新买的笔记本怎么配置TensorFlow-gpu
为了更好地学习深度学习,我今年斥重金买了一台联想-拯救者-R9000,除了P9000之外,这台电脑的配置应该算是笔记本当中的天花板了。但是买来半个月,一直在修改自己的论文,所以除了新的鼠标灵敏度高,打开word不卡之外,也没有体验到天花板有多香。这几天论文改的差不多了,心中又燃起了对深度学习的浴火(主要是想看看这个天花板的性能有没有外界说的那么神)。结果!结果!家人们,咱就是说,吊起来了,内心雀跃之余,得给广大网友分享这份喜悦。具体的心路历程和配置步骤如下:
1、本人电脑型号:
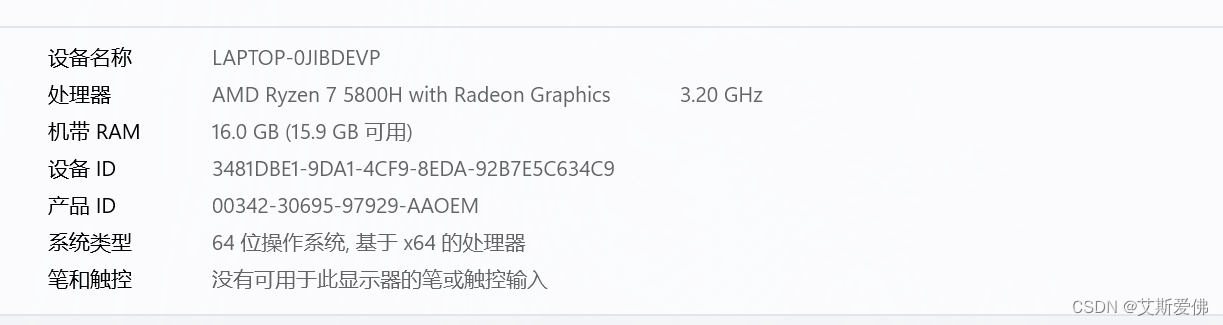

RTX3060gpu大小为6G
2、使用TensorFlow-gpu版的条件
首先电脑上有gpu,这个大家直接搜索“怎么查看自己的gpu”按照步骤去看自己的gpu的情况就好。
然后gpu的性能,官方要求TensorFlow-gpu需要的gpu算力应该在3.5以上。但是实话实说,这个也看gpu的,有些电脑gpu查得到算力是5,但是确实调不起来,或者能装但是也不能跑。我之前那台老电脑gpu型号是940MX,官方算力是5,大小是2个G,但是,,咳咳 ,,,真的调不起来,跑不动,安装了之后他的gpu占用是0,主要是靠CPU跑的。所以如果大家的电脑年份已久(3年及以上)并且是轻薄办公本的话,就老老实实装cpu版的吧,不然就是瞎耽误工夫。
提前声明这篇博客我用的配置是:anaconda3+Python3.9+cuda11.6.1+8.3.8cudnn for cuda 11.5+TensorFlow2.8.0所以如果你的电脑配置跟我一样,并且之前有conda和Python,那么配起来就飞快。如果配置相差较大,大家酌情参考!
1、安装anaconda
anaconda里面有很多编辑器,再加上numpy,pandas等包装起来也特别容易,所以是学习机器学习的最佳选择。我是在官网直接下载的,很多人说慢,但是我下载起来还蛮快的。
官网首页:https://www.anaconda.com/
官网下载页:https://www.anaconda.com/products/individual#Downloads
2、创建新环境
在anaconda的anaconda prompt中新建一个环境
conda create --name yourEnv python=3.9
我的环境名字命名为TensorFlow-gpu,所以创建环境时:
conda create --name TensorFlow-gpu python=2.7
然后打开prompt激活该环境就可以了。
activate Tensorflow-gpu
3、检查Python版本
如果conda装完之后,Python的版本不是3.9,要删除旧版本,升级成3.9
检查方法:
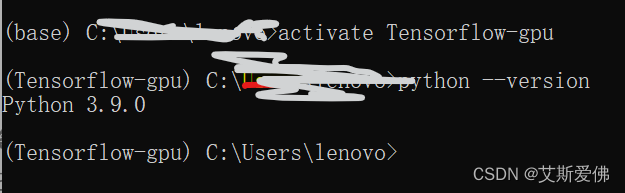
如果不是3.9,要进行版本升级。
4、安装cuda
找到自己NVIDIA控制面板,左下角系统信息打开,如下图第三行可以看到自己所支持的cuda驱动版本
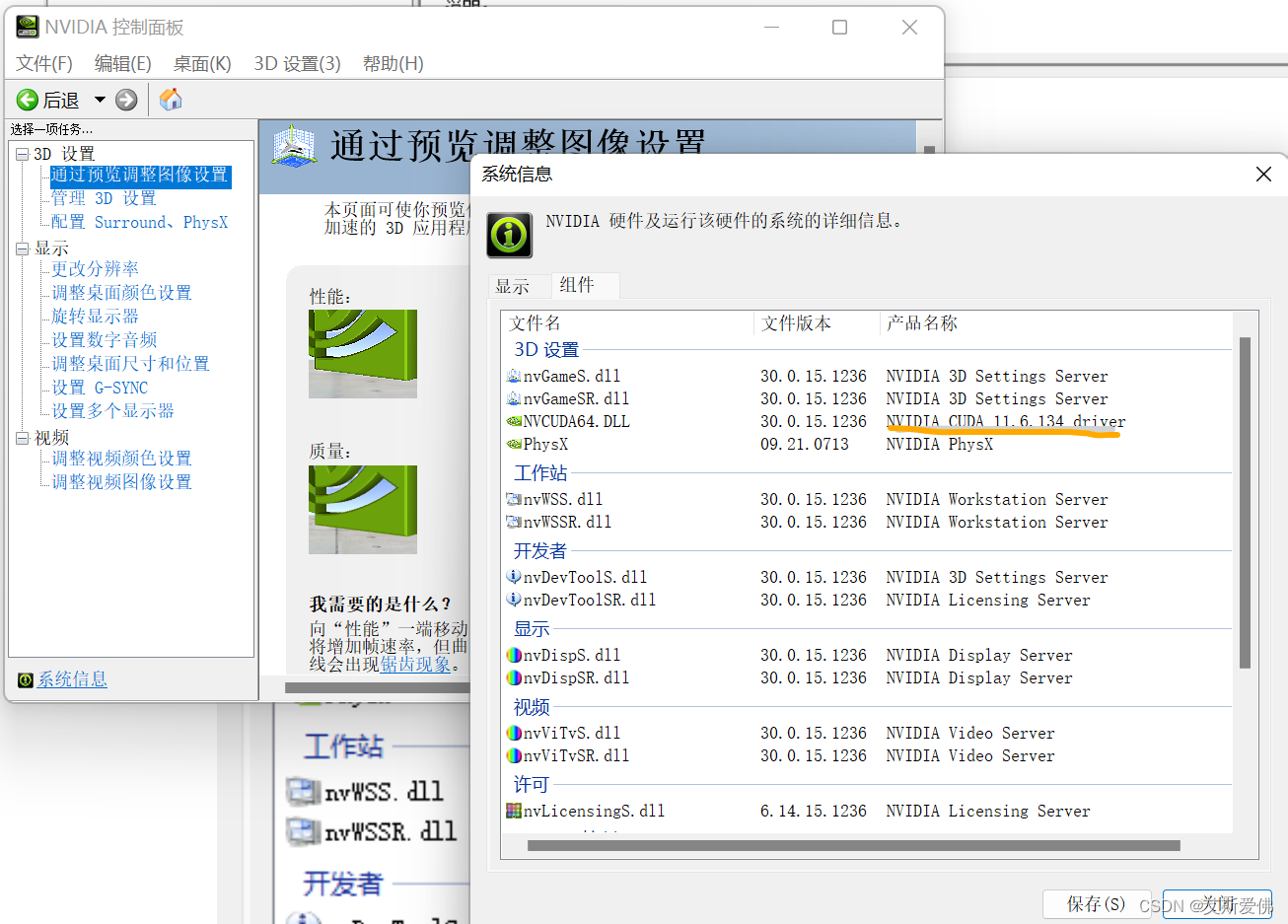
我的是11.6.1,然后从下方cuda官网下载适合自己版本的cuda:
cuda下载
我是按照这个装的,大家在安装的过程中一定不要自己去自定义文件夹,我之前一直想安装在D盘,但是很容易失败,所以能默认的就先默认。具体的下载安装教程转这个:cuda安装教程
4、安装cudnn
cudnn下载
因为cuda安装的是11.6,而cudnn中没有明确的for 11.6,我之前安装的是for 11.x的,但是没调出来,忘记看了哪一篇博客了,说推荐下载for 11.5的,所以进去之后选下面这个:
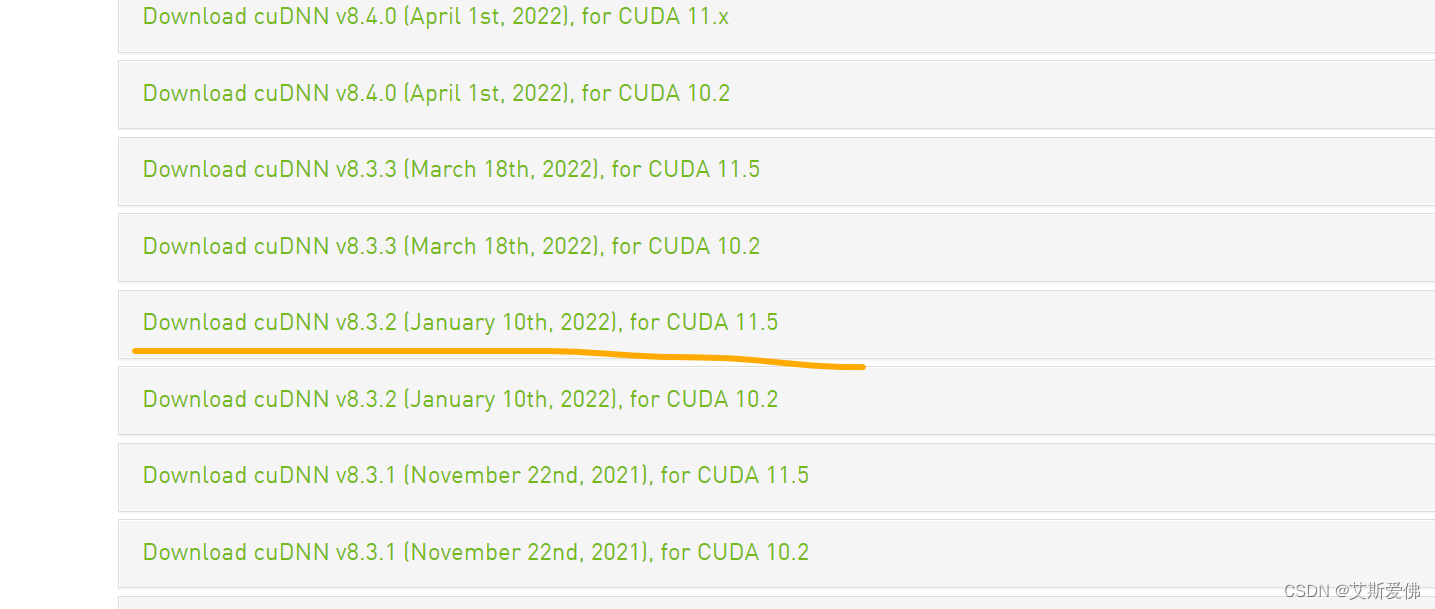 5、下载TensorFlow-gpu
5、下载TensorFlow-gpu
前面的全部配置好,这里因为涉及到的东西很多,所以前面的部分没有写具体,大家自行搜索配置环境的教程按照步骤操作就好。
首先激活自己创建好的TensorFlow环境,然后用下面的命令安装TensorFlow-gpu 2.8.0:
pip install tensorflow-gpu==2.8.0 --default-timeout=100 -i https://pypi.tuna.tsinghua.edu.cn/simple
如果在安装过程中出现闪退,是正常现象,可以把timeout值加大,等待就可以重新安装了。
安装之后,Python下输入:
import tensorflow as tf 没有报错,就是安装成功了!
全部安装配置完成,在后台命令中输入下列命令,有TRUE,表示调用成功:
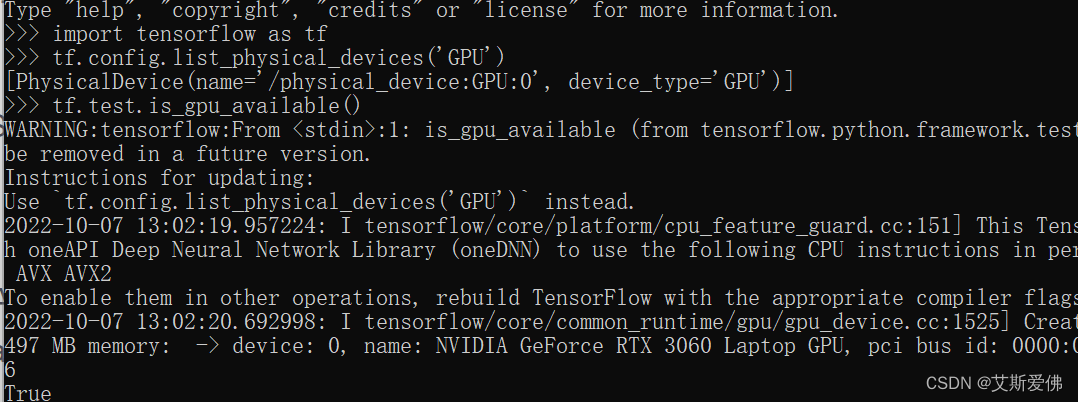
自此,TensorFlow-gpu版本的便是安装完成并能够正常使用了。
尽管教程相对来说,步骤清晰了,但是有些细节没有写清楚,一则是每个部分网上的步骤都很详细,我也是从别人那里参考的。一则,安装这个TensorFlow到写完这篇博客时间相差较大,一些细节已经遗忘。但是如果大家在安装过程中出现什么问题,或者有什么疑问都可以评论或者私信,我会尽量帮助。
我正在尝试编写一个将文件上传到AWS并公开该文件的Ruby脚本。我做了以下事情:s3=Aws::S3::Resource.new(credentials:Aws::Credentials.new(KEY,SECRET),region:'us-west-2')obj=s3.bucket('stg-db').object('key')obj.upload_file(filename)这似乎工作正常,除了该文件不是公开可用的,而且我无法获得它的公共(public)URL。但是当我登录到S3时,我可以正常查看我的文件。为了使其公开可用,我将最后一行更改为obj.upload_file(file
如何在ruby中调用C#dll? 最佳答案 我能想到几种可能性:为您的DLL编写(或找人编写)一个COM包装器,如果它还没有,则使用Ruby的WIN32OLE库来调用它;看看RubyCLR,其中一位作者是JohnLam,他继续在Microsoft从事IronRuby方面的工作。(估计不会再维护了,可能不支持.Net2.0以上的版本);正如其他地方已经提到的,看看使用IronRuby,如果这是您的技术选择。有一个主题是here.请注意,最后一篇文章实际上来自JohnLam(看起来像是2009年3月),他似乎很自在地断言RubyCL
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我需要一些关于TDD概念的帮助。假设我有以下代码defexecute(command)casecommandwhen"c"create_new_characterwhen"i"display_inventoryendenddefcreate_new_character#dostufftocreatenewcharacterenddefdisplay_inventory#dostufftodisplayinventoryend现在我不确定要为什么编写单元测试。如果我为execute方法编写单元测试,那不是几乎涵盖了我对create_new_character和display_invent
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
说在前面这部分我本来是合为一篇来写的,因为目的是一样的,都是通过独立按键来控制LED闪灭本质上是起到开关的作用,即调用函数和中断函数。但是写一篇太累了,我还是决定分为两篇写,这篇是调用函数篇。在本篇中你主要看到这些东西!!!1.调用函数的方法(主要讲语法和格式)2.独立按键如何控制LED亮灭3.程序中的一些细节(软件消抖等)1.调用函数的方法思路还是比较清晰地,就是通过按下按键来控制LED闪灭,即每按下一次,LED取反一次。重要的是,把按键与LED联系在一起。我打算用K1来作为开关,看了一下开发板原理图,K1连接的是单片机的P31口,当按下K1时,P31是与GND相连的,也就是说,当我按下去时
如何找到调用此方法的位置?defto_xml(options={})binding.pryoptions=options.to_hifoptions&&options.respond_to?(:to_h)serializable_hash(options).to_xml(options)end 最佳答案 键入caller。这将返回当前调用堆栈。文档:Kernel#caller.例子[0]%rspecspec10/16|===================================================62=====
Rails相对较新。我正在尝试调用一个API,它应该向我返回一个唯一的URL。我的应用程序中捆绑了HTTParty。我已经创建了一个UniqueNumberController,并且我已经阅读了几个HTTParty指南,直到我想要什么,但也许我只是有点迷路,真的不知道该怎么做。基本上,我需要做的就是调用API,获取它返回的URL,然后将该URL插入到用户的数据库中。谁能给我指出正确的方向或与我分享一些代码? 最佳答案 假设API为JSON格式并返回如下数据:{"url":"http://example.com/unique-url"
我正在写一篇关于在Ruby中几乎一切都是对象的博客文章,我试图通过以下示例来展示这一点:classCoolBeansattr_accessor:beansdefinitialize@bean=[]enddefcount_beans@beans.countendend所以从类中我们可以看出它有4个方法(当然,除非我错了):它可以在创建新实例时初始化一个默认的空bean数组它可以计算它有多少个bean它可以读取它有多少个bean(通过attr_accessor)它可以向空数组写入(或添加)更多bean(也通过attr_accessor)但是,当我询问类本身它有哪些实例方法时,我没有看到默认
我写了一个非常简单的rake任务来尝试找到这个问题的根源。namespace:foodotaskbar::environmentdoputs'RUNNING'endend当在控制台中执行rakefoo:bar时,输出为:RUNNINGRUNNING当我执行任何rake任务时会发生这种情况。有没有人遇到过这样的事情?编辑上面的rake任务就是写在那个.rake文件中的所有内容。这是当前正在使用的Rakefile。requireFile.expand_path('../config/application',__FILE__)OurApp::Application.load_tasks这里