

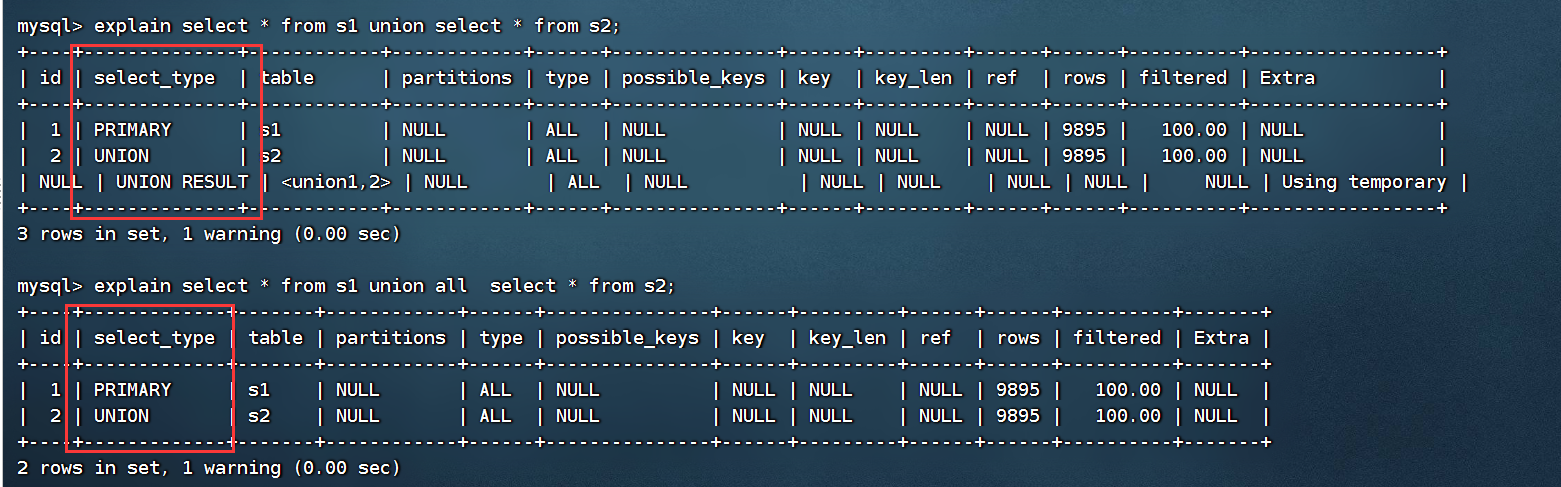
③对于包含UNION、UNION ALL的大查询来说,它是由几个小查询组成的,其中最左边的查询的select_type值就是PRIMARY,其余的小查询的select_type值为UNION
④MySQL选择使用临时表来完成UNION查询的去重工作,针对该临时表的查询的select_type的值是UNION RESULT
UNION 具有去重操作,UNION ALL没有去重操作,所以UNION会有一个临时表
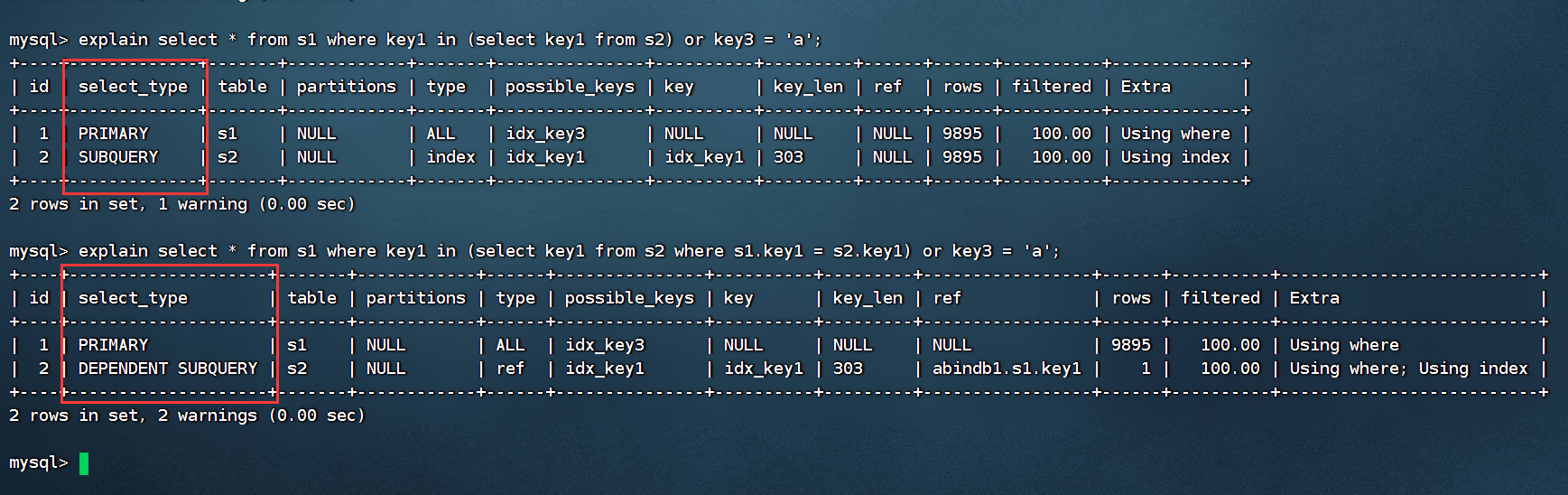
⑤如果包含子查询的查询语句不能转化为多表联查的形式,并且该子查询不是相关子查询,该子查询的第一个select关键字的查询的select_type就是SUBQUERY
⑥如果包含子查询的查询语句不能转化为多表联查的形式,并且该子查询是相关子查询,该子查询的第一个select关键字的查询的select_type就是DEPENDENT SUBQUERY
⑦在包含`UNION`或者`UNION ALL`的大查询中,如果各个小查询都依赖于外层查询的话,那除了最左边的那个小查询之外,其余的小查询的`select type `的值就是`DEPENDENT UNION

⑧对于包含派生表的查询,该派生表对应的子查询的select_type就是DERIVED

⑨当查询优化器在执行包含子查询的语句时,选择将子查询物化之后与外层查询进行连接查询时,该子查询对应的`select type`属性就是‘MATERIALIZED~
4、type
执行计划的一条记录就代表着MySQL对某个表的执行查询时的访问方法,又称°访问类型”,其中的type列就表明了这个访问方法是啥,是较为重要的一个指标。比如,看到type列的值是ref,表明MysQL即将使用ref访问方法来执行对s1表的查询。
完整的访问方法如下: system,const,eq_ref,ref, fulltext,ref_or_null , index_merge ,unique_subquery , index_subquery , range , index,ALL。
①system
当表中只有一条记录并且该表使用的存储引擎统计的书数据是精确的,比如MyISAM、Memory,那么对该表的访问方法就是system
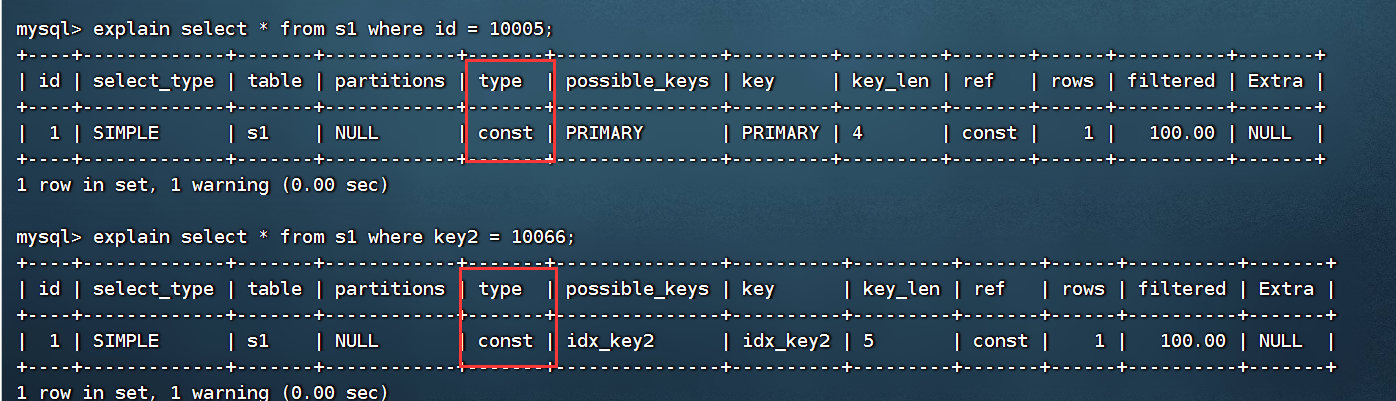
②const
当我们根据主键或唯一的二级索引列与常数进行等值匹配时,对单表的访问方法就是const
explain select * from s1 where id = 10005; explain select * from s1 where key2 = 10066;
③eq_ref
在连接查询时,如果被驱动表是通过主键或者唯一二级索引列等值匹配的方式进行访问的(如果该主键或者唯一二级索引是联合索引的话,所有的索引列都必须进行等值比较),则对该被驱动表的访问方法就是`eg ref`
explain select * from s1 inner join s2 on s1.id = s2.id;

④ref
当通过普通的二级索引列与常量进行等值匹配时来查询某个表,那么对该表的访问方法就可能是`ref'
explain select * from s1 where key1 = 'a';

⑤unique_subquery
unique subquery`是针对在一些包含`IN`子查询的查询语句中,如果查询优化器决定将`IN`子查询
转换为`ExISTS`子查询,而且子查询可以使用到主键进行等值匹配的话,那么该子查询执行计划的'type '列的值就是`unique_ subquery

⑥如果使用索引获取某些范围区间的记录,那么就可能用到range访问方法

⑦index
当我们可以使用索引覆盖,但需要扫描全部的索引记录时,该表的访问方法就是index

⑧all:全表扫描

5、possiable_keys和key
possiable_keys列表示在某个查询语句中,对某个表执行单表查询时可能用到的索引有哪些。
key表示实际用到的索引有哪些
6、key_len
实际使用到的索引的长度(字节数),检查是否充分利用了索引,值越大越好(和自己比),主要针对联合索引。
先更新到这里,会持续更新~~~~
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
我注意到类定义,如果我打开classMyClass,并在不覆盖的情况下添加一些东西我仍然得到了之前定义的原始方法。添加的新语句扩充了现有语句。但是对于方法定义,我仍然想要与类定义相同的行为,但是当我打开defmy_method时似乎,def中的现有语句和end被覆盖了,我需要重写一遍。那么有什么方法可以使方法定义的行为与定义相同,类似于super,但不一定是子类? 最佳答案 我想您正在寻找alias_method:classAalias_method:old_func,:funcdeffuncold_func#similartoca
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
在添加一些空格以使代码更具可读性时(与上面的代码对齐),我遇到了这个:classCdefx42endendm=C.new现在这将给出“错误数量的参数”:m.x*m.x这将给出“语法错误,意外的tSTAR,期待$end”:2/m.x*m.x这里的解析器到底发生了什么?我使用Ruby1.9.2和2.1.5进行了测试。 最佳答案 *用于运算符(42*42)和参数解包(myfun*[42,42])。当你这样做时:m.x*m.x2/m.x*m.xRuby将此解释为参数解包,而不是*运算符(即乘法)。如果您不熟悉它,参数解包(有时也称为“spl
我想从then子句中访问case语句表达式,即food="cheese"casefoodwhen"dip"then"carrotsticks"when"cheese"then"#{expr}crackers"else"mayo"end在这种情况下,expr是食物的当前值(value)。在这种情况下,我知道,我可以简单地访问变量food,但是在某些情况下,该值可能无法再访问(array.shift等)。除了将expr移出到局部变量然后访问它之外,是否有直接访问caseexpr值的方法?罗亚附注我知道这个具体示例很简单,只是一个示例场景。 最佳答案
如何在Ruby的if语句中检查bash命令的返回值(true/false)。我想要这样的东西,if("/usr/bin/fswscell>/dev/null2>&1")has_afs="true"elsehas_afs="false"end它会提示以下错误含义,它总是返回true。(irb):5:warning:stringliteralincondition正确的语法是什么?更新:/usr/bin/fswscell寻找afs安装和运行状态。它会抛出这样的字符串,Thisworkstationbelongstocell如果afs没有运行,命令以状态1退出 最
我最近与一位同事讨论了以下Ruby语法:value=ifa==0"foo"elsifa>42"bar"else"fizz"end我个人并没有看到太多这种逻辑,但我的同事指出,这实际上是一种相当普遍的Rubyism。我试着用谷歌搜索这个主题,但没有找到任何文章、页面或SO问题来讨论它,这让我相信这可能是一种非常实际的技术。然而,另一位同事发现语法令人困惑,而是将上面的逻辑写成这样:ifa==0value="foo"elsifa>42value="bar"elsevalue="fizz"end缺点是value=的重复声明和隐式elsenil的丢失,如果我们想使用它的话。这也感觉它与Ruby
我在Rails上使用带有ruby的solr。一切正常,我只需要知道是否有任何现有代码来清理用户输入,比如以?开头的查询。或* 最佳答案 我不知道执行此操作的任何代码,但理论上可以通过查看parsingcodeinLucene来完成并搜索thrownewParseException(只有16个匹配!)。在实践中,我认为您最好只捕获代码中的任何solr异常并显示“无效查询”消息或类似信息。编辑:这里有几个“sanitizer”:http://pivotallabs.com/users/zach/blog/articles/937-s
我正在为锦标赛开发一个Rails应用程序。我在这个查询中使用了三个模型:classPlayertruehas_and_belongs_to_many:tournamentsclassTournament:destroyclassPlayerMatch"Player",:foreign_key=>"player_one"belongs_to:player_two,:class_name=>"Player",:foreign_key=>"player_two"在tournaments_controller的显示操作中,我调用以下查询:Tournament.where(:id=>params