目录
2.3.1 主键自增进行增量同步(MySQL->MySQL)
2.3.2 时间自增进行增量同步(MySQL->MySQL)
1、mysql <-> mysql <-> hive <-> hive
DataX 是阿里云DataWorks数据集成的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX 实现了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS 等各种异构数据源之间高效的数据同步功能。
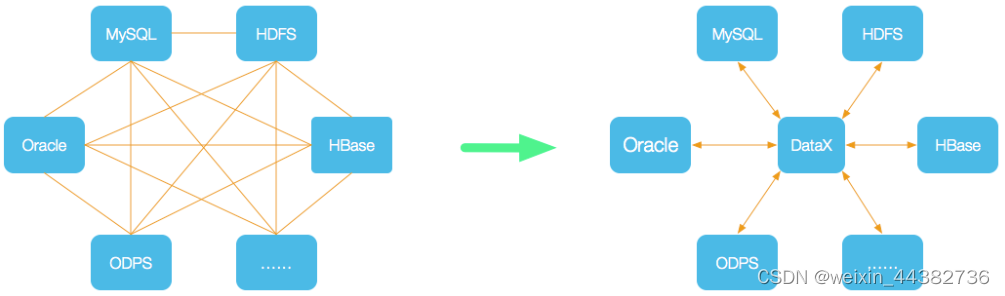
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。

DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
| 类型 | 数据源 | Reader(读) | Writer(写) | 文档 |
| RDBMS 关系型数据库 | MySQL | √ | √ | |
| Oracle | √ | √ | ||
| OceanBase | √ | √ | ||
| SQLServer | √ | √ | ||
| PostgreSQL | √ | √ | ||
| DRDS | √ | √ | ||
| 达梦 | √ | √ | ||
| 通用RDBMS(支持所有关系型数据库) | √ | √ | ||
| 阿里云数仓数据存储 | ODPS | √ | √ | |
| ADS |
| √ | ||
| OSS | √ | √ | ||
| OCS | √ | √ | ||
| NoSQL数据存储 | OTS | √ | √ | |
| Hbase0.94 | √ | √ | ||
| Hbase1.1 | √ | √ | ||
| MongoDB | √ | √ | ||
| Hive | √ | √ | ||
| 无结构化数据存储 | TxtFile | √ | √ | |
| FTP | √ | √ | ||
| HDFS | √ | √ | ||
| Elasticsearch |
| √ |
1、可靠的数据质量监控
1)完美解决数据传输个别类型失真问题
2)提供作业全链路的流量、数据量运行时监控
3)提供脏数据探测
2、丰富的数据转换功能
3、精准的速度控制
4、强劲的同步性能
5、健壮的容错机制
6、极简的使用体验
DataX Web是在DataX之上开发的分布式数据同步工具,提供简单易用的 操作界面,降低用户使用DataX的学习成本,缩短任务配置时间,避免配置过程中出错。用户可通过页面选择数据源即可创建数据同步任务,支持RDBMS、Hive、HBase、ClickHouse、MongoDB等数据源,RDBMS数据源可批量创建数据同步任务,支持实时查看数据同步进度及日志并提供终止同步功能,集成并二次开发,可根据时间、自增主键增量同步数据。
任务"执行器"支持集群部署,支持执行器多节点路由策略选择,支持超时控制、失败重试、失败告警、任务依赖,执行器CPU、内存、负载的监控等等。数据转换UDF、表结构同步、数据同步血缘等更为复杂的业务场景。
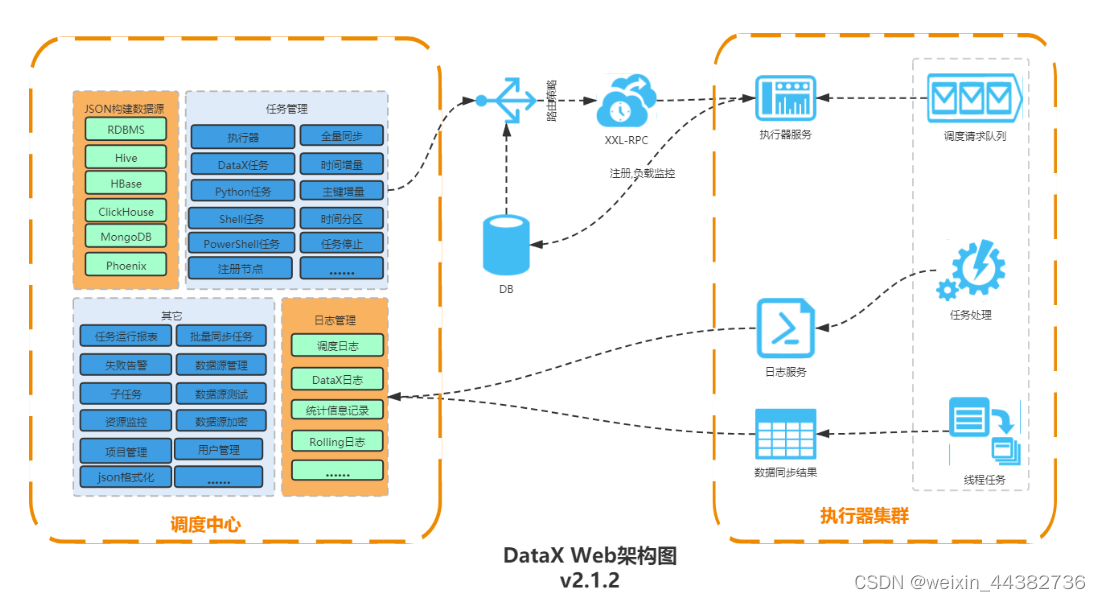
简单来说用户可以通过图形化web,构建DataX Json,可以轻松调度各Job启停,DataX-Web也提供了诸如阻塞处理、超时警告等等功能辅助生产,对于少量数据同步任务,DataX-Web完全可以胜任,并且大大减少了工作量。
从github(https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202210/datax.tar.gz)
下载安装包或者下载源码打包(在这里使用下载安装包的方式),上传到服务器运行tar –zxvf安装
datax/job文件夹下自带一个简单job任务,可以以此测试是否安装成功,
python /usr/datax/bin/datax.py ../job/job.json。具体使用在后文中介绍。

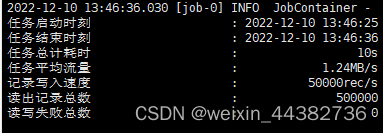
(1)Description:[DataX引擎配置错误,该问题通常是由于DataX安装错误引起,请联系您的运维解决.].- 获取作业配置信息失败:/usr/datax/job/job,json - java.io.FileNotFoundException: File '/usr/datax/job/job,json' does not exist
rm -rf /usr/datax/plugin/*/._* 删除插件文件夹中的隐藏文件
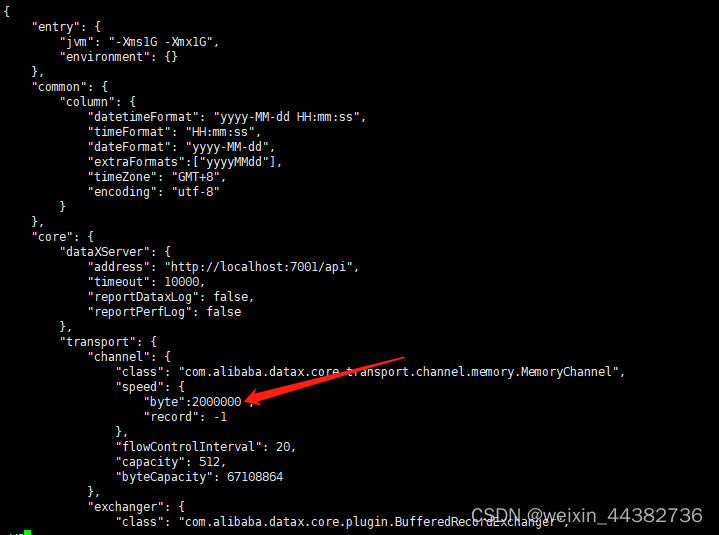
(2)Description:[DataX引擎配置错误,该问题通常是由于DataX安装错误引起,请联系您的运维解决.]. - 在有总bps限速条件下,单个channel的bps值不能为空,也不能为非正数
修改datax/conf/core.json, core -> transport -> channel -> speed -> "byte": 2000000,将单个channel的大小改为2MB即可。

(1)MySQL (5.5+) 必选,对应客户端可以选装, Linux服务上若安装mysql的客户端可以通过部署脚本快速初始化数据库
(2)JDK (1.8.0_xxx) 必选
(3)Maven (3.6.1+) 必选
(4)DataX 必选
(5)Python (2.x) (支持Python3需要修改替换datax/bin下面的三个python文件,替换文件在doc/datax-web/datax-python3下) 必选,主要用于调度执行底层DataX的启动脚本,默认的方式是以Java子进程方式执行DataX,用户可以选择以Python方式来做自定义的改造
打包 mvn clean install

将jar包上传到服务器并tar –zxvf安装,
进入datax-web-2.1.2/bin ,bash运行install.sh进行交互式安装,交互式安装会依次解压各模块的package以及调用configure配置脚本,可以逐步判断安装包是否有误。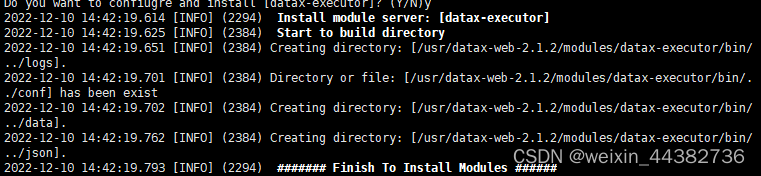

如果服务上有MySQL,则执行安装脚本过程中会出现:
public boolean createPath(String filePath) {
Path path = new Path(filePath);
boolean exist = false;
try {
if (fileSystem.exists(path)) {
String message = String.format("文件路径[%s]已存在,无需创建!",
"message:filePath =" + filePath);
LOG.info(message);
exist = true;
} else {
exist = fileSystem.mkdirs(path);
}
} catch (IOException e) {
String message = String.format("创建文件路径[%s]时发生网络IO异常,请检查您的网络是否正常!",
"message:filePath =" + filePath);
LOG.error(message);
throw DataXException.asDataXException(HdfsWriterErrorCode.CONNECT_HDFS_IO_ERROR, e);
}
return exist;
}2、修改hdfswriter目录下的HdfsWriter.java,在最后的else调用createPath并修改返回日志
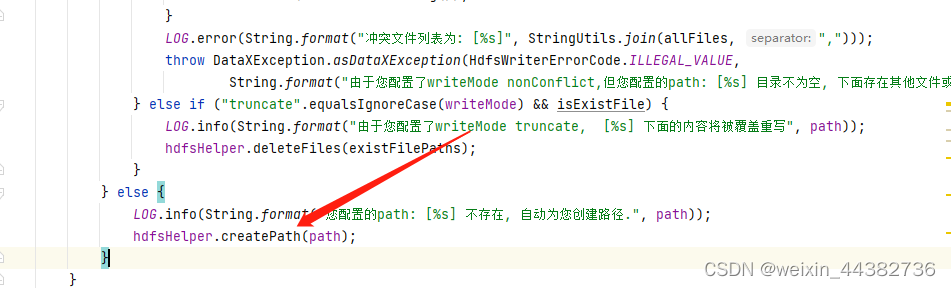
3、将源码打包并替换datax/plugin/writer/hdfswriter/hdfswriter-0.0.1-SNAPSHOT.jar
4、测试

来源:
(二次开发DataX以支持HIVE分区表_datax二次开发_MaxineSgr的博客-CSDN博客)

官方文档中有解释,DataX只支持一次写入单个分区,可以说DataX对hive分区表非常不友好。

DataX-web将写入过程做了简化,但仍然无法做到灵活的创建分区和一次多个写入
任务的设置如下
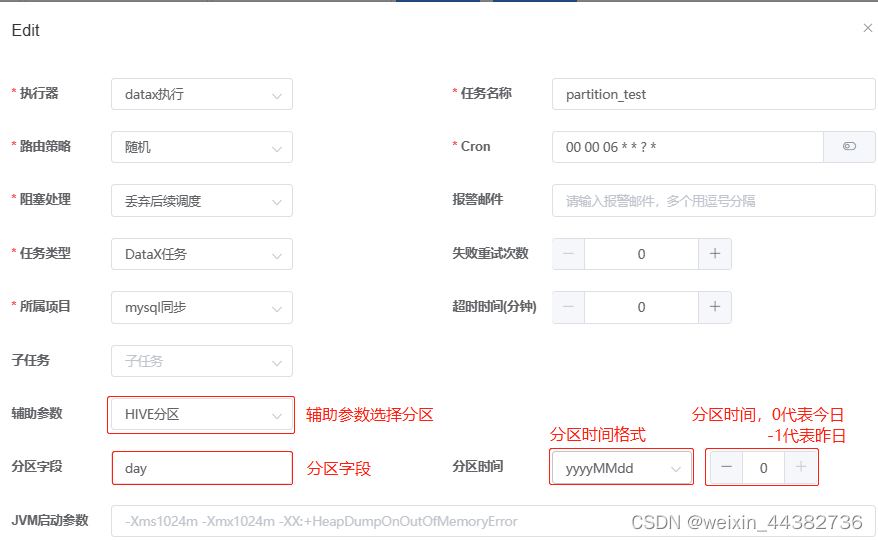
如果按上图设置,最后的分区生成是这样的:

其中分区字段仅支持类似时间的字段,分区时间最多可以选到-20,即当前时间的前二十天。
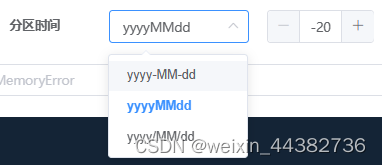
json设置如下,${partition}是固定格式,不能更改

由最后创建的目录可以推断partition是由源码中输入的day与系统当前日期更改格式并计算天数后拼凑成的参数。目前网上没有教程但理论上可以自行修改这部分源码以让分区字段与日期选择更加灵活

注意由此动态分区自动生成路径的方法,写入后可能在Hive端无法查询数据,用MSCK REPAIR TABLE将没有写入metastore的分区信息写入metastore。
MSCK REPAIR TABLE hive_partition_test 运行结果:
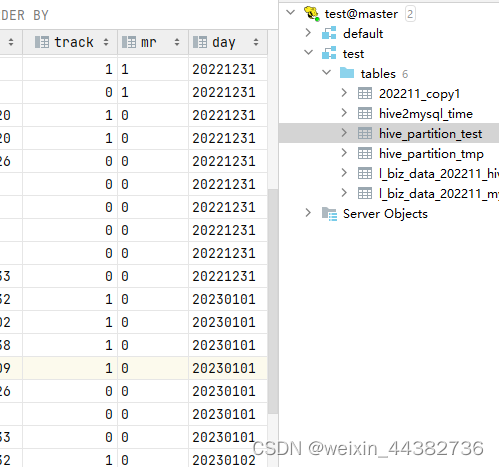
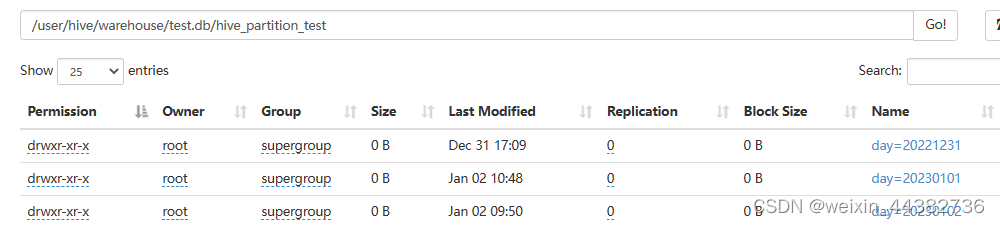
在生产中,假设今日是一月二日,数据接收后存入一张日
1、Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、 Linux、 Unix上运行,绿色无需安装,数据抽取高效稳定。
2、Kettle 中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。
3、Kettle这个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。
4、Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
5、Kettle(现在已经更名为PDI,Pentaho Data Integration-Pentaho)。
(1)Kettle下载安装非常简单,官网下载安装包,找下载数最多的下载解压即可
(Pentaho from Hitachi Vantara - Browse Files at SourceForge.net)
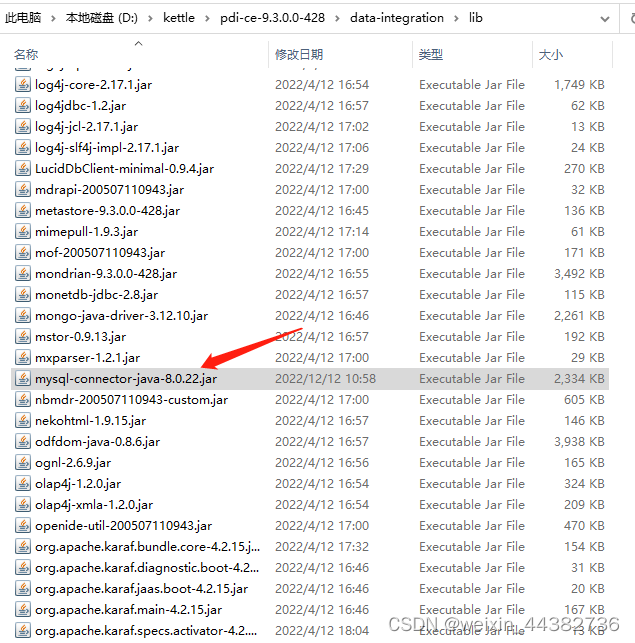
(2)将Mysql连接驱动置于pdi-ce\data-integration\lib下
(3)如果出现hive连接错误的情况,需要将hive lib下的jar包复制到pdi-ce\data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\hdp30\lib
并将hive和hadoop的配置文件都复制到pdi-ce-8.3.0.0-371\data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\hdp30
具体教程可见(kettle连接Hive配置(一)-爱码网)
需要注意的是,官网下载的pdi-9.3版本不知为何缺少hive连接的相关配置文件,且目前缺少该版本的博客,可以下载8.3版本
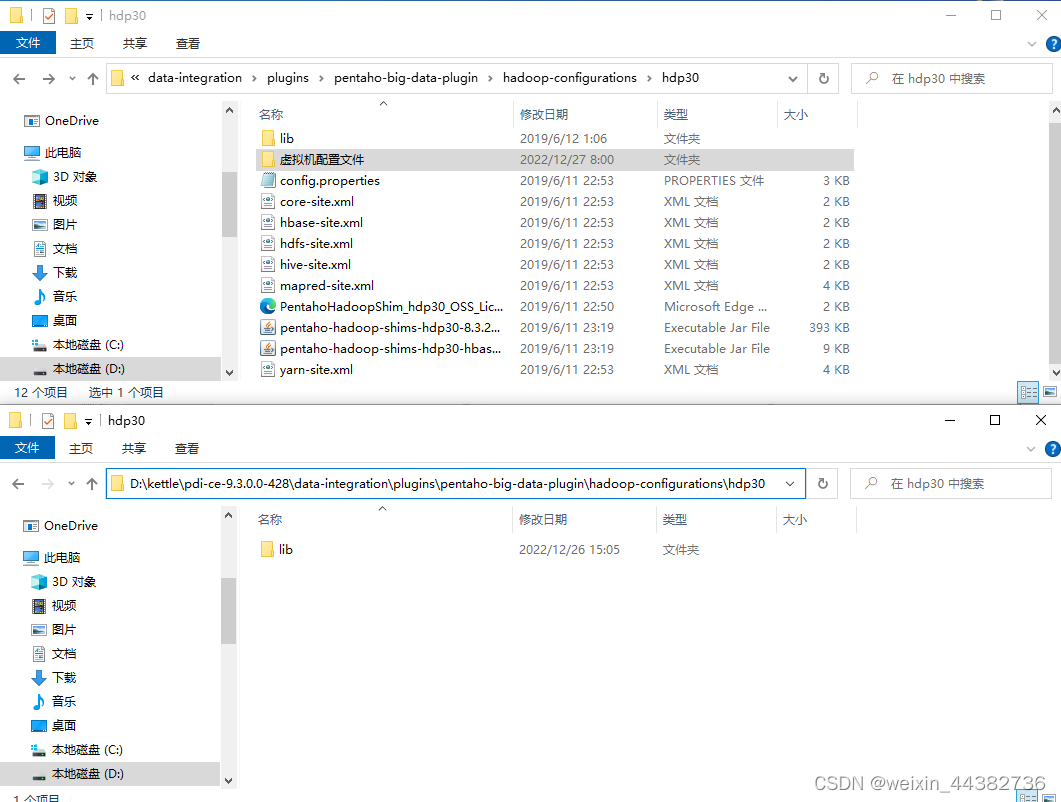
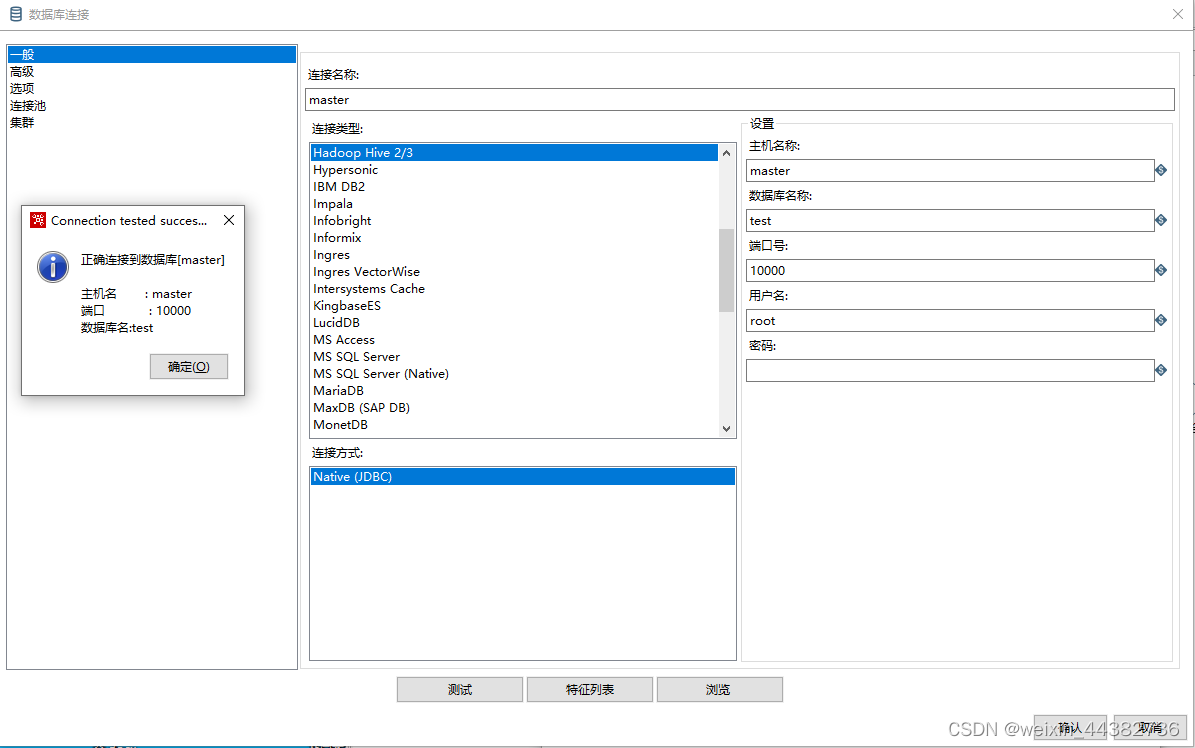
但是kettle8.3版本不兼容mysql8以上版本的jdbc-connecter,若设备使用的是mysql8以上版本,有如下解决办法
1、数据库类型选择Generic Database,相当于不用kettle预设的类型,自定义连接


2、在kettle的安装目录下data-integration\simple-jndi\jdbc.properties加入jdbc的连接信息,相当于预设好一个连接,直接使用
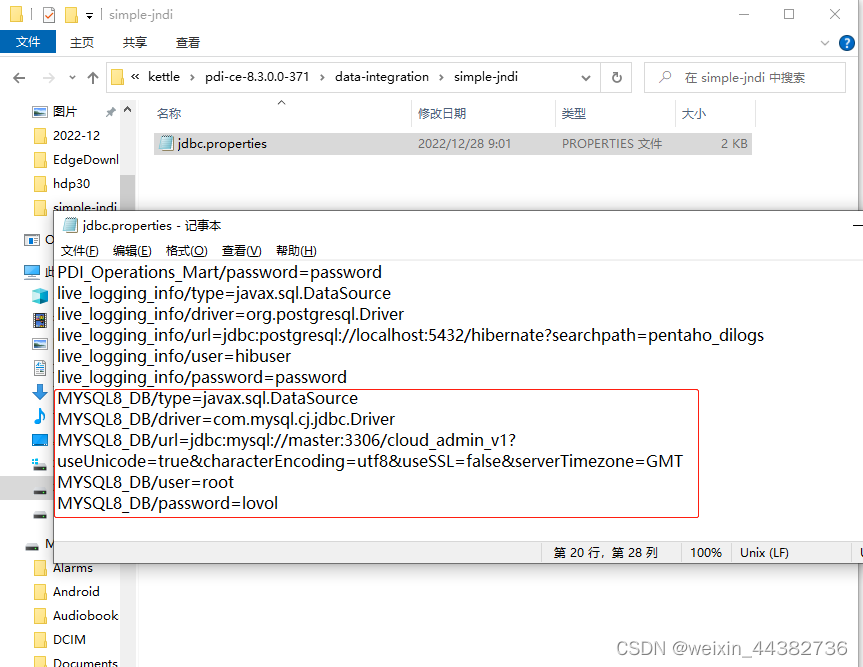
然后在连接类型MySQL中选择预设好的JNDI
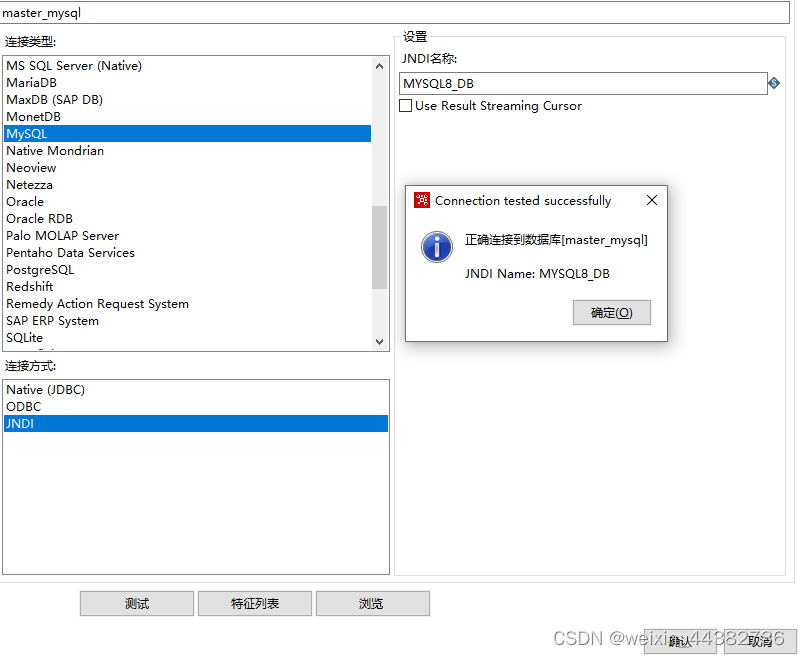
教程参考(kettle连接mysql8.0以上版本_北顾南望的博客-CSDN博客_kettle连接mysql8.0)
设置一个流程将两个MySQL表的内容输入,排序后根据,id将
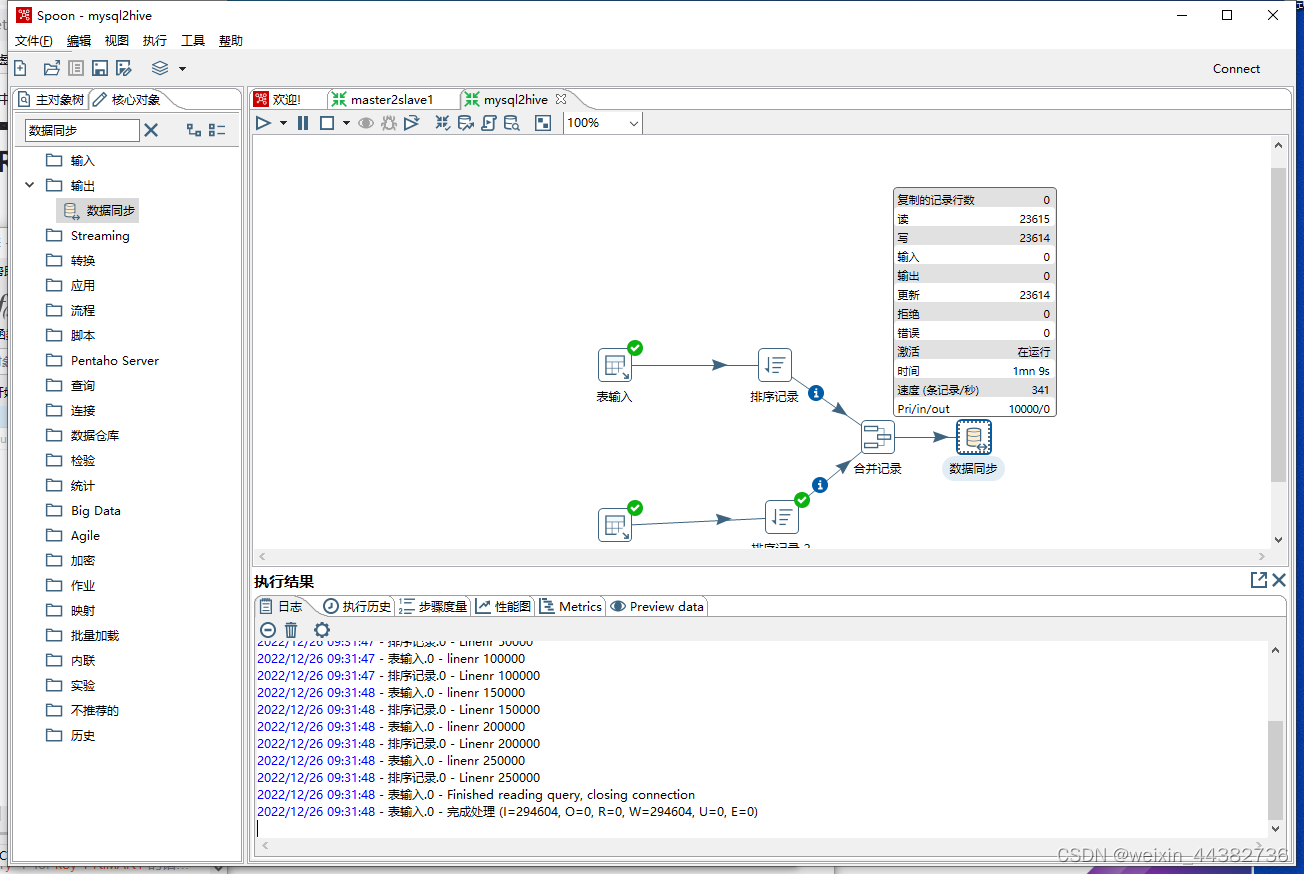
可以看到并更改字段关系映射
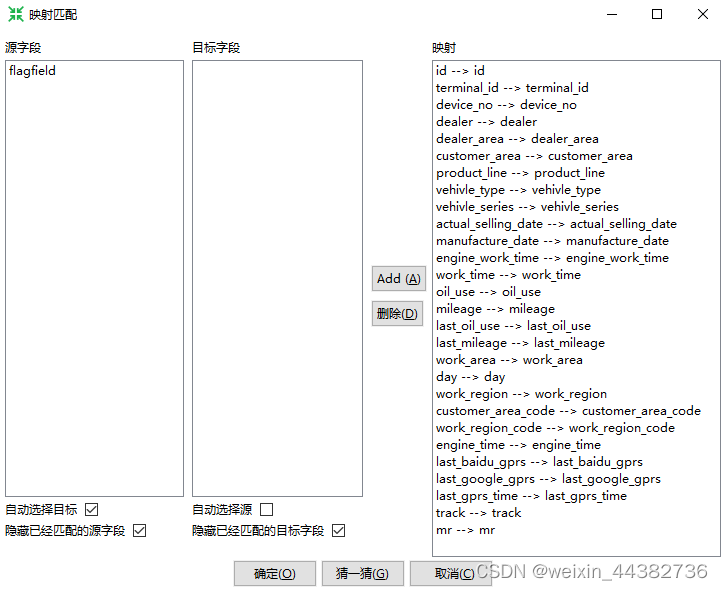
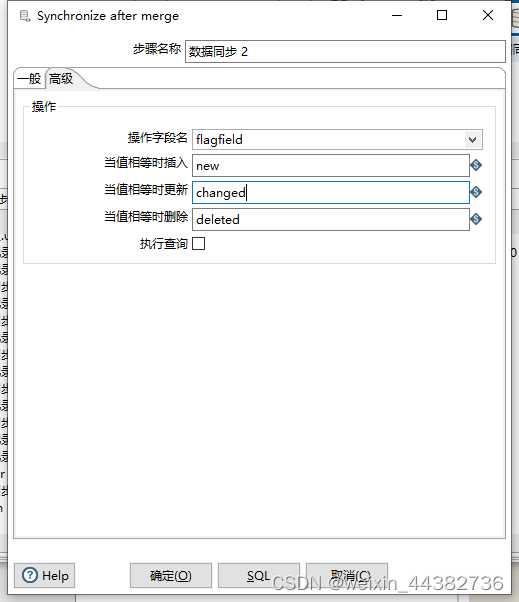
一定要仔细定义数据同步中的高级标签,否则会报错“It was not possible to find operation field [null] in the input stream!”
mysql->mysql运行时长

hive->mysql运行时长

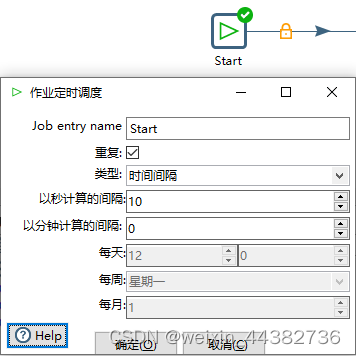
在“作业”中可以对编辑好的“转换”设计运行间隔以达到定时同步的功能。
作为阿里的开源项目,DataX的稳定性与可维护性非常有保障,网上有大量的测试与报错博客,更有补足功能、提供UI操作的DataX-web,使得DataX可以投入到项目中来。另:官方提供了对TDengine的reader和writer。
但DataX有缺陷,作为开源项目,某些功能官方维护不及时,针对某些急需实现的功能(如实例1、(3)中提到的writer过程中的null问题),网上有修改源码的教程。由于本次测试涉及面较窄,生产生活中还可能存在类似情况,到时候需要自主寻错、修改源码。
且DataX对Hive数据的读取可以看作对hdfs上存储的数据进行读取,只能是顺序的,且不能对列有细致操作,实际工作中有类似需要,只能先在数据库中操作,再进行同步作业。
DataX-web提供了一个方便快捷的向分区表写入的方法,但不能自由地多次地写入分区,只能一次写入一个分区,分区字段不能选择除时间以外的字段,时间的选择并不自由,只能选当前时间前20天内的一天作为分区。如果有相关需求,可以进行源码的二次开发,建议二次开发时一定做好记录,提高部门同事间沟通效率,以提高工作效率。
虽有不足但DataX总体上能承担日常生活中的数据同步工作。DataX官方插件有严格的格式设置,编写json时请先查看相关插件的参数介绍。
Kettle提供了强大的图形化Spoon,可以做到中小型需求不写一行代码,大大减少了工作量,且对于Hive数据的读取可以做列的操作,数据的读取是依靠字段进行的而不是顺序进行的,比DataX、Sqoop更加精细。kettle重点是中间变换工作,集成功能速度较慢
时间对比,上图为datax,下图为kettle,可以看到差距还是比较大的
MySQL->MySQL:


Hive->MySQL:


可以看到在同一台机器上运行同一份数据时,在MySQL->MySQL和Hive->MySQL的情况下,仅29万条数据,Kettle和DataX在效率上就存在明显差距。随着数据量的提升,差距会愈发明显。因此若选用Kettle则需要考虑在海量数据的前提下的调优问题,业务越复杂,需要优化的组件就越多。
且Kettle spoon对于定时运行缺乏集成化的设置,一旦业务数量变多,执行定时调度时,就只能通过系统自带的定时任务调度去进行管理。无法统一,假如要做统一的管理,需要安装一套jenkins,但配置和后续的运维成本可能较高。以及kettle的内存占用较高,无法最大效率地利用服务器资源
注意:
(1)hive作为数据源的时候,注意在reader设置中不要跳过表头,否则会缺失第一列数据
(2)单机版的DataX,在脏数据统计上有点小问题。举个例子:先运行了一个任务A,假设这个任务A有5条脏数据,errorlimit设置了record:0,在运行时,这个任务是一定会因为脏数据而终止执行。任务A终止执行后,你紧接着运行任务B,假设任务B没有脏数据,errorlimit也设置了record:0,但有可能任务B在运行时,它也会报“在运行的过程中捕获了5条脏数据,任务结束”。也就是任务A的脏数据会影响任务B。问题出在LocalTGCommunicationManager这个类中,它使用了一个静态变量taskGroupCommunicationMap来存储脏数据。
(1)(问题可能出现在hdfsreader等)
2022-12-15 13:59:56.077 [0-0-0-reader] ERROR StdoutPluginCollector - 脏数据:
{"message":"No enum constant com.alibaba.datax.plugin.unstructuredstorage.reader. UnstructuredStorageReaderUtil.Type.BIGINT","record":[],"type":"reader"}

问题原因:datax支持的数据类型与hive有不同
| DataX 数据类型 | Hive表 数据类型 |
| Long | TINYINT,SMALLINT,INT,BIGINT |
| Double | FLOAT,DOUBLE |
| String | String,CHAR,VARCHAR,STRUCT,MAP,ARRAY,UNION,BINARY |
| Boolean | BOOLEAN |
| Date | Date,TIMESTAMP |
其余多种数据库间数据类型映射,可参考(datax与多种数据库间数据类型映射_datax 数据类型_chimchim66的博客-CSDN博客)
将reader中所有其余数据库的数据类型依次按照对照表改为datax支持的数据类型。
(2)(问题可能出现在hdfsreader等)

在read过程中,\N不能转换为DATE属性的值,报类型转换错误
1、在reader中设置,使空值不再参与转换,直接跳过
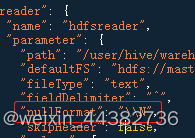
2、设中转表将DATE类型改为STING类型,再由数据库或olap组件内部转换格式。
(3)(问题可能出现在将数据同步后的Hive又作为数据源输出时)
类型转换错误,无法将[]转换为[date]等等一系列类似错误
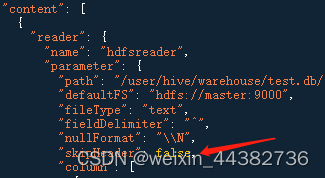
hdfswriter并未提供nullFormat参数:也就是用户并不能自定义null值写到HFDS文件中的存储格式。默认情况下,hdfswriter会将null值存储为空字符串(’’),但Hive默认的null值存储格式为\N。所以后期将DataX同步的文件导入Hive表就会出现问题。
1、修改datahdfswriter的源码,增加自定义null值存储格式的逻辑,参考(记Datax3.0解决MySQL抽数到HDFSNULL变为空字符的问题_谭正强的博客-CSDN博客_datax nullformat),然后mvn打包。在hdfswriter阶段就把null值划分清楚,避免后续问题积少成多。
在hive表同步到hive表的过程中reader和writer都要设置nullFormat参数。
2、或是在Hive中建表时指定null值存储格式为空字符串(’’)(不推荐)
例如:
DROP TABLE IF EXISTS base_province;
CREATE EXTERNAL TABLE base_province
(
`id` STRING COMMENT '编号',
`name` STRING COMMENT '省份名称',
`region_id` STRING COMMENT '地区ID',
`area_code` STRING COMMENT '地区编码',
`iso_code` STRING COMMENT '旧版ISO-3166-2编码,供可视化使用',
`iso_3166_2` STRING COMMENT '新版IOS-3166-2编码,供可视化使用'
) COMMENT '省份表'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/base_province/';
(4)(问题可能出现在hdfsreader、hdfswriter等)
在同步过程中,出现列数据混乱,或日志出现类型转换错误
由于datax对于hdfs读写非常格式化,如果建表的列顺序不对或列分隔符出现在表中的话,都会引起数据读写的混乱的情况。
实际建表中建议hive列分隔符不要出现任何表中可能有的元素,例如“\t”,“,”“;”等。创建列的先后顺序严格一致,以减少同步过程中数据混乱。
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po