

这么可爱的猫猫不值得点个赞吗😽😻
目录
链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表
中的指针链接次序实现的
链表其实有很多种类:
1.单向 双向
2.带头 不带头
3.循环 不循环
其中共能组合出8种形式的链表;
这篇文章讲的是结构最简单的链表,也就是单向不带头不循环链表,即单链表。
单链表中的元素称为节点,节点有一个数据data,还有一个结构体指针next 存储下一个节点的地址,最后一个节点的next是NULL。


typedef int SLdatatype; //对数据类型重定义,方便后续更改
typedef struct SListNode
{
SLdatatype data;
struct SListNode* next;
}SLNode;想要实现尾插,就要先找到尾节点,但要注意,当链表是空时,就没有尾节点,这个时候直接插入就行了;
我们可以申请一个新的节点newnode,然后插入链表中,由于尾插和头插都需要申请新的节点,所以我们可以将这封装成一个函数;
注意,不管是尾插还是头插,最后都会使链表发生改变,所以我们要传二级指针进去。
找尾节点时,while里的循环条件要写成 tail->next !=NULL
请看逻辑结构:
申请新节点 BuySListNode
SLNode* BuySListNode(SLdatatype x)
{
SLNode* newnode = (SLNode*)malloc(sizeof(SLNode));
assert(newnode);
newnode->data = x; //x是要插入的数据
newnode->next = NULL;
return newnode;
}尾插 SListpushback

void SListpushback(SLNode** pphead,SLdatatype x) //注意传的是二级指针
{
SLNode* newnode = BuySListNode(x);
if (*pphead == NULL) //判断链表是否为空
{
*pphead = newnode;
}
else
{
SLNode* tail = *pphead; //寻找尾节点
while (tail->next != NULL) //注意这里不能写成 while(tail!=NULL)
{
tail = tail->next;
}
tail->next = newnode;
}
}头插时只需让新节点的 next 指向旧的头节点,然后再把 newnode 赋给头节点,使之成为新的头节点,即使是空表也没关系,newnode 会直接成为头节点。
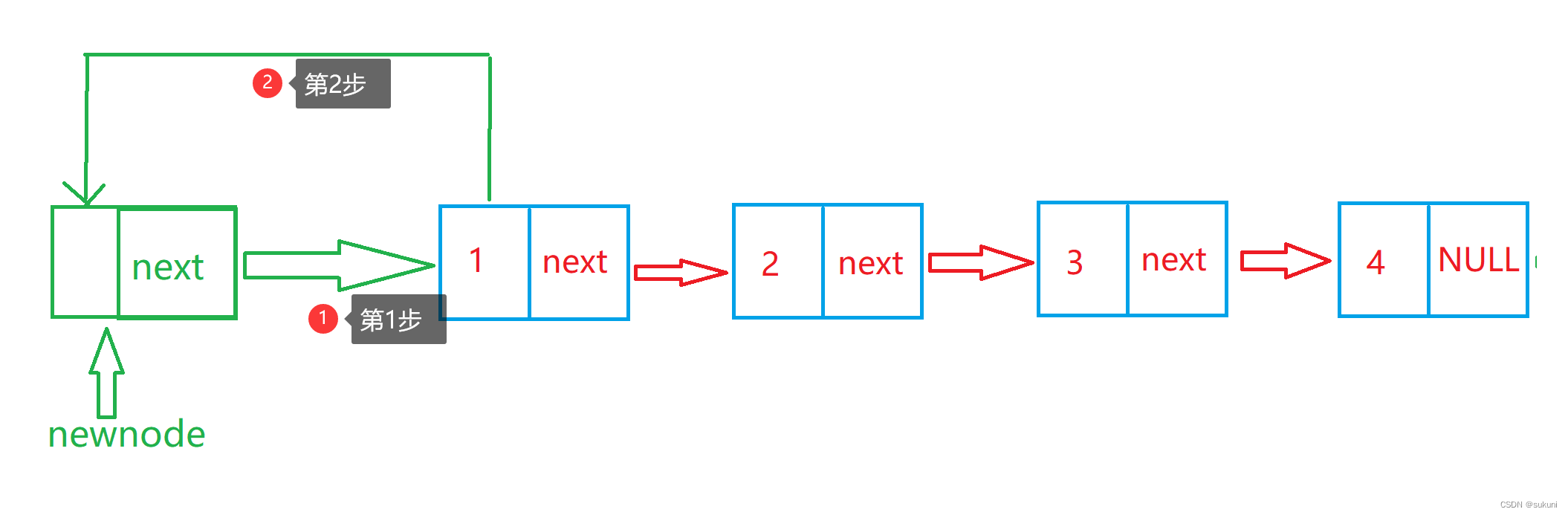
void SListpushfront(SLNode** pphead, SLdatatype x)
{
SLNode* newnode = BuySListNode(x);
newnode->next = *pphead;
*pphead = newnode;
}尾删前,我们需要判断:
1.若为空表,则直接结束函数;
2.若链表中只有一个节点,则直接 free 头节点,然后置为NULL;
3.寻找尾节点 tail 和尾节点的前一个节点 pre ,因为我们释放掉尾节点后,pre就成为了新的尾节点,而尾节点的 next 是 NULL ,所以我们需要找到尾节点的前一个节点。
找尾的方法和之前的一样。
void SListpopback(SLNode** pphead)
{
if (*pphead == NULL)
{
return;
}
else if ((*pphead)->next == NULL) //注意这里因为优先级的问题,*pphead 要打括号
{
free(*pphead);
*pphead = NULL;
}
else
{
SLNode* pre = NULL;
SLNode* tail = *pphead;
while (tail->next != NULL)
{
pre = tail; //记录 tail 的前一个节点
tail = tail->next;
}
pre->next = NULL; //next 置为NULL
}
}在头删前:
1.判断是否为空表;
2.定义一个 next 用来保存头节点中的 next ,释放完后,这个 next 就成为了新的头节点。
void SListpopfront(SLNode** pphead)
{
if (*pphead == NULL)
{
return;
}
else
{
SLNode* next = (*pphead)->next;
free(*pphead);
*pphead = next;
}
}在插入和释放前,都需要调用 find 函数,来找到希望插入或是释放的位置。
SLNode* SListfind(SLNode* phead, SLdatatype x)
{
SLNode* pos = phead;
while (pos)
{
if (pos->data == x)
{
return pos;
}
pos = pos->next;
}
}如果是链表中只有一个节点,就变成了头插,只需要调用头插函数就行了,如果是空表也不用担心,可以设置成不调用函数;
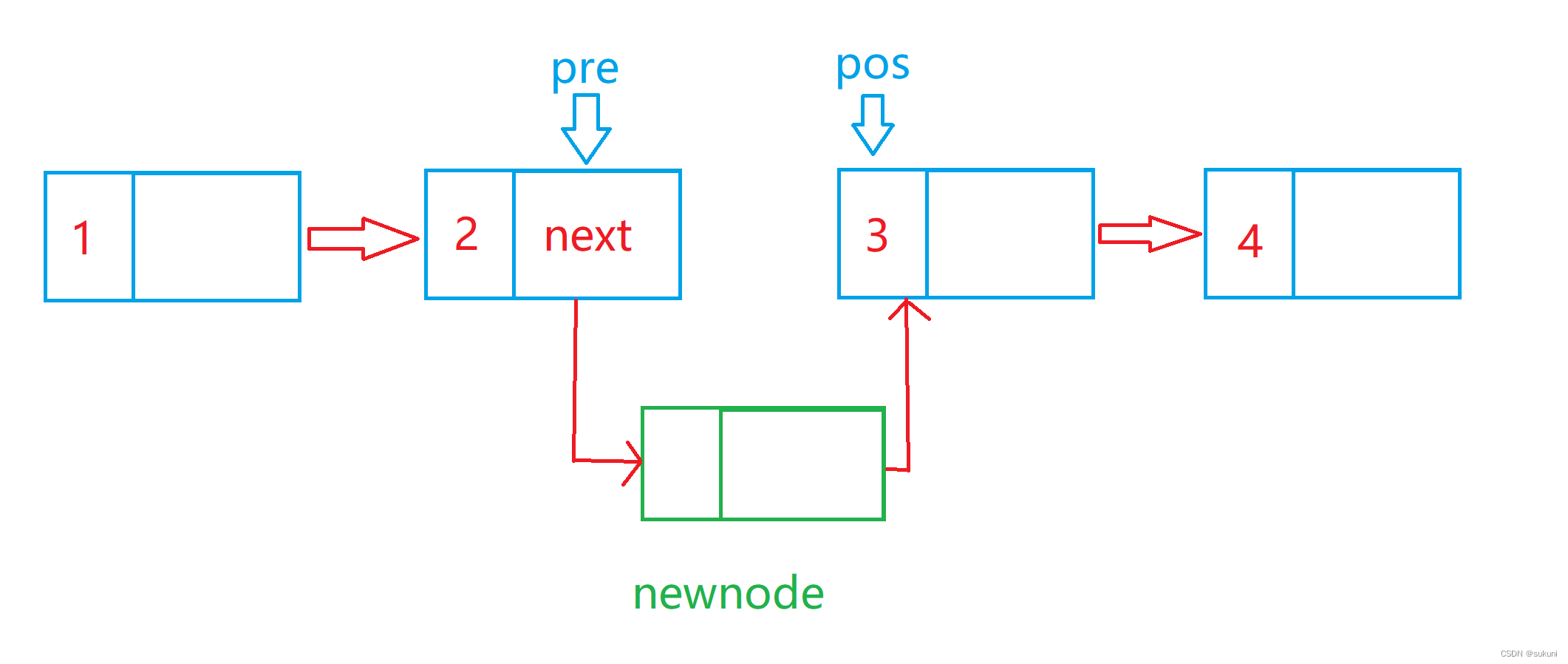
在插入前,需要找到指定位置 pos 的前驱 pre,
使pre->next=newnode , newnode->next=pos
如图所示,假设在3的前一个位置插入数据:
void SListinsert(SLNode** pphead, SLNode* pos,SLdatatype x)
{
SLNode* newnode = BuySListNode(x);
if (pos->next == NULL)
{
SListpushfront(pphead, x);
}
else
{
SLNode* pre = *pphead;
while (pre->next != pos)
{
pre = pre->next;
}
pre->next = newnode;
newnode->next = pos;
}
}释放前:
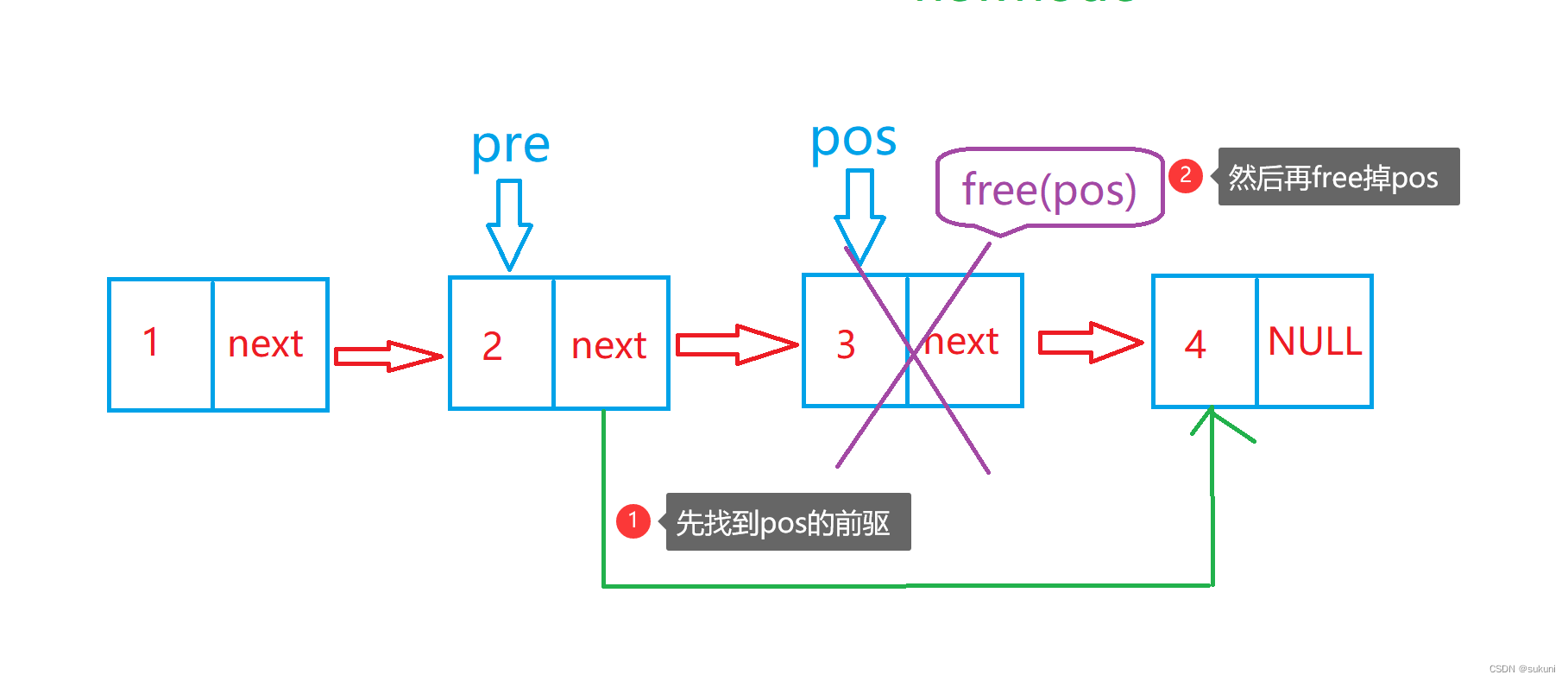
1.如果只有一个节点,则直接释放头节点,再置为空即可;
2.如果不止一个节点,还需找到要释放的位置的前一个节点 pre ,将 pre 的 next 指向 pos 的next,然后再释放;
如图所示,假设要释放掉3这个节点:
void SListerase(SLNode** pphead, SLNode* pos, SLdatatype x)
{
if (pos->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
else
{
SLNode* pre = *pphead;
while (pre->next !=pos)
{
pre = pre->next;
}
pre->next = pos->next;
free(pos);
}
}虽然可以直接用头节点 phead 遍历,但博主还是推荐定义一个新的结构体指针 cur ,把phead 的值赋给 cur ,会显得更优雅;
注意这里的 while 里的式子要写成 cur ,如果 写成 cur->next ,那么最终打印出来的结果会少一个节点的数据。
void SListprint(SLNode* phead)
{
SLNode* cur = phead;
while (cur != NULL)
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL\n");
}#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
typedef int SLdatatype;
typedef struct SListNode
{
SLdatatype data;
struct SListNode* next;
}SLNode;
void SListprint(SLNode* phead); //打印
void SListpushback(SLNode** pphead,SLdatatype x); //尾插
void SListpushfront(SLNode** pphead, SLdatatype x); //头插
void SListpopfront(SLNode** pphead); //头删
void SListpopback(SLNode** pphead); //尾删
SLNode* SListfind(SLNode* phead,SLdatatype x); //查找
void SListinsert(SLNode** pphead, SLNode* pos,SLdatatype x); //插入
void SListerase(SLNode** pphead, SLNode* pos, SLdatatype x); //释放#define _CRT_SECURE_NO_WARNINGS
#include "SList.h"
void SListprint(SLNode* phead)
{
SLNode* cur = phead;
while (cur != NULL)
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL\n");
}
SLNode* BuySListNode(SLdatatype x)
{
SLNode* newnode = (SLNode*)malloc(sizeof(SLNode));
assert(newnode);
newnode->data = x;
newnode->next = NULL;
return newnode;
}
void SListpushback(SLNode** pphead,SLdatatype x)
{
SLNode* newnode = BuySListNode(x);
if (*pphead == NULL)
{
*pphead = newnode;
}
else
{
SLNode* tail = *pphead; //寻找尾节点
while (tail->next != NULL)
{
tail = tail->next;
}
tail->next = newnode;
}
}
void SListpushfront(SLNode** pphead, SLdatatype x)
{
SLNode* newnode = BuySListNode(x);
newnode->next = *pphead;
*pphead = newnode;
}
void SListpopfront(SLNode** pphead)
{
if (*pphead == NULL)
{
return;
}
else
{
SLNode* next = (*pphead)->next;
free(*pphead);
*pphead = next;
}
}
void SListpopback(SLNode** pphead)
{
if (*pphead == NULL)
{
return;
}
else if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
else
{
SLNode* pre = NULL;
SLNode* tail = *pphead;
while (tail->next != NULL)
{
pre = tail;
tail = tail->next;
}
pre->next = NULL;
}
}
SLNode* SListfind(SLNode* phead, SLdatatype x)
{
SLNode* pos = phead;
while (pos)
{
if (pos->data == x)
{
return pos;
}
pos = pos->next;
}
}
void SListinsert(SLNode** pphead, SLNode* pos,SLdatatype x)
{
SLNode* newnode = BuySListNode(x);
if (pos->next == NULL)
{
SListpushfront(pphead, x);
}
else
{
SLNode* pre = *pphead;
while (pre->next != pos)
{
pre = pre->next;
}
pre->next = newnode;
newnode->next = pos;
}
}
void SListerase(SLNode** pphead, SLNode* pos, SLdatatype x)
{
if (pos->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
else
{
SLNode* pre = *pphead;
while (pre->next !=pos)
{
pre = pre->next;
}
pre->next = pos->next;
free(pos);
}
}博主写的主函数只是用来测试单链表的,写起主函数来也不难,大家可以自行编写。
#include "SList.h"
void testSList1()
{
SLNode* plist = NULL;
SListpushback(&plist,1);
SListpushback(&plist,2);
SListpushback(&plist,3);
SListpushback(&plist,4);
SListprint(plist);
SListpushfront(&plist, 0);
SListprint(plist);
SListpopfront(&plist);
SListpopfront(&plist);
SListpopfront(&plist);
SListprint(plist);
SListpopback(&plist);
SListpopback(&plist);
SListpopback(&plist);
SListprint(plist);
}
void testSList2()
{
SLNode* plist = NULL;
SListpushback(&plist, 1);
SListpushback(&plist, 2);
SListpushback(&plist, 3);
SListpushback(&plist, 4);
SLNode* pos = SListfind(plist, 3);
if (pos)
{
SListinsert(&plist,pos, 20);
SListprint(plist);
}
pos = SListfind(plist, 2);
if (pos)
{
SListerase(&plist,pos,2);
SListprint(plist);
}
}
int main()
{
//testSList1();
testSList2();
return 0;
}在单链表中,要想找到某一个数据,就需要从头节点开始,所以单链表是非随机存取的存储结构,且要想对单链表进行一些操作,总是要找到前驱节点,有时还需判断一些特殊情况,有什么办法能解决这些问题呢?
博主将在下篇双向带头循环链表中讲解,敬情期待~
🤩🥰本篇文章到此就结束了,如有错误或是建议,欢迎小伙伴们提出~😍😃
🐲👻希望可以多多支持博主哦~🥰😍
🤖🐯谢谢你的阅读~👻🦁

我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
