
文 | 智商掉了一地
交互式视觉分割新作,具有语义感知的新模型~
自从 Meta 发布了“分割一切”的 SAM 之后,各种二创如雨后春笋般冒出,昨天微软的一篇论文又在推特上引起讨论,虽然最开始吸引小编的是它的名字——分割“瞬息全宇宙”(《Everything,Everywhere, All at Once》),看到后满脑子都是杨紫琼斩获奥斯卡最佳女主角的这个电影:

哈哈扯远了...回归正题:
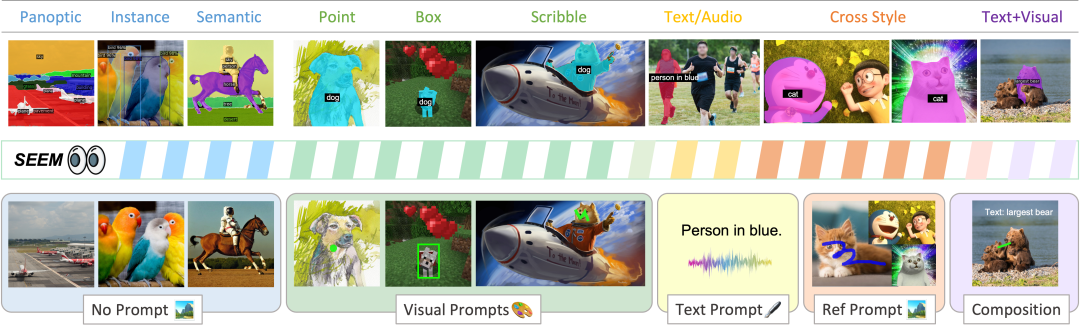
这是个视觉理解方面的多模态 AI 交互研究,受到 LLM 基于 prompt 的通用界面开发的启发,作者提出了一个名为 SEEM 的模型,它能够在一次操作中完成各种分割任务,包括语义、实例和全景分割,同时也支持各种 prompt 类型和它们的任意组合。
作者指出,SEEM 有以下 4 个亮点:
多功能性(Versatile):处理各种类型的 prompt ,例如点击、框选、多边形、涂鸦、文本和参考图像;
组合式(Compositional):处理 prompt 的任何组合;
交互性(Interactive):与用户多轮交互,得益于 SEEM 的记忆 prompt 来存储会话历史记录;
语义感知(Semantic-aware):为任何预测的掩码提供语义标签。
论文题目:
Segment Everything Everywhere All at Once
论文链接:
https://arxiv.org/abs/2304.06718
项目地址:
https://github.com/ux-decoder/segment-everything-everywhere-all-at-once
Demo地址:
https://36771ee9c49a4631.gradio.app/
在分割问题领域,Meta 几天前提出的 SAM 提供了一个通用且全自动的图像分割方法,它的创新之处在于可以同时执行交互式分割和自动分割,并且可以通过灵活的 prompt 界面来适应新任务和新领域。它解决了传统方法需要很多手动注释和对于特定对象的限制的问题,具有很高的适用性和可扩展性。
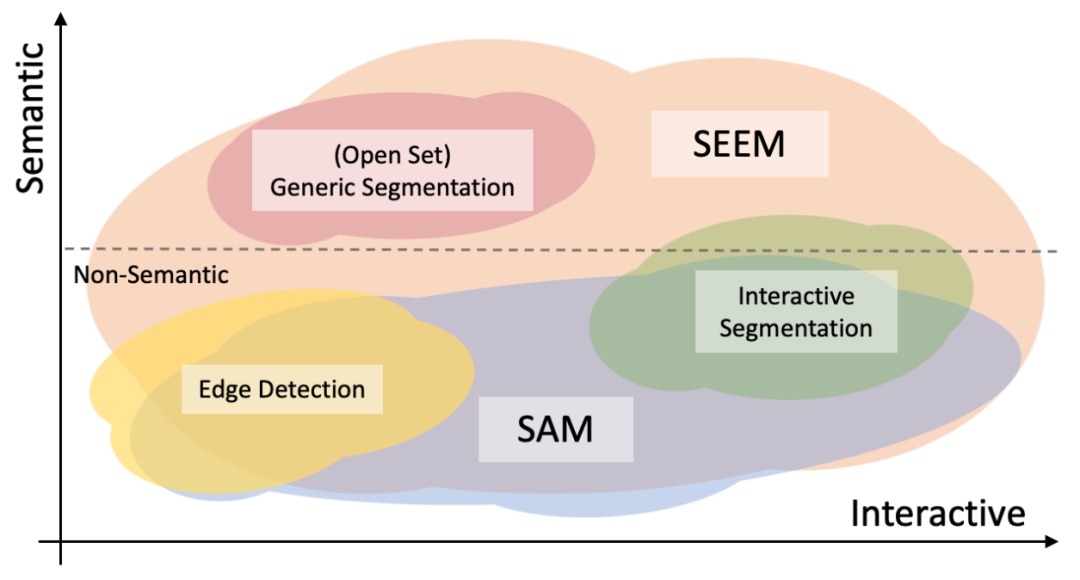
自从 SAM 开始,视觉 prompt 的一阵风便吹向了计算机视觉领域。作者比较了 SEEM 和 SAM 的在交互性和语义性方面的区别与联系,:
SEEM 在交互性和语义性方面的覆盖范围更广,支持更多类型的 prompt ,并理解语义;而 SAM 只支持受限的交互类型,比如点和框,同时也无法输出语义标签。这主要因为 SEEM 具有统一的 prompt 编码器,将所有视觉和语言 prompt 编码为一个联合表示空间,因此可以支持更具泛化性的用法,并有潜力扩展到自定义 prompt。
SEEM 在文本到 Mask(grounding 分割)方面表现得很好,可以输出具有语义感知的预测。因此,作者指出 SEEM 的交互和语义性能力更强。
SEEM 模型采用了一种通用的编码器-解码器架构,主要关注 query 和 prompt 之间的复杂交互。模型由文本编码器和视觉采样器组成。文本和视觉 prompt 被编码成可学习的查询,然后送入 SEEM 模型中,并输出 Mask 和语义标签。视觉 prompt 被编码成池化图像特征,然后在 SEEM 解码器中使用 Self-Attention 和 Cross-Attention。如图 4(a) 所示:
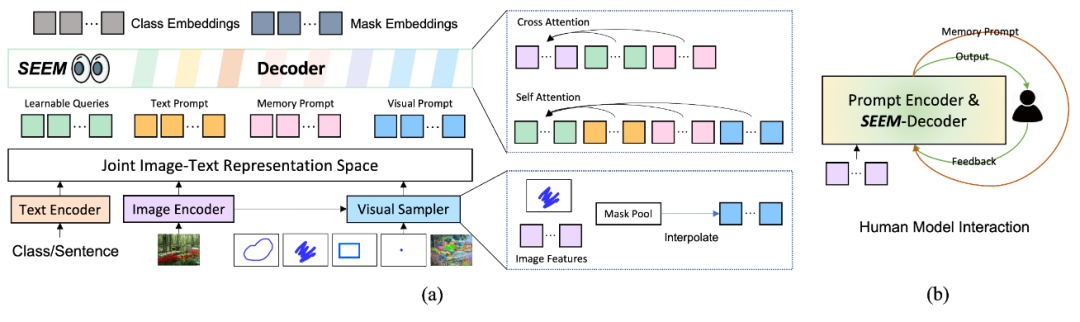
SEEM 与人之间的多轮交互如图 4(b),主要包括以下 3 个步骤:
人给出 prompt;
模型向人发送预测结果;
模型更新记忆 prompt。
主要利用视觉 prompt 来处理非文本输入(如点、框、涂鸦和另一张图像的指定区域),并将其统一以 token 的形式在同一视觉嵌入空间中表示。该模型采用均匀采样方式获取指定区域的最多 512 个图像特征,同时在语义分割和目标参照分割中,模型通过学习一个共同的视觉-语义空间来实现视觉 prompt 与文本 prompt 的自然对齐。该设计可以避免先前方法中因空间转换耗费大量计算资源以及难以泛化到未见过 prompt 的问题。
为了满足用户在实际应用中可能使用不同类型或组合输入的需求,组合式提示(prompt)方法必不可少。然而,模型训练过程中面临两个问题:
训练数据往往只包含单一类型的输入(如无、文本、视觉);
即使使用视觉 prompt 将所有非文本类型的 prompt 统一到一起与文本 prompt 对齐,它们嵌入的空间仍然不同。
为解决这些问题,提出了一种新的方法:使用不同类型的输出来匹配不同类型的 prompt。在训练过程中,通过匹配 Mask 嵌入 和类型嵌入 ,选择匹配的输出索引,以适应不同的 prompt 类型。实验结果表明,相较于只使用 或 并针对所有 prompt 类型进行匹配的方法,该方法更具优势。在训练后,模型能够熟悉所有 prompt 类型,支持多种组合方式,包括无 prompt 、单个 prompt 类型,或同时使用视觉和文本 prompt。特别的是,即使没有接受这样的训练,可以简单地连接视觉和文本 prompt 并输入到 SEEM 解码器中。
通常需要多次交互才能完成图像分割的细化,就像 ChatGPT 对话过程一样。在模型中提出了一种称为“记忆 prompt”的新型 prompt 方式,通过它们将来自先前迭代的 Mask 知识传递给当前迭代。与以前使用网络来编码 Mask 的模型不同,SEEM 模型只需要使用几个记忆 prompt 即可,它们使用 Mask 引导的交叉注意力结合特征图来编码历史信息。更新后的记忆 prompt 通过自注意力与其他的 prompt 进行交互,传递当前交互轮次的历史信息。不过这种设计虽然可以轻松扩展以支持同时交互分割多个对象,但还需要进一步的研究。
这里的设计与之前的类别无关的交互式分割方法(如 Simple Click 和 SAM)不同,在联合视觉-语义空间中对齐了视觉 prompt 特征与文本特征,因此能够为来自各种 prompt 组合的 Mask 赋予语义标签,如图 4(a) 所示,计算了 Mask 嵌入和视觉采样之间的相似度矩阵。尽管没有为交互式分割训练任何语义标签,但由于联合视觉-语义空间的作用,计算出的 logits 已经较好地对齐了。
作者提供了体验 Demo,访问链接已经放在了本文的开头,感兴趣的朋友可以自己试试看。在实验中展示了以下可视化的实验结果:
如图 5 所示,在点击分割中,SEEM 超越 SAM 的地方在于支持用户的任意格式点击或勾勒。此外,它同时给出了分割 Mask 的语义标签。

如下图所示,参考的文本显示在 Mask 上,同时,SEEM 适用于卡通、电影和游戏领域的各种类型的输入图像。


图 7 中,给出一个具有简单空间提示的参考图像,SEEM 可以分割出不同目标图像中语义相似的内容。
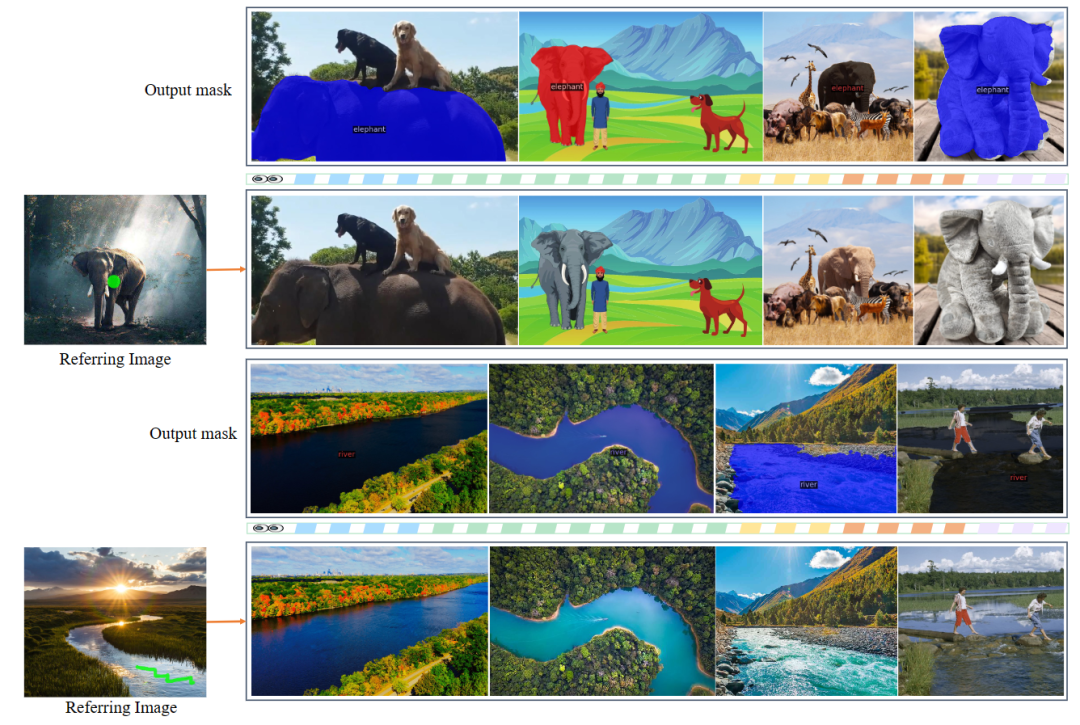
图 8 展示了即使面对由模糊或强烈形变引起的明显外观变化,也能精确地分割所需对象。

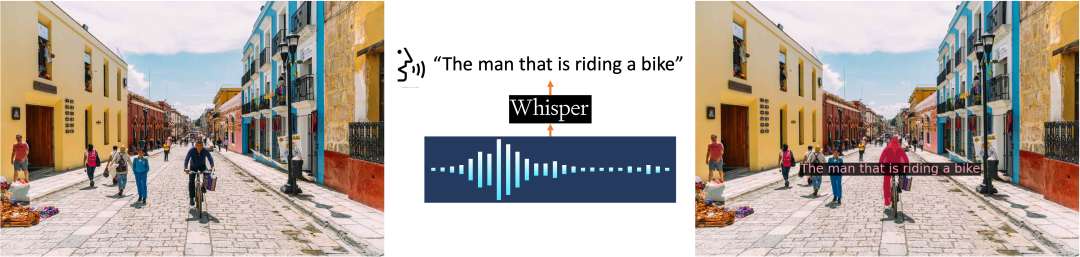
同时在 Demo 中还可以体验将音频转换为文本 prompt 来分割对象的操作,如图 9 所示:
对于 SEEM 模型,在交互和 prompt 方面可以总结如下:
可以同时进行所有可能的 prompt 组合的语义分割,具有很好的泛化性能,能够处理多种词汇和多种视觉 prompt。
可以与用户进行交互,接受多种视觉 prompt,包括点击、框选、多边形、涂抹、文本和参考图像分割。这使得模型对于不同的任务和用户需求有很好的适应能力。
使用了一个 prompt 编码器将视觉 prompt 映射到一个联合的视觉-语义空间中,这使得模型可以适应不同类型的 prompt 并灵活地组合它们,从而提高分割的效果和精度。
相信未来会有更多基于交互式计算机视觉的研究涌现,这将使我们改变观念、重新审视该领域。这些研究可能涌现于图像理解和多模态学习领域,为智能交互的发展带来崭新的可能性。让我们拭目以待,期待更多的新研究与发现吧~

卖萌屋作者:智商掉了一地
北理工计算机硕士在读,近期沉迷于跟 ChatGPT 唠嗑,对一切新颖的 NLP 应用充满好奇,正在努力成为兴趣广泛的斜杠青年~
作品推荐
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜推广与求职讨论群
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我有一些非常大的模型,我必须将它们迁移到最新版本的Rails。这些模型有相当多的验证(User有大约50个验证)。是否可以将所有这些验证移动到另一个文件中?说app/models/validations/user_validations.rb。如果可以,有人可以提供示例吗? 最佳答案 您可以为此使用关注点:#app/models/validations/user_validations.rbrequire'active_support/concern'moduleUserValidationsextendActiveSupport:
对于Rails模型,是否可以/建议让一个类的成员不持久保存到数据库中?我想将用户最后选择的类型存储在session变量中。由于我无法从我的模型中设置session变量,我想将值存储在一个“虚拟”类成员中,该成员只是将值传递回Controller。你能有这样的类(class)成员吗? 最佳答案 将非持久属性添加到Rails模型就像任何其他Ruby类一样:classUser扩展解释:在Ruby中,所有实例变量都是私有(private)的,不需要在赋值前定义。attr_accessor创建一个setter和getter方法:classUs
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序
我正在使用Rails3.1并在一个论坛上工作。我有一个名为Topic的模型,每个模型都有许多Post。当用户创建新主题时,他们也应该创建第一个Post。但是,我不确定如何以相同的形式执行此操作。这是我的代码:classTopic:destroyaccepts_nested_attributes_for:postsvalidates_presence_of:titleendclassPost...但这似乎不起作用。有什么想法吗?谢谢! 最佳答案 @Pablo的回答似乎有你需要的一切。但更具体地说...首先改变你View中的这一行对此#