步骤1:安装Python3环境
前往 Download Python | Python.org 下载Windows环境版本(Python 3.8以上)。安装过程中选中“Add Python directory to 'PATH' environment variable”。选中之后,Python可以像系统自带命令一样,在所有CMD目录下运行。否则每次执行Python都需要输入它的目录位置。其他选项按默认即可。
(可选操作)步骤1a:替换下载镜像为清华大学镜像源
在命令行输入 pip config set global.index-url Simple Index
这样对于国内用户来说下载速度会更快
步骤2:安装VOSK API库
打开CMD(命令提示符)输入 pip install vosk
步骤3:配置目录并下载语音模型
在桌面创建 vosk 目录。
前往 VOSK Models 下载中文语音模型。
或者直接点击下面的链接下载,并解压到vosk目录下。将解压出来的目录重命名为 “model”(不含引号)。
vosk-model-cn-0.1.zip
195M TBD Big narrowband Chinese model for server processing Apache 2.0
步骤4:下载ffmpeg
前往 https://github.com/BtbN/FFmpeg-Builds/releases 下载ffmpeg,并将 ffmpeg.exe 解压到桌面 vosk 目录内
linux,下载docker pull fogg4444/centosffmpeg,免得搭配各种ffmpeg依赖包。
步骤5:安装并打开Notepad++ (或者使用你自己的高级文本编辑器)
前往 https://notepad-plus-plus.org/downloads/ 下载 notepad++
(国内镜像:http://www.pc6.com/softview/SoftView_13941.html)
安装打开,并创建新文件,拷贝以下内容:
#使用方法
#拷贝语音模型到当前目录下 并命名为 'model'
#拷贝ffmpeg.exe文件到当前目录下
#执行 python test_ffmpeg.py speech.mp3 即可
#!/usr/bin/env python3
from vosk import Model, KaldiRecognizer, SetLogLevel
import sys
import os
import wave
import subprocess
import json
SetLogLevel(0)
if not os.path.exists("model"):
print ("Please download the model from VOSK Models and unpack as 'model' in the current folder.")
exit (1)
sample_rate=16000
model = Model("model")
rec = KaldiRecognizer(model, sample_rate)
process = subprocess.Popen(['ffmpeg', '-loglevel', 'quiet', '-i',
sys.argv[1],
'-ar', str(sample_rate) , '-ac', '1', '-f', 's16le', '-'],
stdout=subprocess.PIPE)
f = open("result.txt", "w+")
while True:
data = process.stdout.read(10000)
if len(data) == 0:
break
if rec.AcceptWaveform(data):
re = rec.Result()
print(re)
re = json.loads(re)
f.write(re['text'] + '\n')
else:
print(rec.PartialResult())
f.close()
# print(rec.FinalResult())
另存为 vosk 目录下的 voice2text.py 文件。
(可选步骤)步骤4a:调试命令行
步骤4给出的代码最适合处理mp3录音文件。如果你想要处理更多形式的音频,例如实时录音,或者更多的对话模式,例如电影对白,你可以参考官方的代码,地址是 vosk-api/python/example at master · alphacep/vosk-api · GitHub 。
步骤4的代码就是根据官方的 test_ffmpeg.py 代码修改而来。
步骤6:运行程序并识别文字
将需要识别的mp3/wav/mp4等音视频文件拷贝至 桌面的vosk目录内。例如,我需要识别的文件为 story.mp3。
进入CMD环境,输入 cd ~/Desktop/vosk 进入工作目录,然后输入 python voice2text.py story.mp3。
系统开始识别语音内容,你可以看到识别的文字在窗口内一段段显示出来。
识别效果
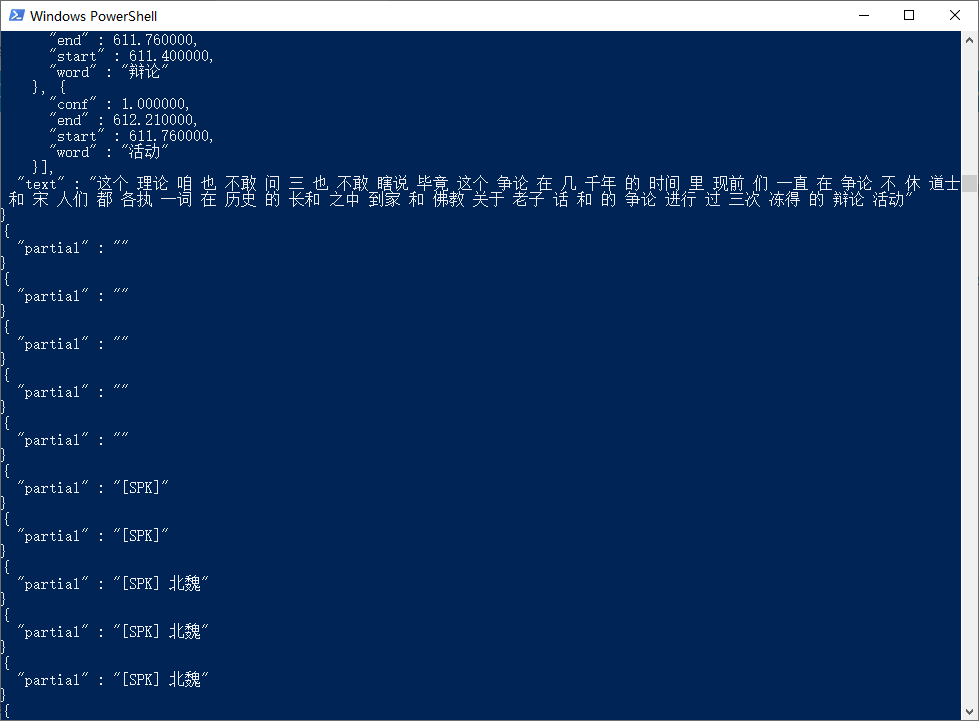
最终结果将存储到 vosk 目录下的 result.txt 文件内。你可以在word中进一步处理这些内容。
我有一大串格式化数据(例如JSON),我想使用Psychinruby同时保留格式转储到YAML。基本上,我希望JSON使用literalstyle出现在YAML中:---json:|{"page":1,"results":["item","another"],"total_pages":0}但是,当我使用YAML.dump时,它不使用文字样式。我得到这样的东西:---json:!"{\n\"page\":1,\n\"results\":[\n\"item\",\"another\"\n],\n\"total_pages\":0\n}\n"我如何告诉Psych以想要的样式转储标量?解
我想在一个没有Sass引擎的类中使用Sass颜色函数。我已经在项目中使用了sassgem,所以我认为搭载会像以下一样简单:classRectangleincludeSass::Script::FunctionsdefcolorSass::Script::Color.new([0x82,0x39,0x06])enddefrender#hamlengineexecutedwithcontextofself#sothatwithintemlateicouldcall#%stop{offset:'0%',stop:{color:lighten(color)}}endend更新:参见上面的#re
我是Google云的新手,我正在尝试对其进行首次部署。我的第一个部署是RubyonRails项目。我基本上是在关注thisguideinthegoogleclouddocumentation.唯一的区别是我使用的是我自己的项目,而不是他们提供的“helloworld”项目。这是我的app.yaml文件runtime:customvm:trueentrypoint:bundleexecrackup-p8080-Eproductionconfig.ruresources:cpu:0.5memory_gb:1.3disk_size_gb:10当我转到我的项目目录并运行gcloudprevie
对于作为String#tr参数的单引号字符串文字中反斜杠的转义状态,我觉得有些神秘。你能解释一下下面三个例子之间的对比吗?我特别不明白第二个。为了避免复杂化,我在这里使用了'd',在双引号中转义时不会改变含义("\d"="d")。'\\'.tr('\\','x')#=>"x"'\\'.tr('\\d','x')#=>"\\"'\\'.tr('\\\d','x')#=>"x" 最佳答案 在tr中转义tr的第一个参数非常类似于正则表达式中的括号字符分组。您可以在表达式的开头使用^来否定匹配(替换任何不匹配的内容)并使用例如a-f来匹配一
我想为我的Rails网络应用程序提供推荐功能。特别是,我想向新注册的用户推荐他可能想要关注的其他用户。Rails中是否有用于此目的的引擎/gem?如果没有,我应该从哪里开始构建它?谢谢。 最佳答案 有Coletivogemhttps://github.com/diogenes/coletivo我试了一下。在MySQL上运行。Neo4jhttp://neo4j.org真的很容易实现一个“跟随谁”。事实上,大多数展示其能力的样本都涉及“跟随谁”。快速提示-只有在JRuby上运行时,Neo4j.rb才会很酷。如果不是-使用Neograph
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
我可以在Azure网站上部署RubyonRails吗? 最佳答案 还没有。目前仅支持.NET和PHP。 关于ruby-on-rails-RubyonRails可以部署在Azure网站上吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/12964010/
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame
前置步骤我们都操作完了,这篇开始介绍jenkins的集成。话不多说,看操作1、登录进入jenkins后会让你选择安装插件,选择第一个默认的就行。安装完成后设置账号密码,重新登录。2、配置JDK和Git都需要执行路径,所以需要先把执行路径找到,先进入服务器的docker容器,2.1JDK的路径root@69eef9ee86cf:/usr/bin#echo$JAVA_HOME/usr/local/openjdk-82.2Git的路径root@69eef9ee86cf:/#whichgit/usr/bin/git3、先配置JDK和Git。点击:ManageJenkins>>GlobalToolCon