目录
针孔相机成像原理其实就是利用投影将真实的三维世界坐标转换到二维的相机坐标上去,其模型示意图如下图所示:
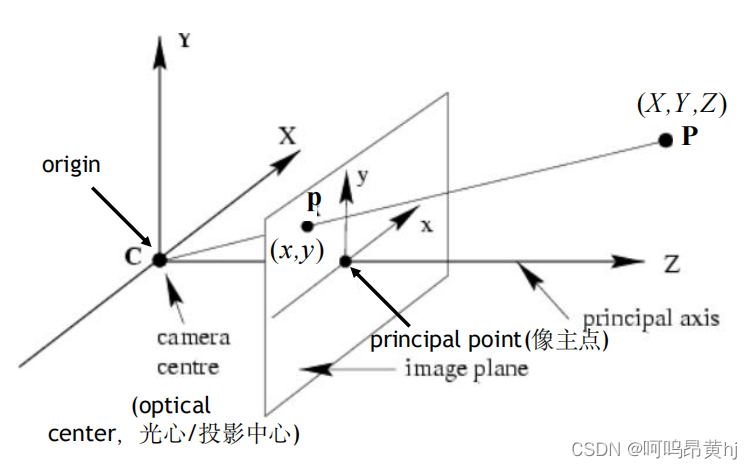
(X,Y,Z)为在世界坐标系下一点的物理坐标
( u , v ) 为该点对应的在像素坐标系下的像素坐标
引入齐次坐标的原因:引入齐次坐标的目的是为了升维,将坐标从二维坐标变为三维坐标。
相机成像系统中,共包含四个坐标系:世界坐标系、相机坐标系、图像坐标系、像素坐标系。
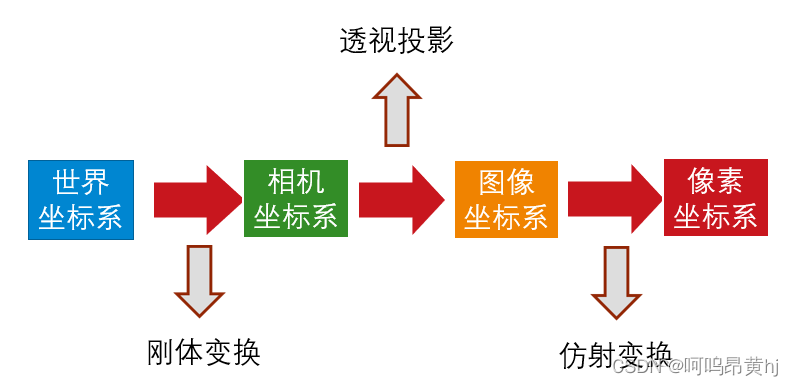
(1)世界坐标系(,
,
)
描述目标在真实世界中的位置引入的参考坐标系。
(2)相机坐标系(,
,
)
联系世界坐标系与图像坐标系的桥梁,一般取摄像机的光学轴为z轴。
(3)图像坐标系(x,y)
根据投影关系引入,方便进一步得到像素坐标,单位为毫米,坐标原点为摄像机光轴与图像物理坐标系的交点位置。
(4)像素坐标系(u,v)
真正从相机内读到的信息,图像物理坐标的离散化,以像素为单位,坐标原点在左上角。
像素坐标系和图像坐标系都在成像平面上,只是各自的原点和度量单位不一样。
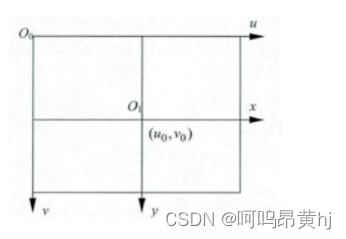
由于(u,v)只代表像素的列数与行数,而像素在图像中的位置并没有用物理单位表示出来,所以,我们还要建立以物理单位(如毫米)表示的图像坐标系(x,y)。将相机光轴与图像平面的交点(一般位于图像平面的中心处,也称为像主点(principal point)定义为该坐标系的原点,且x轴与u轴平行,y轴与v轴平行,假设(
,
)代表
在(u,v)坐标系下的坐标,dx与dy分别表示每个像素在横轴x和纵轴y上的物理尺寸,则图像中的每个像素在(u,v)坐标系中的坐标和在(x,y)坐标系中的坐标之间都存在如下的关系:
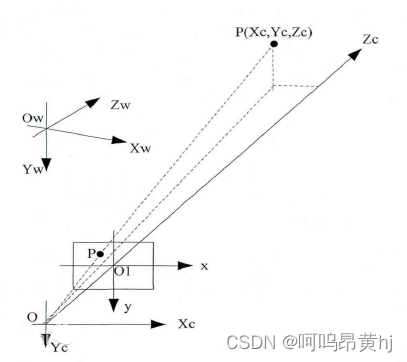
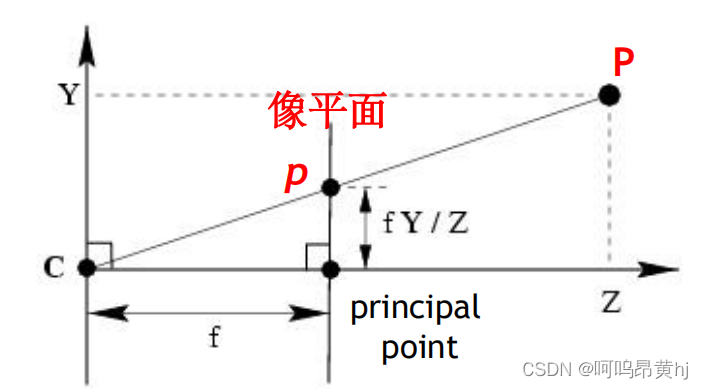
点P(Xc,Yc,Zc)由通过投影中心的光线投影到图像平面上,相应的图像点为p(x,y,f);根据相似三角形原理:
用线性矩阵描述为:
世界坐标系是为了描述相机的位置而被引入,上图中坐标系OwXwYwZw即为世界坐标系。平移向量t旋转矩阵R可以用来表示相机坐标系与世界坐标系的关系。所以,假设空间点P在世界坐标系下的齐次坐标是,在相机坐标下的齐次坐标是
,则存在如下关系:
其中 R为3x3的旋转矩阵,t为3x1的平移矢量。
世界坐标系到像素坐标系的变换可由上面的公式组合而成:
其中M1称为相机的内部参数矩阵,M2称为相机的外部参数矩阵,M称为投影矩阵 。
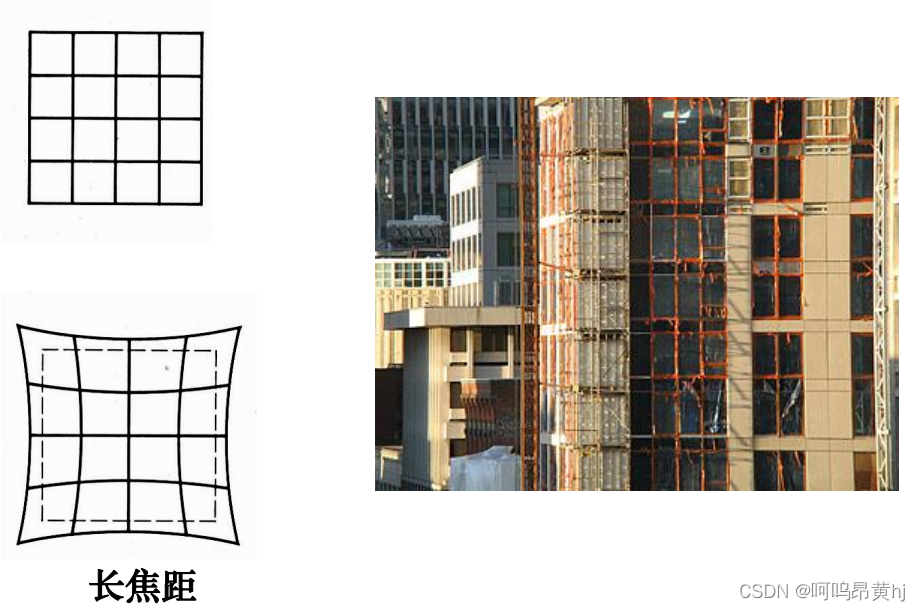
在世界坐标中的一条直线上的点在相机上只呈现出了一个点,其中发生了非常大的变化,同时也损失和很多重要的信息,这正是我们3D重建、目标检测与识别领域的重点和难点。实际中,镜头并非理想的透视成像,带有不同程度的畸变。理论上镜头的畸变包括径向畸变和切向畸变,切向畸变影响较小,通常只考虑径向畸变。
径向畸变:径向畸变主要由镜头径向曲率产生(光线在远离透镜中心的地方比靠近中心的地方更加弯曲)。导致真实成像点向内或向外偏离理想成像点。其中畸变像点相对于理想像点沿径向向外偏移,远离中心的,称为枕形畸变;径向畸点相对于理想点沿径向向中心靠拢,称为桶状畸变。
桶状畸变:

枕形畸变:
径向畸变公式:
切向畸变公式:
其中,(),(
)分别为理想的无畸变的归一化的图像坐标、畸变后的归一化图像坐标,
为图像像素点到图像中心点的距离,即
相机标定的第二个目的就是获得相机的畸变参数,如上式中的
针对针孔相机模型,只要内参矩阵和外参矩阵就可以唯一的确定相机模型。这个过程就称为相机标定。相机标定的目的是为了获得相机的内参矩阵和外参矩阵。相机标定的内参主要包括焦距、像主点坐标、畸变参数。
通过世界坐标集(,
,
),以及它们在图像平面上的投影坐标集(
,
),计算相机投影 矩阵M中的 11个未知参数。
相机模型:
线性方法:
非线性方法:
张正友标定法利用如下图所示的棋盘格标定板,在得到一张标定板的图像之后,可以利用相应的图像检测算法得到每一个角点的像素坐标( u , v ) 。
张正友标定法将世界坐标系固定于棋盘格上,则棋盘格上任一点的物理坐标W = 0 ,由于标定板的世界坐标系是人为事先定义好的,标定板上每一个格子的大小是已知的,我们可以计算得到每一个角点在世界坐标系下的物理坐标( U , V , W = 0 ) 。
我们将利用这些信息:每一个角点的像素坐标( u , v ) 、每一个角点在世界坐标系下的物理坐标( U , V , W = 0 ),来进行相机的标定,获得相机的内外参矩阵、畸变参数。

2D图像点:
3D图像点:
描述空间坐标到图像坐标的映射:
张正友标定法标定相机的内外参数的思路如下:
1)、求解内参矩阵与外参矩阵的积;
2)、求解内参矩阵;
3)、求解外参矩阵。
1)求解内参与外参的积
不妨设棋盘格位于Z=0
定义旋转矩阵R的第i列为ri,则有:
于是空间到图像的映射可改为:
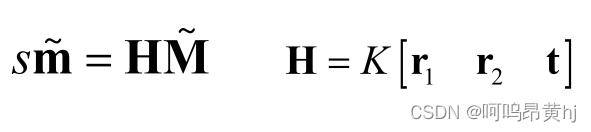
令H为
Homography 有 8 个自由度,
其中,H为一个3*3的矩阵,并且有一个元素作为齐次坐标。因此,H有8个自由度。现在有8个自由度需要求解,所以需要四个对应点。也就是四个点就可以求出图像平面到世界平面的单应性矩阵H。通过4个点,我们就可以可以获得单应性矩阵H。但是,H是内参阵和外参阵的合体。
由于和
是通过单应性求解出来的,所以我们要求解的参数就变成K矩阵中未知的5个参数。我们可以通过三个单应性矩阵来求解这5个参数,利用三个单应性矩阵在两个约束下可以生成6个方程。其中,三个单应性矩阵可以通过三张对同一标定板不同角度和高度的照片获得。
2)求解内参
定义
B是对称矩阵,其未知量可表示为6D向量b,
设H中的第i列为,
根据b的定义,推导出:
可以推导出
当观测图像大于或等于三幅图像时,就可以得到b的唯一解,应用上述公式我们就可以估算出B了。
B是通过b构造的对称矩阵。
得到B后,我们通过cholesky分解 ,就可以得到摄相机机的内参阵A的六个自由度,即
3)求解外参
根据化简可得外部参数,即:
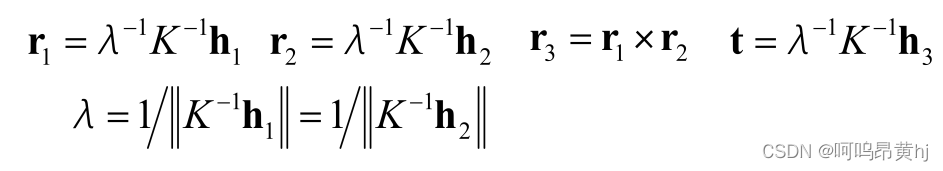
(1)准备一个张正友标定法的棋盘格,棋盘格大小已知,用相机对其进行不同角度的拍摄,得到一组图像;
(2)对图像中的特征点如标定板角点进行检测,得到标定板角点的像素坐标值,根据已知的棋盘格大小和世界坐标系原点,计算得到标定板角点的物理坐标值;
(3)求解内参矩阵与外参矩阵;
(4)求解畸变系数;
(5)利用L-M(Levenberg-Marquardt)算法对上述参数进行优化。
import cv2
import glob
import numpy as np
w = 9 # 内角点个数,内角点是和其他格子连着的点
h = 6
objp = np.zeros((w * h, 3), np.float32)#一个9*6行3列的矩阵
objp[:, :2] = np.mgrid[0:w, 0:h].T.reshape(-1, 2)# 储存棋盘格角点的世界坐标和图像坐标对 reshape(-1, 2)-1表示不确定分几行,2表示分为2列
objp=2.6*objp #棋盘格实际大小
objpoints = [] # 在世界坐标系中的三维点
imgpoints = [] # 在图像平面的二维点
images = glob.glob('photo2/*.jpg')
# 取文件夹中所有图片
for fname in images:
# 对每张图片,识别出角点,记录世界物体坐标和图像坐标
img = cv2.imread(fname)#获取图像的水平方向和垂直方向的尺寸
img = cv2.resize(img, None, fx=0.5, fy=0.5, interpolation=cv2.INTER_CUBIC)#立方插值法 缩放到原来的二分之一
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转灰度
# 寻找角点,存入corners,ret是找到角点的flag
ret, corners = cv2.findChessboardCorners(gray, (9, 6), None)
# criteria:角点精准化迭代过程的终止条件
criteria = (cv2.TERM_CRITERIA_MAX_ITER+ cv2.TERM_CRITERIA_EPS , 30, 0.001)#第一项表示迭代次数达到最大次数时停止迭代,第二项表示角点位置变化的最小值已经达到最小时停止迭代
# 执行亚像素级角点检测
corners2 = cv2.cornerSubPix(gray, corners, (11, 11), (-1, -1), criteria) # 输入图像、角点初始坐标、搜索窗口为2*winsize+1、第四个参数作用类似于winSize,但是总是具有较小的范围,通常忽略(即Size(-1, -1)), 求角点的迭代终止条件
objpoints.append(objp)# .append()向列表/数组添加元素
imgpoints.append(corners2)
# 在棋盘上绘制角点
img = cv2.drawChessboardCorners(img, (9, 6), corners2, ret)
cv2.namedWindow('img', cv2.WINDOW_NORMAL)
cv2.imshow('img', img)
cv2.waitKey(1000)
'''
传入所有图片各自角点的三维、二维坐标,相机标定。
每张图片都有自己的旋转和平移矩阵,但是相机内参和畸变系数只有一组。
mtx,相机内参;dist,畸变系数;rvecs,旋转矩阵;tvecs,平移矩阵。
'''
# 输入:世界坐标系里的位置 像素坐标 图像的像素尺寸大小 3*3矩阵,相机内参数矩阵 畸变矩阵
#使用cv2.calibrateCamera()进行标定,这个函数会返回标定结果、相机的内参数矩阵、畸变系数、旋转矩阵和平移向量
ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(objpoints, imgpoints, gray.shape[::-1], None, None)
img = cv2.imread('photo2/5.jpg')
img = cv2.resize(img, None, fx=0.5, fy=0.5, interpolation=cv2.INTER_CUBIC)
h, w = img.shape[:2]
'''
使用cv.getOptimalNewCameraMatrix()优化内参数和畸变系数
参数1表示保留所有像素点,同时可能引入黑色像素,并返回一个ROI用于将其剪裁掉
设为0表示尽可能裁剪不想要的像素,这是个scale,0-1都可以取。
'''
newcameramtx, roi = cv2.getOptimalNewCameraMatrix(mtx, dist, (w, h), 1, (w, h))
# 纠正畸变
dst = cv2.undistort(img, mtx, dist, None, newcameramtx)
# 输出纠正畸变以后的图片
x, y, w, h = roi
dst = dst[y:y + h, x:x + w]
cv2.imwrite('result.png', dst)
# 输出:标定结果 相机的内参数矩阵 畸变系数 旋转矩阵 平移向量
mtx_new=mtx.tolist()
print("相机内参矩阵:\n", mtx_new)#[fx,s,x0;0,fy,y0;0,0,1],fx,fy为焦距,一般二者相等;x0、y0为主点坐标(相对于成像平面),s为坐标轴倾斜参数,理想情况下为0
print("newcameramtx:\n", newcameramtx)
print (("旋转向量rvecs:\n"),rvecs) # 旋转向量 # 外参数,3个旋转参数
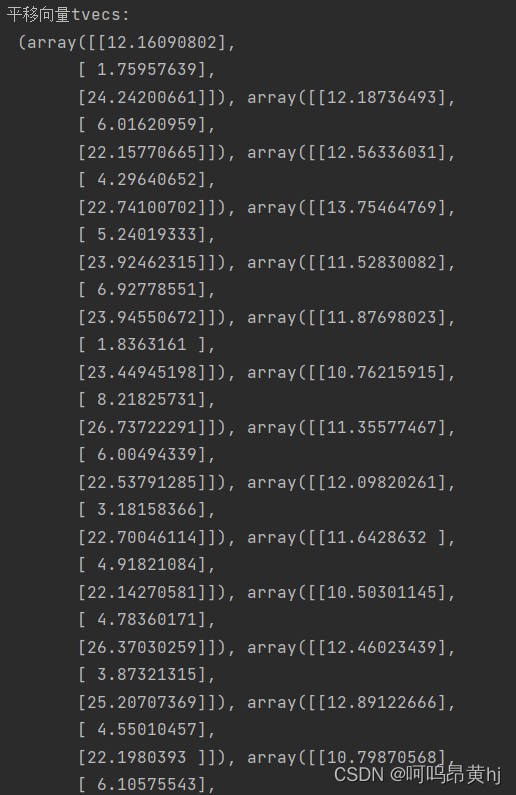
print (("平移向量tvecs:\n"),tvecs) # 平移向量 # 外参数,3个平移参数
print("畸变系数dist:\n", dist)#5个畸变参数,径向畸变k1,k2,k3,切向畸变p1、p2
# 计算误差
# 反投影误差越接近0,说明结果越理想。
# 通过之前计算的内参数矩阵、畸变系数、旋转矩阵和平移向量,使用cv2.projectPoints()计算三维点到二维图像的投影,
# 然后计算反投影得到的点与图像上检测到的点的误差,最后计算一个对于所有标定图像的平均误差,这个值就是反投影误差。
tot_error = 0
for i in range(len(objpoints)):
imgpoints2, _ = cv2.projectPoints(objpoints[i], rvecs[i], tvecs[i], mtx, dist)
error = cv2.norm(imgpoints[i], imgpoints2, cv2.NORM_L2) / len(imgpoints2)
tot_error += error
print("total error: ", tot_error / len(objpoints))
本次实验采用了两组数据,第1组为拍摄角度变化较大的15张,第2组拍摄角度几乎没变的15张。
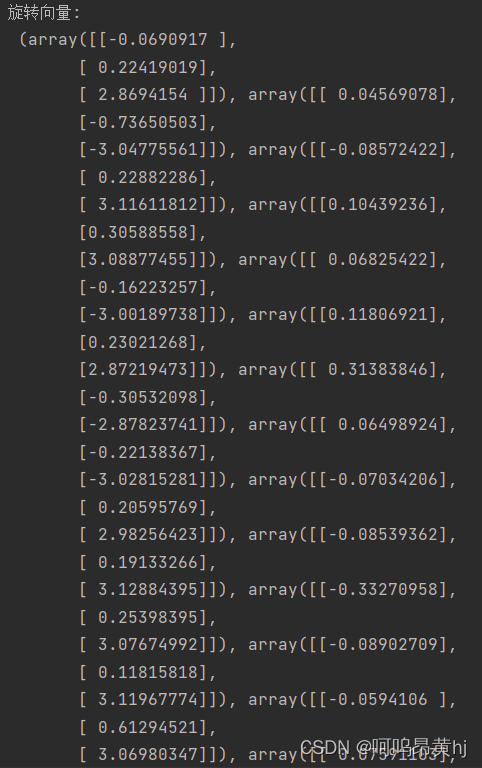
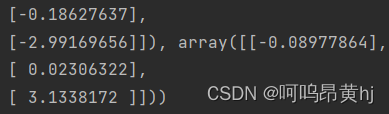
第1组棋盘格照片(角度变化比较大的15张):

实验结果:
角点检测结果:




第2组棋盘格照片(拍摄角度几乎不变的15张):

实验结果:





(1) 同一相机用同一组图片进行多次实验得到的相机内参一致,且畸变系数保持不变。但是每张图片的旋转矩阵和平移矩阵不同。
(2) 同一相机分别对角度变化比较大的15张图片和角度几乎不变的15张图片进行实验得到的相机内参不一致,是由于相机标定时采用的是小孔成像模型,但是这个模型并不是真正的模型,只是一个近似模型,所以不同距离等效的相机光心点不一样,导致在不同距离标定的相机内参是不一样的。另一方面的原因是因为相机标定时标定板并不能做到完全在一个平面上,会对实验结果产生一定的误差。
(3) 标定照片的图片不能太少,会导致标定参数不准确。
(4) 拍摄过程中如果调整了焦距会对实验结果有影响,需要重新标定。
(5)拍摄的图片的清晰度会影响角点检测,从而影响实验结果。
📢博客主页:https://blog.csdn.net/weixin_43197380📢欢迎点赞👍收藏⭐留言📝如有错误敬请指正!📢本文由Loewen丶原创,首发于CSDN,转载注明出处🙉📢现在的付出,都会是一种沉淀,只为让你成为更好的人✨文章预览:一.分辨率(Resolution)1、工业相机的分辨率是如何定义的?2、工业相机的分辨率是如何选择的?二.精度(Accuracy)1、像素精度(PixelAccuracy)2、定位精度和重复定位精度(RepeatPrecision)三.公差(Tolerance)四.课后作业(Post-ClassExercises)视觉行业的初学者,甚至是做了1~2年
在本文中,我们将探讨摄影机的外参,并通过Python中的一个实践示例来加强我们的理解。相机外参摄像头可以位于世界任何地方,并且可以指向任何方向。我们想从摄像机的角度来观察世界上的物体,这种从世界坐标系到摄像机坐标系的转换被称为摄像机外参。那么,我们怎样才能找到相机外参呢?一旦我们弄清楚相机是如何变换的,我们就可以找到从世界坐标系到相机坐标系的基变换的变化。我们将详细探讨这个想法。具体来说,我们需要知道相机是如何定位的,以及它在世界空间中的位置,有两种转换可以帮助我们:有助于确定摄影机方向的旋转变换。有助于移动相机的平移变换。让我们详细看看每一个。旋转通过旋转改变坐标让我们看一下将点旋转一个角度
俯拍相机中心和吸嘴中心的标定文章目录俯拍相机中心和吸嘴中心的标定前言适用模型如下:一、使用一个标定片进行标定1.关键注意:2.标定步骤:二、使用一个L型的工件1.关键注意:2.标定步骤:总结前言在自动化设备领域,使用相机进行定位是很普遍存在的,而使用相机定位就必定会用到标定,本文介绍两种关于吸嘴上方的俯拍相机和吸嘴中心的标定方法(前提是带有仰拍相机和俯拍相机)。【还有很多相机的使用场景的标定方法将在以后的文章中进行阐述】适用模型如下:一、使用一个标定片进行标定1.关键注意:关键是使用两个相机的中心和识别偏差,得到两个相机的中心固定偏差。注:后续俯拍相机拍物料识别得到的偏差以吸嘴中心在俯拍相机中
相机内参标定,相机和激光雷达联合标定一、相机标定原理1.1成像过程1.2标定详解二、相机和激光雷达联合标定2.1标定方法汇总2.2Autoware的安装与运行2.2.1安装方式2.2.2安装Autoware的依赖(Ubuntu16.04/kinetic)2.2.3编译Autoware1.创造工作空间2.下载Autoware源码3.其他依赖4.编译5.效果2.3Autoware标定激光雷达和相机的外参过程一、相机标定原理1.1成像过程现实物体在相机中的成像过程离不开世界坐标系、相机坐标系、图像坐标系以及像素坐标系,只有理解了这些才能对获取的图像进行准确的分析。成像过程:四个坐标系如下图所示:世界
1,Camera基本工作原理答案:光线通过镜头Lens进入摄像头内部,然后经过IRFilter过滤红外光,最后到达sensor(传感器),senor分为按照材质可以分为CMOS和CCD两种,可以将光学信号转换为电信号,再通过内部的ADC电路转换为数字信号,然后传输给DSP(如果有的话,如果没有则以DVP的方式传送数据到基带芯片baseband,此时的数据格式RawData,后面有讲进行加工)加工处理,转换成RGB、YUV等格式输出。数据流是如何从sensor到APP的?上述描述结束后,在ISP处理后面的阶段,数据会进行分流,分为capture,preview,video等以供后续动作使用。例如
项目场景Baumer工业相机堡盟相机是一种高性能、高质量的工业相机,可用于各种应用场景,如物体检测、计数和识别、运动分析和图像处理。 Baumer的万兆网相机拥有出色的图像处理性能,可以实时传输高分辨率图像。此外,该相机还具有快速数据传输、低功耗、易于集成以及高度可扩展性等特点。 Baumer堡盟VCX相机为堡盟全系列相机中的主流常用相机,性能强大、坚固可靠,易于集成,常用与一般行业的检测定位识别使用。问题描述工业相机的触发有多种方式:1.硬件触发:使用外部硬件设备来触发相机,如传感器或开关。2.软件触发:使用软件来触发相机,可以是手动的也可以是自动的。3.同步触发:使相机的触发与其他设备或系
自定义相机起因由于最近用uniapp调用原生相机容易出现闪退问题,找了很多教程又是压缩图片又是优化代码,我表示并没有太大作用!!实现自定义相机使用效果图拓展实现多种自定义相机水印相机身份证相机人像相机起因由于最近用uniapp调用原生相机容易出现闪退问题,找了很多教程又是压缩图片又是优化代码,我表示并没有太大作用!!于是开启了我的解决之路利用livePusher实现实现自定义相机拓展性挺强的,可以实现自定义水印、身份证拍摄、人像拍摄等这里我简单实现一个相机功能主要用于解决闪退Tip:这里需要创建nvue文件哦~创建camera.nvuetemplate> viewclass="pengke-c
虽然我已经将它传递给我的渲染方法,但我为什么要将它添加到场景中?我在存储库中看到的每个示例都将相机添加到场景中,例如weggl_geometries.但是在删除scene.add(camera)之后它仍然有效......初始化函数camera=newTHREE.PerspectiveCamera(45,window.innerWidth/window.innerHeight,1,2000);camera.position.y=400;scene.add(camera);渲染函数renderer.render(scene,camera); 最佳答案
我在看两个例子,一个是Canvas交互对象,另一个是鼠标工具提示。我尝试将两者结合起来在每个单独的立方体上生成文本标签,这就是我目前所拥有的。但是,文本会随着旋转的立方体移动,并且有时会向后或向侧面显示文本。我怎样才能像鼠标工具提示(http://stemkoski.github.io/Three.js/Mouse-Tooltip.html)示例中那样将文本固定在Sprite中?我试图合并Sprite,但我不断收到错误。我不知道该怎么做。你能解释一下我该如何去做吗?谢谢。到目前为止,这是我的代码:three.jscanvas-interactive-cubesbody{font-fam
在three.js中,我试图创建一个纹理,其图像是从相机看到的当前场景。使用CubeCamera来创建类似的效果是有据可查的;我用CubeCamera创建了一个场景示例来说明我的目标:http://stemkoski.github.com/Three.js/Camera-Texture-Almost.html但是,我想使用普通相机(而不是立方体相机)作为纹理。我怎么能这样做? 最佳答案 理想情况下这会起作用。初始化:renderTarget=newTHREE.WebGLRenderTarget(512,512,{format:THR