拓扑排序是将偏序的数据线性化的一种排序方法。复习下偏序和全序的概念:
全序关系是偏序关系的一个子集。
全序是集合内任何一对元素都是可比较的,比如数轴上的点都具有一个线性的数值,因此根据数值就可以进行比较。
偏序是集合内不是所有元素都是可以比较的,比如平面内的点由横坐标和纵坐标组成,是不可直接比较大小的。这是因为横坐标和纵坐标是两个维度,在每个维度内都可以用数值比较,但是维度之间不可量化比较(就像学习成绩和身体素质之间无法量化比较)。当然偏序是个数学概念,未必是多维度引发的不可比较,只需满足以下关系即满足偏序关系:
设 P 是集合,P 上的二元关系“≤”满足以下三个条件,则称“≤”是 P 上的偏序关系(或部分序关系):
(1)自反性:a≤a,∀a∈P;
(2) 反对称性:∀a,b∈P,若 a≤b 且b≤a,则 a=b;
(3) 传递性:∀a,b,c∈P,若 a≤b 且b≤c,则 a≤c;
注意这里的“≤”是一个自定义的二元运算符,而不是通常的线性运算的大小关系。
理解了偏序关系之后,拓扑排序就是将偏序关系线性化。举一个具体场景,在有向无环图中,“节点 A 是否可由节点 B 到达”即是一种偏序关系。在该有向无环图中节点,在不移动的情况下可以到达自身,因此满足自反性。且在有向无环图中不存在环,若 A 可到达 B 且 B可到达A,则A,B 必是相同节点,因此满足反对称性。当节点 A 可以到达节点 B,且节点 B 可以到达节点C 时,节点 A 也可以到达节点 C,因此满足传递性。
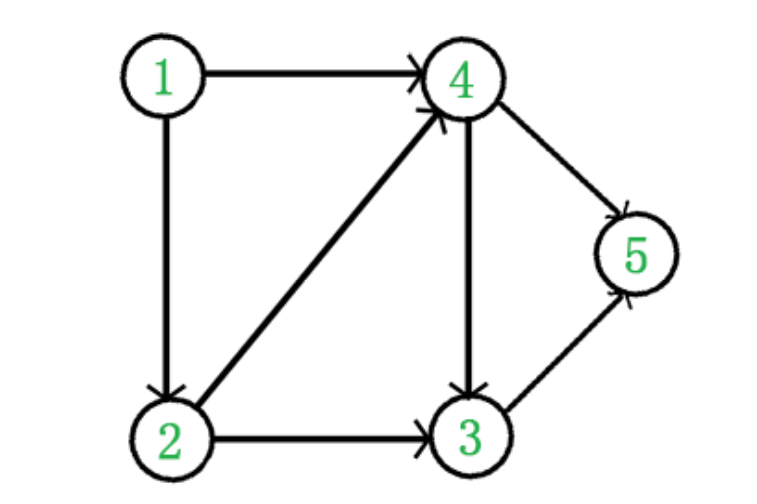
在该场景下,拓扑排序即是将有向无环图中所有节点按照“节点 A 是否可由节点 B 到达”来进行线性化排序。如上图所示,对它进行拓扑排序可以使用深度优先算法完成,深度优先算法可以复习课件,其过程大概如下。
这种方法可以将满足偏序关系的有向无环图线性化为?一种排序结果:1,2,4,3,5。当然对于更复杂的有向无环图可能有多种合法的排序结果。
实现代码如下:
//
// Created by lenovo on 2022/5/1.
//
#include <utility>
#include "iostream"
#include "vector"
#include "fstream"
using namespace std;
typedef struct EdgeNode
{
int index; //邻接点
struct EdgeNode *next; //链表,指向下一个邻接点
}EdgeNode;
typedef struct PointNode //顶点表节点
{
int in; //顶点入度
int data; //顶点信息
EdgeNode* firstEdge; //边表头指针
PointNode(){in=NULL;data= NULL;firstEdge= nullptr;}
}PointNode;
typedef struct Graph{
int NumPoint,NumEdge;
PointNode* arr;
}Graph;
void read_file(Graph* G){ //构造图Graph
ifstream inputData;
string input_file_path="..\\input.txt"; //示例输入在同级目录input.txt
inputData.open(input_file_path, ios::in);
string line;
int tmp=0;
int i=0;
EdgeNode *e;
while (inputData>>line){
int bracketPos = line.find(',');
int from = stoi(line.substr(0, bracketPos));
int to= stoi(line.substr(bracketPos+1,line.size()-bracketPos));
G->NumEdge++; //增加边
if(from!=tmp){tmp=from;G->NumPoint++;} //增加新的节点
/*保存边信息*/
e = (EdgeNode*)malloc(sizeof(EdgeNode));
e->index = to;
e->next = G->arr[from].firstEdge;
G->arr[from].firstEdge = e;
G->arr[to].in++;
}
inputData.close();
}
/*获取输入的边的数量*/
int read_num(){
ifstream inputData;
string input_file_path="..\\input.txt";
inputData.open(input_file_path, ios::in);
string line;
int tmp=0;
while (inputData>>line){
tmp++;
}
inputData.close();
return tmp;
}
int ToupuSort(Graph* G){
EdgeNode* edge;
int next;
vector<int> stack;
int count=0;
for(int i=0;i<G->NumPoint;++i){ //栈stack存储入度为0的节点,需排除0节点
if(G->arr[i].in==0)
stack.push_back(i);
}
int out;
while (stack[0]!=stack.back()){ //当栈为非空
out=stack.back();
cout<<out<<",";
stack.pop_back();
count++;
for(edge=G->arr[out].firstEdge;edge;edge=edge->next){ //更新邻接点的入度,-1
next=edge->index;
if(!(--G->arr[next].in)) //邻接节点入度原为1,则入栈
stack.push_back(next);
}
}
if(count<G->NumPoint){ //有环
return 0;
}else
return 1; //无环,且全部输出
}
int main(){
Graph G;
PointNode arry[read_num()];
G.arr=arry;
read_file(&G); //构建图
ToupuSort(&G); //输出拓扑排序
return 0;
}
示例输入:
1,2
1,4
2,4
2,3
3,5
4,3
4,5
示例输出:
1,2,4,3,5
我需要用任何语言编写一个算法,根据3个因素对数组进行排序。我以度假村为例(如Hipmunk)。假设我想去度假。我想要最便宜的地方、最好的评论和最多的景点。但是,显然我找不到在所有3个中都排名第一的方法。Example(assumingthereare20importantattractions):ResortA:$150/night...98/100infavorablereviews...18of20attractionsResortB:$99/night...85/100infavorablereviews...12of20attractionsResortC:$120/night
我正在尝试按Rails相关模型中的字段进行排序。我研究的所有解决方案都没有解决如果相关模型被另一个参数过滤?元素模型classItem相关模型:classPriority我正在使用where子句检索项目:@items=Item.where('company_id=?andapproved=?',@company.id,true).all我需要按相关表格中的“位置”列进行排序。问题在于,在优先级模型中,一个项目可能会被多家公司列出。因此,这些职位取决于他们拥有的company_id。当我显示项目时,它是针对一个公司的,按公司内的职位排序。完成此任务的正确方法是什么?感谢您的帮助。PS-我
我正在构建一个小部件来显示奥运会的奖牌数。我有一个“国家”对象的集合,其中每个对象都有一个“名称”属性,以及奖牌计数的“金”、“银”、“铜”。列表应该排序:1.首先是奖牌总数2.如果奖牌相同,按类型分割(金>银>铜,即2金>1金+1银)3.如果奖牌和类型相同,则按字母顺序子排序我正在用ruby做这件事,但我想语言并不重要。我确实找到了一个解决方案,但如果感觉必须有更优雅的方法来实现它。这是我做的:使用加权奖牌总数创建一个虚拟属性。因此,如果他们有2个金牌和1个银牌,加权总数将为“3.020100”。1金1银1铜为“3.010101”由于我们希望将奖牌数排序为最高的,因此列表按降序排
例如,假设我有一个名为Products的模型,并且在ProductsController中,我有以下代码用于product_listView以显示已排序的产品。@products=Product.order(params[:order_by])让我们想象一下,在product_listView中,用户可以使用下拉菜单按价格、评级、重量等进行排序。数据库中的产品不会经常更改。我很难理解的是,每次用户选择新的order_by过滤器时,rails是否必须查询,或者rails是否能够以某种方式缓存事件记录以在服务器端重新排序?有没有一种方法可以编写它,以便在用户排序时rails不会重新查询结果
我有一个对象如下:[{:id=>2,:fname=>"Ron",:lname=>"XXXXX",:photo=>"XXX"},{:id=>3,:fname=>"Dain",:lname=>"XXXX",:photo=>"XXXXXXX"},{:id=>1,:fname=>"Bob",:lname=>"XXXXXX",:photo=>"XXXX"}]我想按fname排序,不区分大小写,所以它会导致编号:1,3,2我该如何排序?我正在尝试:@people.sort!{|x,y|y[:fname]x[:fname]}但这没有任何效果。 最佳答案
有人可以告诉我如何根据自定义字符串对嵌套数组进行排序吗?比如有没有办法排序:[['Red','Blue'],['Green','Orange'],['Purple','Yellow']]“橙色”、“黄色”,然后是“蓝色”?最终结果如下所示:[['Green','Orange'],['Purple','Yellow'],['Red','Blue']]它不是按字母顺序排序的。我很想知道我是否可以定义要排序的值以实现上述目标。 最佳答案 sort_by对于这种排序总是非常方便:a=[['Red','Blue'],['Green','Ora
我有以下现有的Dog对象数组,它们按age属性排序:classDogattr_accessor:agedefinitialize(age)@age=ageendenddogs=[Dog.new(1),Dog.new(4),Dog.new(10)]我现在想插入一条新的狗记录,并将它放在数组中的正确位置。假设我想插入这个对象:another_dog=Dog.new(8)我想把它插入到数组中,让它成为数组中的第三项。这是一个人为的示例,旨在演示我特别想如何将一个项目插入到现有的有序数组中。我意识到我可以创建一个全新的数组并重新对所有对象进行排序,但这不是我的目标。谢谢!
我有一个这样的哈希{55=>{:value=>61,:rating=>-147},89=>{:value=>72,:rating=>-175},78=>{:value=>64,:rating=>-155},84=>{:value=>90,:rating=>-220},95=>{:value=>39,:rating=>-92},46=>{:value=>97,:rating=>-237},52=>{:value=>73,:rating=>-177},64=>{:value=>69,:rating=>-167},86=>{:value=>68,:rating=>-165},53=>{:va
如何在ruby中先根据值然后根据键对散列进行排序?例如h={4=>5,2=>5,7=>1}将排序为[[7,1],[2,5],[4,5]]我可以根据值进行排序h.sort{|x,y|x[1]y[1]}但我不知道如何根据值进行排序,然后在值相同时键入 最佳答案 h.sort_by{|k,v|[v,k]}这使用了Array的事实混入Comparable并定义逐元素。注意上面等价于h.sort_by{|el|el.reverse}相当于h.sort_by(&:reverse)这可能会或可能不会更具可读性。如果你知道Hashes一般都是先
在Ruby中,默认排序将空字符串放在第一位。['','g','z','a','r','u','','n'].sort给予:["","","a","g","n","r","u","z"]但是,在end处需要空字符串是很常见的。做类似的事情:['','g','z','a','r','u','','n'].sort{|a,b|a[0]&&b[0]?ab:a[0]?-1:b[0]?1:0}工作并给予:["a","g","n","r","u","z","",""]但是,这不是很可读,也不是很灵活。在Ruby中是否有一种合理且干净的方法让sort将空字符串放在最后?只映射到一个没有空字符串的数组,