m_sequencer是定义在uvm_sequencer_item中的,uvm_sequencer_base类型的句柄,也就是说
m_sequencer源码如下:
class uvm_sequence_item extends uvm_transaction;
...
protected uvm_sequencer_base m_sequencer;
...
endclass
m_sequencer在类库中的关系如下图紫色箭头所示:
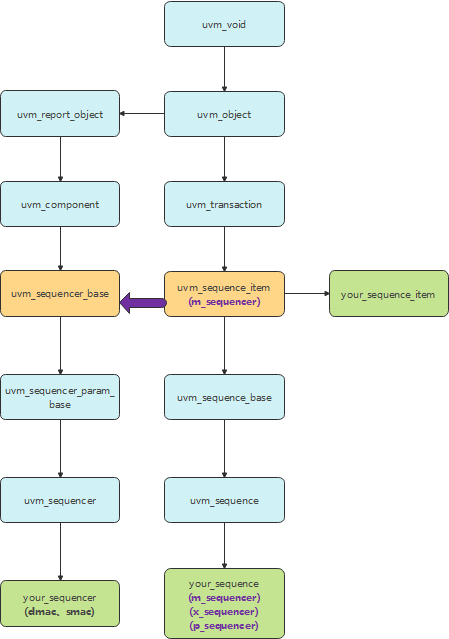
sequence属于object,sequencer属于component。
正常来说,sequence无法与sequencer进行交互,也不可能通过component的结构层次获得顶层配置及其他信息。因此需要一个能沟通sequence和sequencer的桥梁,m_sequencer就是这个桥梁。
通常调用uvm_do系列宏时,uvm能够自动根据传入的sequence或sequence_item调用对应的方法。使m_sequencer由指向uvm_sequencer_base,变为指向用户指定的sequencer,(例如类库中的your_sequencer),如下图蓝色虚线将变为紫色实线。

由此搭建了sequence和sequencer的桥梁,调用其他方法同理(不管是什么方法,没有改变m_sequencer指向给定的sequencer这一本质)。
因此使用者只需要调用所需方法,有关于m_sequencer的使用由uvm自动完成了。
值得注意的一点是用户指定的sequencer是uvm_sequencer_base的子类,对于m_sequencer而言,此时是父类句柄指向了子类对象,这也为下面的动态转换打下了基础。
p_sequencer是由`uvm_decalre_p_sequencer宏,定义在用户指定的sequence(例如类库中的your_sequence)中的,用户指定的类型的句柄(例如类库中的your_sequencer),也就是说
p_sequencer源代码如下:
`define uvm_declare_p_sequencer(SEQUENCER)
SEQUENCER p_sequencer; //SEQUENCER是由用户指定的类型
virtual function void m_set_p_sequencer();
super.m_set_p_sequencer(); //父类的m_set_p_sequencer是空函数
if (!$cast(p_sequencer, m_sequencer))
`uvm_fatal("DCLPSQ", $sformatf("%m %s Error casting p_sequencer, please verify that this sequence/sequence item is intended to execute on this type of sequencer", get_full_name()))
endfunction
可能到这里还是有些抽象,接下来我们进行一个更为形象的说明。
在sequence机制中,sequence就像是一个快递,它可以装入商品(sequence_itm),也可以装入另一个快递(sequence);sequencer就像是商家,他把快递交给物流公司(driver),物流公司再把快递交给用户(DUT)。
当有很多个快递时,物流公司怎么知道把哪个快递交给哪个用户呢,这就需要商家给快递上注明收货人和发货人的信息(your_sequencer中的dmac和smac等)。
也就是说your_sequence要访问your_sequencer中的成员变量dmac和smac,虽然这是your_sequence中的m_sequencer经过调用`uvm_do后已经指向了your_sequencer,但此时他的类型还是uvm_sequencer_base,而uvm_sequencer_base是your_sequencer的父类。父类句柄直接访问子类对象是不允许的。
因此我们需要将m_sequencer的类型转换成子类类型(也就是your_sequencer)。
首先我们在your_sequencer中声明了一个your_sequencer类型的句柄x_sequencer,再将m_sequencer动态转换成子类句柄,这样your_sequence就可以访问your_sequencer的成员变量了。
代码如下:
class your_sequence extends uvm_sequence #(your_transaction);
your_trasaction your_trans;
`uvm_object_utils(your_squence)
...
virtual task body();
your_sequencer x_sequencer;//声明x_sequencer
...
$cast(x_sequencer,m_sequencer);//动态转换
...
repeat(10)
begin
`uvm_do_with(m_trans,{your_trans.dmac==x_sequencer.dmac;
your_trans.smac==x_sequencer.smac;})//访问your_sequencer中的变量
end
...
endclass
如此一来,快递(your_sequence)上就有了一个标明了收货发货信息(dmac和smac)的快递面单,物流公司(driver)就可以按照快递单来派送了。
但是每次都需要通过声明x_sequencer,再动态转换就像人工手写快递面单一样繁琐,因此uvm将上述过程封装成立宏`uvm_declare_p_sequencer,以后就可以自动打印快递面单了
只需要在你需要的sequence中调用宏uvm_declare_p_sequencer(SEQUENCER) ,uvm将自动做以下事情:
你所需要做的只是考虑需要把哪些信息打印到快递面单上了。
1.《UVM实战 卷Ⅰ》 张强著
2.《芯片验证漫游指南——从系统理论到UVM的验证全视界》刘斌著
3. 芯片验证面试必考题:m_sequencer与p_sequencer的区别是什么?https://zhuanlan.zhihu.com/p/436911218
我刚刚开始从Ruby1.8.7升级到Ruby1.9.2(使用RVM)。我的所有应用程序都使用“脚本/服务器”(或“rails服务器”)和1.9.2运行,但是,只有Rails3.0.0RC应用程序可以与Passenger一起使用。Rails2.3.8应用给出的错误信息是:invalidbytesequenceinUS-ASCII我猜这是一个Passenger问题。我使用找到的RVM指南安装了Passenger2.2.15here.任何想法如何修复这个错误?谢谢。我已更新以包含堆栈跟踪:/Users/kevin/.rvm/gems/ruby-1.9.2-p0/gems/actionpack
尝试在我的Rails应用程序中导入CSV文件时,出现错误UTF-8中的无效字节序列。一切正常,直到我添加了一个gsub方法来将其中一个CSV列与我的数据库中的一个字段进行比较。当我导入CSV文件时,我想检查每一行的地址是否包含在特定客户端的不同地址数组中。我有一个带有alt_addresses属性的客户端模型,其中包含客户端地址的几种不同可能格式。然后我有一个引用模型(如果您熟悉本地SEO,您就会知道这个术语)。引用模型没有地址字段,但它有一个nap_correct?字段(NAP代表“姓名”、“地址”、“电话号码”)。如果CSV行的名称、地址和电话号码与我在该客户的数据库中拥有的相同,
前面一篇关于智能合约翻译文讲到了,是一种计算机程序,既然是程序,那就可以使用程序语言去编写智能合约了。而若想玩区块链上的项目,大部分区块链项目都是开源的,能看得懂智能合约代码,或找出其中的漏洞,那么,学习Solidity这门高级的智能合约语言是有必要的,当然,这都得在公链``````以太坊上,毕竟国内的联盟链有些是不兼容Solidity。Solidity是一种面向对象的高级语言,用于实现智能合约。智能合约是管理以太坊状态下的账户行为的程序。Solidity是运行在以太坊(Ethereum)虚拟机(EVM)上,其语法受到了c++、python、javascript影响。Solidity是静态类型
我对UTF-8编码有一些问题。我在这里阅读了一些帖子,但它仍然无法正常工作。这是我的代码:#!/bin/envruby#encoding:utf-8defdeterminefile=File.open("/home/lala.txt")file.eachdo|line|puts(line)type=line.match(/DOG/)puts('aaaaa')iftype!=nilputs(type[0])breakendendend这是我文件的前3行:;?lalalalal60000065535-1362490443-0000006334-0000018467-0000000041en
Halo,这里是Ppeua。平时主要更新C语言,C++,数据结构算法,Linux…感兴趣就关注我吧!你定不会失望。目录1.ls显示当前目录下的文件内内容2.pwd-显示用户当前所在的目录3.cd-改变工作目录。将当前工作目录改变到指定的目录下1.cd-回到上一次待的工作空间2.cd..返回上一层目录1.相对路径:cd../aurora2.绝对路径:cd/home/aurora/lesson1/aurora3.cd~进入用户家目录4.cd/进入root目录4.mkdir-新建目录5.rmdir/rm-删除1.rmdir删除空文件夹2.rm删除1.rm-f2.rm-i3.rm-r1.ls显示当前目
我有两个模型(项目和主题)。它们都属于具有has_many关联的第三个模型用户(用户有很多主题和项目)。Item和Theme都有_many:images.图像模型是一个多态关联,因此该表具有列imageable_id和imageable_type。如果我同时拥有一个ID为1的项目和一个ID为1的主题,那么该表将如下所示idimageable_idimageable_type------------------------------------11Item21Theme我正在使用declarative_authorization重写我的数据库的SQL查询,以防止用户访问他们帐户之外的项
在我的Rails应用程序上工作时,我在终端中使用以下命令创建了一个“Pins”脚手架:railsgeneratescaffoldPinsdescription:string--skip-stylesheets这会在我的应用程序中创建脚手架,然后我运行:rakedb:migrate一切顺利。我没有更改任何生成的页面,但是当我最终尝试访问localhost:3000上的新脚手架时,出现以下错误:RuntimeErrorinPinsController#indexInordertouserespond_with,firstyouneedtodeclaretheformatsyourcontr
在IRB中,我正在尝试以下操作:1.9.3p194:001>foo="\xBF".encode("utf-8",:invalid=>:replace,:undef=>:replace)=>"\xBF"1.9.3p194:002>foo.match/foo/ArgumentError:invalidbytesequenceinUTF-8from(irb):2:in`match'知道出了什么问题吗? 最佳答案 我猜"\xBF"已经认为它是用UTF-8编码的,所以当你调用encode时,它认为你正在尝试编码一个UTF-8中的UTF-8字符
我正在尝试上传一个csv文件,但收到UTF-8中的无效字节序列错误。我正在使用“roo”gem。我的代码是这样的:defupload_results_csvfilespreadsheet=MyFileUtil.open_file(file)header=spreadsheet.row(1)#THISLINERAISESTHEERROR(2..spreadsheet.last_row).eachdo|i|row=Hash[[header,spreadsheet.row(i)].transpose]......endclassMyFileUtildefself.open_file(file
我想在我的irb中输入德语变音符号,但出现奇怪的错误。我可以毫无问题地输入äöü的任何字符,但是每个ÄÖÜß都会导致以下错误:$irbruby-1.9.2-p136:001>?#hereIenteredÜbutitdisplaysonly?/Users/lorenz/.rvm/rubies/ruby-1.9.2-p136/lib/ruby/1.9.1/irb/ruby-lex.rb:728:in`blockinlex_int2':invalidbytesequenceinUTF-8(ArgumentError)我已经查看了很多关于Ruby、rvm和UTF-8的SO问题,但都没有帮助。大