感兴趣的话大家可以关注一下公众号 : 猿人刘先生 , 欢迎大家一起学习 , 一起进步 , 一起来交流吧!
Elasticsearch(简称ES) 是一个分布式 , RESTful风格的搜索和数据分析引擎 , 使用java开发并且是当前最流行的开源的企业级搜索引擎,能够达到近实时搜索,稳定,可靠,快速,安装使用方便。
客户端支持Java、.NET(C#)、PHP、Python、Ruby等多种语言。
官方网站: https://www.elastic.co/
下载地址:https://www.elastic.co/cn/downloads/past-releases#elasticsearch
演示版本为7.17.3 运行Elasticsearch,需安装并配置JDK
各个版本对Java的依赖 : https://www.elastic.co/support/matrix#matrix_jvm Elasticsearch
5需要Java 8以上的版本 , Elasticsearch 从6.5开始支持Java 11 , 7.0开始,内置了Java环境
https://www.elastic.co/cn/downloads/past-releases#elasticsearch
将下载下来的压缩包放到linux安装的文件下
tar zxvf elasticsearch-7.17.3-linux-x86_64.tar.gz
cd elasticsearch-7.17.3/config
vim elasticsearch.yml
#开启远程访问
network.host: 0.0.0.0
# 建议Xms和Xmx设置成一样 , Xmx不要超过机器的50% ,不要超过30G , jvm.options文件在config目录下
vim jvm.options
# ES不允许使用Root账号启动 , 如果是Root用户则需要新建一个用户
# 为elaticsearch创建用户并赋予相应权限
adduser es
passwd es
chown -R es:es elasticsearch-7.17.3
# 非root用户启动
bin/elasticsearch
# 后台启动
bin/elasticsearch -d
启动之后访问http://ip:9200
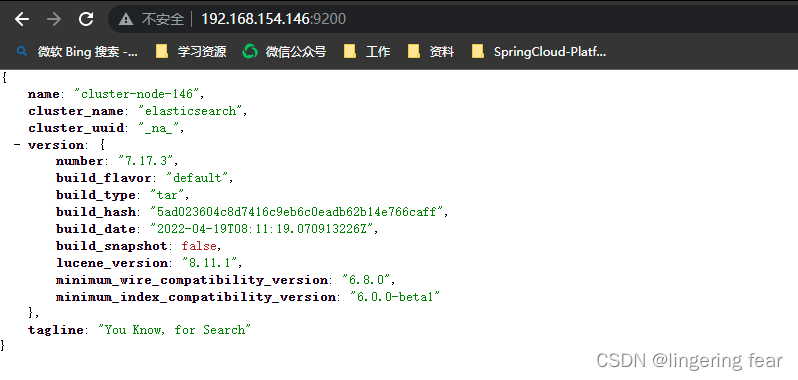
#查看已安装插件
bin/elasticsearch-plugin list
#安装插件
bin/elasticsearch-plugin install analysis-icu
#删除插件
bin/elasticsearch-plugin remove analysis-icu
安装和删除完之后都需要重启es才可以生效
离线安装 ik分词器
本地下载相应的插件,解压,然后手动上传到elasticsearch的plugins目录,然后重启ES实例就可以了。
比如ik中文分词插件:https://github.com/medcl/elasticsearch-analysis-ik (下载zip文件)
POST _analyze
{
"analyzer":"icu_analyzer",
"text":"中华人民共和国"
}
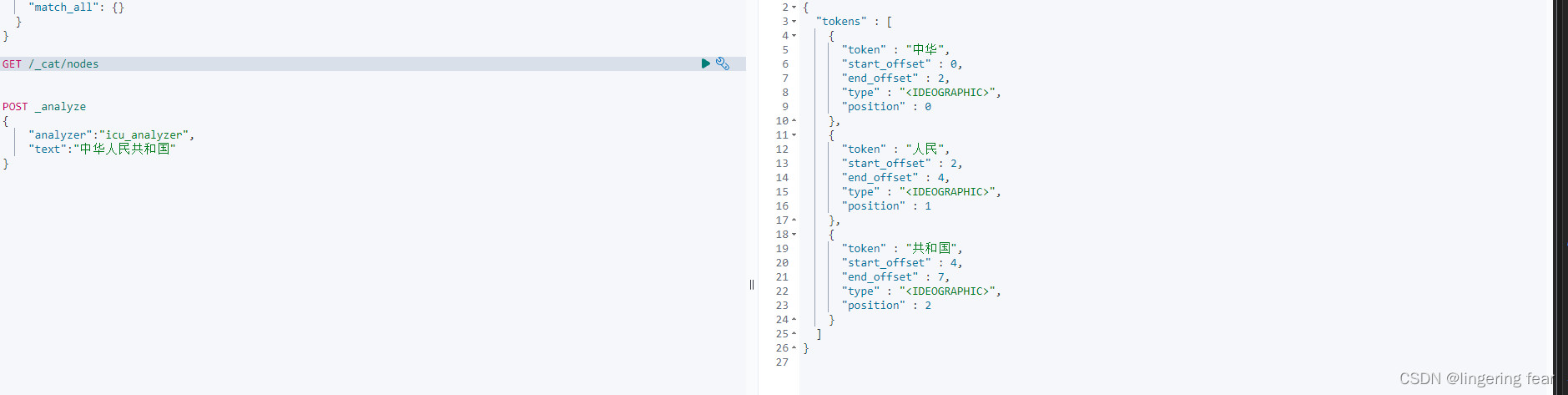
#ES的默认分词设置是standard,会单字拆分
POST _analyze
{
"analyzer":"standard",
"text":"中华人民共和国"
}
#ik_smart:会做最粗粒度的拆
POST _analyze
{
"analyzer": "ik_smart",
"text": "中华人民共和国"
}
#ik_max_word:会将文本做最细粒度的拆分
POST _analyze
{
"analyzer":"ik_max_word",
"text":"中华人民共和国"
}
创建索引时可以指定IK分词器作为默认分词器
PUT /es_db
{
"settings" : {
"index" : {
"analysis.analyzer.default.type": "ik_max_word"
}
}
}
ES因为需要大量的创建索引文件,需要大量的打开系统的文件,所以我们需要解除linux系统当中打开文件最大数目的限制,不然ES启动就会抛错
#切换到root用户
vim /etc/security/limits.conf
末尾添加如下配置:
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096
无法创建本地线程问题,用户最大可创建线程数太小
vim /etc/security/limits.d/20-nproc.conf
改为如下配置:
* soft nproc 4096
vim /etc/sysctl.conf
追加以下内容:
vm.max_map_count=262144
保存退出之后执行如下命令:
sysctl -p
缺少默认配置,至少需要配置discovery.seed_hosts/discovery.seed_providers/cluster.initial_master_nodes中的一个参数.
1.discovery.seed_hosts: 集群主机列表
2.discovery.seed_providers: 基于配置文件配置集群主机列表
3.cluster.initial_master_nodes: 启动时初始化的参与选主的node,生产环境必填
vim config/elasticsearch.yml
#添加配置
discovery.seed_hosts: ["127.0.0.1"]
cluster.initial_master_nodes: ["node-1"]
#或者 单节点(集群单节点)
discovery.type: single-node
# 配置这两个参数即可
node.name: node-1
cluster.initial_master_nodes: ["node-1"]
修改上面的jvm参数即可
本集群基于上面的单节点搭建
切换到root用户 , 执行以下操作
vim /etc/hosts
192.168.154.146 cluster-node-146
192.168.154.147 cluster-node-147
192.168.154.148 cluster-node-148
# 指定集群名称3个节点必须一致
cluster.name: es‐cluster
#指定节点名称,每个节点名字唯一
node.name: cluster-node-146
#是否有资格为master节点,默认为true
node.master: true
#是否为data节点,默认为true
node.data: true
# 绑定ip,开启远程访问,可以配置0.0.0.0
network.host: 0.0.0.0
#指定web端口
#http.port: 9200
#指定tcp端口
#transport.tcp.port: 9300
#用于节点发现
discovery.seed_hosts: ["cluster-node-146", "cluster-node-147", "cluster-node-148"]
#7.0新引入的配置项,初始仲裁,仅在整个集群首次启动时才需要初始仲裁。
#该选项配置为node.name的值,指定可以初始化集群节点的名称
cluster.initial_master_nodes: ["cluster-node-146", "cluster-node-147", "cluster-node-148"]
#解决跨域问题
http.cors.enabled: true
http.cors.allow‐origin: "*"
每个节点的启动方式和单节点启动方式相同
访问http://ip:9200/_cat/nodes?
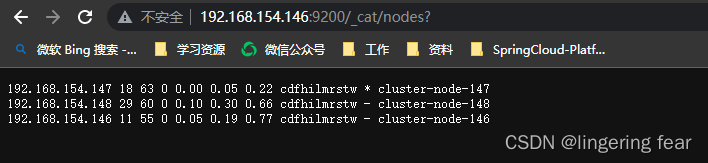
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
我想安装一个带有一些身份验证的私有(private)Rubygem服务器。我希望能够使用公共(public)Ubuntu服务器托管内部gem。我读到了http://docs.rubygems.org/read/chapter/18.但是那个没有身份验证-如我所见。然后我读到了https://github.com/cwninja/geminabox.但是当我使用基本身份验证(他们在他们的Wiki中有)时,它会提示从我的服务器获取源。所以。如何制作带有身份验证的私有(private)Rubygem服务器?这是不可能的吗?谢谢。编辑:Geminabox问题。我尝试“捆绑”以安装新的gem..
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
最近,当我启动我的Rails服务器时,我收到了一长串警告。虽然它不影响我的应用程序,但我想知道如何解决这些警告。我的估计是imagemagick以某种方式被调用了两次?当我在警告前后检查我的git日志时。我想知道如何解决这个问题。-bcrypt-ruby(3.1.2)-better_errors(1.0.1)+bcrypt(3.1.7)+bcrypt-ruby(3.1.5)-bcrypt(>=3.1.3)+better_errors(1.1.0)bcrypt和imagemagick有关系吗?/Users/rbchris/.rbenv/versions/2.0.0-p247/lib/ru
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo
我是Google云的新手,我正在尝试对其进行首次部署。我的第一个部署是RubyonRails项目。我基本上是在关注thisguideinthegoogleclouddocumentation.唯一的区别是我使用的是我自己的项目,而不是他们提供的“helloworld”项目。这是我的app.yaml文件runtime:customvm:trueentrypoint:bundleexecrackup-p8080-Eproductionconfig.ruresources:cpu:0.5memory_gb:1.3disk_size_gb:10当我转到我的项目目录并运行gcloudprevie
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
您如何在Rails中的实时服务器上进行有效调试,无论是在测试版/生产服务器上?我试过直接在服务器上修改文件,然后重启应用,但是修改好像没有生效,或者需要很长时间(缓存?)我也试过在本地做“脚本/服务器生产”,但是那很慢另一种选择是编码和部署,但效率很低。有人对他们如何有效地做到这一点有任何见解吗? 最佳答案 我会回答你的问题,即使我不同意这种热修补服务器代码的方式:)首先,你真的确定你已经重启了服务器吗?您可以通过跟踪日志文件来检查它。您更改的代码显示的View可能会被缓存。缓存页面位于tmp/cache文件夹下。您可以尝试手动删除
我可以在Azure网站上部署RubyonRails吗? 最佳答案 还没有。目前仅支持.NET和PHP。 关于ruby-on-rails-RubyonRails可以部署在Azure网站上吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/12964010/
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt