短时傅里叶变换公式
S
(
m
,
k
)
=
∑
n
=
1
N
−
1
x
(
n
+
m
H
)
w
(
n
)
e
−
i
2
π
k
N
n
S(m,k) = \sum_{n=1}^{N-1} x(n+mH)w(n)e^{-i2 \pi \frac{k}{N} n}
S(m,k)=n=1∑N−1x(n+mH)w(n)e−i2πNkn
其中,m是当前滤波器的序号,表征了当前的时间段,k是当前频率的序号,表征了当前正在对哪一频率的
e
−
i
2
π
k
N
n
e^{-i2 \pi \frac{k}{N} n}
e−i2πNkn 信号,寻找最佳的振幅和初相,w(n)是窗函数。更多关于短时傅里叶变换的知识,请参考深入理解傅里叶变换(四)。
本文要讲解的梅尔时频谱图,需要有时频谱图的知识,也可参考深入理解傅里叶变换(四)。
人耳对音高(pitch)的感知是非线性的,当声音频率线性增加时,我们不会感觉音高也是线性增加的。为了将人耳对音高的线性感知刻画出来,我们需要梅尔刻度,梅尔刻度本质上是关于频率的函数,将赫兹(Hz)映射为梅尔(mel):
m
=
2595
l
o
g
10
(
1
+
f
700
)
=
1127
l
n
(
1
+
f
700
)
m = 2595 log_{10}(1+\frac{f}{700}) = 1127 ln(1+\frac{f}{700})
m=2595log10(1+700f)=1127ln(1+700f)
从公式可见,对数部分可以以自然对数为底数,也可以以10为底数,不同的底数对应不同的系数,要确定当前的系数,只需要代入(1000Hz, 1000mel)即可。
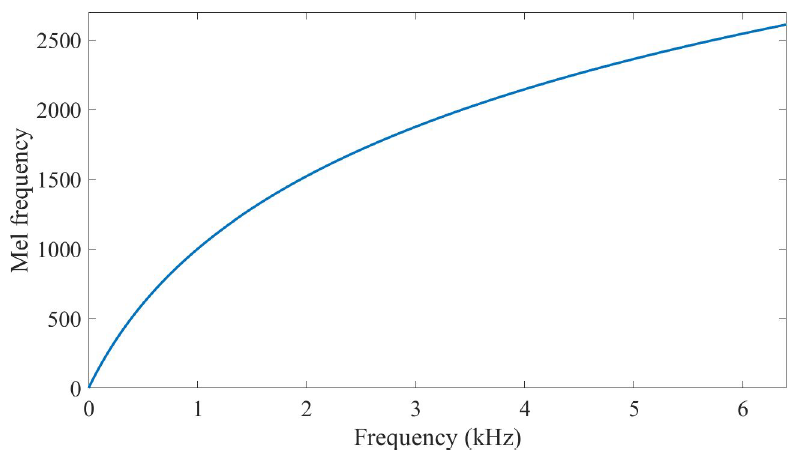
我们不仅好奇,既然人耳对音高的感知是非线性的,为什么梅尔刻度会过(1000Hz, 1000mel)这个点呢?原因是人耳对低频部分的感知是近似线性的,这个低频部分大概是0Hz~1000Hz,因此梅尔刻度也过(0Hz, 0mel)点,梅尔刻度图上也可看出该低频部分是近似线性的:
从梅尔刻度到赫兹的映射如下:
f
=
700
(
1
0
m
2595
−
1
)
=
700
(
e
m
1127
−
1
)
f = 700(10^{\frac{m}{2595}}-1) = 700(e^{\frac{m}{1127}}-1)
f=700(102595m−1)=700(e1127m−1)
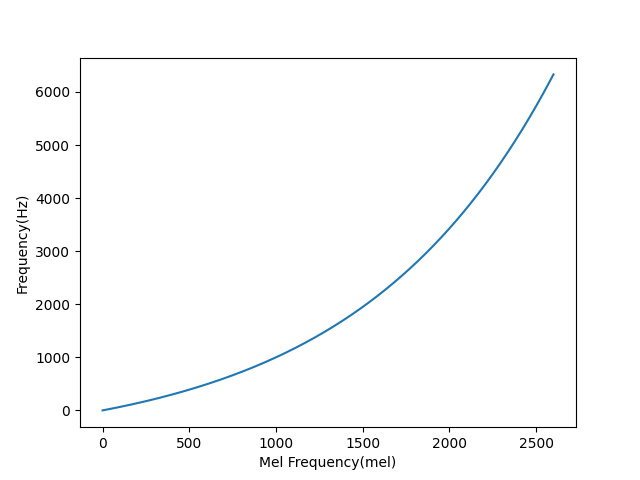
现在,当梅尔刻度线性增加,赫兹呈现对数增加,人耳对这样变化的音高的感知是线性的。
梅尔时频谱图(Mel spectrogram)是同时考虑了三个要素,而绘制出来的:
使用梅尔滤波器组的步骤有三:
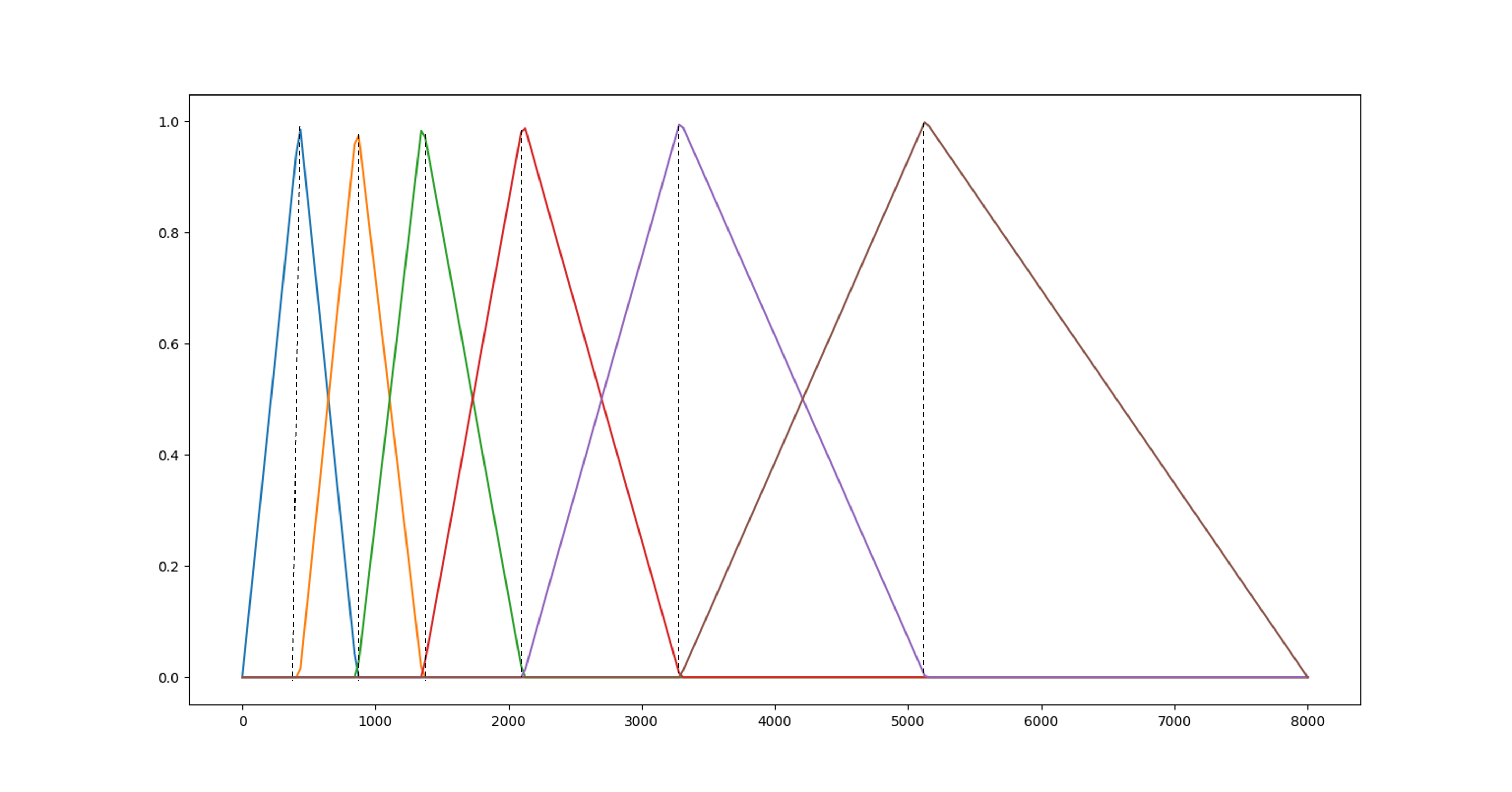
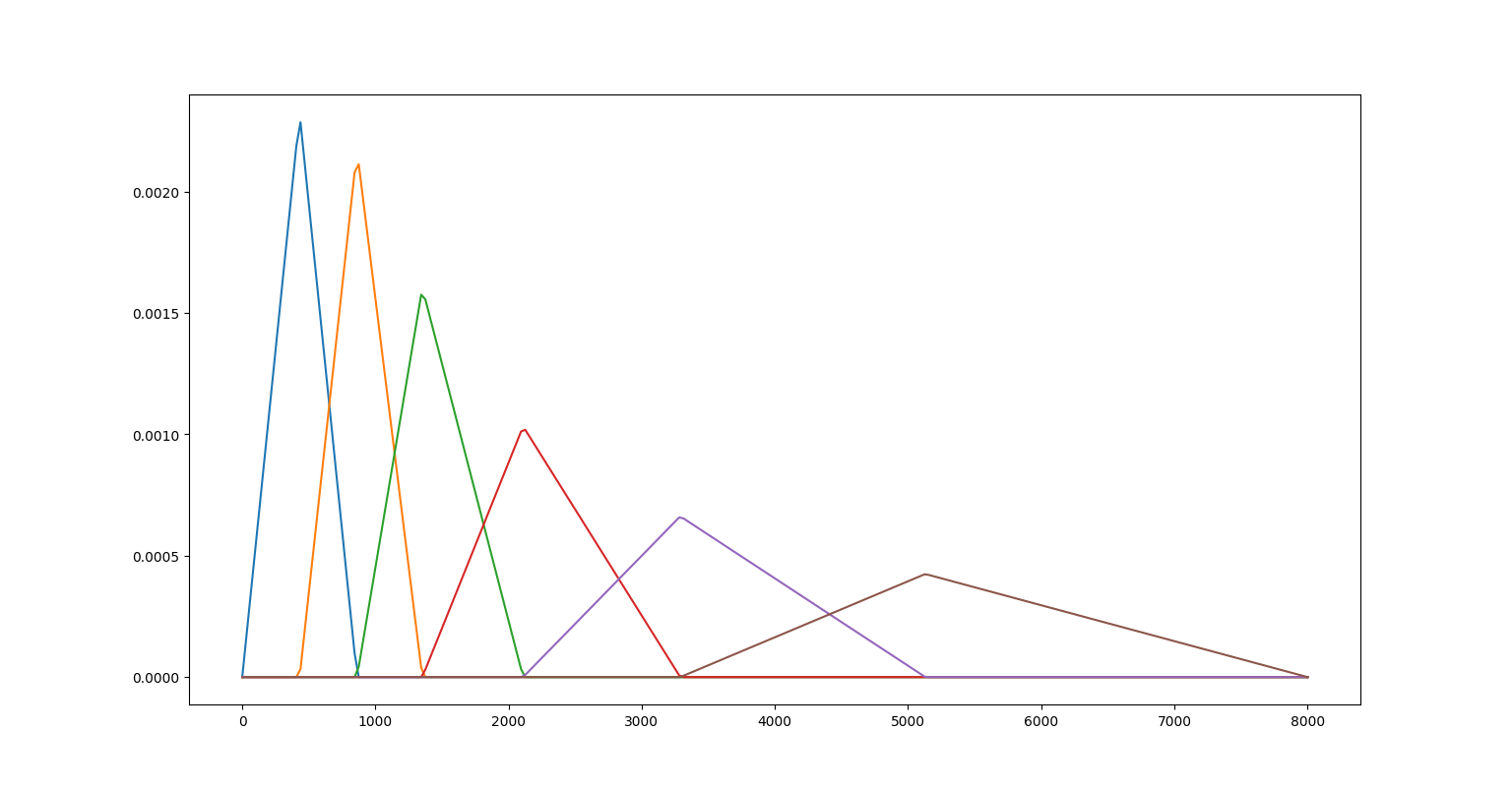
读取一段音频,使用短时傅里叶变换,得到普通的时频谱图,然后绘制梅尔滤波器组,值得注意的是,librosa的梅尔滤波器组函数还带有权重归一化功能,即对一个三角形滤波器的每个权重,都除以该三角形的面积,如果不希望进行该归一化,设置参数 norm=None,即 melfb = librosa.filters.mel(sr=sr, n_fft=N_FFT, n_mels=N_MELS, norm=None)。
import librosa
import librosa.display
import matplotlib.pyplot as plt
import numpy as np
if "__main__" == __name__:
debussy_path = r"16 - Extracting Spectrograms from Audio with Python\audio\debussy.wav"
signal, sr = librosa.load(path=debussy_path, sr=16000)
N_FFT = 512
N_MELS = 6
stft = librosa.stft(y=signal,
n_fft=N_FFT,
hop_length=sr // 100,
win_length=sr // 40)
freq = librosa.fft_frequencies(sr=sr, n_fft=N_FFT)
power, phase = librosa.magphase(stft, power=2)
melfb = librosa.filters.mel(sr=sr, n_fft=N_FFT, n_mels=N_MELS)
plt.plot(freq, np.transpose(melfb))
plt.show()
直接矩阵乘积,然后将振幅的平方转为分贝,绘制梅尔时频谱图,注意一定要先滤波,再转分贝。
import librosa
import matplotlib.pyplot as plt
import librosa.display
import numpy as np
if "__main__" == __name__:
# m = np.linspace(0, 2600, 2600 + 1)
# f = 700 * (np.exp(m / 1127) - 1)
# plt.plot(m, f)
# plt.xlabel("Mel Frequency(mel)")
# plt.ylabel("Frequency(Hz)")
debussy_path = r"16 - Extracting Spectrograms from Audio with Python\audio\debussy.wav"
signal, sr = librosa.load(path=debussy_path, sr=16000)
N_FFT = 512
N_MELS = 6
stft = librosa.stft(y=signal,
n_fft=N_FFT,
hop_length=sr // 100,
win_length=sr // 40)
freq = librosa.fft_frequencies(sr=sr, n_fft=N_FFT)
power, phase = librosa.magphase(stft, power=2)
melfb = librosa.filters.mel(sr=sr, n_fft=N_FFT, n_mels=N_MELS)
# plt.plot(freq, np.transpose(melfb))
melspec = np.matmul(melfb, power)
melspec_db = librosa.power_to_db(melspec)
# plt.subplot(2, 1, 1)
librosa.display.specshow(melspec_db,
sr=sr,
n_fft=N_FFT,
hop_length=sr // 100,
win_length=sr // 40,
x_axis="s",
y_axis="mel")
plt.colorbar(format="%+2.f db")
plt.show()
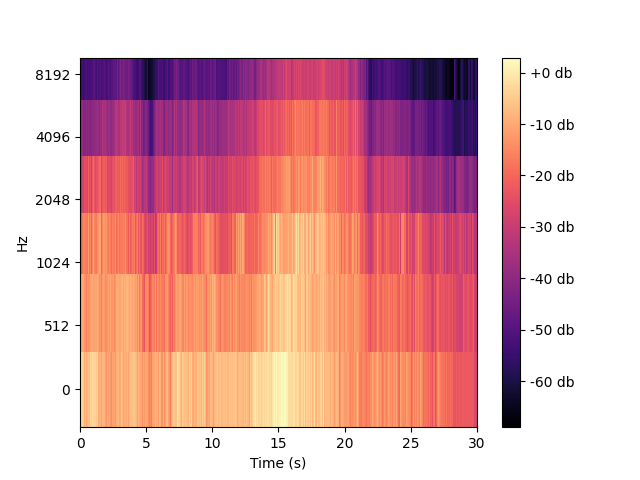
自己按照理论绘制的结果与librosa直接绘制的结果一致:
import librosa
import matplotlib.pyplot as plt
import librosa.display
import numpy as np
if "__main__" == __name__:
# m = np.linspace(0, 2600, 2600 + 1)
# f = 700 * (np.exp(m / 1127) - 1)
# plt.plot(m, f)
# plt.xlabel("Mel Frequency(mel)")
# plt.ylabel("Frequency(Hz)")
debussy_path = r"16 - Extracting Spectrograms from Audio with Python\audio\debussy.wav"
signal, sr = librosa.load(path=debussy_path, sr=16000)
N_FFT = 512
N_MELS = 6
stft = librosa.stft(y=signal,
n_fft=N_FFT,
hop_length=sr // 100,
win_length=sr // 40)
freq = librosa.fft_frequencies(sr=sr, n_fft=N_FFT)
power, phase = librosa.magphase(stft, power=2)
melfb = librosa.filters.mel(sr=sr, n_fft=N_FFT, n_mels=N_MELS)
# plt.plot(freq, np.transpose(melfb))
melspec = np.matmul(melfb, power)
melspec_db = librosa.power_to_db(melspec)
plt.subplot(2, 1, 1)
librosa.display.specshow(melspec_db,
sr=sr,
n_fft=N_FFT,
hop_length=sr // 100,
win_length=sr // 40,
x_axis="s",
y_axis="mel")
plt.colorbar(format="%+2.f db")
S = librosa.feature.melspectrogram(y=signal,
sr=sr,
n_fft=N_FFT,
hop_length=sr // 100,
win_length=sr // 40,
n_mels=N_MELS)
S_dB = librosa.power_to_db(S)
plt.subplot(2, 1, 2)
librosa.display.specshow(S_dB,
sr=sr,
n_fft=N_FFT,
hop_length=sr // 100,
win_length=sr // 40,
x_axis="s",
y_axis="mel")
plt.colorbar(format="%+2.f db")
np.testing.assert_array_almost_equal(S_dB, melspec_db)
plt.show()
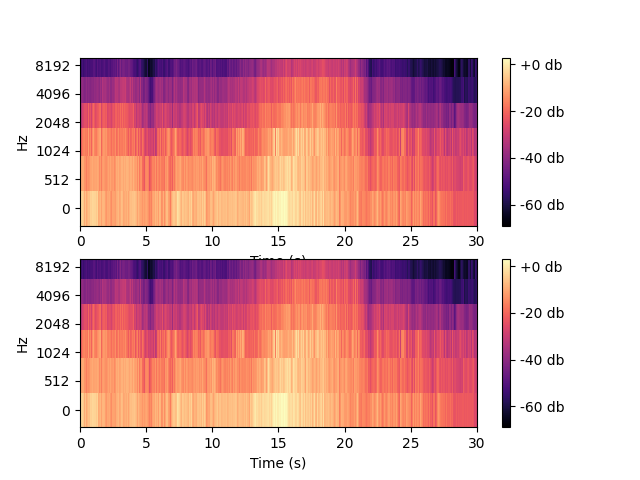
梅尔时频谱图是广为使用的音频特征。
下一节讲MFCC,梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficient, MFCC)。
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。我们不允许提问寻求书籍、工具、软件库等的推荐。您可以编辑问题,以便用事实和引用来回答。关闭3年前。Improvethisquestion我正处于学习Ruby的阶段,我想查看一些小型库的源代码以了解它们是如何构建的。我不知道什么是小型图书馆,但希望SO能推荐一些易于理解的图书馆来学习。因此,如果有人知道一两个非常小的库,这是新手Rubyists学习的好例子,请推荐!我想使用Manveru'sInnatelib,因为它试图保持在2000LOC以下,但我还不熟悉其中经常使用的Ruby速记。也许大约100-5
由于匿名block和散列block看起来大致相同。我正在玩它。我做了一些严肃的观察,如下所示:{}.class#=>Hash好的,这很酷。空block被视为Hash。print{}.class#=>NilClassputs{}.class#=>NilClass为什么上面的代码和NilClass一样,下面的代码又显示了Hash?puts({}.class)#Hash#=>nilprint({}.class)#Hash=>nil谁能帮我理解上面发生了什么?我完全不同意@Lindydancer的观点你如何解释下面几行:print{}.class#NilClassprint[].class#A
我很难理解Ruby中sender和receiver的实际含义。它们一般是什么意思?到目前为止,我只是将它们理解为方法调用和获取其返回值的调用。但是,我知道我的理解还远远不够。谁能给我一个Ruby中发送者和接收者的具体解释? 最佳答案 面向对象中的一个核心概念是消息传递和早期概念化,这在很大程度上借鉴了计算的Actor模型。艾伦·凯(AlanKay)创造了面向对象一词并发明了最早的OO语言之一SmallTalk,他拥有voicedregretatusingatermwhichputthefocusonobjectsinsteadofo
rails新手。只是想了解\assests目录中的这两个文件。例如,application.js文件有如下行://=requirejquery//=requirejquery_ujs//=require_tree.我理解require_tree。只是将所有JS文件添加到当前目录中。根据上下文,我可以看出requirejquery添加了jQuery库。但是它从哪里得到这些jQuery库呢?我没有在我的Assets文件夹中看到任何jquery.js文件——或者直接在我的整个应用程序中没有看到任何jquery.js文件?同样,我正在按照一些说明安装TwitterBootstrap(http:
我在某些代码中遇到了三元组,但我无法理解条件:str.split(/',\s*'/).mapdo|match|match[0]==?,?match:"somestring"end.join我确实理解我是在某些点上拆分字符串并将总结果转换为数组,然后依次处理数组的每个元素。除此之外,我不知道发生了什么。 最佳答案 一种(稍微)不那么令人困惑的写法是:str.split(/',\s*'/).mapdo|match|ifmatch[0]==?,matchelse"somestring"endend.join我认为多行三元语句很糟糕,尤其是
有没有人成功地将S3存储桶读取为子文件夹?文件夹1--子文件夹2----文件3----文件4--文件1--文件2文件夹2--子文件夹3--文件5--文件6我的任务是读取文件夹1。我希望看到子文件夹2、文件1和文件2,但看不到文件3或文件4。现在,因为我将存储桶键限制为prefix=>'folder1/',你仍然会得到file3和4,因为它们在技术上具有folder1前缀。似乎真正做到这一点的唯一方法是吸收folder1下的所有键,然后使用字符串搜索从结果数组中实际排除file3和file4。有没有人有过这方面的经验?我知道像Transmit和Cyberduck这样的FTP风格的S3
关于yolov5训练时参数workers和batch-size的理解yolov5训练命令workers和batch-size参数的理解两个参数的调优总结yolov5训练命令python.\train.py--datamy.yaml--workers8--batch-size32--epochs100yolov5的训练很简单,下载好仓库,装好依赖后,只需自定义一下data目录中的yaml文件就可以了。这里我使用自定义的my.yaml文件,里面就是定义数据集位置和训练种类数和名字。workers和batch-size参数的理解一般训练主要需要调整的参数是这两个:workers指数据装载时cpu所使