首页最近被chatGPT刷屏,但翔二博主左看右看发现很多想法似乎都是一脉相通的,于是连夜从存档中找了一些文章尝试理一理它的理论路线。
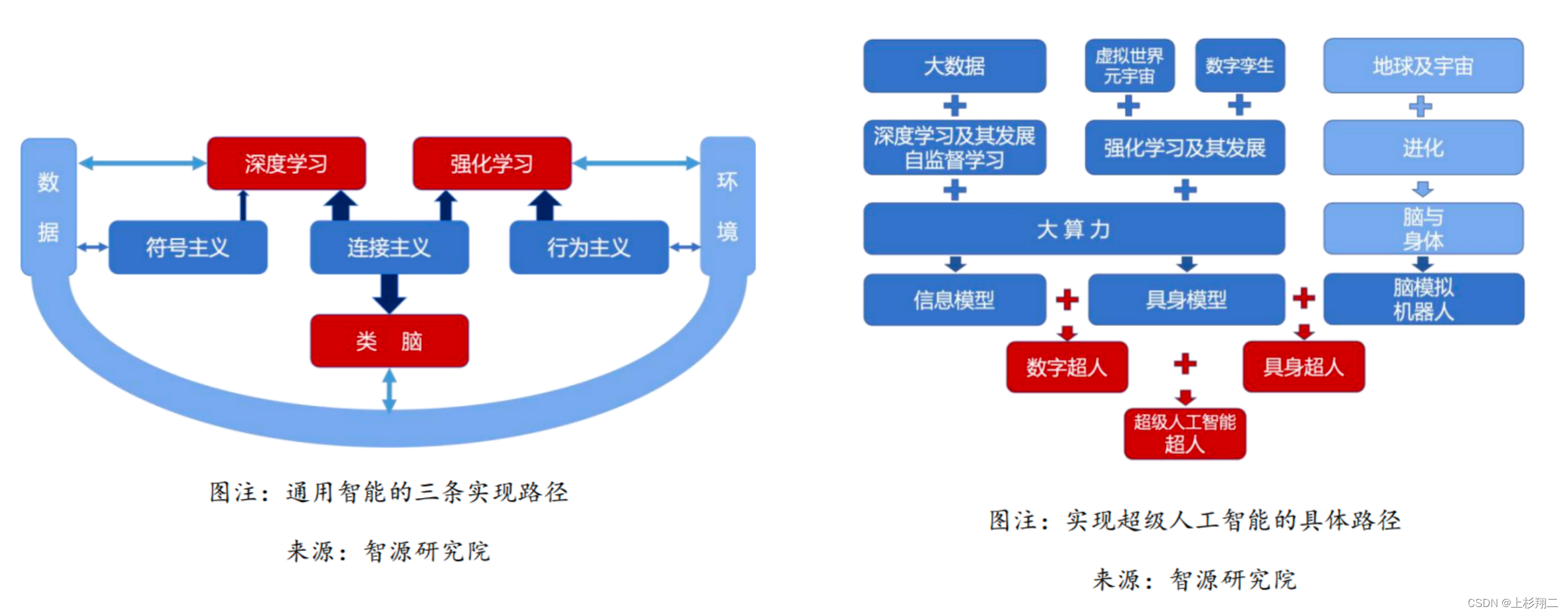
同时想到今年在智源人工智能前沿报告(2021-2022年度)中其实就有说道:
“未来三年,基于虚拟世界、实时时空环境训练的具身模型会取得较大的发展,如自动驾驶、机器人、游戏中数字人等······未来五到十年,超大规模预训练模型(信息模型)和具身模型将会结合,成为‘数字超人’,在知识能力以及跟环境的互动程度上,将比以往的人类都要强······具身模型和机器人也将结合,在物理世界出现能力比人类还要强的无人系统,即‘具身超人’。乐观估计,在未来三十年,数字超人和具身超人可能会结合,最终诞生超级人工智能。”
测了测chatGPT的性能后,好像这一切来的稍快了一点?
博主个人理解,它以更为embodied AI形式的指令作为输入,以训练/微调大规模的信息模型,并基于强化学习与真实世界做持续交互,已经很接近此处所提到的“数字超人”了。
关于chatGPT的基础介绍和使用本文不做过多介绍,可以参考各种报道文和知乎等等,此处推荐几份解读。
本篇博文先简要整理一下跟chatGPT相关Instruction Tuning的几篇论文。
Finetuned Language Models Are Zero-Shot Learners
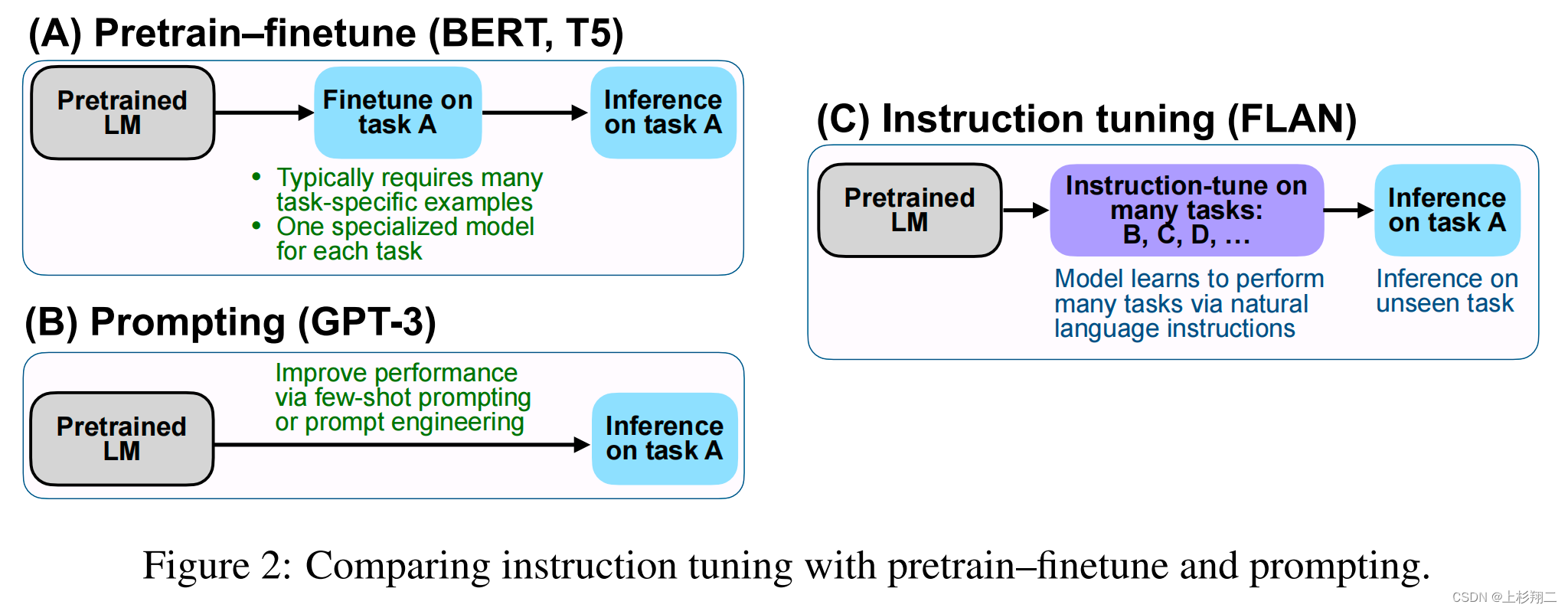
首先是ICLR22的FLAN模型,这篇文章明确提出 Instruction Tuning(指令微调)的技术,它的本质目的是想将 NLP 任务转换为自然语言指令,再将其投入模型进行训练,通过给模型提供指令和选项的方式,使其能够提升Zero-Shot任务的性能表现。
Motivation在于大规模的语言模型如GPT-3可以非常好地学习few-shot,但它在zero-shot上却不那么成功。例如, GPT-3在阅读理解、问题回答和自然语言推理等任务上的表现很一般,作者认为一个潜在的原因是,如果没有少量示例的zero-shot条件下,模型很难在与训练前数据格式(主要是prompts)维持一致。
既然如此,那么为什么不直接用自然语言指令做输入呢?如下图所示,不管是commonsense reasoning任务还是machine translation任务,都可以变为instruct的形式,然后利用大模型进行学习。在这种方式下,而当一个unseen task进入时,通过理解其自然语言语义可以轻松实现zero-shot的扩展,如natural language inference任务。
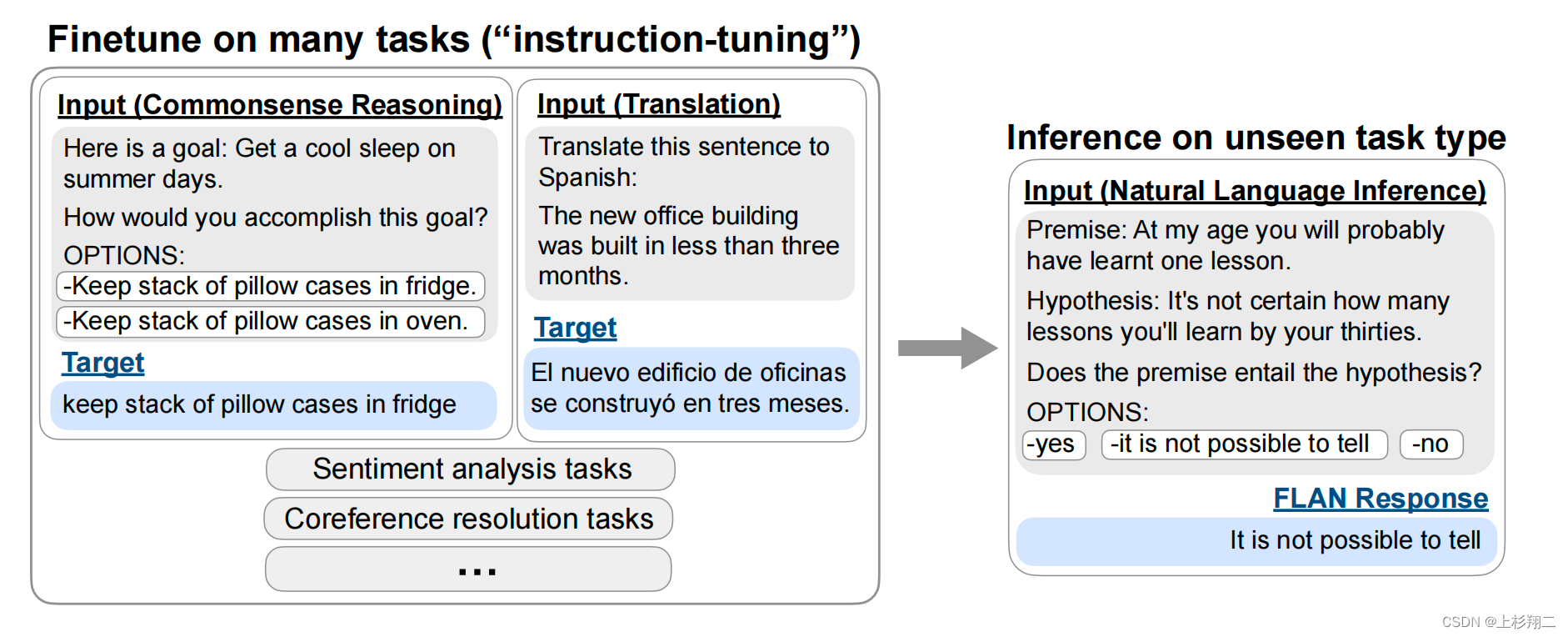
Instruction-tuning、Fine-tuning、Prompt-Tuning的区别在哪?
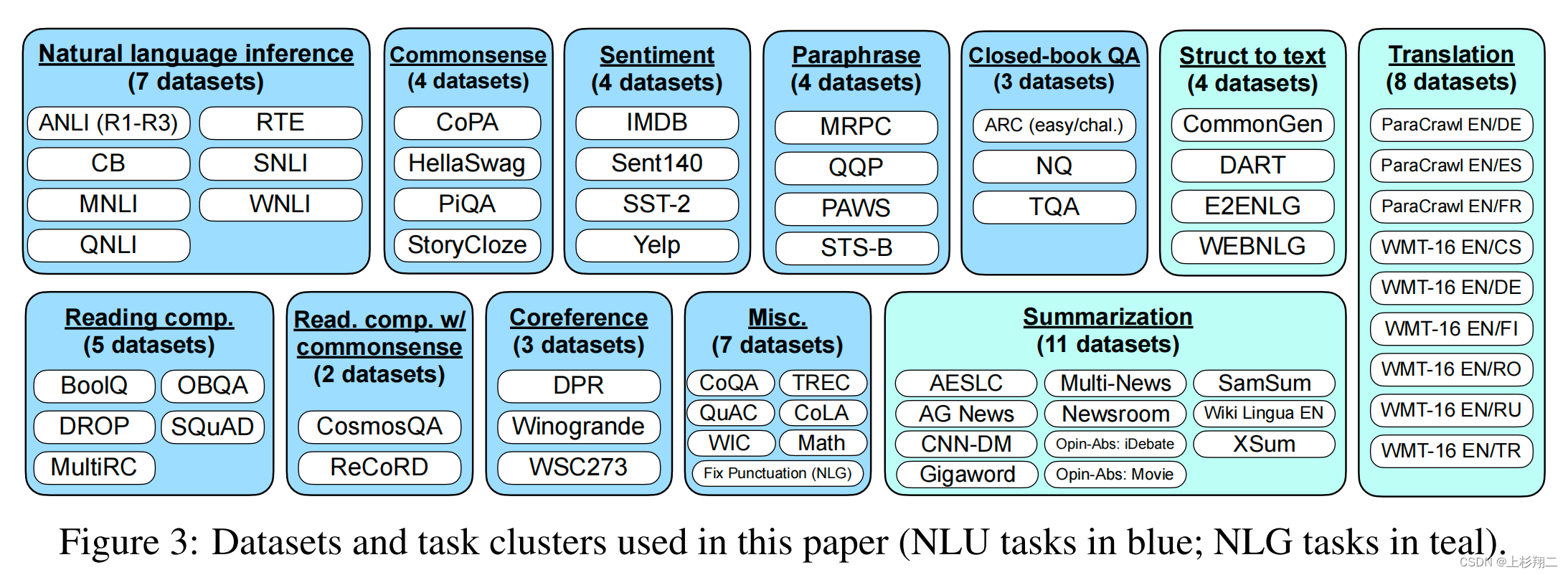
具体来说,作者提出的Finetuned LAnguage Net(FLAN)模型将62个NLP task分为12 cluster,同一个cluster内是相同的任务类型,如下图所示。
对于每个task,将为其手动构建10个独特template,作为以自然语言描述该任务的instructions。为了增加多样性,对于每个数据集,还包括最多三个“turned the task around”的模板(例如,对于情感分类,要求其生成电影评论的模板)。所有数据集的混合将用于后续预训练语言模型做instruction tuning,其中每个数据集的template都是随机选取的。如下图所示,Premise、Hypothesis、Options会被填充到不同的template中作为训练数据。
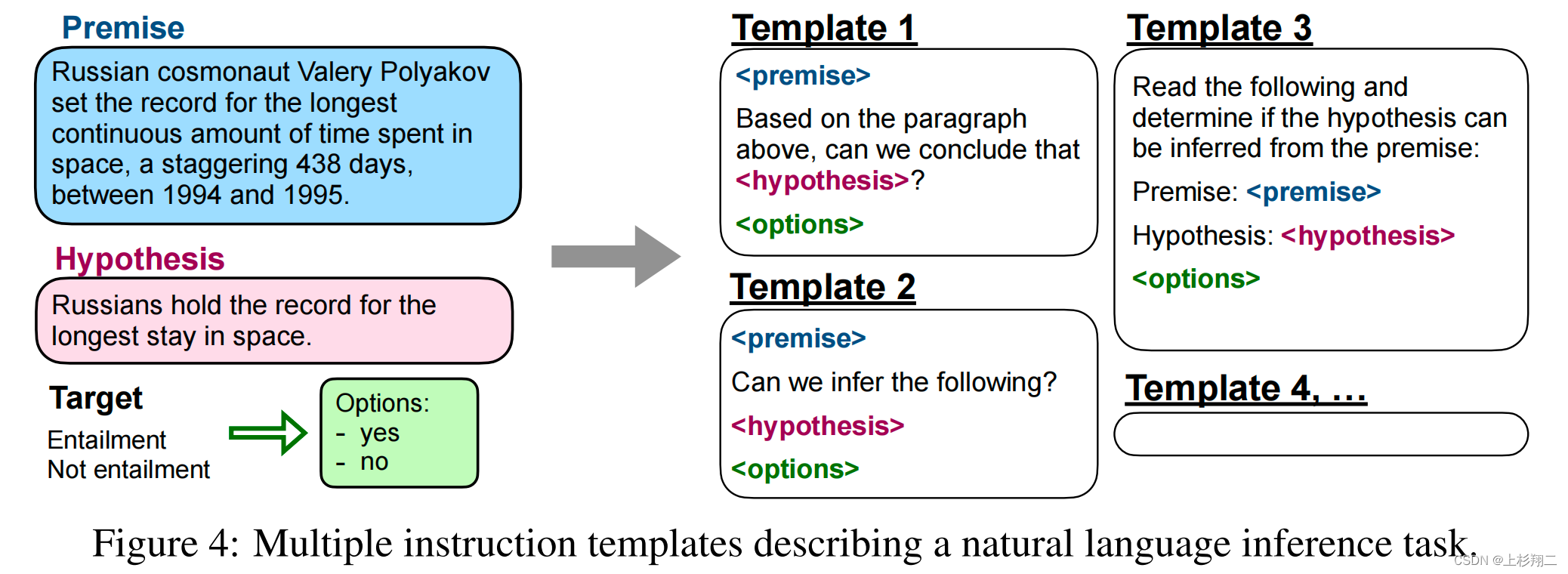
然后基于LaMDA-PT模型进行微调。LaMDA-PT是一个包含137B参数的自回归语言模型,这个模型在web文档(包括代码)、对话数据和维基百科上进行了预训练,同时有大约10%的数据是非英语数据。然后FLAN混合了所有构造的数据集在128核的TPUv3上微调60个小时。
在介绍instructGPT和chatGPT前,还有两份比较重要的前置工作,即Reinforcement Learning from Human Feedback (RLHF),如何从用户的明确需要中学习。
Fine-Tuning Language Models from Human Preferences
这份工作是将大模型往人类偏好进行结合的一次尝试,其使用强化学习PPO而不是监督学习来微调语言模型GPT-2。
为了弄清人类偏好,首先需要从预训练好的GPT-2 开始,并通过询问人工标注者四个生成样本中哪个样本最好来收集数据集。基于收集的数据集,尝试基于强化学习微调GPT,简要模型结构如下图,其需要训练两个模块一个是GPT模型(policy),一个是奖励模型(reward model),其中奖励模型用于模拟人类对四个样本的打分以代表其选择偏好。
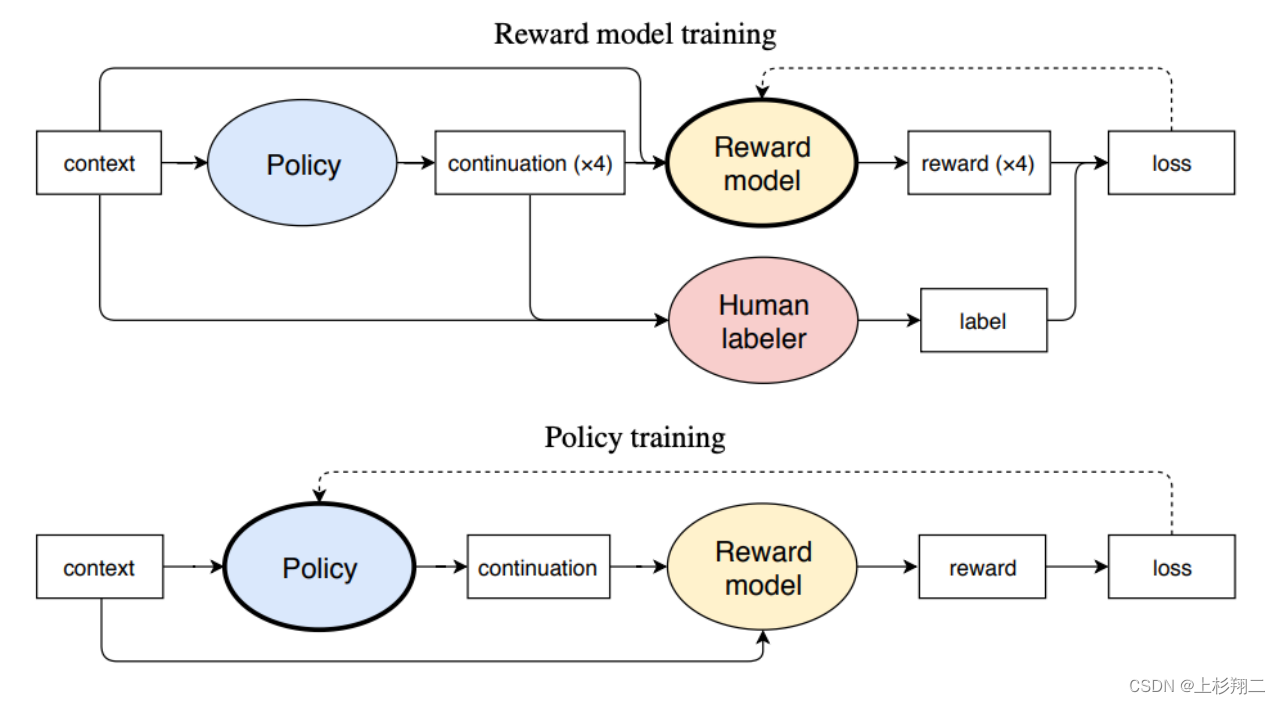
整体的训练过程是:
paper:https://arxiv.org/abs/1909.08593
code:https://github.com/openai/lm-human-preferences
这篇论文的主要启发在于,人类偏好的约束、使用PPO的训练方法可以使模型在online的过程中持续学习。
Learning to Summarize with Human Feedback
随后的这份工作会更为贴近instructGPT和chatGPT,其提出主要按照人类偏好的summarization场景中。其模型框架架构如下图所示,和instructGPT类似,主要分为三步:先收集人类在成对摘要上偏好的数据集,然后通过监督学习训练一个奖励模型(RM)来预测人类偏好的摘要。最后,利用奖励模型RM给出的分数去微调生成摘要的大模型,以上模型都基于GPT-3进行微调。
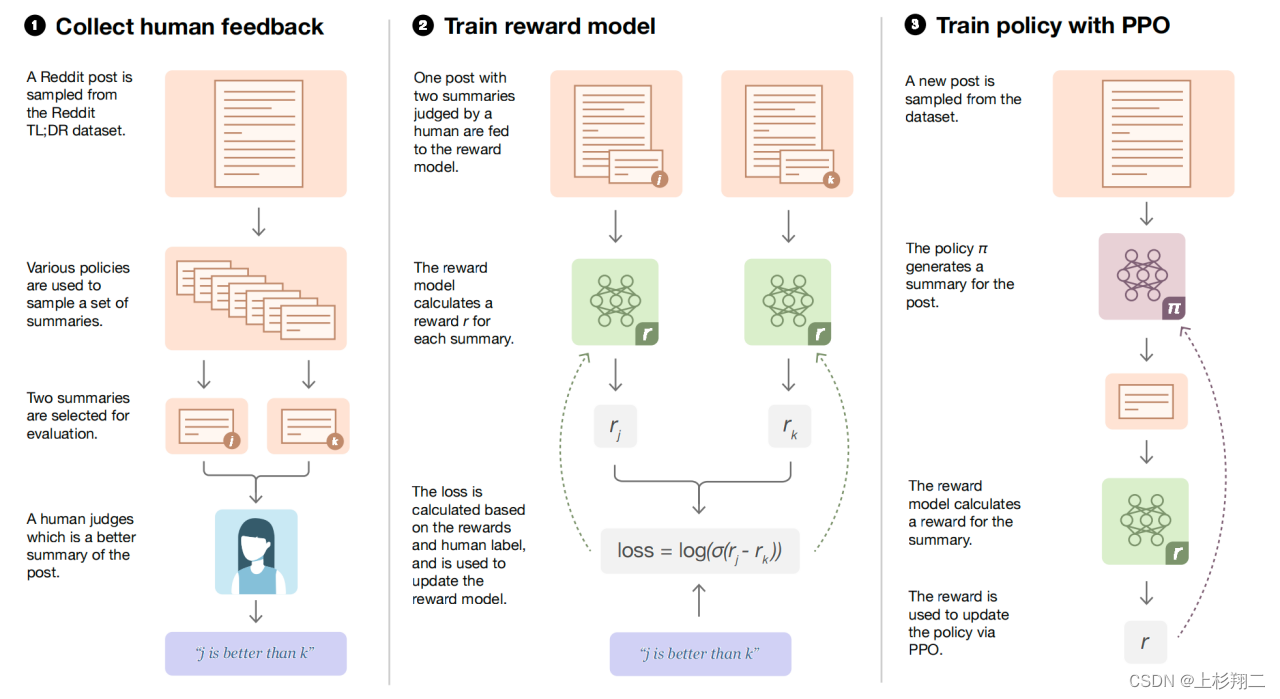
这份工作虽然局限于摘要,但在训练框架是为后续的instructGPT打下了基础,即人工标注+强化学习。
instructGPT
instructGPT从模型结构上与上一篇文章几乎一摸一样,但它通向了更为宽广的领域。通过收集带有更多人类instruct的自然语言文本句子,使其可以完成各种nlp任务,正式进化为一个全能模型。
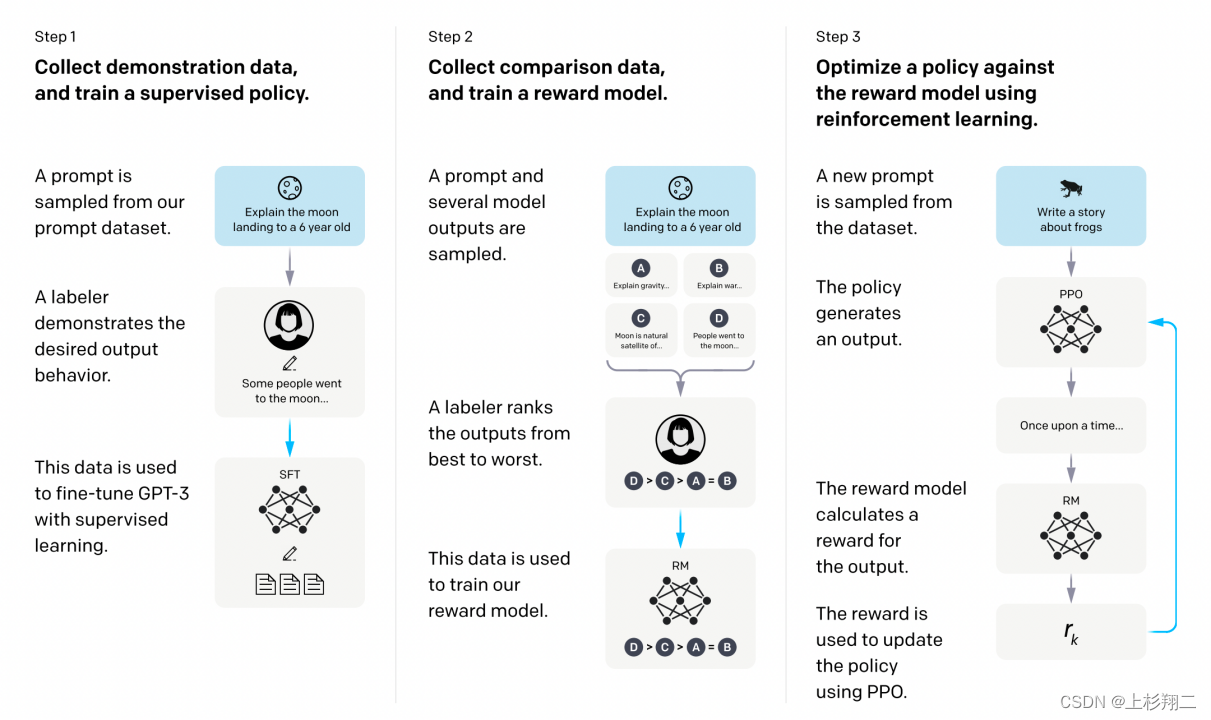
实现上仍然分为三个步骤,
更多细节可以见开头的讲解视频。
chatGPT
目前只知道chatGPT基于instructGPT进行训练,但具体细节没有更多的披露,但是从以上几份工作中,可以窥见一些技术路线。
如chatGPT可以轻轻松松根据人类的语言完成从对话、写诗、编故事、写代码等等等等等各种任务,大概率就是基于FLAN模型这种迁移任务的方式,从而能够满足各位用户老爷们的奇怪需要。而instructGPT则应该是chatGPT用于训练的主要架构,包括数据集构建、模型框架和训练目标等等。
最后想再放一次这张图,博主也需要再好好悟一悟。
英文版英文链接关注公众号在“亚特兰蒂斯的回声”中踏上一段难忘的冒险之旅,深入未知的海洋深处。足智多谋的考古学家AriaSeaborne偶然发现了一件古代神器,揭示了一张通往失落之城亚特兰蒂斯的隐藏地图。在她神秘的导师内森·兰登教授的指导和勇敢的冒险家亚历克斯·默瑟的帮助下,阿丽亚开始了一段危险的旅程,以揭开这座传说中城市的真相。他们的冒险之旅带领他们穿越险恶的大海、神秘的岛屿和充满陷阱和谜语的致命迷宫。随着Aria潜在的魔法能力的觉醒,她被睿智勇敢的QueenNeria的幻象所指引,她让她为即将到来的挑战做好准备。三人组揭开亚特兰蒂斯令人惊叹的隐藏文明,并了解到邪恶的巫师马拉卡勋爵试图利用其古
2022年底,OpenAI的预训练模型ChatGPT给人工智能领域的爱好者和研究人员留下了深刻的印象和启发,他展现的惊人能力将人工智能的研究和应用热度推向高潮,网上也充斥着和ChatGPT的各种聊天,他可以作诗、写小说、写代码、讨论疫情问题等。下面就是一些他的神回复:人命关天的坑: 写歌,留给词作者的机会不多了。。。 回答人类怎么样面对人工智能: 什么是ChatGPT?借用网上的一段介绍,ChatGPT是由人工智能研究实验室OpenAI在2022年11月30日发布的全新聊天机器人模型,一款人工智能技术驱动的自然语言处理工具。它能够通过学习和理解人类的语言来进行对话,还能根据聊天的上下文进行互动
目录ChatGPT简介技术原理应用未来发展ChatGPT的10 种用法ChatGPT简介ChatGPT是一种基于深度学习的大型语言模型,由OpenAI公司开发。技术原理GPT是GenerativePre-trainedTransformer的缩写,意为生成式预训练变压器。它的技术原理是使用了一个基于注意力机制的变压器(Trans
♥️作者:白日参商🤵♂️个人主页:白日参商主页♥️坚持分析平时学习到的项目以及学习到的软件开发知识,和大家一起努力呀!!!🎈🎈加油!加油!加油!加油🎈欢迎评论💬点赞👍🏻收藏📂加关注+!「想体验ChatGPT中文聊天?」那快进来,你用不上算我输项目场景:项目条件一、那就开始吧1、安装ChatGPT-Desktop2、OpenAPI设置二、使用实例恭喜你!!!配置成功了!!!API和URL都是博主免费提供给大家的!!!恭喜你!!!配置成功了!!!API和URL都是博主免费提供给大家的!!!🎈🎈加油!加油!加油!加油🎈欢迎评论💬点赞👍🏻收藏📂加关注+!项目场景:近几个月可以说ChatGPT是火得一
ChatGPT掀起了AI股历史上最疯狂的一轮市值狂飙。自春节后至今,ChatGPT概念股开始了暴走模式,短短半月时间,海天瑞声、开普云等ChatGPT概念股市值累计增加了近1400亿。如此的爆炸效应,得益于ChatGPT所展现出商业化落地的巨大潜力。要知道,在此之前,无论是十年AI投入超千亿的百度,还是困在硬件化里的AI四小龙,都在重复着AI商业化难落地的故事。ChatGPT的出现,让AI从生产力的赋能者直接成为一种创造生产力的工具。随着订阅模式的推出,ChatGPT已经成为第一个以AI技术为核心直接变现的消费者应用。本文持有以下核心观点:1、ChatGPT是AI技术迭代的受益者。过去受限技术
文章目录前言1.AI的发展历程2.我是如何接触到人工智能的概念和产品的3.对于ChatGPT的一点看法4.AI对大学毕业生的职业发展的利与弊5.对于AI的思考和问题前言随着ChatGPT的爆火,生成式AI,大模型的人工智能被越来越多的人注意到,同时他也带来了许多问题。本文将对几方面进行探讨。1.AI的发展历程远古时期在公元前第一个千禧年,中国,印度和希腊哲学家都提出了一些推理的研究理论,比如亚里士多德(Aristotle)进行了演绎推理三段论的完整分析,欧几里得(Euclid)所著Elements是一种形式推理的模型,MuḥammadibnMūsāal-Khwārizmī,发明了代数学,即我们
当前科技领域最有热度的话题,无疑是OpenAI新提出的大规模对话语言模型ChatGPT,一经发布上线,短短五天就吸引了百万用户,仅一个多月的时间月活已然破亿,并且热度一直在持续发酵,各行各业的从业人员、企业机构都开始体验关注甚至自研“类ChatGPT”模型。这里,笔者从一位NLP从业人员的角度谈一谈对ChatGPT的一些看法和思考。1、ChatGPT诞生之路1.1BERT2018年,谷歌提出BERT(BidirectionalEncoderRepresentationfromTransformer)模型,一时之间疯狂屠榜,在各种自然语言处理领域建模任务中取得了最佳的成绩,NLP自此进入了大规模
解开谜团:深入探索ChatGPT的技术奇迹。ChatGpt无处不在,无论是在播客、博客、YouTube还是社交媒体上。当我注意到这项新技术如此受欢迎时,我决定试一试,我被震惊了!有很多关于ChatGpt及其魔力的博客,但在这篇博客中,我将深入探讨其内部技术及其工作原理!ChatGpt简介根据OpenAI,ChatGpt被描述为:“我们训练了一个名为ChatGpt的模型,它以对话方式进行交互。对话格式使ChatGpt可以回答后续问题、承认错误、挑战不正确的前提并拒绝不适当的请求。ChatGPT是InstructGPT的兄弟模型,它经过训练可以按照提示中的说明进行操作并提供详细的响应。”OpenA
以前我们经常打趣说:***,你out了!当然了,玩笑成分居多。但是如果作为一名技术人员,现在还没有听说过ChatGPT,那么你可能真的“out”了。比尔·盖茨说,ChatGPT的重要性堪比互联网的发明,甚至它“将改变我们的世界”。ChatGPT得到科技界大佬的如此推崇,那么,ChatGPT到底是什么?ChatGPT是2022年11月底,美国OpenAI公司推出的一款人工智能聊天机器人。两个月后,ChatGPT的月活用户已经突破1亿,成为有史以来增长速度最快的消费者应用程序。ChatGPT功能极其强大,它能够通过学习和理解人类的语言进行对话,还能根据上下文进行互动,实现像人类一样的聊天交流。除了
近期,AI安全问题闹得沸沸扬扬,多国“禁令”剑指ChatGPT。自然语言大模型采用人类反馈的增强学习机制,也被担心会因人类的偏见“教坏”AI。4月6日,OpenAI官方发声称,从现实世界的使用中学习是创建越来越安全的人工智能系统的“关键组成部分”,该公司也同时承认,这需要社会有足够时间来适应和调整。至于这个时间是多久,OpenAI也没给出答案。大模型背后的“算法黑箱”无法破解,开发它的人也搞不清机器作答的逻辑。十字路口在前,一些自然语言大模型的开发者换了思路,给类似GPT的模型立起规矩,让对话机器人“嘴上能有个把门的”,并“投喂”符合人类利益的训练数据,以便它们输出“更干净”的答案。这些研发