Graphviz - Graph Visualization Software(图形可视化软件)
官方网址:Graphviz
个人理解:针对神经网络来说,这个库可以用来显示神经网络结构图形(如下图为Keras Applications中的VGG16网络结构图),作用类似model.summary()

首先先前往graphviz官网下载对应系统的exe文件,然后运行这个exe文件进行安装
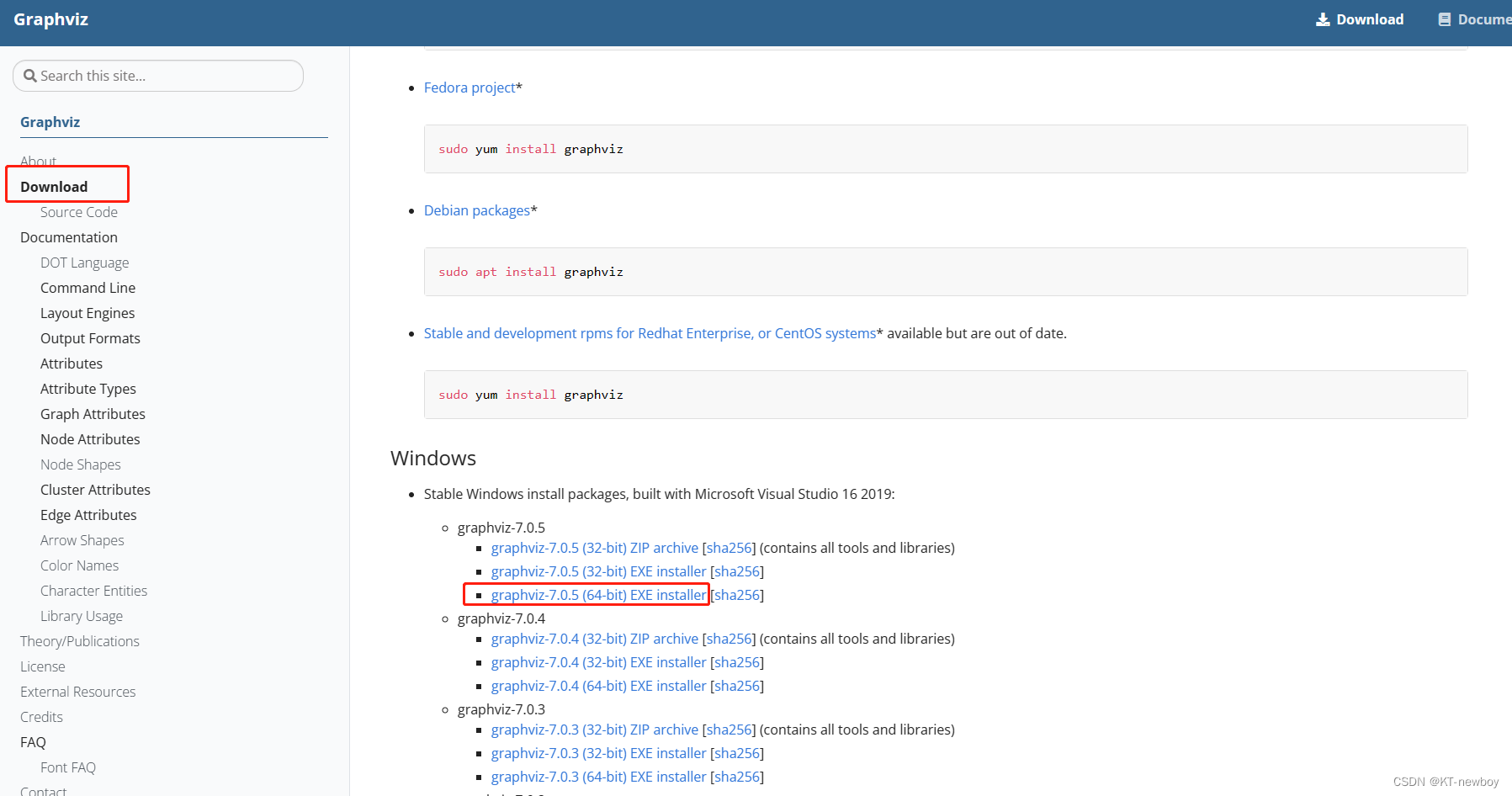
安装时选择这个会自动添加到系统环境变量中去
上图表示graphviz安装成功。

输入:conda create -p=F:\conda_environment\graphviz-test python=3.9
-p 后面表示创建的虚拟环境的路径
python=3.9 表示使用conda里面3.9版本的python解释器
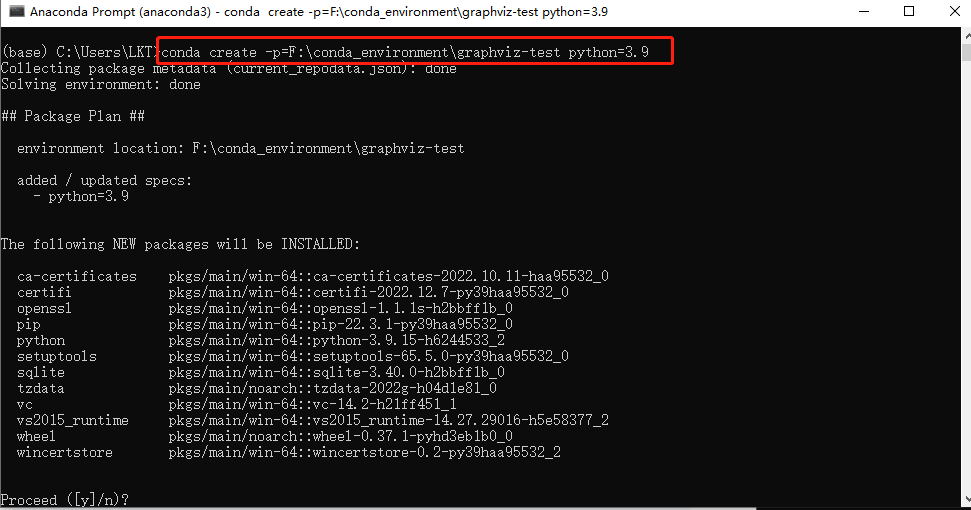
Proceed ([y]/n)? 输入:y
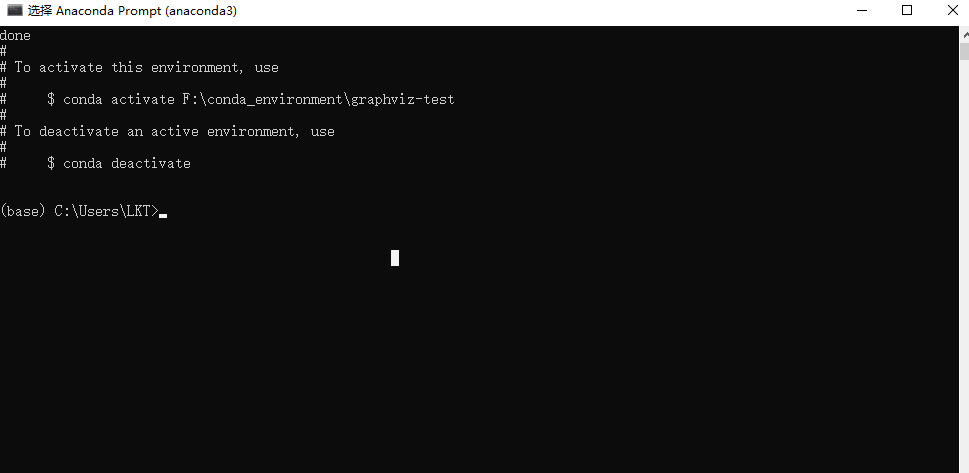
表示在路径F:\conda_environment\graphviz-test 建好了conda虚拟环境
输入:conda info -e
查看创建好的虚拟环境
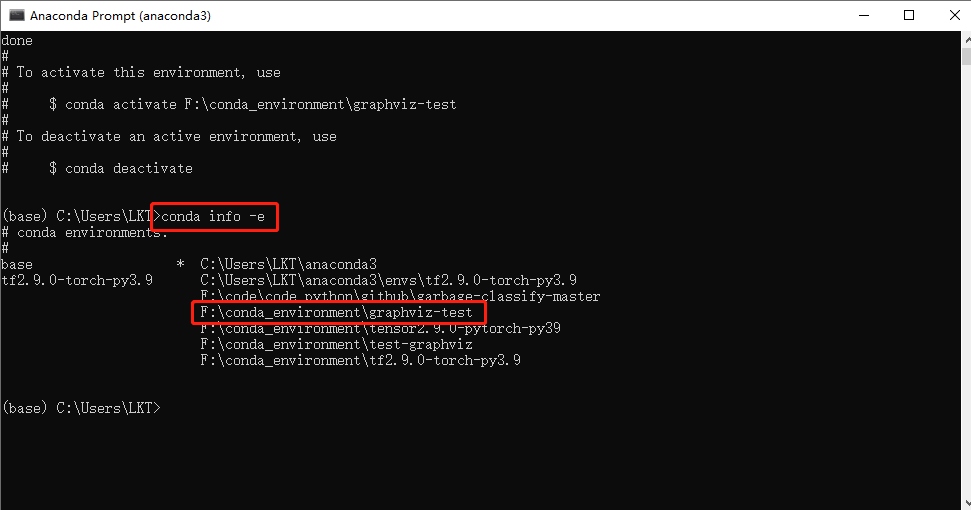
表示已经成功创建好虚拟环境。
接下来需要激活我们刚才创建的虚拟环境(F:\conda_environment\graphviz-test),这样我们才能在这个环境中下载安装我们所需要的库。
输入:conda activate F:\conda_environment\graphviz-test
激活环境

环境激活成功后前面(base)将会变成你所激活的环境(F:\conda_environment\graphviz-test)
首先先下载pydotplus库
输入:pip install pydotplus
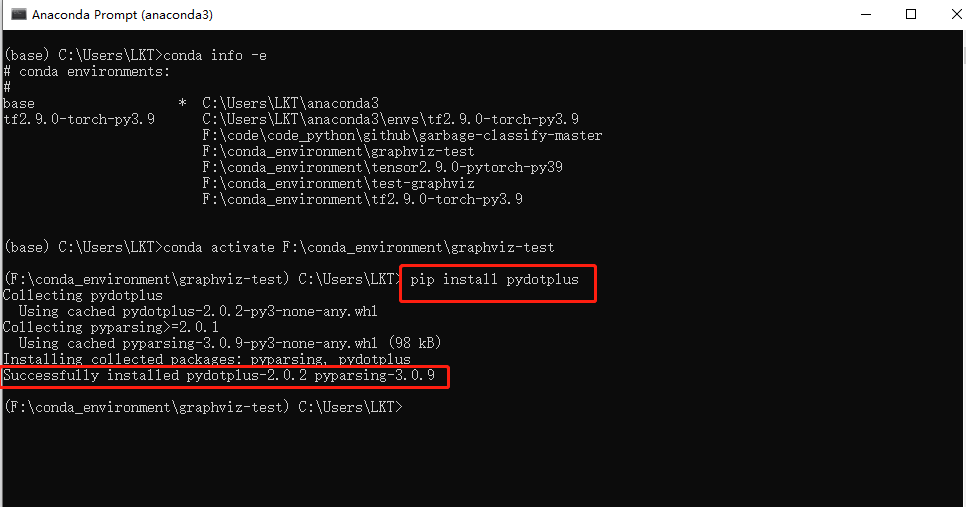
再输入:pip install graphviz

这样就安装好graphviz库了!!!
打开Pycharm创建新项目
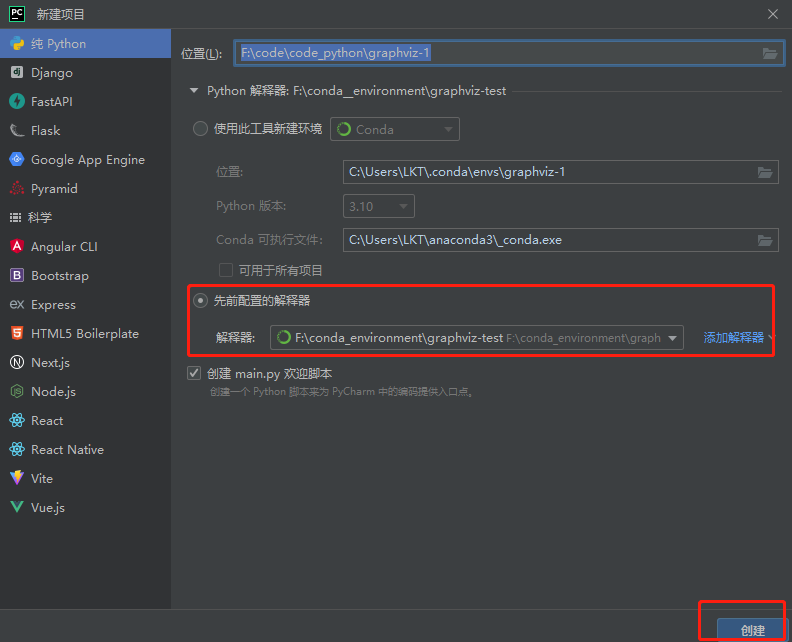
1.创建项目的路径:F:\code\code_python\graphviz-1
2.选择:先前配置的解释器
3.点击“添加解释器”——“添加本地解释器”(这时候就可以选择我们前面刚创建好的conda 虚拟环境里面的解释器作为这个项目的python解释器)

下一步就是选择解释器
1.选择:Conda环境
2.选择:使用现有环境
3.选择刚才创建的虚拟环境 F:\conda_environment\graphviz-test
4.点击“确定”

此时已经给项目配置好解释器,最后点击“创建”即可。
创建好项目后新建一个py文件
输入测试代码:
from keras.applications import VGG16
from keras.utils import plot_model
from IPython.display import Image
conv_base=VGG16(weights='imagenet',
include_top=True)
# conv_base.summary()
plot_model(conv_base,show_shapes=True,to_file='VGG16.png')
Image(filename='VGG16.png')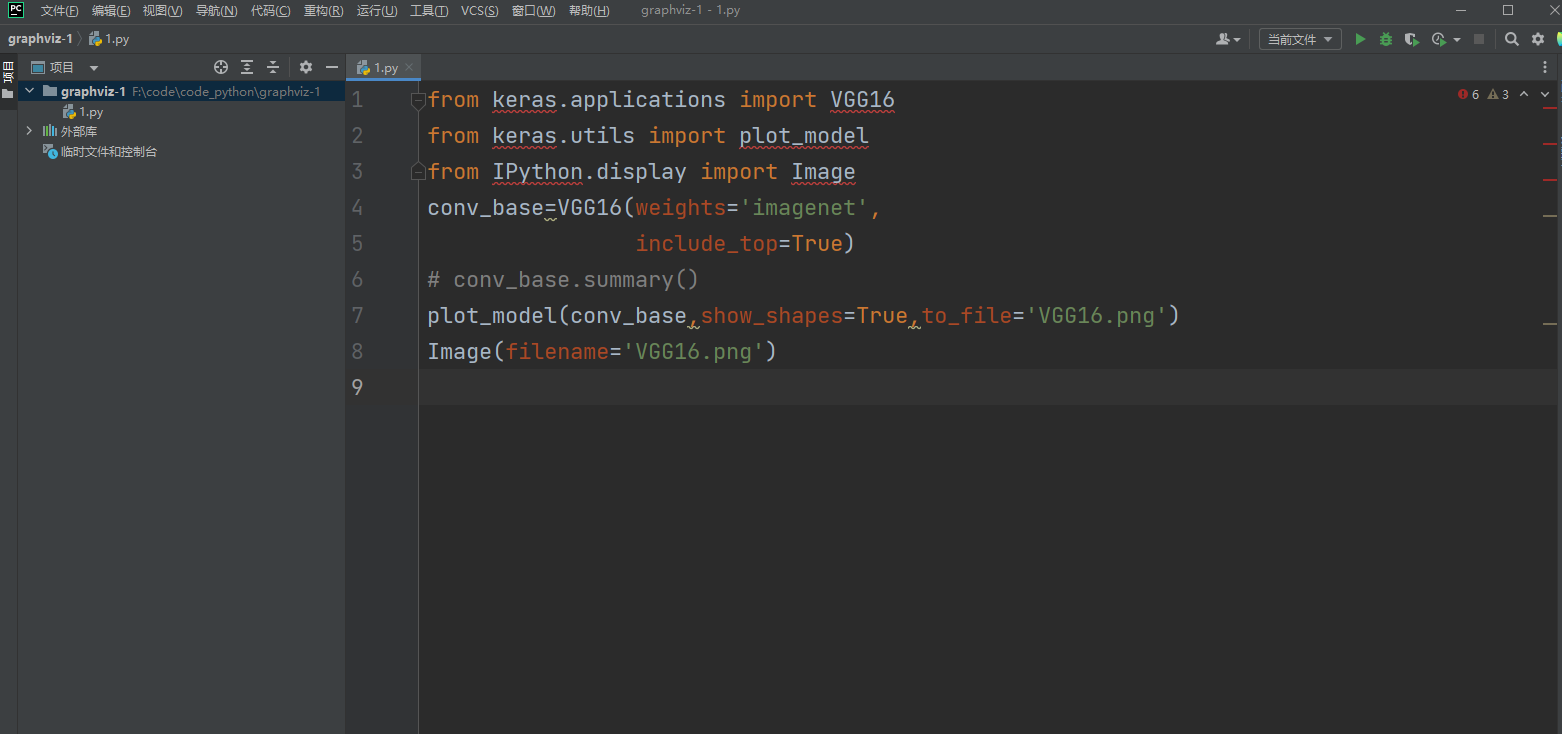
此时需要在终端处进行tensorflow和IPython库的安装即可运行代码
首先先在终端激活前面创建的虚拟环境:F:\conda_environment\graphviz-test
在终端处输入:conda activate F:\conda_environment\graphviz-test
即可激活虚拟环境


然后再这个虚拟环境中用清华镜像源进行安装tensorflow和IPython库
输入:pip install tensorflow -i https://pypi.tuna.tsinghua.edu.cn/simple


输入: pip install IPython -i https://pypi.tuna.tsinghua.edu.cn/simple

此时即可运行代码
输入: python ./1.py
即可
运行后再项目文件夹下就会出现此文最开始的那张图片。至此完成graphviz库的安装以及测试。(测试也可以网上找其他代码进行验证)

1.最开始pip install pydot 和 pip install graphviz ,但是一直会出现下面这个错误。最后在网上找到资料说python3.6版本以上不适用pydot,需要下载pydotplus库,下载完pydotplus后再运行测试代码就可以了。
如果只是针对上面使用的测试代码(上面那个代码是我在跟着学习视频敲出来的测试代码,是一个老师自己写的),其实只需要pip了pydotplus就可以运行代码了,而不需要下载graphviz。
但是针对网上其他的graphviz测试代码则只需要pip下载graphviz,pydotplus这个看情况下载,我测试了一个网上代码竟然不需要下载pydotplus也可以运行,所以看情况而定。
2.如果直接在终端pip install keras,然后运行代码会报错没有模块‘tensorflow',需要直接下载tensorflow库(可能原因是keras是在tensorflow基础上开发出来的,有些文件在tensorflow中,而不在keras,所以直接下载tensorflow也包含了keras所需要的文件),就不会报错了。

很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我打算为ruby脚本创建一个安装程序,但我希望能够确保机器安装了RVM。有没有一种方法可以完全离线安装RVM并且不引人注目(通过不引人注目,就像创建一个可以做所有事情的脚本而不是要求用户向他们的bash_profile或bashrc添加一些东西)我不是要脚本本身,只是一个关于如何走这条路的快速指针(如果可能的话)。我们还研究了这个很有帮助的问题:RVM-isthereawayforsimpleofflineinstall?但有点误导,因为答案只向我们展示了如何离线在RVM中安装ruby。我们需要能够离线安装RVM本身,并查看脚本https://raw.github.com/wayn
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我有一个奇怪的问题:我在rvm上安装了rubyonrails。一切正常,我可以创建项目。但是在我输入“railsnew”时重新启动后,我有“程序'rails'当前未安装。”。SystemUbuntu12.04ruby-v"1.9.3p194"gemlistactionmailer(3.2.5)actionpack(3.2.5)activemodel(3.2.5)activerecord(3.2.5)activeresource(3.2.5)activesupport(3.2.5)arel(3.0.2)builder(3.0.0)bundler(1.1.4)coffee-rails(
我刚刚为fedora安装了emacs。我想用emacs编写ruby。为ruby提供代码提示、代码完成类型功能所需的工具、扩展是什么? 最佳答案 ruby-mode已经包含在Emacs23之后的版本中。不过,它也可以通过ELPA获得。您可能感兴趣的其他一些事情是集成RVM、feature-mode(Cucumber)、rspec-mode、ruby-electric、inf-ruby、rinari(用于Rails)等。这是我当前用于Ruby开发的Emacs配置:https://github.com/citizen428/emacs
我有一个围绕一些对象的包装类,我想将这些对象用作散列中的键。包装对象和解包装对象应映射到相同的键。一个简单的例子是这样的:classAattr_reader:xdefinitialize(inner)@inner=innerenddefx;@inner.x;enddef==(other)@inner.x==other.xendenda=A.new(o)#oisjustanyobjectthatallowso.xb=A.new(o)h={a=>5}ph[a]#5ph[b]#nil,shouldbe5ph[o]#nil,shouldbe5我试过==、===、eq?并散列所有无济于事。
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
我正在尝试在我的centos服务器上安装therubyracer,但遇到了麻烦。$geminstalltherubyracerBuildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingtherubyracer:ERROR:Failedtobuildgemnativeextension./usr/local/rvm/rubies/ruby-1.9.3-p125/bin/rubyextconf.rbcheckingformain()in-lpthread...yescheckingforv8.h...no***e