——问题来自:死磕Elasticsearch 知识星球微信群
这个问题涉及到业务细节,至今没有定论。不过,该问题引发了我的思考。
我们使用 Elasticsearch 到底用来做什么?
除了 Elasticsearch 早已不是10年前因“菜谱”而火出技术圈的搜索引擎组件,它早已不是“单兵作战”,而是 ELKB 形成的 Elastic Stack “行走江湖”。
但,至少技术选型涉及到大数据的检索几乎无一例外 Elasticsearch 都是“首发阵容”。
关于全文搜索,《这就是搜索引擎》张俊林博士从搜索引擎的角度阐述了用户的关注点,核心就是两个。
其一:精准率;
其二:召回率。
通俗点讲:
精准率是站在用户角度,召回的数据贴合用户的预期,越准确越好。
当然,大数据时代的今天,单纯的字、词匹配早已跟不上时代的步伐,基于用户行为的推荐(如:抖音、网易云音乐)往往更吊起用户的胃口。

而召回率是满足检索条件的语句都尽可能的召回,到底要什么,让用户在结果中二次再做选择。
这两种都有应用场景,无所谓谁对谁错。
提到 Elasticsearch 精准召回数据,先不谈“精准”,先说一下召回。
如下图所示,可以分两部分看:数据的写入过程、数据检索过程。
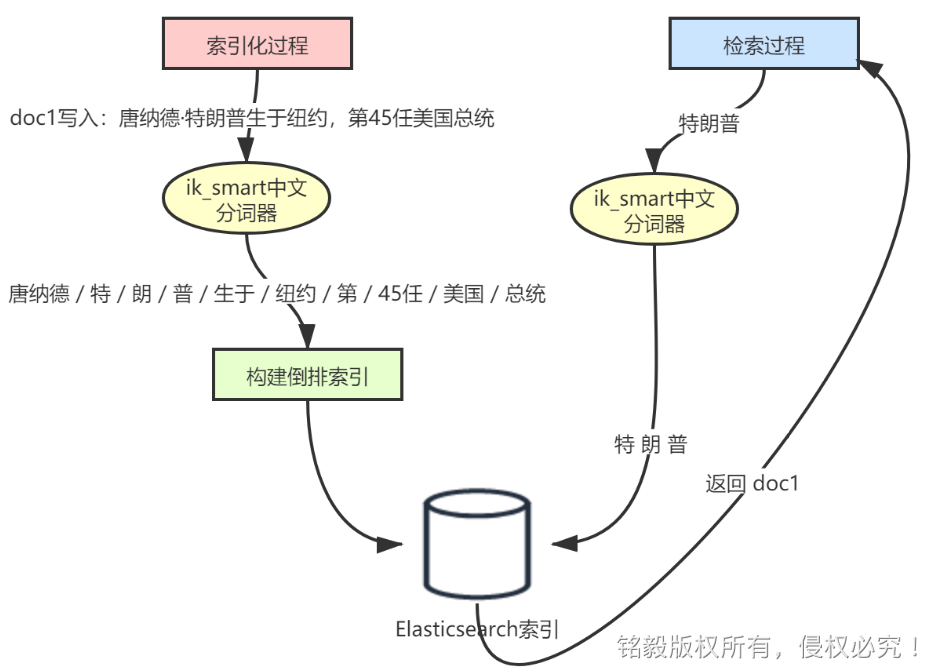
数据写入过程要比图中复杂,我们着重关注建立倒排索引的过程,因为后面我们要基于倒排索引做全文检索。
写入的文本如下:

基于 ik_smart 分词后,倒排索引的中的分词词典如下所示:

Elasticsearch 提到检索,这其实是一个大的概念,不信你看下面的脑图。
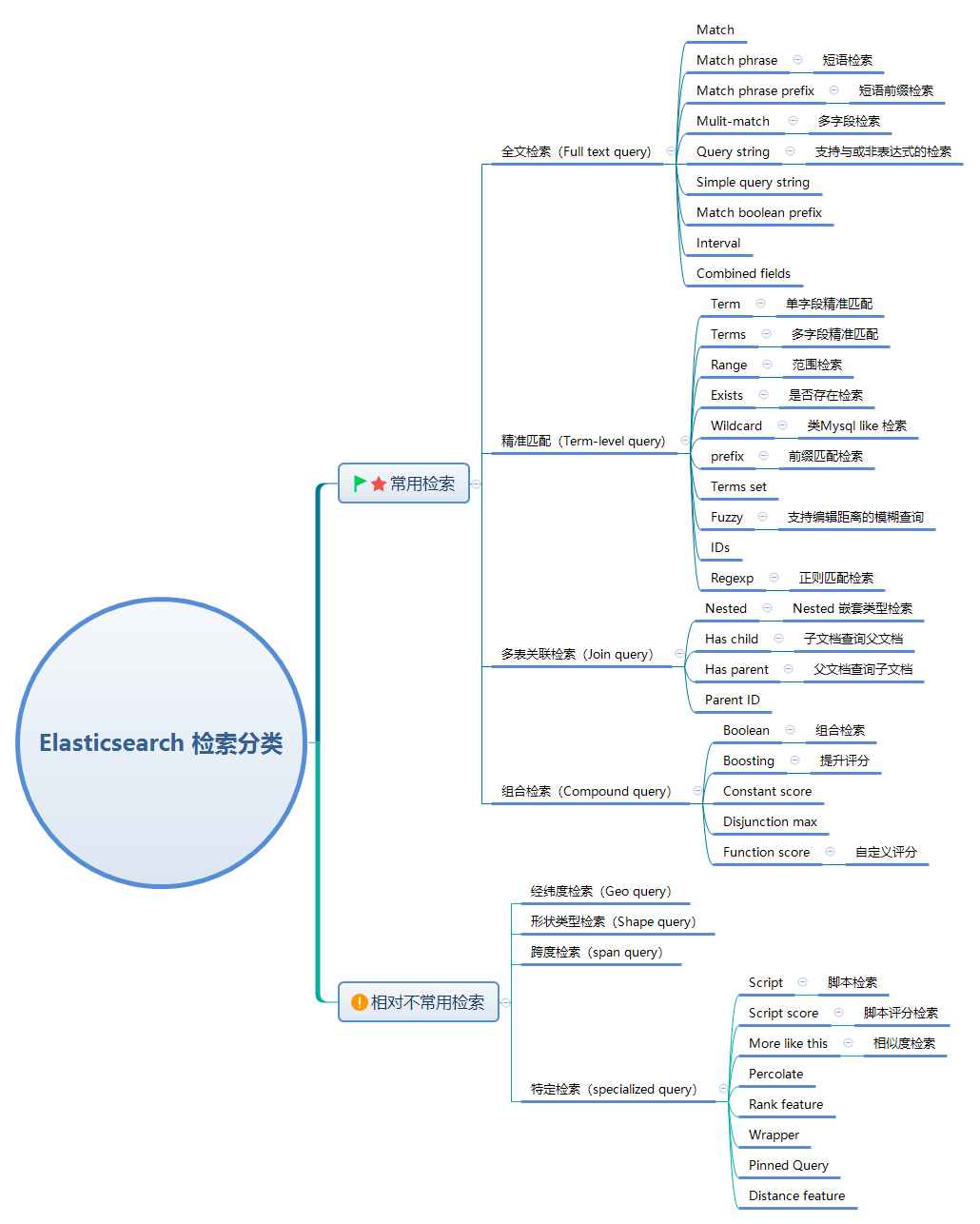
Elasticsearch 检索从大的角度可以看成黑盒,类似:Google、baidu 搜索框。用户搜索框输入内容,检索召回数据。
但是,技术人员的眼里看搜索,更关注用哪种类型搜索。这涉及到检索分类。
Elasticsearch 检索大致可以分为:全文检索、精准匹配检索、多表关联检索、组合检索、不常用检索。
精准匹配检索回答的是“是和否、存在或不存在”问题?比如:小明的手机号为:“13566668888”,多一位、少一位、错一位都不能被召回!完全满足检索条件就召回,不满足检索条件就不要召回。不存在中间情况。
而全文检索回答的是“相关度”的问题?如文章开头提到的“手表”、“手表带”、“表带”就有相关度,哪些数据该召回?谁优先被召回(也就是谁排在前面)。
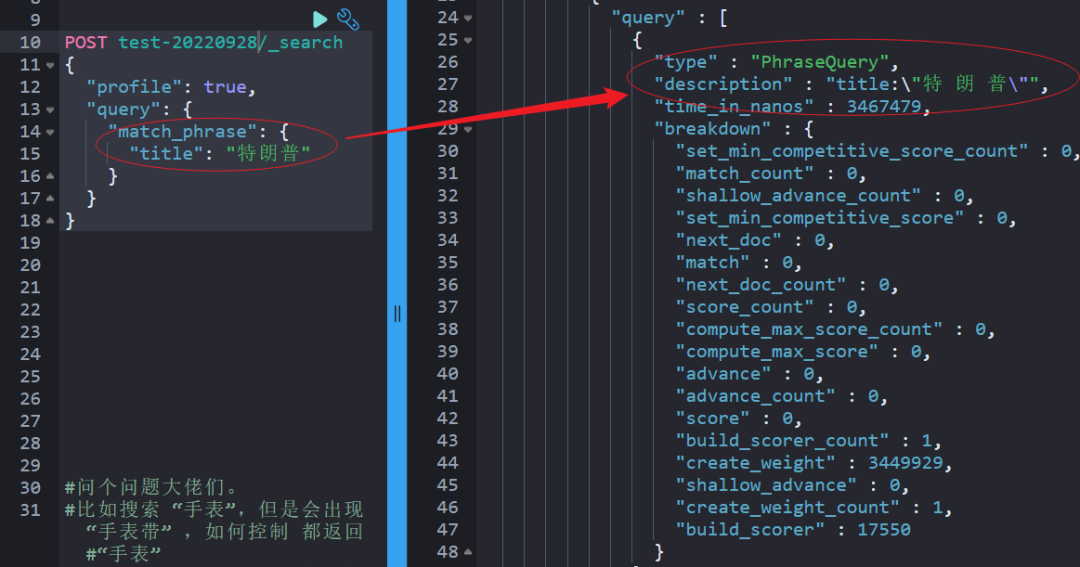
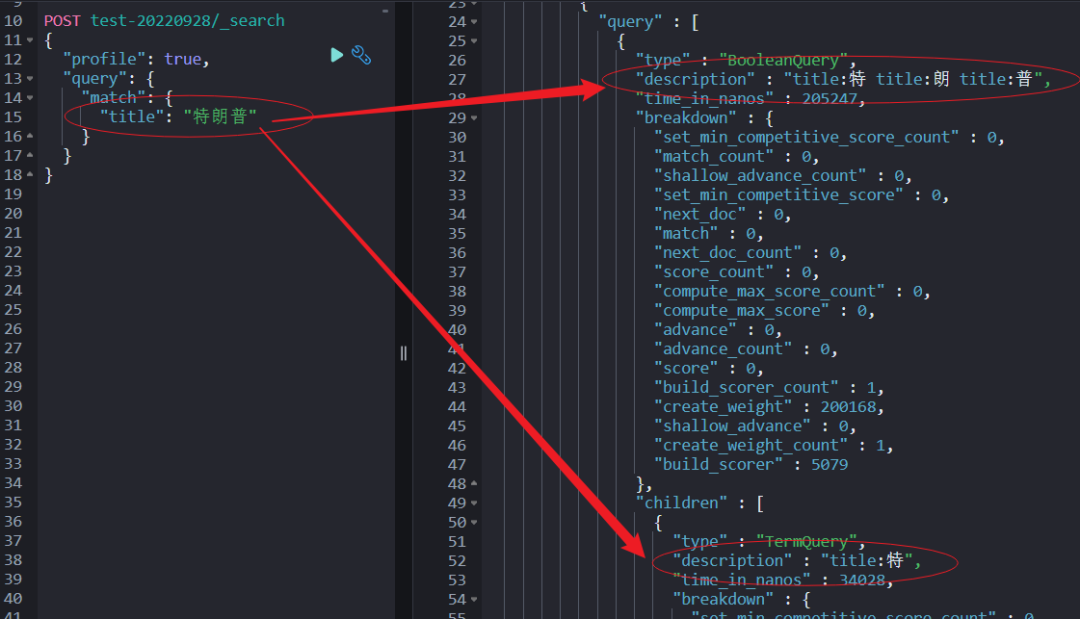
match_phrase 和 match 等实现检索的机制是不一样的,“profile:true" API 能帮我们更精细的看到底层的实现。
简单点说:match_phrase 走的是短语检索匹配,而 match 走的是多字段拆解后的 term query 的 bool 语句组合体。
其实这个没有普适的标准,不同的业务系统是不一样的。
建议,结合业务需求、产品经理和技术经理、项目经理、核心技术人员共同敲定。
满足用户要求的“精准”才算是精准。
比如文章开头提到的“手表”,其实有多种理解?
其一:只有“手表”两个字,没有任何其他,这种叫精准。
其二:分词词典里有“手表”,就要召回,这种也叫精准。
其三:只要文本里有就要召回,这也是某种意义的精准。比如:“南京市长江大桥”,搜索“江大桥”也要求召回。
等等......不一而足。
有了上面的思考,我们尝试解读一下开篇的问题。
如下示例,拿数据说话!
词索引——使用 ik_smart 分词。
字索引——使用 standard 标准分词。
保留了 keyword 类型,便于方案二的精准字符匹配。
DELETE test-20220928
PUT test-20220928
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_smart",
"fields": {
"standard": {
"type": "text",
"analyzer": "standard"
},
"keyword": {
"type": "keyword"
}
}
}
}
}
}
POST test-20220928/_bulk
{"index":{"_id":1}}
{"title":"手表带真好看"}
{"index":{"_id":2}}
{"title":"手表最近卖的不好,咋整"}
{"index":{"_id":3}}
{"title":"卡西欧手表不错哦"}
{"index":{"_id":4}}
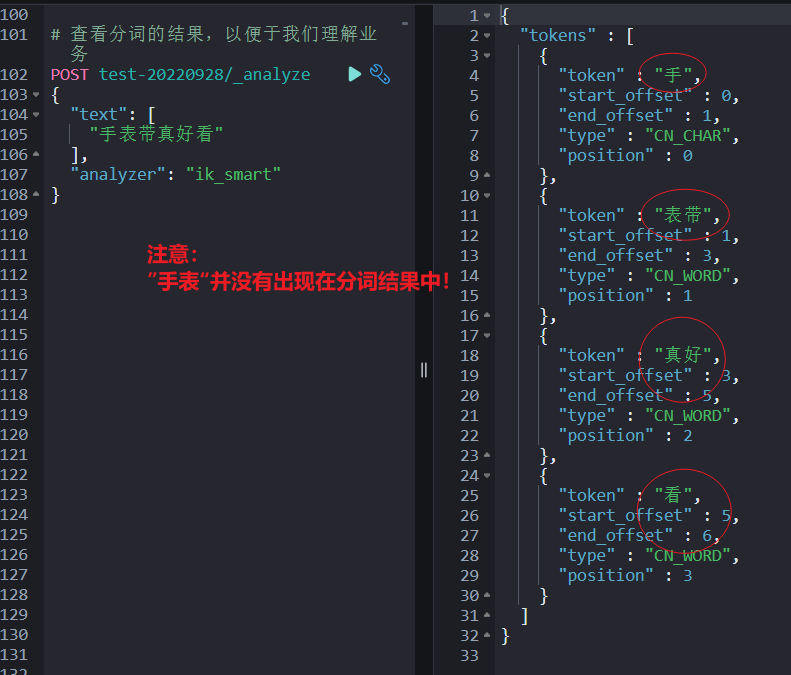
{"title":"手表"}先看“手表带真好看”这个文档 ik_smart 的分词结果。
其他几个文档{“2”,“3”,“4”} 都包含手表的分词,大家可以自己验证,篇幅原因,没有截图。
如下检索是 bool 组合混合体。
对于:must 条件要求单字相连的多字(可以理解为短语,但不见得是有意义的短语,如:江大桥)必须满足,用 短语 match_phrase 进行检索。
对于:should 条件满足 ik_smart 分词存在结果,则召回数据,且极大的提升评分权重。
POST test-20220928/_search
{
"query": {
"bool": {
"should": [
{
"match_phrase": {
"title": {
"query": "手表",
"boost": 50
}
}
}
],
"must": [
{
"match": {
"title.standard": "手表"
}
}
]
}
}
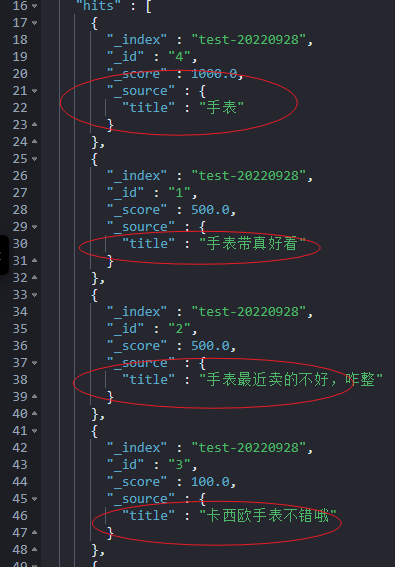
}明显看出来:包含手表要排在前面。
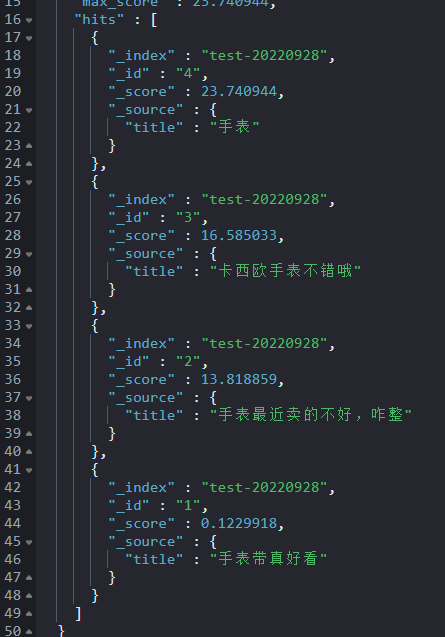
使用前提:针对是 keyword 类型。
大家记住:sort 排序、aggregation 聚合、script 脚本都只能针对 keyword 类型,text 类型都是不支持的,除非开启“fielddata”(必要性非常小,使用场景也小,不建议开启)。
如下脚本的含义,如果字段精准匹配,没有多余字符,则评分极高,设置为1000;如果字段以给定关键词开头,则评分高,设置为500;如果属于包含关系,则评分也较高,设置为100;如果没有包含,那评分为10。
POST test-20220928/_search
{
"query": {
"script_score": {
"query": {
"match_all": {}
},
"script": {
"source": "if(doc['title.keyword'].value == params.keyword) { return 1000; } else if(doc['title.keyword'].value.startsWith(params.keyword)){ return 500; } else if(doc['title.keyword'].value.contains(params.keyword)) { return 100; } else { return 10;}",
"params": {
"keyword": "手表"
}
}
}
}
}相当于我们人工干预了评分,基于字段精准匹配的情况实现了评分的区分。这样,最先召回的结果数据就是我们最期望的精准匹配结果了。
针对企业级实战问题,引发了思考,并根据思考尝试做了解答。
当然,这道业务题目会有具体的细节业务场景,还需要进一步沟通交流。
本文涉及的技术点都不复杂。包含如下:
分词(中文分词器、默认分词器)
组合分词(fields)
组合检索
排序(评分)+ 全文检索+召回
自定义评分(自己定义的规则来进行数据的评分,进而将评分高的优先返回,排在前面进行返回!)
仅就本文的讨论和实现,相信你也遇到过类似问题,欢迎留言交流下你的思考!
4、如何从0到1打磨一门 Elasticsearch 线上直播课?

更短时间更快习得更多干货!
中国50%+Elastic认证专家出自于此!
在不确定的时代,寻求确定性!

比同事抢先一步学习进阶干货!
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
给定这段代码defcreate@upgrades=User.update_all(["role=?","upgraded"],:id=>params[:upgrade])redirect_toadmin_upgrades_path,:notice=>"Successfullyupgradeduser."end我如何在该操作中实际验证它们是否已保存或未重定向到适当的页面和消息? 最佳答案 在Rails3中,update_all不返回任何有意义的信息,除了已更新的记录数(这可能取决于您的DBMS是否返回该信息)。http://ar.ru
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我想要做的是有2个不同的Controller,client和test_client。客户端Controller已经构建,我想创建一个test_clientController,我可以使用它来玩弄客户端的UI并根据需要进行调整。我主要是想绕过我在客户端中内置的验证及其对加载数据的管理Controller的依赖。所以我希望test_clientController加载示例数据集,然后呈现客户端Controller的索引View,以便我可以调整客户端UI。就是这样。我在test_clients索引方法中试过这个:classTestClientdefindexrender:template=>