有些爱学习的小伙伴可能在外出或者回老家过节前会有提前将学习视频缓存的习惯,但是缓存的视频只能用BilibiliApp来看,屏幕属实有一点点小,因此更想将其下载到电脑上,然后用自己喜欢的播放器去观看(如potPlayer)。
本篇博客将分享个JS脚本,利用免费解析网站,来实现批量的视频下载。
后续如果有bug将会在gitee上进行更新: https://gitee.com/he_fu_ren/bilibili-video-download
注:本脚本仅供学习使用,切勿用于商业用途
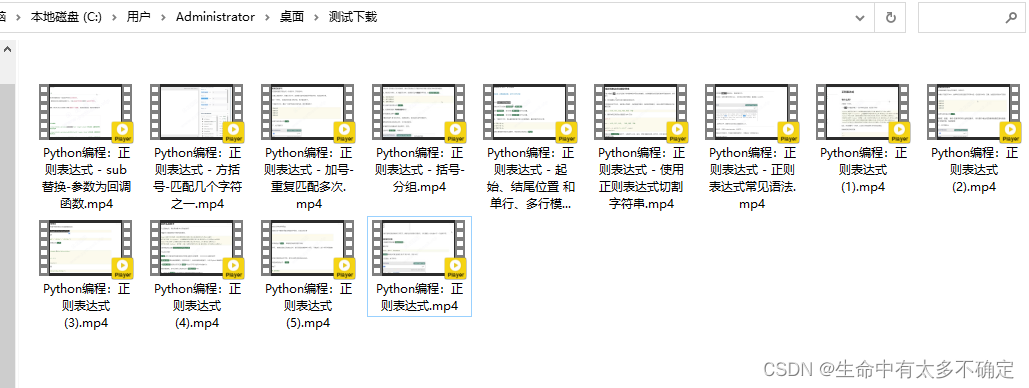
以下面的这个集数较少的视频为例,可以看到此教程有13个Part
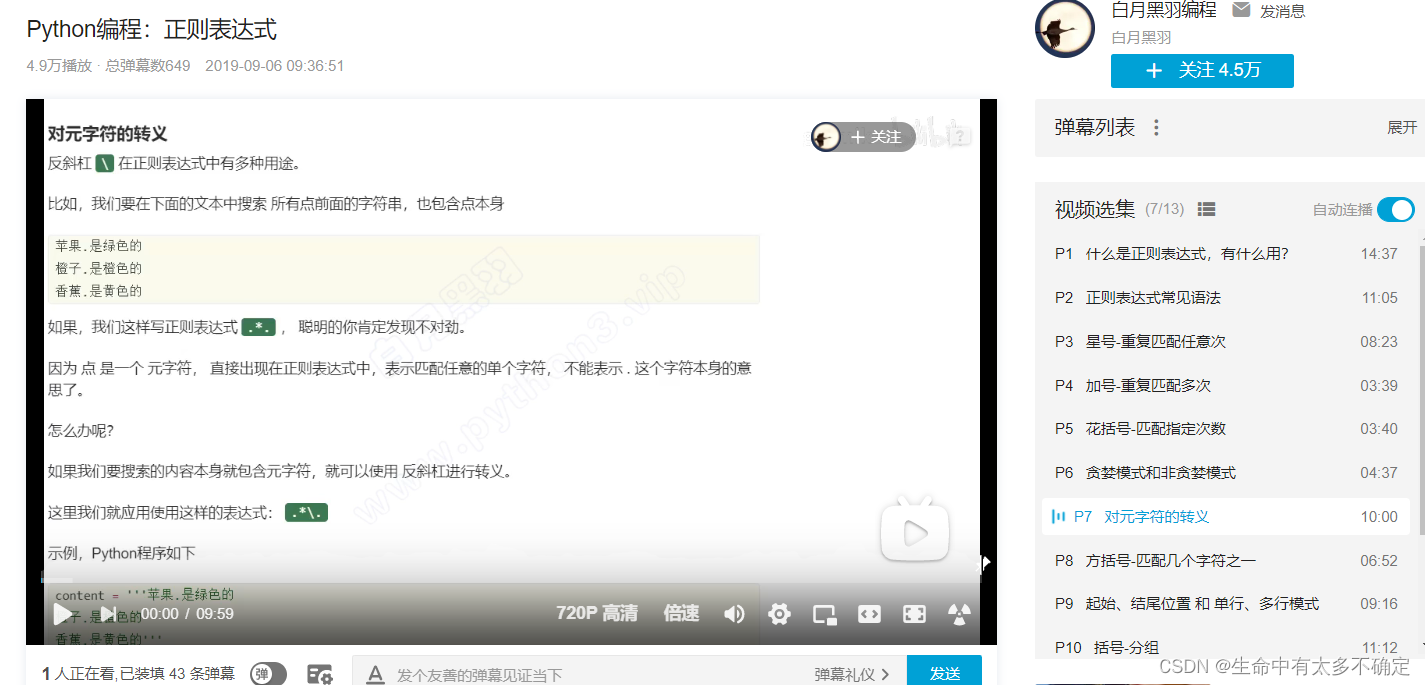
脚本运行截图
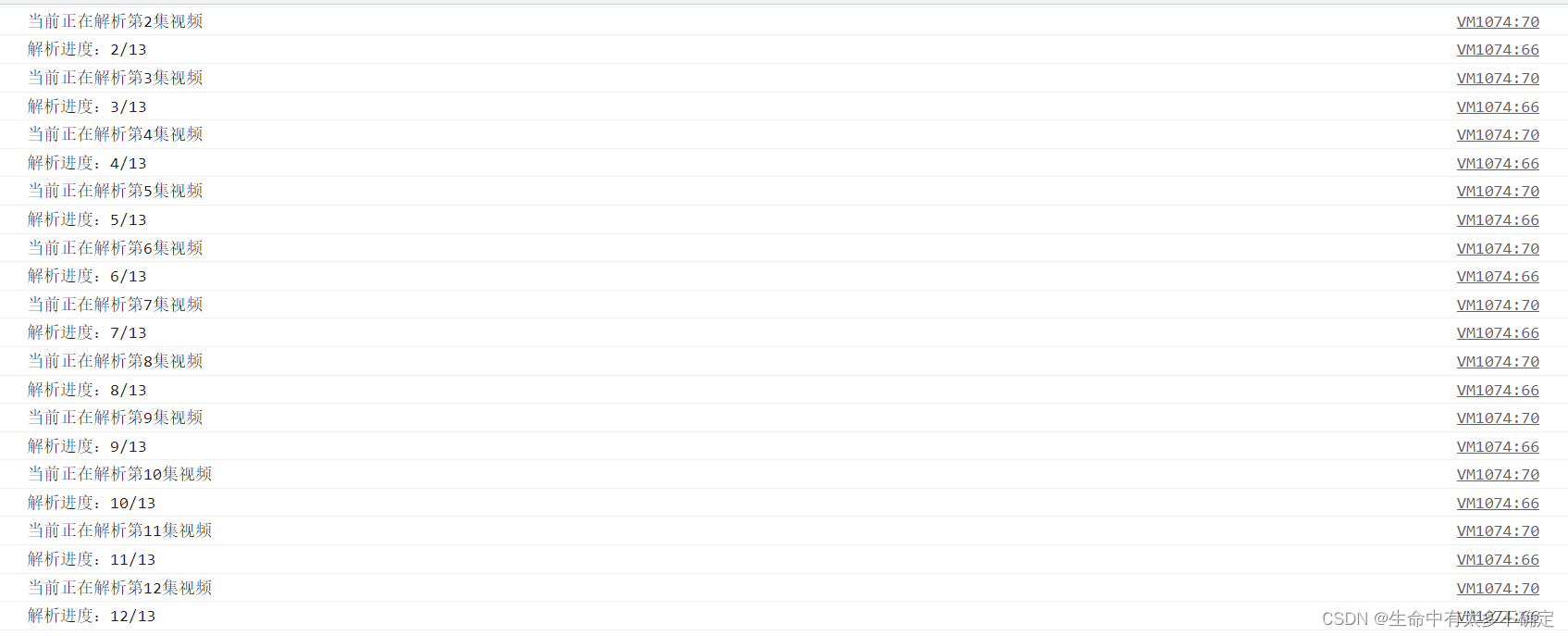
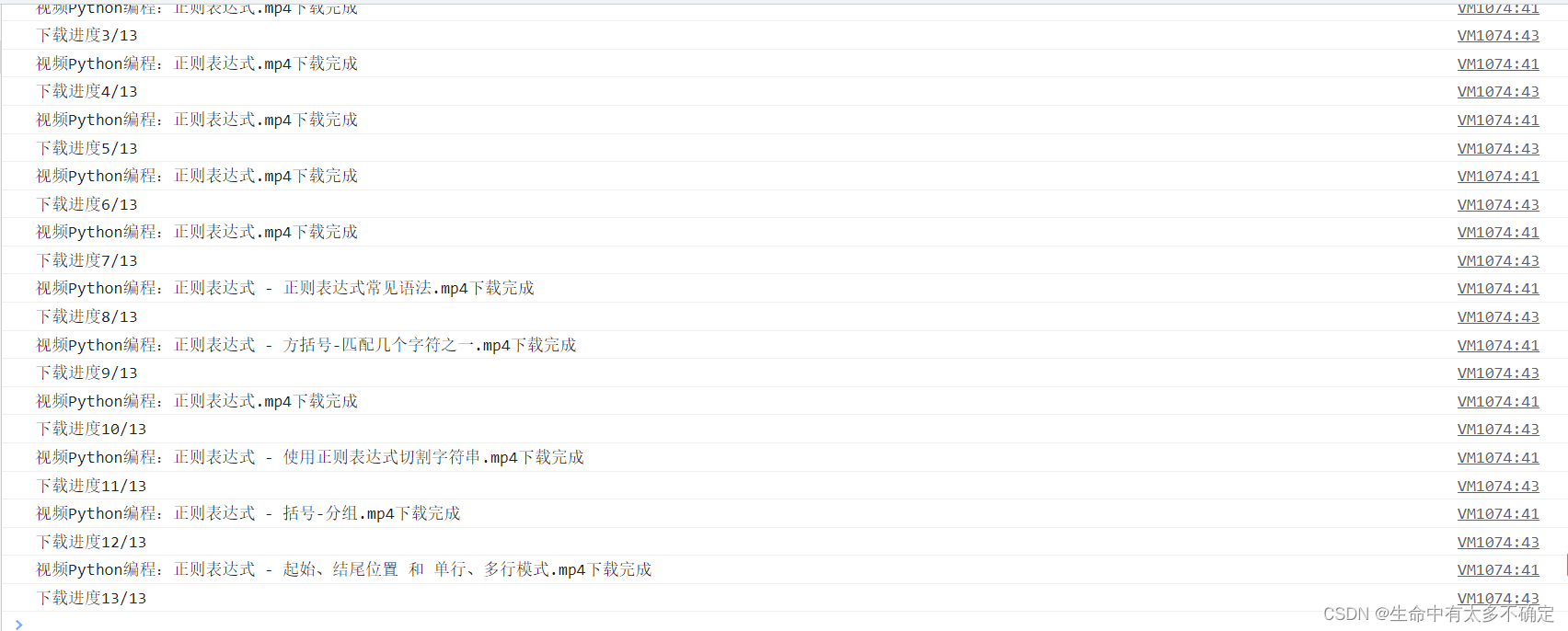
下载文件截图
本脚本使用的编程语言为为JavaScript,可以直接在浏览器中运行
let inputElement = document.getElementsByTagName('input')[0];
let resolveBtn = document.getElementsByClassName('btn')[0];
let beginTime = 0;
let downloadCount = 0;
let resolveCount = 0;
// 视频的前缀,只需要修改 .../video/av?p= 中的 av 号即可
let prefix = "https://www.bilibili.com/video/BV1EN411X7jw/?p=";
// 从点击完解析按钮到解析完成的时间间隔,默认1s
let interval = 2000;
// 从第几集开始下载,默认是从第一集开始
let beginPart = 1;
// 要下载的视频的集数
let num = 13;
// 算出最后一个Part
let endPart = beginPart + num - 1;
// 标记每一Part是否需要重置,1表示需要,0表示不需要
let retryCandidate = new Array(num);
retryCandidate.fill(1);
let retryTime = (interval + 1000) * num;
// 下载视频,url:视频链接,name:下载后的文件名
function downloadVideo(url,name) {
//创建XMLHttpRequest对象
let httpRequest = new XMLHttpRequest();
//打开连接,将请求参数拼在url后面
httpRequest.open('GET', url, true);
//设置期望的返回值类型
httpRequest.responseType = "blob";
//请求成功回调函数
httpRequest.onload = function (oEvent) {
if (httpRequest.status === 200) {
let fileName = decodeURI(name+'.mp4');
let response = httpRequest.response;
//数据转换为文件下载
let elink = document.createElement('a');
elink.download = fileName;
elink.style.display = 'none';
let blob = new Blob([response]);
elink.href = URL.createObjectURL(blob);
document.body.appendChild(elink);
elink.click();
document.body.removeChild(elink);
console.log('视频' + fileName + '下载完成');
downloadCount = downloadCount + 1;
console.log('下载进度' + downloadCount + '/' + num);
}else {
console.log('下载失败,请手动下载,视频url ' + url);
}
}
httpRequest.send();
};
// 解析Part的url与名称
function resolve(i) {
if (document.getElementsByClassName('caption').length > 0) {
// 获取解析后的url
let url = document.getElementsByClassName('caption')[0].getElementsByTagName('p')[1].getElementsByTagName('a')[0].getAttribute('href');
// 获取文件名
let name = document.getElementsByClassName('caption')[0].getElementsByTagName('p')[0].innerText;
// 为了保证下载后的视频顺序,统一加上'Part-'前缀
name = 'Part-' + i + ' ' + name;
resolveCount = resolveCount + 1;
// 这里-1的目的是为了将逻辑下标变成物理下标
retryCandidate[i-1] = 0;
downloadVideo(url, name);
} else {
console.log('第' + i + '集视频解析失败,稍后将会重试');
}
console.log('解析进度:' + resolveCount + '/' + num);
};
// 调用网页的解析功能
function sendResolvRequest(i) {
console.log('当前正在解析第' + i + '集视频');
// url
let bilibiliUrl = prefix + i;
inputElement.value = bilibiliUrl;
let evt = document.createEvent('HTMLEvents');
evt.initEvent('input',true,true);
inputElement.dispatchEvent(evt);
// 触发按钮点击事件
resolveBtn.click();
// 解析结果
setTimeout(resolve(i),interval);
};
function doRetry() {
console.log('开始重试');
// 待重试的数量
let len = num - resolveCount;
// 重置开始解析的时间,初始化为0,表示第一次解析是在0s后执行,也就是立刻执行
beginTime = 0;
console.log('剩余解析失败的视频数量:',len);
// 遍历retryCandidate数组,找出需要重试的part
for(let i = 0; i < num; i++) {
if (retryCandidate[i] == 1) {
setTimeout(function(){
// 物理下标转逻辑下标
sendResolvRequest(i+1);
},beginTime);
console.log('第' + (i + 1) + '个视频将在' + beginTime/1000 + '秒后重试');
beginTime = beginTime + interval + 1000;
}
}
// 计算下一次重试的开始时间
let retryTime = (interval + 1000) * len ;
console.log('将在' + retryTime/1000 + 's后进行下一轮重试');
setTimeout(function() {
retry();
},retryTime);
}
// 重试失败的Part
function retry() {
// 成功解析的Part的数量 < 预期解析的Part的数量
if (resolveCount < num) {
console .log('开始重试');
doRetry()
}
}
// 正常的去解析下载每一个Part
for(let i = beginPart; i <= endPart; i++) {
setTimeout(function(){
sendResolvRequest(i);
},beginTime);
beginTime = beginTime + interval + 1000;
}
// 在上面循环结束完之后会解析重试失败的Part
setTimeout(function() {
retry();
},retryTime);
第一步
打开视频解析网址:https://bilibili.iiilab.com/
第二步
按F12打开控制台 或者 右键网页然后再点检查,打开控制台后点击`Consoles,切换到控制台界面
第三步
将上述代码全部复制到文本编辑器中,根据自身情况去做修改
可修改部分在代码最上面:
// 视频的前缀,只需要修改 .../video/【av】?p= 中括号内的部分即可,av号在对应B站视频的url中可以看到
let prefix = "https://www.bilibili.com/video/BV1q4411y7Zh/?p=";
// 从点击完解析按钮到解析完成的时间间隔,默认2s(2000ms),网速如果比较慢就改大一些
let interval = 2000;
// 从第几集开始下载,默认是从第一集开始
let beginPart = 1;
// 要下载的视频的集数,配合上面的参数,就是下载1-13集视频
let num = 13;
修改完之后就可以将修改后的代码粘贴到第一步打开的网页中去了。
说明
本脚本仅供学习使用,目前是初代版本,可能会有一些小bug,比如可能漏下载个别视频等,之后有时间会进行修复,并提交到git上
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
这个问题在这里已经有了答案:Railsformattingdate(4个答案)关闭4年前。我想格式化Time.Now函数以显示YYYY-MM-DDHH:MM:SS而不是:“2018-03-0909:47:19+0000”该函数需要放在时间中.现在功能。require‘roo’require‘roo-xls’require‘byebug’file_name=ARGV.first||“Template.xlsx”excel_file=Roo::Spreadsheet.open(“./#{file_name}“,extension::xlsx)xml=Nokogiri::XML::Build
我喜欢使用Textile或Markdown为我的项目编写自述文件,但是当我生成RDoc时,自述文件被解释为RDoc并且看起来非常糟糕。有没有办法让RDoc通过RedCloth或BlueCloth而不是它自己的格式化程序运行文件?它可以配置为自动检测文件后缀的格式吗?(例如README.textile通过RedCloth运行,但README.mdown通过BlueCloth运行) 最佳答案 使用YARD直接代替RDoc将允许您包含Textile或Markdown文件,只要它们的文件后缀是合理的。我经常使用类似于以下Rake任务的东西:
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
是否有简单的方法来更改默认ISO格式(yyyy-mm-dd)的ActiveAdmin日期过滤器显示格式? 最佳答案 您可以像这样为日期选择器提供额外的选项,而不是覆盖js:=f.input:my_date,as::datepicker,datepicker_options:{dateFormat:"mm/dd/yy"} 关于ruby-on-rails-事件管理员日期过滤器日期格式自定义,我们在StackOverflow上找到一个类似的问题: https://s
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------