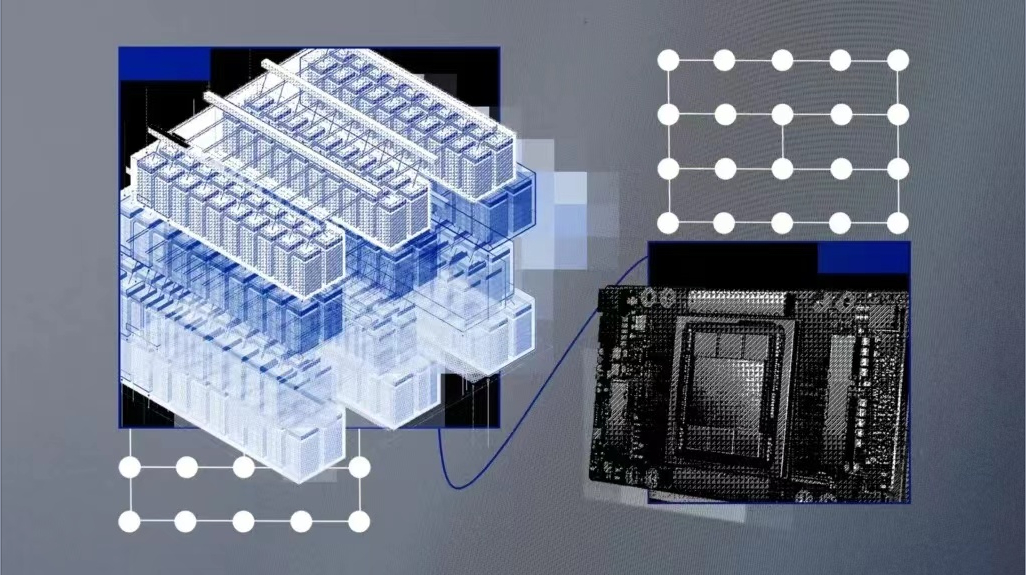
 基础模型是基于大量未标记数据训练的AI模型,它们的通用性意味着只需微调就可以用于一系列不同的任务。它们的规模非常庞大,需要大量且成本高昂的计算能力。因此正如专家表示,计算能力将成为开发下一代大规模基础模型的最大瓶颈,训练它们需要花费大量算力和时间。训练可以运行数百亿个或数千亿个参数的模型,需要采用高性能的计算硬件,包括网络、并行文件系统和裸机节点等。这些硬件很难部署,运行成本也很高。微软于2020年5月为OpenAI建造了AI超级计算机,并托管在Azure云平台中。但IBM表示,它们是由硬件驱动的,这增加了成本,并限制了灵活性。云端AI超级计算机因此,IBM创建了名为Vela的“专门专注于大规模AI”的系统。 Vela可以根据需要部署到IBM的任何一个云数据中心中,它本身就是一个“虚拟云”。与构建物理的超级计算机相比,虽然这种方法在计算能力方面有所下降,但创造了一个更灵活的解决方案。云计算解决方案通过API接口为工程师提供资源,更方便地访问广泛的IBM云生态系统以进行更深入的集成,并能够根据需要扩展性能。 IBM工程师解释说,Vela能够访问IBM云对象存储上的数据集,而不是构建自定义存储后端。以往这些基础设施必须单独构建到超级计算机中。 任何AI超级计算机的关键组成部分都是大量的GPU以及连接它们的节点。Vela其实是将每个节点配置为虚拟机(而不是裸机),这是最常见的方法,也被广泛认为是AI训练最理想的方法。 Vela是如何构建的? 云端虚拟计算机的弊病之一是性能不能保证。为了解决性能下降问题,并在虚拟机内部提供裸机性能,IBM工程师找到了一种释放全部节点性能(包括GPU、CPU、网络和存储),并将负载损耗降低到5%以下的方法。这涉及到为虚拟化配置裸机主机,支持虚拟机扩展、大型页面和单根IO虚拟化,以及真实地表示虚拟机内的所有设备和连接;还包括网卡与CPU和GPU匹配,以及它们彼此之间如何桥接起来。完成这些工作后,他们发现虚拟机节点的性能“接近裸机”。此外,他们还致力于设计具有大型GPU内存和大量本地存储的AI节点,用于缓存AI训练数据、模型和成品。在使用PyTorch的测试中,他们发现通过优化工作负载通信模式,与超级计算中使用的类似Infiniband的更快的网络相比,他们还能够弥补以太网网络相对较慢的瓶颈。配置方面,每个Vela都采用了8个80GB A100 GPU、两个第二代Intel Xeon可扩展处理器、1.5TB内存和四个3.2TB NVMe硬盘驱动器,并能够以任何规模部署到IBM在全球的任何一个云数据中心。IBM的工程师表示:“拥有合适的工具和基础设施是提高研发效率的关键因素。许多团队选择遵循为AI构建传统超级计算机的可靠路径……我们一直在研究一种更好的解决方案,以提供高性能计算和高端用户生产力的双重好处。”
基础模型是基于大量未标记数据训练的AI模型,它们的通用性意味着只需微调就可以用于一系列不同的任务。它们的规模非常庞大,需要大量且成本高昂的计算能力。因此正如专家表示,计算能力将成为开发下一代大规模基础模型的最大瓶颈,训练它们需要花费大量算力和时间。训练可以运行数百亿个或数千亿个参数的模型,需要采用高性能的计算硬件,包括网络、并行文件系统和裸机节点等。这些硬件很难部署,运行成本也很高。微软于2020年5月为OpenAI建造了AI超级计算机,并托管在Azure云平台中。但IBM表示,它们是由硬件驱动的,这增加了成本,并限制了灵活性。云端AI超级计算机因此,IBM创建了名为Vela的“专门专注于大规模AI”的系统。 Vela可以根据需要部署到IBM的任何一个云数据中心中,它本身就是一个“虚拟云”。与构建物理的超级计算机相比,虽然这种方法在计算能力方面有所下降,但创造了一个更灵活的解决方案。云计算解决方案通过API接口为工程师提供资源,更方便地访问广泛的IBM云生态系统以进行更深入的集成,并能够根据需要扩展性能。 IBM工程师解释说,Vela能够访问IBM云对象存储上的数据集,而不是构建自定义存储后端。以往这些基础设施必须单独构建到超级计算机中。 任何AI超级计算机的关键组成部分都是大量的GPU以及连接它们的节点。Vela其实是将每个节点配置为虚拟机(而不是裸机),这是最常见的方法,也被广泛认为是AI训练最理想的方法。 Vela是如何构建的? 云端虚拟计算机的弊病之一是性能不能保证。为了解决性能下降问题,并在虚拟机内部提供裸机性能,IBM工程师找到了一种释放全部节点性能(包括GPU、CPU、网络和存储),并将负载损耗降低到5%以下的方法。这涉及到为虚拟化配置裸机主机,支持虚拟机扩展、大型页面和单根IO虚拟化,以及真实地表示虚拟机内的所有设备和连接;还包括网卡与CPU和GPU匹配,以及它们彼此之间如何桥接起来。完成这些工作后,他们发现虚拟机节点的性能“接近裸机”。此外,他们还致力于设计具有大型GPU内存和大量本地存储的AI节点,用于缓存AI训练数据、模型和成品。在使用PyTorch的测试中,他们发现通过优化工作负载通信模式,与超级计算中使用的类似Infiniband的更快的网络相比,他们还能够弥补以太网网络相对较慢的瓶颈。配置方面,每个Vela都采用了8个80GB A100 GPU、两个第二代Intel Xeon可扩展处理器、1.5TB内存和四个3.2TB NVMe硬盘驱动器,并能够以任何规模部署到IBM在全球的任何一个云数据中心。IBM的工程师表示:“拥有合适的工具和基础设施是提高研发效率的关键因素。许多团队选择遵循为AI构建传统超级计算机的可靠路径……我们一直在研究一种更好的解决方案,以提供高性能计算和高端用户生产力的双重好处。” 我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
我正在为一个项目制作一个简单的shell,我希望像在Bash中一样解析参数字符串。foobar"helloworld"fooz应该变成:["foo","bar","helloworld","fooz"]等等。到目前为止,我一直在使用CSV::parse_line,将列分隔符设置为""和.compact输出。问题是我现在必须选择是要支持单引号还是双引号。CSV不支持超过一个分隔符。Python有一个名为shlex的模块:>>>shlex.split("Test'helloworld'foo")['Test','helloworld','foo']>>>shlex.split('Test"
我不确定传递给方法的对象的类型是否正确。我可能会将一个字符串传递给一个只能处理整数的函数。某种运行时保证怎么样?我看不到比以下更好的选择:defsomeFixNumMangler(input)raise"wrongtype:integerrequired"unlessinput.class==FixNumother_stuffend有更好的选择吗? 最佳答案 使用Kernel#Integer在使用之前转换输入的方法。当无法以任何合理的方式将输入转换为整数时,它将引发ArgumentError。defmy_method(number)
两者都可以defsetup(options={})options.reverse_merge:size=>25,:velocity=>10end和defsetup(options={}){:size=>25,:velocity=>10}.merge(options)end在方法的参数中分配默认值。问题是:哪个更好?您更愿意使用哪一个?在性能、代码可读性或其他方面有什么不同吗?编辑:我无意中添加了bang(!)...并不是要询问nobang方法与bang方法之间的区别 最佳答案 我倾向于使用reverse_merge方法:option
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我有一个只接受一个参数的方法:defmy_method(number)end如果使用number调用方法,我该如何引发错误??通常,我如何定义方法参数的条件?比如我想在调用的时候报错:my_method(1) 最佳答案 您可以添加guard在函数的开头,如果参数无效则引发异常。例如:defmy_method(number)failArgumentError,"Inputshouldbegreaterthanorequalto2"ifnumbereputse.messageend#=>Inputshouldbegreaterthano
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub