GMS一种基于运动统计的快速鲁棒特征匹配过滤算法,能明显地改善匹配结果,目前已经集成进入OpenCV之中
项目地址:GMS: Fast and Robust Feature Matcher (CVPR 17 & IJCV 20) – Jia-Wang Bian
论文 GMS: Grid-based Motion Statistics for Fast, Ultra-robust Feature Correspondence
首先给出第一个假设:
运动平滑性:真实匹配的小邻域内匹配通常是在三维空间中的同一块区域。同样地,一个错误匹配的邻域内的匹配通常是几何上不同的三维位置。
这个假设告诉我们:正确匹配的邻域内有多个支持它的匹配,而错误匹配的邻域内支持它的匹配是很少的。这里其实隐含着一个逻辑:作者通过观察发现,正确匹配的邻域内匹配的数量多的概率就会很大,反之则少;那么根据贝叶斯法则,那些匹配对邻域内有很多匹配的匹配关系有很大概率是正确匹配。
一句话:正确匹配周围会有较多的匹配去支持它,而错误的匹配周围支持它的匹配很少。

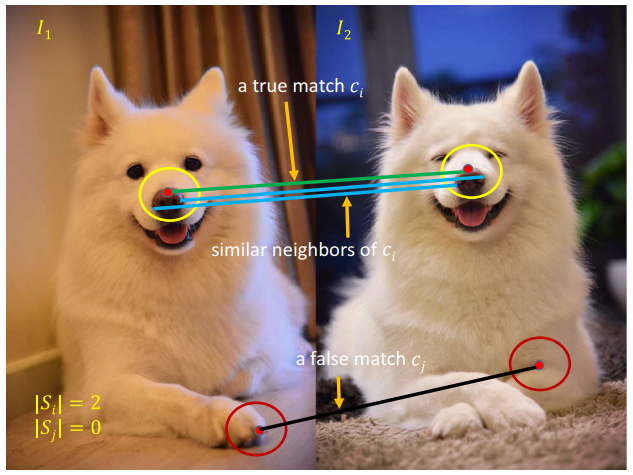

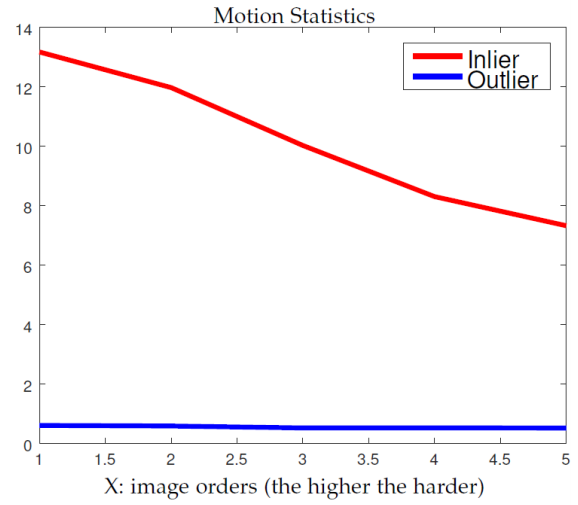
上图展示了作者在Oxford Affine Dataset上验证模型合理性的示意图。利用SIFT特征进行匹配,根据真值标记出正确以及错误匹配。统计每个匹配所在小邻域内的匹配数量。可以发现,正确匹配的支持域得分明显高于错误匹配,即使在非常困难的匹配序列上,该现象仍然存在。

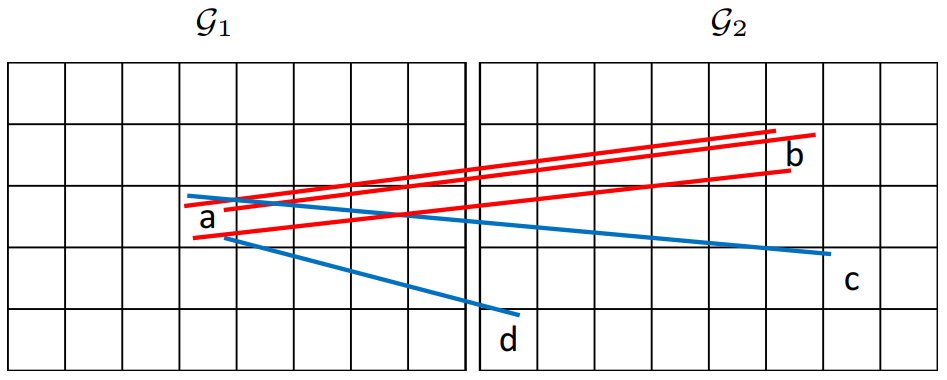
 6. 运动核
6. 运动核如果网格很小,则很少邻域信息将被考虑, 这会降低算法性能。 但是,如果网格很大,则将包括更多不正确的对应关系。为解决这个矛盾,我们将网格大小设置为较小以提高准确性,并提出运动内核以考虑更多邻域信息。
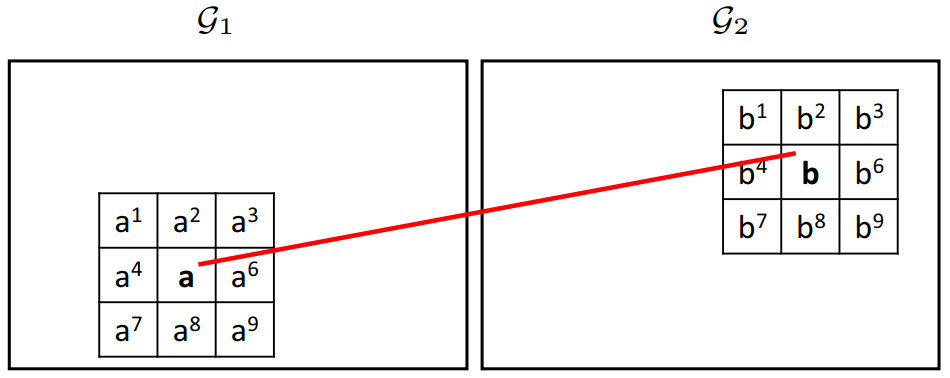

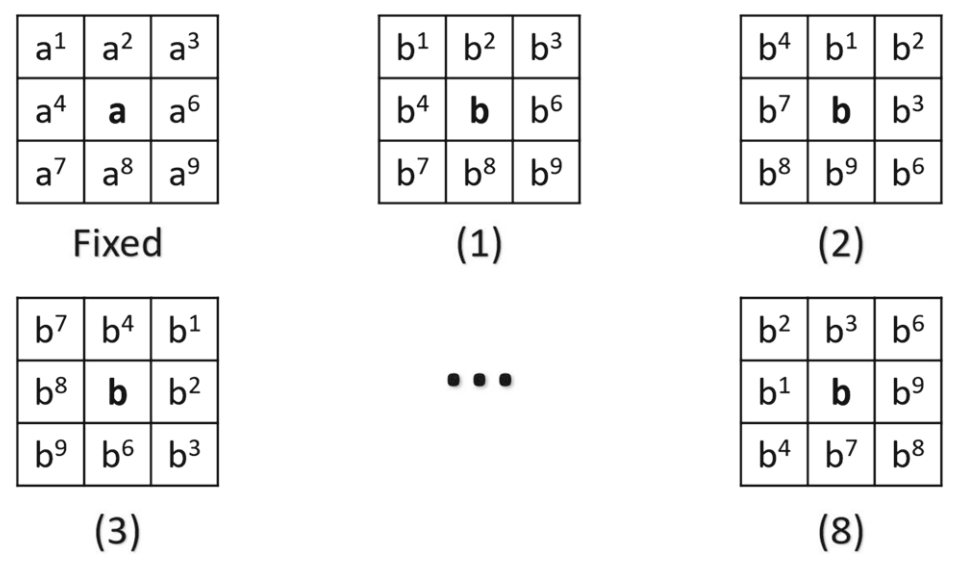
为了应对匹配过程中的尺度与旋转问题,本文提出了多尺度以及多旋转策略。

利用旋转运动核模拟不同方向的旋转,如下图所示,固定,对
按照顺时针旋转,这样可以得到8个运动核。然后利用GMS算法在所有的运动核上,然后选择最好的结果(选择匹配数量最多那个)。

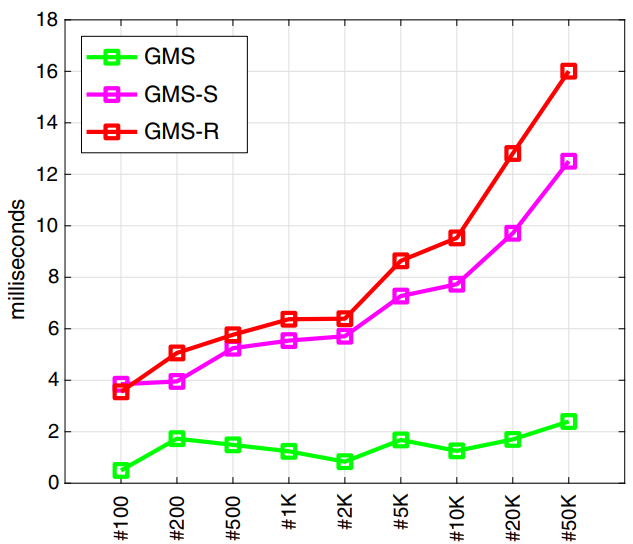
GMS能够在PC端速度2ms,multi-scale(GMS-S)以及multi-rotation(GMS-R)会增加一定的耗时。
求解位姿速度快,且位姿精确。
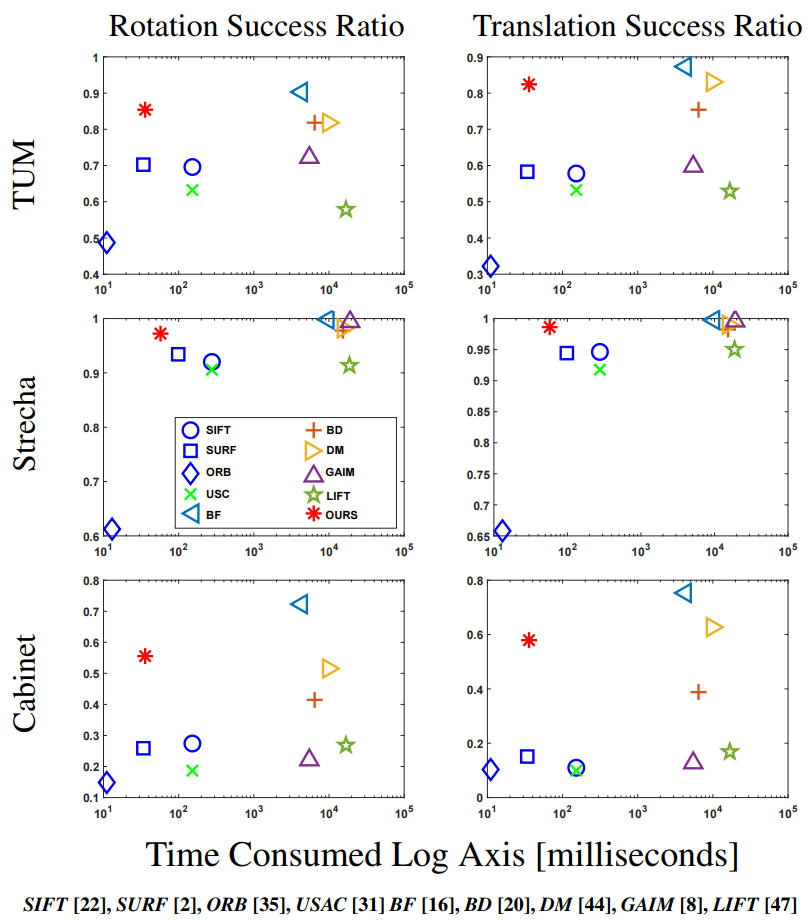
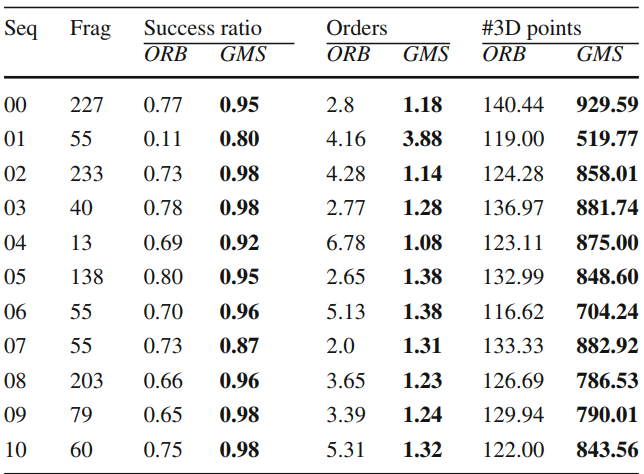
集成到SLAM也可获得较好的结果(该实验不够充分,仅测试了将GMS集成到SLAM初始化的阶段,为了展示GMS能够更快/更好的进行初始化,同时能够产生较多的地图点)。
本文提供了一种高效/快速的外点滤除算法,能够在PC端实现实现实时滤除外点;
本算法已经被集成到OpenCV中,接口名为matchGMS(),可直接调用;
本算法可用于SLAM/SFM等领域,可提高位姿解算的精度以及速度;
(局限)本算法需要提取较多的特征点以提高正确匹配与错误匹配的可区分度,若特征匹配较少;该算法性能会有一定下降;
(局限)由于仅统计特征匹配数量,在重复纹理条件下该算法的性能也会下降;
#include <opencv2/xfeatures2d.hpp>
void cv::xfeatures2d::matchGMS(const Size& size1,
const Size& size2,
const std::vector< KeyPoint >& keypoints1,
const std::vector< KeyPoint >& keypoints2,
const std::vector< DMatch >& matches1to2,
std::vector< DMatch >& matchesGMS,
const bool withRotation = false,
const bool withScale = false,
const double thresholdFactor = 6.0) Parameters
| size1 | Input size of image1. |
| size2 | Input size of image2. |
| keypoints1 | Input keypoints of image1. |
| keypoints2 | Input keypoints of image2. |
| matches1to2 | Input 1-nearest neighbor matches. |
| matchesGMS | Matches returned by the GMS matching strategy. |
| withRotation | Take rotation transformation into account. |
| withScale | Take scale transformation into account. |
| thresholdFactor | The higher, the less matches. |
#include <iostream>
#include <opencv2/core.hpp>
#include <opencv2/highgui.hpp>
#include <opencv2/imgproc.hpp>
#include <opencv2/flann.hpp>
#include <opencv2/features2d.hpp>
#include <opencv2/xfeatures2d.hpp>
using namespace cv;
using namespace std;
using namespace cv::xfeatures2d;
int main()
{
Mat img_1 = imread("01.jpg");
Mat img_2 = imread("02.jpg");
//Ptr<Feature2D> sift = xfeatures2d::SIFT::create();
//Ptr<Feature2D> surf = xfeatures2d::SURF::create();
Ptr<ORB> orb = ORB::create(5000);
orb->setFastThreshold(0);
vector<KeyPoint> keypoints_1, keypoints_2;
Mat descriptors_1,descriptors_2;
//sift->detect(img_1, keypoints_1);
//sift->compute(img_1, keypoints_1, descriptors);
orb->detectAndCompute(img_1, Mat(),keypoints_1, descriptors_1);
orb->detectAndCompute(img_2, Mat(), keypoints_2, descriptors_2);
//orb ->detect(img_1, keypoints_1);
//orb ->compute(img_1, keypoints_1, descriptors_1);
//orb->detect(img_2, keypoints_2);
//orb->compute(img_2, keypoints_2, descriptors_2);
Mat ShowKeypoints1, ShowKeypoints2;
drawKeypoints(img_1, keypoints_1, ShowKeypoints1);
drawKeypoints(img_2, keypoints_2, ShowKeypoints2);
imshow("Result_1", ShowKeypoints1);
imshow("Result_2", ShowKeypoints2);
vector<DMatch> matchesAll, matchesGMS;
BFMatcher matcher(NORM_HAMMING);
matcher.match(descriptors_1, descriptors_2, matchesAll);
cout << "matchesAll: " << matchesAll.size() << endl;
matchGMS(img_1.size(), img_2.size(), keypoints_1, keypoints_2, matchesAll, matchesGMS);
std::cout << "matchesGMS: " << matchesGMS.size() << std::endl;
Mat finalMatches;
drawMatches(img_1, keypoints_1, img_2, keypoints_2, matchesGMS, finalMatches, Scalar::all(-1), Scalar::all(-1),
std::vector<char>(), DrawMatchesFlags::NOT_DRAW_SINGLE_POINTS);
imshow("Matches GMS", finalMatches);
imwrite("MatchesGMS.jpg", finalMatches);
waitKey(0);
return 0;
}
📝笔记:GMS一种基于运动统计的快速鲁棒特征匹配过滤算法 | RealCat
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
在我的应用程序中,我需要能够找到所有数字子字符串,然后扫描每个子字符串,找到第一个匹配范围(例如5到15之间)的子字符串,并将该实例替换为另一个字符串“X”。我的测试字符串s="1foo100bar10gee1"我的初始模式是1个或多个数字的任何字符串,例如,re=Regexp.new(/\d+/)matches=s.scan(re)给出["1","100","10","1"]如果我想用“X”替换第N个匹配项,并且只替换第N个匹配项,我该怎么做?例如,如果我想替换第三个匹配项“10”(匹配项[2]),我不能只说s[matches[2]]="X"因为它做了两次替换“1fooX0barXg
如何匹配未被反斜杠转义的平衡定界符对(其本身未被反斜杠转义)(无需考虑嵌套)?例如对于反引号,我试过了,但是转义的反引号没有像转义那样工作。regex=/(?!$1:"how\\"#expected"how\\`are"上面的正则表达式不考虑由反斜杠转义并位于反引号前面的反斜杠,但我愿意考虑。StackOverflow如何做到这一点?这样做的目的并不复杂。我有文档文本,其中包括内联代码的反引号,就像StackOverflow一样,我想在HTML文件中显示它,内联代码用一些spanMaterial装饰。不会有嵌套,但转义反引号或转义反斜杠可能出现在任何地方。
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我有一个驼峰式字符串,例如:JustAString。我想按照以下规则形成长度为4的字符串:抓取所有大写字母;如果超过4个大写字母,只保留前4个;如果少于4个大写字母,则将最后大写字母后的字母大写并添加字母,直到长度变为4。以下是可能发生的3种情况:ThisIsMyString将产生TIMS(大写字母);ThisIsOneVeryLongString将产生TIOV(前4个大写字母);MyString将生成MSTR(大写字母+tr大写)。我设法用这个片段解决了前两种情况:str.scan(/[A-Z]/).first(4).join但是,我不太确定如何最好地修改上面的代码片段以处理最后一种
我真的为这个而疯狂。我一直在搜索答案并尝试我找到的所有内容,包括相关问题和stackoverflow上的答案,但仍然无法正常工作。我正在使用嵌套资源,但无法使表单正常工作。我总是遇到错误,例如没有路线匹配[PUT]"/galleries/1/photos"表格在这里:/galleries/1/photos/1/edit路线.rbresources:galleriesdoresources:photosendresources:galleriesresources:photos照片Controller.rbdefnew@gallery=Gallery.find(params[:galle
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
我已经在mountainlion上成功安装了rbenv和rubybuild。运行rbenvinstall1.9.3-p392结束于:校验和不匹配:ruby-1.9.3-p392.tar.gz(文件已损坏)预期f689a7b61379f83cbbed3c7077d83859,得到1cfc2ff433dbe80f8ff1a9dba2fd5636它正在下载的文件看起来没问题,如果我使用curl手动下载文件,我会得到同样不正确的校验和。有没有人遇到过这个?他们是如何解决的? 最佳答案 tl:博士;使用浏览器从http://ftp.rub
@raw_array[i]=~/[\W]/非常简单的正则表达式。当我用一些非拉丁字母(具体来说是俄语)尝试时,条件是错误的。我能用它做什么? 最佳答案 @raw_array[i]=~/[\p{L}]/使用西里尔字符进行测试。引用:http://www.regular-expressions.info/unicode.html#prop 关于ruby-正则表达式将非英文字母匹配为非单词字符,我们在StackOverflow上找到一个类似的问题: https://